


python爬虫-CrawlSpider的全站数据爬取
了解CrawlSpider
CrawlSpider是Spider的子类
它的创建方式是:
scrapy genspider -t crawl spiderName www.xxx.com
创建爬虫文件成功后,我们可以看到它和Spider最大的不同就是多了一个Rule
from scrapy.linkextractors import LinkExtractor
from scrapy.spiders import CrawlSpider, Rule
rules = (
Rule(LinkExtractor(allow=r'Items/'), callback='parse_item', follow=True),
)
Rule:规则解析器
LinkExtractor:链接提取器
follow:能将新的请求网址也进行链接提取,以此来进行全站数据爬取。
链接提取器
根据指定规则提取链接
其中 allow='正则表达式' 来指定规则
规则解析器
将链接提取器提取到的链接进行指定规则的解析操作
其中 callback 来指定解析规则
使用CrawlSpider进行全站数据爬取
我们以 爬取w3school上所有技术的简介 为例
观察网页
我们可以看见每一种技术都是在 /x.asp 链接下,所以这个就可以作为我们提取链接的规则

我们进入其中一个页面,可以看见,技术的简介位置。我们可以根据这个层级进行数据解析
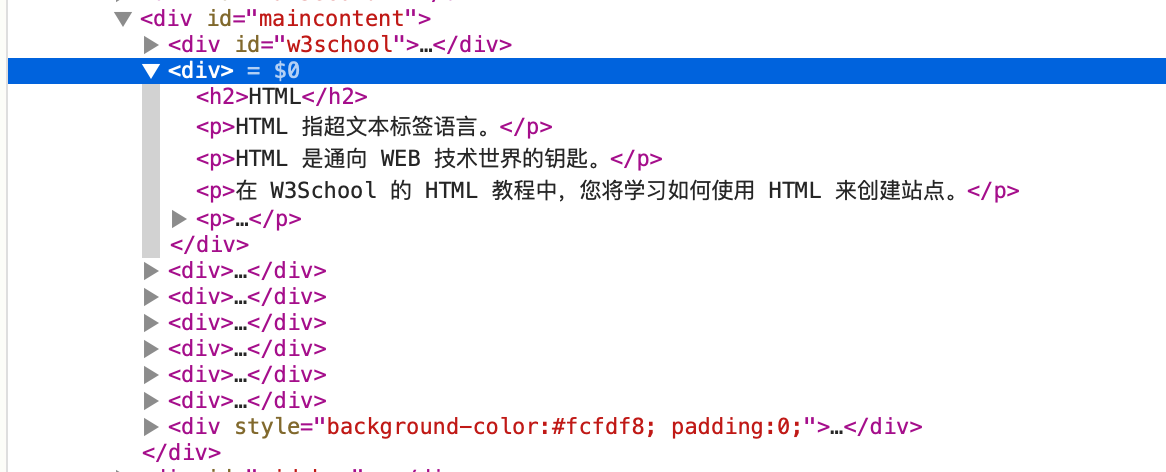
编写代码
"""
获取w3school每个技术的简介
"""
import scrapy
from scrapy.linkextractors import LinkExtractor
from scrapy.spiders import CrawlSpider, Rule
class TestSpider(CrawlSpider):
name = 'test'
# allowed_domains = ['www.xxx.com']
start_urls = ['https://www.w3school.com.cn']
rules = (
Rule(LinkExtractor(allow=r'/[a-z].asp'), callback='parse_item', follow=False),
)
def parse_item(self, response):
item = {}
# item['domain_id'] = response.xpath('//input[@id="sid"]/@value').get()
# item['name'] = response.xpath('//div[@id="name"]').get()
# item['description'] = response.xpath('//div[@id="description"]').get()
text_list = response.xpath('//*[@id="maincontent"]/div//text()').extract()
text_list = ''.join(text_list)
print(text_list)
既然我们能够获取简介,那么继续编写详情页的链接提取规则和数据解析方法,我们就能够获取更详细的数据
分类:
网络爬虫


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 分享一个免费、快速、无限量使用的满血 DeepSeek R1 模型,支持深度思考和联网搜索!
· 25岁的心里话
· 基于 Docker 搭建 FRP 内网穿透开源项目(很简单哒)
· ollama系列01:轻松3步本地部署deepseek,普通电脑可用
· 按钮权限的设计及实现