【ABAP系列】SAP ABAP 字符编码与解码、Unicode

前言部分
大家可以关注我的公众号,公众号里的排版更好,阅读更舒适。
正文部分
本文为转载文章
DATA : xstr TYPE xstring .
DATA : l_codepage ( 4 ) TYPE n .
DATA : l_encoding ( 20 ).
********** 字符集名与内码转换
" 将外部字符集名转换为内部编码
CALL FUNCTION 'SCP_CODEPAGE_BY_EXTERNAL_NAME'
EXPORTING
external_name = 'UTF-8'
IMPORTING
sap_codepage = l_codepage .
l_encoding = l_codepage .
********** 编码
DATA : convout TYPE REF TO cl_abap_conv_out_ce .
" 创建编码对象
convout = cl_abap_conv_out_ce => create ( encoding = l_encoding ).
convout -> write ( data = 'matinal测试 ' ). " 编码
xstr = convout -> get_buffer ( ). " 获取码流
WRITE : / xstr . "E6B19FE6ADA3E5869B
********** 解码
DATA : convin TYPE REF TO cl_abap_conv_in_ce .
" 创建解码对象
convin = cl_abap_conv_in_ce => create ( encoding = l_encoding input = xstr ).
DATA : str TYPE string .
CALL METHOD convin -> read " 解码
IMPORTING data = str .
WRITE : / str . " matinal测试
使用CL_ABAP_CODEPAGE类进行编解码:
DATA: xstr TYPE xstring,
str TYPE string,
l_codepage(4) TYPE n ,
l_encoding(20).
**********字符集名与内码转换
"将外部字符集名转换为内部编码
CALL FUNCTION 'SCP_CODEPAGE_BY_EXTERNAL_NAME'
EXPORTING
external_name = 'UTF-8'
IMPORTING
sap_codepage = l_codepage.
WRITE: / l_codepage.
"等同于下面类方法
l_codepage = cl_abap_codepage=>sap_codepage( 'UTF-8' ).
WRITE: / l_codepage.
"编码
xstr = cl_abap_codepage=>convert_to(
source = 'matinal测试'
codepage = `UTF-8` ).
WRITE: / xstr.
"解码
str = cl_abap_codepage=>CONVERT_FROM(
source = xstr
codepage = `UTF-8` ).
WRITE: / str.
4110
4110
E6B19FE6ADA3E5869B
matinal测试
ABAP中的特殊字符列表
cl_abap_char_utilities=>horizontal_tab — 09 TAB符
cl_abap_char_utilities=>CR_LF ———-- 0D0A 回车换行
cl_abap_char_utilities=>VERTICAL_TAB —- 0B 垂直制表符
cl_abap_char_utilities=>NEWLINE —---- 0A 换行
cl_abap_char_utilities=>FORM_FEED —--- 0C 换页
cl_abap_char_utilities=>BACKSPACE —---08 退格符
CL_ABAP_CHAR_UTILITIES=>BYTE_ORDER_MARK_LITTLE-----(utf-16le')的文件头
CL_ABAP_CHAR_UTILITIES=>BYTE_ORDER_MARK_UTF8-------(utf-8)的文件头
如果是要单独取得回车或者换行(不是回车加换行),可以采用:
cl_abap_char_utilities=>CR_LF(1)
cl_abap_char_utilities=>CR_LF 1(1)
空白字符:
System.out.println((int)' ');//12288
DATA: gc_result(50) TYPE c.
CONSTANTS: c_tab TYPE c VALUE cl_abap_char_utilities=>horizontal_tab.
CONCATENATE 'text01' c_tab 'text02' c_tab 'text03' INTO gc_result.
Unicode字符串互转
DATA: c(4) TYPE c VALUE 'ABCD'.
FIELD-SYMBOLS <fs1>.
"将字符串以十六进制的Unicode码来表示
ASSIGN c TO <fs1> type 'X'.
WRITE: / <fs1>.0041004200430044这是在AIX上测试的结果。注意,SAP上使用的是Unicode码,所以为双字节,在转换为十六进制时,与服务器所在操作系统的字节顺有关(Java是与平台无关的,在任何平台上都是高字节序),从这里就可以看出Windows与Unix上的字节序不是一样的。
"====分配时指定类型
DATA: x(8) TYPE x ."这里的8表示8个字节
x = <fs1>.
FIELD-SYMBOLS <fs3> .
"将十六进制的Unicode码转换为字符串
ASSIGN x TO <fs3> type 'C'. "C在这里是一般类型,代指字符串,而不是只一个C
WRITE:/ <fs3>.
"====通过强转
FIELD-SYMBOLS <fs4> TYPE c. "C在这里也是一般类型
ASSIGN x TO <fs4> CASTING.
WRITE:/ <fs4>.
4100420043004400
ABCD
ABCD
JAVA与ABAP中的Unicode
Java与ABAP内存存储字符时,都是以Unicode来编解码的。
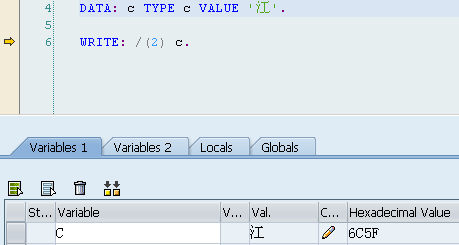
注:平时我们讲的字节序是以字节为单位,字节与字节是有高低之分的,但在某个字节里是没有高低位之分的。就像下面江字那样,在低字节系统中为5F6C,而决不可能出现 F5 或 C6 之类的情况出现。
“江”字的Unicode编码为:27743(十进制),6C5F(十六进制)

从上面可以看出:Java中的Unicode编码是采用高字节序(符合人的阅读习惯),而ABAP中是采用低字节序(符合机器存储结构)(注意,可能与测试的环境有关。经测试,与测试环境确实有关系,请看下面在AIX机器上的测试结果——高字节顺序——高字节在前,低字节在后,符合人的阅读习惯,但与机器存储刚好相反——内存是从左到右字节地址越来越大,即内存前面是低字节,而后面是高字节。正是因为ABAP不像Java那样跨平台,所以在ABAP中可以通过CL_ABAP_CHAR_UTILITIES=>ENDIAN获得当前SAP所在的服务器的字节序类别;但是Java是跨平台的,在任何平台下都是采用上面的高字节序)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号