

hadoop入门(13):NameNode、SecondaryNameNode剖析
NameNode、SecondaryNameNode解析
- NameNode主要负责集群当中元数据信息管理,而且元数据需要经常随机访问,因为元数据信息必须高效的检索。
- 为了保证元数据信息的快速检索,元数据信息必须放在内存中,因为内存中的元数据能够最快速的检索,随着元数据信息的增多(每个block块大约150字节的元数据),内存的消耗也会越来越多。
- 如果所有元数据都存放在内存中,服务器断电,内存中所有数据都丢失,为了保证元数据安全持久,元数据信息必须做可靠的持久化。
- 在hadoop中为了持久化存储元数据信息,将所有元数据信息都存放在FSImage文件中。随着时间的推移FSImage必然越来越膨胀,FSImage的操作会越来越困难,为了解决元数据嘻嘻的增删改,hadoop当中还引入了了元数据操作日志文件edits,edits文件记录客户端操作元数据的信息。但是随着时间的推移,edits文件越会越来越膨胀,于是hadoop当中还引入secondarynamenode来专门做fsimage和edits文件的合并。
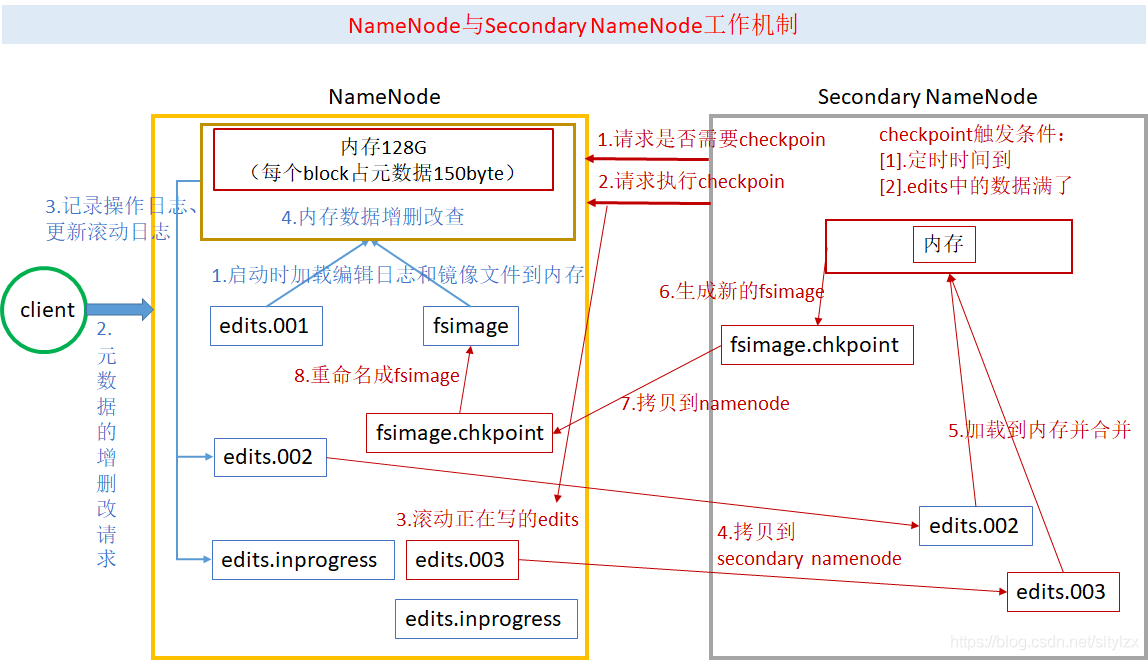
namenode工作机制
- 将映像文件载入内存
- 执行编辑日志中各种编辑操作
- namenode将内存元数据生成新的镜像文件滚动生成新的日志文件,此时间为time1
- hdfs增删改操作
hdfs dfs -put xxx.avi - 记录操作日志
- 内存中更新元数据
secondarynamenode工作机制
- 每分钟检查一次namenode,距离上次checkpoint是否超过一小时,edits_inprogress事务是否超出100万
- 请求执行checkpoint
- 滚动生成新的日志文件;原inprogress文件重命名(文件名后缀表示包含的事务)
- 通过
http get拉取fsimage、edits日志 - fsimage加载到内存;执行edits编辑操作
- 生成合并的镜像文件fsimage_num.ckpt
http post将镜像文件回传到namenode- 将镜像文件重命名fsimage_num;更新checkpointshijian为time2
FSImage和edits详解
- 所有元数据都保存在FSImage文件和edits文件中,配置在hdfs-site.xml文件中
<!-- fsimage文件目录 -->
<property>
<name>dfs.namenode.name.dir</name>
<value>file:///hadoop安装路径……/hadoop-x.x.x/hadoopDatas/namenodeDatas<value>
</property>
<!-- edits文件目录 -->
<property>
<name>dfs.namenode.edits.dir</name>
<value>file:///hadoop安装路径……/hadoop-x.x.x/hadoopDatas/dfs/nn/edits<value>
</property>
- 客户端对hdfs写文件首先会被记录到edits文件夹中,edits修改时也会更新。每次hdfs更新时都会先更新edits,客户端才会看到新信息。
- fsimage是namenode中关于元数据的镜像,一般称为检查点。
# fsimage帮助信息
hdfs oiv
# edits帮助信息
hdfs oev
namenode元数据多目录配置
为了确保元数据的安全性,我们一般先确定好我们的磁盘挂载目录,将元数据的磁盘做RAID1 namenode的本地目录可以配置成多个,且每个目录存放的内容相同,增加可靠性。
多个目录逗号分隔。
hdfs-site.xml中的相关配置
<property>
<name>dfs.namenode.name.dir</name>
<value>
file:///xxx/hadoop/hadoopDatas/namenodeDatas,
file:///path/to/anthor/
<value>
</property>


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· Manus的开源复刻OpenManus初探
· AI 智能体引爆开源社区「GitHub 热点速览」
· 从HTTP原因短语缺失研究HTTP/2和HTTP/3的设计差异
· 三行代码完成国际化适配,妙~啊~