随机效应 VS 固定效应
1. 固定效应
Group 中的level是pre-specified,就特殊的,就这么几个。that is, having pre-specified levels, with the goal of comparing specific levels of that effect。
例如治疗组和安慰剂组的对比,对比结论就是限制在治疗组和安慰剂组。但是,此时,patient是随机效应,两种治疗在patient之间的效应,会推论到更多的patient。
![]()
y: 反应变量
X: 是模型内固定因子关系矩阵
b: 是待估计的参数向量
e: 代表未知的随机取样的误差.
这个就是固定效应模型,将其推广,得到混合线性模型。
随机效应和固定效应区别在于:
从客观角度讲,研究对象得固定效应在什么时候测量都是一样得。研究对象得随机效应,研究对象自身会变化,测量结果也会变化。
2. 混合线性模型
![]()
y: 反应变量
X: 是模型内固定因子关系矩阵。也就是数据中收集了y和b的数值,通过这些数值,算出来X。
b: 是待估计的参数向量
Z: 随机因子关系矩阵。也就是数据中收集了y和b的数值,通过这些数值,算出来Z。
u: 随机效果的参数向量。(u就是v)
e: 代表未知的随机取样的误差,e 值间的独立关系也未必成立
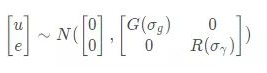
上面的意思是 u 和 e 的平均值为0,方差为G和R,协方差为0。
推断:
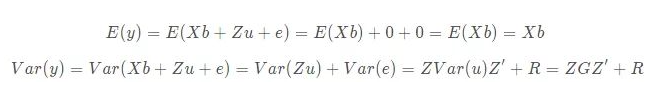
y 反应变量的期望是Xb,y的变异数矩阵,也就是变异,是ZGZ' + R
G是随机变量的变异数矩阵(变异),R是e的变异。
如果随机因子间是没有关系的,是直和。如果有关系,则是直积。

3. 随机效应
A random effect is one whose levels are randomly selected from a large population of levels. There is no interest in making inferences about specific levels of a random factor, but rather about any level in general.
group的level是随机的。
举例:在任意剂量中选几个,再选个安慰剂对照,做个试验,剂量组都有效。推论:所有剂量都对人有好处。
这个地方有两个随机效应,一是剂量,而是patient。
重复测量是一种特殊的随机效应:重复测量在个体展开多次测量。说白了就是within-subject factors在所有个体中都是相同的。个体是最基本的研究对象,是在个体基础上搜集数据,展开研究。
例如 res 在VISIT 1 3 5各测一次,或者在Period A测一次,Period B测一次.
3.1 重复测量
随机效应是上述混合线性模型中v。
重复测量的随机效用是within-subject variation。个体内的变异。
而随机效应是between-subject variation。个体间的变异。

一些详细解释可参考这篇文章RANDOM and REPEATED statements - How to Use Them to Model the Covariance Structure in Proc Mixed。
当用GLM算随机效应时:
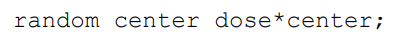
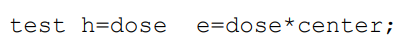
e = dose * center 和 e = dose(center)相同,都是组内误差。
data xover; input pat seq $ trt $ pd y @@; datalines; 1 AB A 1 6 3 AB A 1 8 5 AB A 1 12 6 AB A 1 7 9 AB A 1 9 10 AB A 1 6 13 AB A 1 11 15 AB A 1 8 1 AB B 2 4 3 AB B 2 7 5 AB B 2 6 6 AB B 2 8 9 AB B 2 10 10 AB B 2 4 13 AB B 2 6 15 AB B 2 8 2 BA A 2 7 4 BA A 2 6 7 BA A 2 11 8 BA A 2 7 11 BA A 2 8 12 BA A 2 4 14 BA A 2 9 16 BA A 2 13 2 BA B 1 5 4 BA B 1 9 7 BA B 1 7 8 BA B 1 4 11 BA B 1 9 12 BA B 1 5 14 BA B 1 8 16 BA B 1 9 ; proc glm data = xover; class seq trt pd pat; model y = seq pat*seq trt pd; random seq pat*seq; test h = seq e = pat*seq; **和()作用都相同; /* model y = seq pat(seq) trt pd; */ /* test h=seq e = pat(seq); */ /* random seq pat(seq);*/ run; proc mixed data = xover; class seq trt pd pat; model y = seq pat*seq trt pd; run;
proc glm data = xover; class seq trt pd pat; model y = seq pat*seq trt pd; random seq pat*seq; test h = seq e = pat*seq; run; proc glm data = xover; class seq trt pd pat; model y = seq pat*seq trt pd; test h = seq e = pat*seq; run;
结果完全相同。GLM 程序对随机效果的估计法与 对固定效果的估计法完全一样。
MIXED中固定效应和GLM中随机效应相同。
MIXED的优势在于可以在RANDOM 选项中加上 TYPE = .指定covariance type。

也就是通过TYPE指定随机效应的协方差结构。
本文来自博客园,作者:Iving,转载请注明原文链接:https://www.cnblogs.com/SAS-T/p/15550078.html
