

hadoop入门(2):为三台CentOS安装Hadoop集群
操作前说明
-
环境
| 机器名 | IP | 用户 |
|---|---|---|
| node001 | 192.168.77.110 | hadoop |
| node002 | 192.168.77.120 | hadoop |
| node003 | 192.168.77.130 | hadoop |
-
要求
- 三台机器之间可通信、可免密登录
- 三台机器时间同步
- 三台机器Java环境已配置好
-
部署目标
| 服务器IP | node001 | node002 | node003 |
|---|---|---|---|
| HDFS | NameNode | ||
| HDFS | SecondaryNameNode | ||
| HDFS | DataNode | DataNode | DataNode |
| YARS | ResourceManager | ||
| YARS | NodeManager | NodeManager | NodeManager |
| 历史日志服务器 | JobHistoryServer |
获取压缩包
-
官网个人并不推荐(太慢了,各位还是在有资源的前辈们那里拿一下吧)
第一台机器
1. 传输到第一台机器
- 方法一: 使用终端管理软件传输
- 方法二: 使用ssh+scp远程传输
scp 被传输文件路径 机器用户@机器ip:传输到机器的路径
2. 解压到指定目录
tar -xvf hadoop-3.2.2.tar -C /sjj/install/
- 因为我是.tar文件 所以是
-xvf - 如果是.tar.gz文件 需要是
-zvxf
3. 查看解压是否到位
cd /sjj/install
ls

配置🌟🌟🌟🌟🌟(集群失败的很多原因的在这里
1. hadoop目录下操作
-
进入目录
cd /sjj/install/hadoop-3.2.2
ls

-
可以删除share中的doc文件夹里面的东西并不重要
cd share/
ls
rm -rf doc/ -
执行checknative文件
cd /sjj/install/hadoop-3.2.2
bin/hadoop checknative
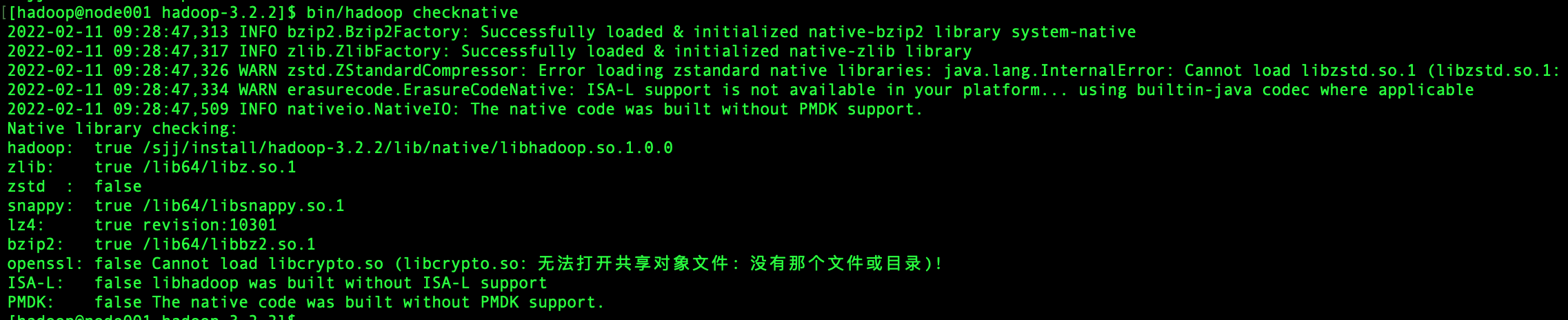
可以看见openssl为false,我们在线下载一个
注意三台机器都要安装
sudo yum -y install openssl-devel
2. 修改配置文件
第一台机器下执行
- 进入配置文件的文件夹
cd /sjj/install/hadoop-3.2.2/etc/hadoop/ -
修改Hadoop-env.sh
vim hadoop-env.sh
/JAVA_HOME进行搜索
找到以下配置添加,要是你自己的jdk版本
export JAVA_HOME=/sjj/install/jdk1.8.0_321 -
修改core-site.xml
vim core-site.xml
添加下面配置
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://node001:8020</value>
</property>
<!--运行文件存储目录-->
<property>
<name>hadoop.tmp.dir</name>
<value>/sjj/install/hadoop-3.2.2/hadoopDatas/tempDatas</value>
</property>
<!--缓冲区大小,默认2048,实际动态调整 -->
<property>
<name>io.file.buffer.size</name>
<value>2048</value>
</property>
<!--hdfs开启垃圾桶机制-->
<property>
<name>fs.trash.interval</name>
<value>10080</value>
</property>
</configuration>
-
修改hdfs-site.xml
vim hdfs-site.xml
添加以下配置
<configuration>
<!--集群动态上下线
<property>
<name>dfs.hosts</name>
<value>/sjj/install/hadoop-3.2.2/etc/hadoop/accept_host</value>
</property>
<property>
<name>dfs.hosts.exclude</name>
<value>/sjj/install/hadoop-3.2.2/etc/hadoop/deny_host</value>
</property>
-->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>node001:9868</value>
</property>
<property>
<name>dfs.namenode.http-address</name>
<value>node001:9870</value>
</property>
<!-- namenode保存fsimage的路径 -->
<property>
<name>dfs.namenode.name.dir</name>
<value>file:///sjj/install/hadoop-3.2.2/hadoopDatas/namenodeDatas</value>
</property>
<!-- 定义dataNode数据存储的节点位置,实际工作中,一般先确定磁盘挂载目录,然后多个目录用,进行分割 -->
<property>
<name>dfs.datanode.data.dir</name>
<value>file:///sjj/install/hadoop-3.2.2/hadoopDatas/datanodeDatas</value>
</property>
<!-- namenode保存editslog的目录 -->
<property>
<name>dfs.namenode.edits.dir</name>
<value>file:///sjj/insatll/hadoop-3.2.2/hadoopDatas/dfs/nn/edits</value>
</property>
<!-- secondarynamenode保存待合并的fsimage -->
<property>
<name>dfs.namenode.checkpoint.dir</name>
<value>file:///sjj/install/hadoop-3.2.2/hadoopDatas/dfs/snn/name</value>
</property>
<!-- secondarynamenode保存待合并的editslog -->
<property>
<name>dfs.namenode.checkpoint.edits.dir</name>
<value>file:///sjj/install/hadoop-3.2.2/hadoopDatas/dfs/nn/snn/edits</value>
</property>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.permissions.enabled</name>
<value>false</value>
</property>
<property>
<name>dfs.blocksize</name>
<value>134217728</value>
</property>
</configuration>
-
修改mapred-site.xml
vim mapred-site.xml
t添加以下配置
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.job.ubertask.enable</name>
<value>true</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>node001:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>node001:19888</value>
</property>
<property>
<name>yarn.app.mapreduce.am.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
<property>
<name>mapreduce.map.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
<property>
<name>mapreduce.reduce.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
</configuration>
-
修改yarn-site.xml
vim yarn-site.xml
添加以下配置
<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>node001</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
-
修改workers
vim workers
替换localhost为以下配置
node001
node002
node003
创建文件存放目录
node001上操作
mkdir -p /sjj/install/hadoop-3.2.2/hadoopDatas/tempDatas
mkdir -p /sjj/install/hadoop-3.2.2/hadoopDatas/namenodeDatas
mkdir -p /sjj/install/hadoop-3.2.2/hadoopDatas/datanodeDatas
mkdir -p /sjj/install/hadoop-3.2.2/hadoopDatas/dfs/nn/edits
mkdir -p /sjj/install/hadoop-3.2.2/hadoopDatas/dfs/snn/name
mkdir -p /sjj/install/hadoop-3.2.2/hadoopDatas/dfs/nn/snn/edits
安装包分发
-
进入hadoop-3.2.2所在目录
cd /sjj/install
1. scp全量分发
scp -r hadoop-3.2.2/ node002:$PWD
scp -r hadoop-3.2.2/ node003:$PWD
2. 使用rsync等工具增量分发(这里不介绍
修改hadoop的环境变量
三台机器都要操作
sudo vim /etc/profile
末尾添加配置
export HADOOP_HOME=/sjj/install/hadoop-3.2.2
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
保存退出,让配置生效
source /etc/profile
格式化集群
仅首次执行需要,node001执行一遍就行
hdfs namenode -format
或
hadoop namenode -format
日志中显示succssfully表示成功

集群启动
1. 启动HDFS、YARS、Historyserver
-
前提:配置了workers和ssh免密登录
-
在主节点node001执行命令
start-dfs.sh
start-yarn.sh
mapred --daemon start historyserver -
停止集群
stop-dfs.sh
stop-yarn.sh
mapred --daemon stop historyserver
2. 单个进程逐个启动
hdfs --daemon start xxx
yarn --daemon start xxx
如果要停止satrt换成stop即可
验证
全部启动后输入jps查看是否启动
要求和部署目标一致
-
Namenode information 192.168.77.110:9870
-
All Applications 192.168.77.110:8088
-
JobHistory 192.168.77.110:19888
-
DataNode
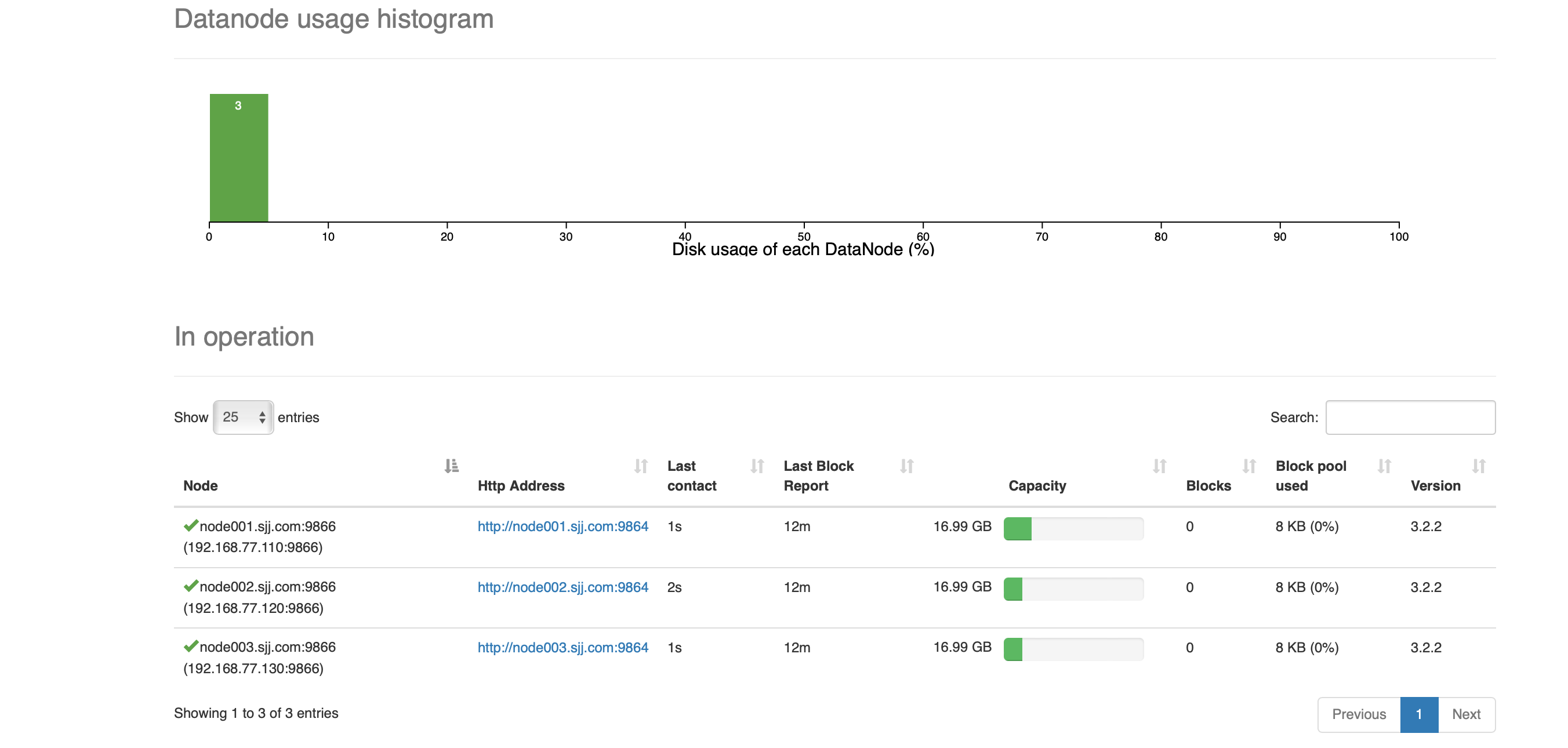
-
JobHistory
-
All Applications
最后
关闭顺序一定要是 hadoop集群->虚拟机->电脑
不然很容易出问题
分类:
Hadoop


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 单元测试从入门到精通
· 上周热点回顾(3.3-3.9)
· winform 绘制太阳,地球,月球 运作规律