


HBase —— 入门
HBase —— 入门
HBase介绍
HBase是一个分布式的、面向列的开源数据库,该技术来源于 Fay Chang 所撰写的Google论文“Bigtable:一个结构化数据的分布式存储系统”。就像Bigtable利用了Google文件系统(File System)所提供的分布式数据存储一样,HBase在Hadoop之上提供了类似于Bigtable的能力。HBase是Apache的Hadoop项目的子项目。HBase不同于一般的关系数据库,它是一个适合于非结构化数据存储的数据库。另一个不同的是HBase基于列的而不是基于行的模式。
HBase的架构组件
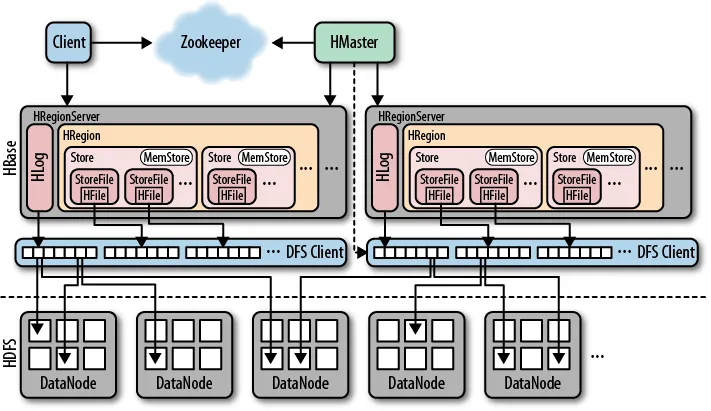
Client
- 客户端负责发送请求到数据库
- 客户端的连接方式主要有两种:hbase shell 和 类JDBC
- 发送的请求也是基本的数据库操作 DDL、DML、DQL
- client还维护着一些cache来加快hbase的访问,例如Region的位置信息
Zookeeper
-
保证任何时候集群只有一个master
-
存储所有Region的寻址入口和所有元数据信息
-
实时监控Region Server的状态,将其上下线信息汇报给Master
-
存储Hbase的schema,包括表和列簇
HMaster
- HBase的主节点,为Region Server分配Region并负责其负载均衡
- 管理用户的DDL操作,表的元数据存储在Zookeeper中,表的数据存储在HRegionServer上
- 当HRegionServer下线时,HMaster会将该HRegionServer上的region转移到其他HRegionServer上
HRegionServer
- HBase具体数据的管理者,维护Master分配给它的region,处理对这些region的IO请求
- 实时和Master保持通信,汇报当前节点信息
- 当接收到master创建一张表的命令时,分配一个region对应一张表
- Region Server 负责切分在运行过程中变得过大的region
- 当客户端发送DML和DQL操作时,HRegionServer负责和客户端连接
- 当前Region Server意外关闭,其region会被其他Region Server接手
HRegion
- HRegion是HBase中分布式存储的最小单元,可存储在不同的HRegionServer中
- HBase自动把表水平划分为多个region,每个region会保存一个表里某一段连续的数据
- 开始一张表只有一个region,当region增大一定程度会发生等分裂变。
Store
- HRegion是表获取和分布的基本元素,由一个或多个Store组成,每个store保存一个列簇
- store又由一个memstore和零个或多个StoreFile组成
- HFile是HBase在HDFS中文件的存储格式,包含多层索引,不必为了一部分数据而加载整个文件
Hlog
- 做任何事情之前先写日志,Hlog实际是一个普通的Hadoop Sequence文件
- Hlog直接存储在HDFS上,一个HRegionServer只有一个log文件
- 当memstore达到阈值开始写出日志文件,会在日志文件中设置一个检查点
- MasterProcWAL:HMaster记录管理操作,WAL记录所有HBase数据改变
HBase的数据模型
数据类型:HBase不存在数据类型,唯一的数据类型就是字节
NameSpace:命名空间是关系数据库中的概念,实际是表的逻辑分组。HBase有两个特殊的命名空间,default和hbase。
Table:
| Row key | Time Stamp | Column Family1 | Column Family2 | Column Family3 |
|---|---|---|---|---|
| 1 | t6 | CF2:q1=val1 | CF3:q3=val3 | |
| 2 | t3 | CF1:q2=val3 | ||
| t2 | CF2:q3=val2 |
Row Key
- 一行的唯一标识,是用来检索记录的主键。
- 行键可以是任意字符串,最长64kb,以字节数组保存
- 存储是按照行键的字典序(byte order)进行排序。设计时一般将会一起被读取的行放在一起。
Column Family
- 每一行都有相同的列簇,列簇包含许多列与列的值,每个列簇都有一些存储属性可配置。
- 例如:可使用存储、压缩类型、存储版本号。
- 将功能属性相近的放在同一个列簇,而同一个列簇的列会存储在同一个Store中。
- 列簇一般在创建表的时候就声明,一般不要超过三个。
- 列簇由多个列组成,表由多个列簇组成。
Column Qualifier
- 列簇的限定词,可以理解为唯一标识,但是列标识时可改变的,所以每一行可以有不同的列标识。
- 使用方式必须为,列簇: 列
- 列可以根据需求动态添加或删除,同一个表中不同行的数据列都可以不同。
Cell
- cell由row key、column family、column qualifier、version组成
- cell中数据没有类型,全部由字节存储
Time Stamp
- HBase中每个cell存储着同一份数据的不同版本。
- 版本通过时间戳来索引:
- 时间戳的类型是64位整型
- 时间戳精确到毫秒,不自行设置默认为系统当前时间
- 若应用程序想要避免版本冲突,就需要自己生成具有唯一性的时间戳
- 每个cell中不同版本的数据按照时间倒序排序,最新的排在最前
- 查询时不指定时间戳,则默认显示最新数据
- 为了避免数据存在过多版本难以管理,采用保存最后n个版本或保存最后一段时间内的版本的方式。
安装HBase
上传解压安装包
scp hbase压缩包 用户@机器IP:/上传/目录
tar -xzvf hbase压缩包 -C /解压/目录
修改配置文件
修改hbase-env.sh:
cd hbase-2.4.13/conf/
vim hbase-env.sh
export JAVA_HOME=/JDK安装路径
export HBASE_MANAGES_ZK=false
修改hbase-site.xml:
vim hbase-site.xml
<property>
<name>hbase.rootdir</name>
<value>hdfs://192.168.19.5:8020/hbase</value>
</property>
<!--false单机模式、true分布式-->
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<!--zookeeper位置-->
<property>
<name>hbase.zookeeper.quorum</name>
<value>192.168.19.5:2181</value>
</property>
<!--zookeeper快照存储位置-->
<property>
<name>hbase.zookeeper.property.dataDir</name>
<value>/home/sjj/install/apache-zookeeper-3.7.1-bin/data</value>
</property>
<property>
<name>hbase.unsafe.stream.capability.enforce</name>
<value>false</value>
</property>
配置环境变量
vim /etc/profile
# 配置HBase环境
export HBASE_HOME=/home/sjj/install/hbase-2.4.13
export PATH=$PATH:${HBASE_HOME}/bin:${HBASE_HOME}/sbin
source /etc/profile
复制jar包到lib
cd hbase-2.4.13/lib/client-facing-thirdparty
cp htrace-core4-4.2.0-incubating.jar ../lib
修改regionservers
cd hbase-2.4.13/conf
vim regionservers
你的节点机器
分发HBase包
scp -r hbase包 用户名@机器IP:/分发/目的地
分发完之后记得还要为分发的机器设置环境变量
启动HBase
# 注意要先启动zookeeper
start-dfs.sh
start-hbase.sh
hbase shell


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 10年+ .NET Coder 心语 ── 封装的思维:从隐藏、稳定开始理解其本质意义
· 提示词工程——AI应用必不可少的技术
· 地球OL攻略 —— 某应届生求职总结
· 字符编码:从基础到乱码解决
· SpringCloud带你走进微服务的世界