混合模型 - Mixed
混合模型也叫随机模型,多水平模型。
重复测量是多水平模型一个特例。
随机语句通常用于对对象之间的变化进行建模,而重复语句通常用于对对象内的变化进行建模。也就是REPEATED 和 RANDOM语句。
随机效应 VS 固定效应简单介绍了两种效应。
1.
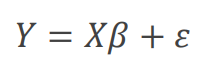
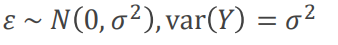
这是线性模型,残差服从均值为0,方差为sigma 2正态分布,Y的方差就是残差。
例如:
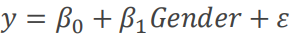
2.
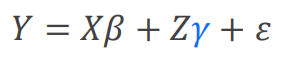
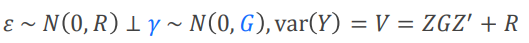
伽马(r)服从均值为0方差为G的正态分布,G就是TYPE=里面指定的方差-协方差结构,就是随机效应变量各个水平之间的相关关系是什么样的。
虽然随机模型和一般线性模型的残差都是epsilon(e),但随机模型中的残差已经减去了随机效应变量的残差(标准差),更精准些;
例如:
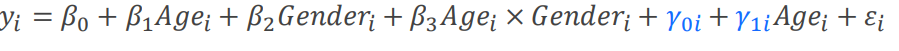
随机截距:即截距不同,斜率相同。
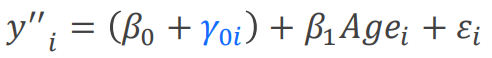
随机斜率:即截距相同,斜率不同。
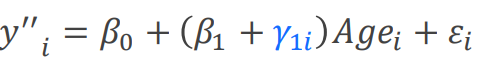
截距和斜率都不同:
![]()
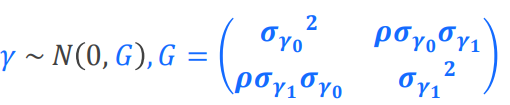
TYPE是指定G矩阵形式:
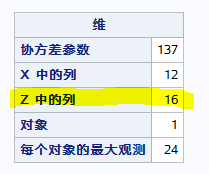
G矩阵:如果TYPE = UN: 两两比较,C16 2 = 120, 加上16个方差,1 个残差,等于 137。因为这是假设任意两个协方差都不一致。
如果TYPE = CS: 协方差全都相同(只有一个),只有一个方差,这是共计1个,再加1个残差,就是2 个参数。
random int age / subject = person type = un;
这是指定随机截距和随机斜率。

本文来自博客园,作者:Iving,转载请注明原文链接:https://www.cnblogs.com/SAS-T/p/15541915.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号