03-程序的机器级表示
在编译结束、汇编开始之前,会生成.s程序,这个程序中存放的是代码到汇编的汇编指令。然后再将.s文件通过汇编器生成.o二进制文件。我们来做个实验看看一个代码编程汇编是什么样子,然后二进制.o文件通过objdump反汇编后是什么样子(这里需要说明一下,objdump是一个反汇编工具。汇编器将汇编代码翻译成二进制的机器代码,机器代码无法被查看,那么反汇编器就是将机器代码翻译成汇编代码)
long mult2(long, long);
void mulstore(long x, long y, long *dest) {
long t = mult2(x, y);
*dest = t;
}
如上实例代码通过gcc指令编译生成.s汇编代码:
gcc -Og -S mstore.c
生成汇编.s代码如下:

其中以.开头的都是汇编链接相关的伪指令,我们将其忽略,剩余的代码即为逻辑相关:

pushq指令执行的操作是,将寄存器rbx的值压栈,并且栈顶指针由高地址向低地址偏移:
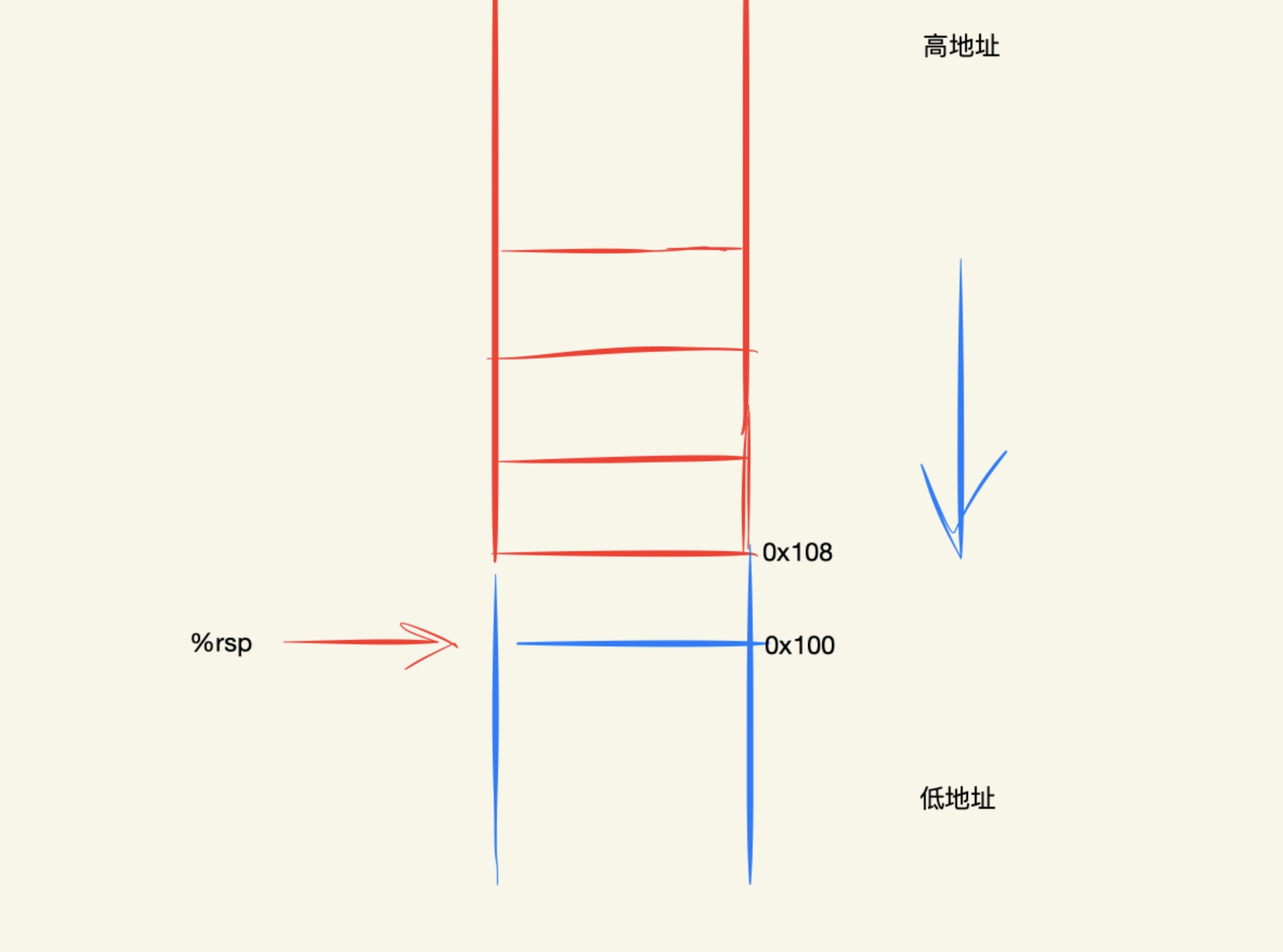
如上图,pushq %rbx等价于:
subq $8, %rsp
movq %rbx, (%rsp)
首先给栈指针减去直接数8,即让地址发生一个字偏移,然后将需要存放的值由rbx寄存器移动至rsp栈指针指向的区域。程序之所以将rbx寄存器的值压栈,主要是进行保存操作,以便于汇编代码执行完毕后恢复rbx的值,如上述代码中的popq %rbx,将栈顶元素弹出。
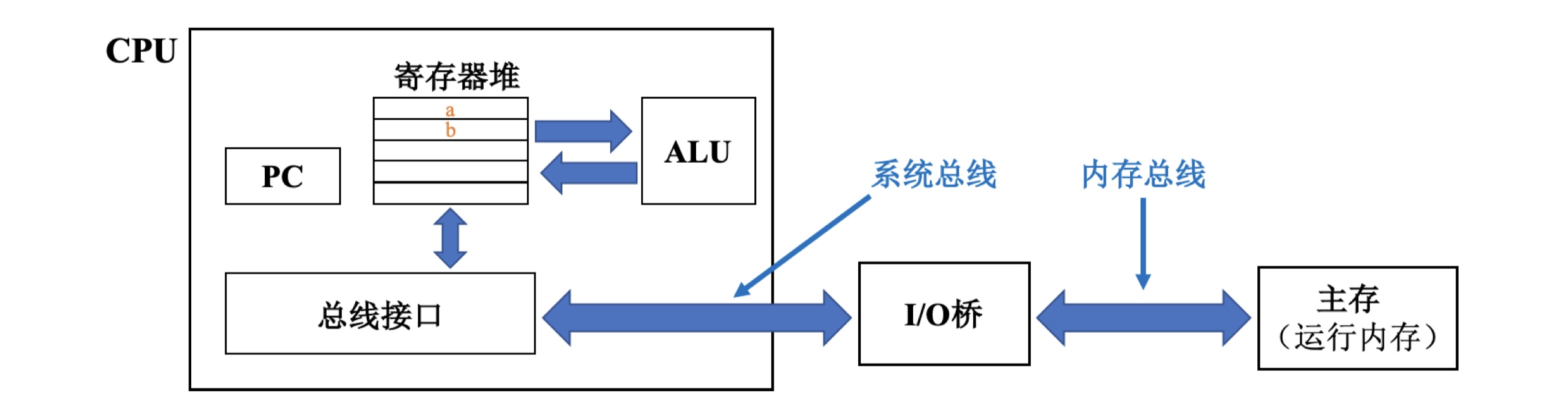
关于汇编,需要补充说明一些内容,在Inter x86-64的处理器中包含了16个通用目的的寄存器,这些寄存器用来存放整数数据和指针。分别如下:

可以看到16个寄存器名字均以%r开头,在详细介绍寄存器的功能之前,我们首先需搞清楚两个概念:调用者保存寄存器和被调用者保存寄存器。
程序中经常会有某个函数调用另一个函数,那么发起调用的就是调用者,被调用的函数就是被调用者。
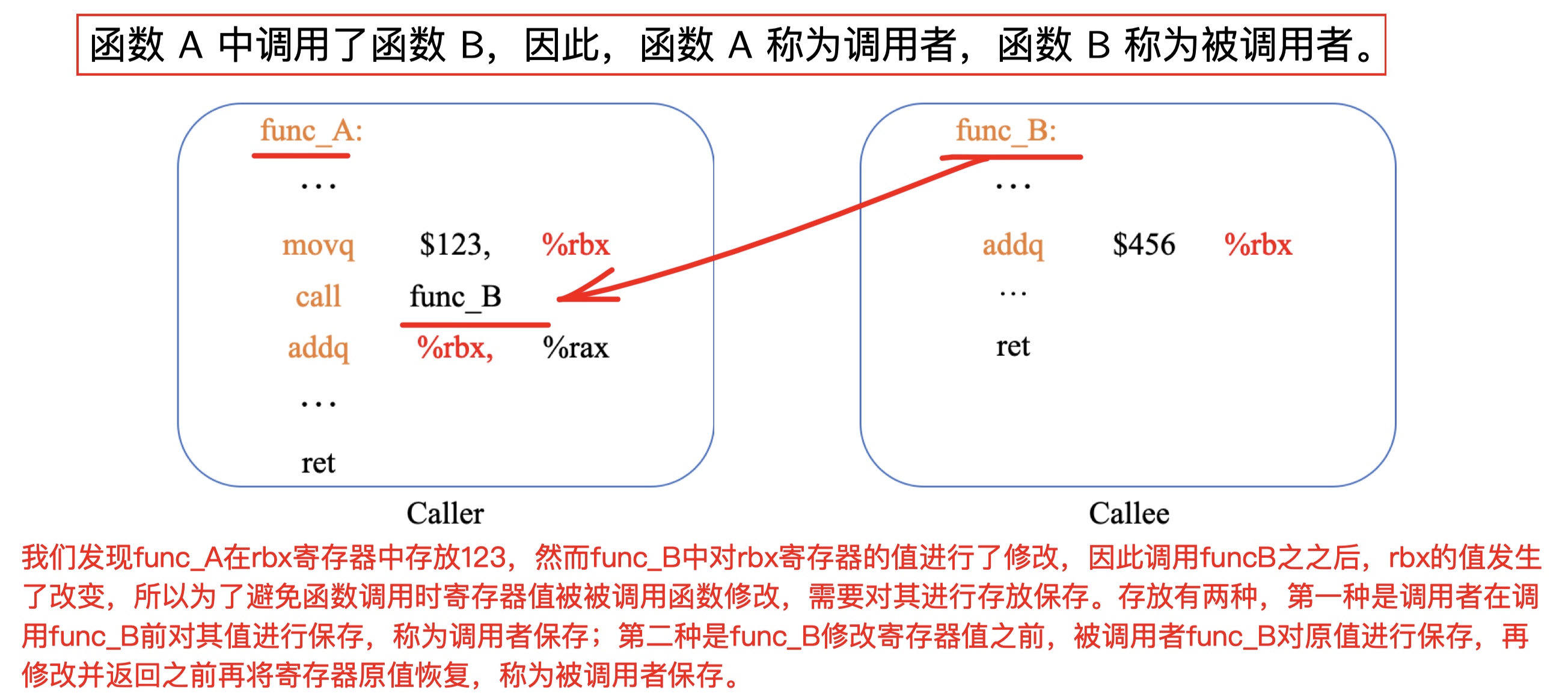
上图理论上提到了有两种保存方式,调用者保存和被调用者保存,通常由于寄存器的数量是有限的,我们在对某个函数进行调用的时候,被调用的函数可能也会使用寄存器,因此寄存器在源调函数中的值可能会被覆盖修改,所以我们需要保存相关值,保存方法如下:

对于具体使用调用者保存寄存器还是被调用者保存寄存器的方式,不同的寄存器有不同的措施,以下是使用调用者保存寄存器和被调用者保存寄存器策略的划分:

实际上rbx寄存器只能使用被调用者保存寄存器的策略,回到刚才的代码可以看到:

上面的代码中,相对于main函数而言,mulstore函数是被调用者,当进入被调用者时,后续的一系列操作都将可能对rbx寄存器进行修改,因此我们会首先将rbx寄存器的值入栈,然后再程序返回前通过popq %rbx将栈顶元素弹出至rbx寄存器中,达到恢复的目的。我们可以看到第二句执行了movq指令,将寄存器rdx中的值存放至rbx中,那有同学就要问了,我们怎么知道我们要去操作rdx寄存器呢?为什么不能是rsi寄存器或者rax寄存器?如果有这样的问题,说明对每个寄存器特定功能不了解,接下来我们先去了解几个主要寄存器的功能:
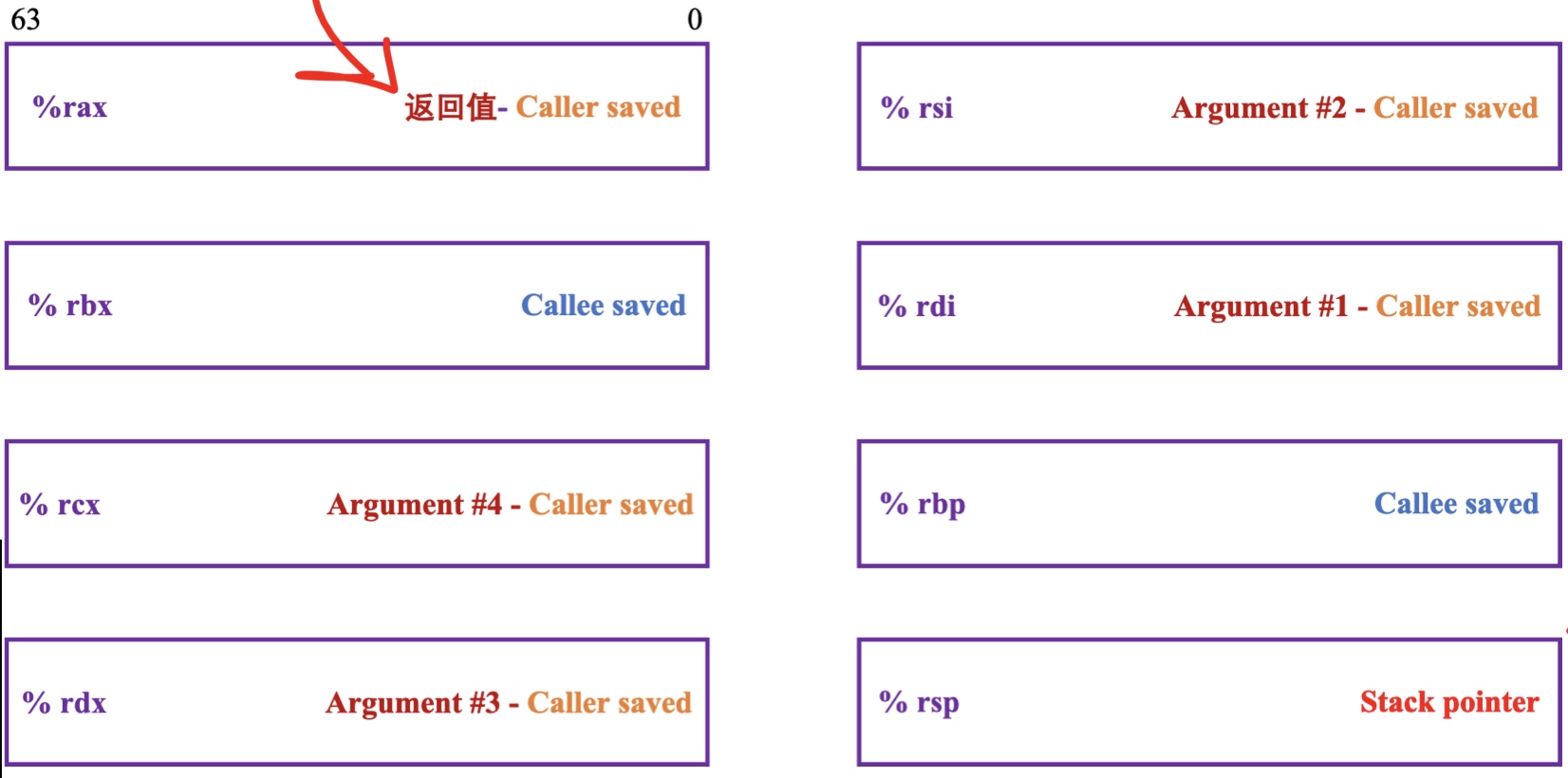
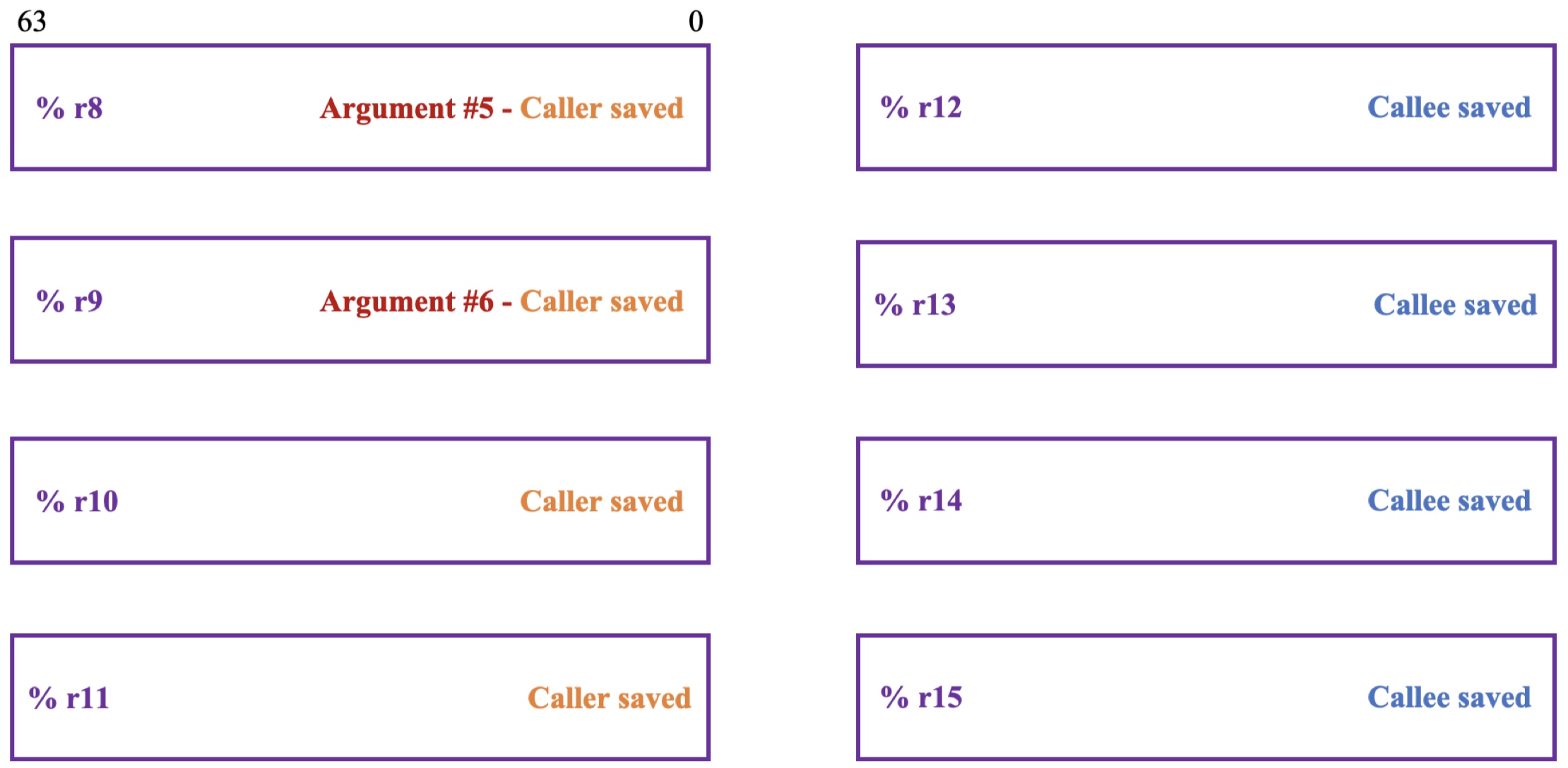
可以看到rax一般用于存放要返回的值,rdi、rsi、rdx、rcx、r8、r9分别用于存放当前函数的六个参数值,这七个寄存器均采用调用者保存寄存器策略,rsp寄存器在上面提到过,是栈顶指针寄存器。
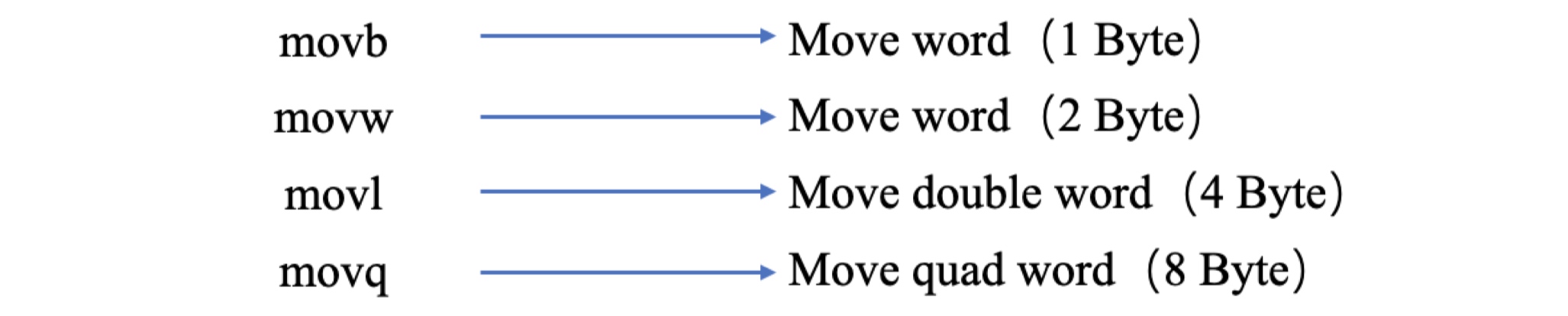
指令通常都有后缀,如pushq中的q,代表着8字节,更多汇编码后缀如下图所示:
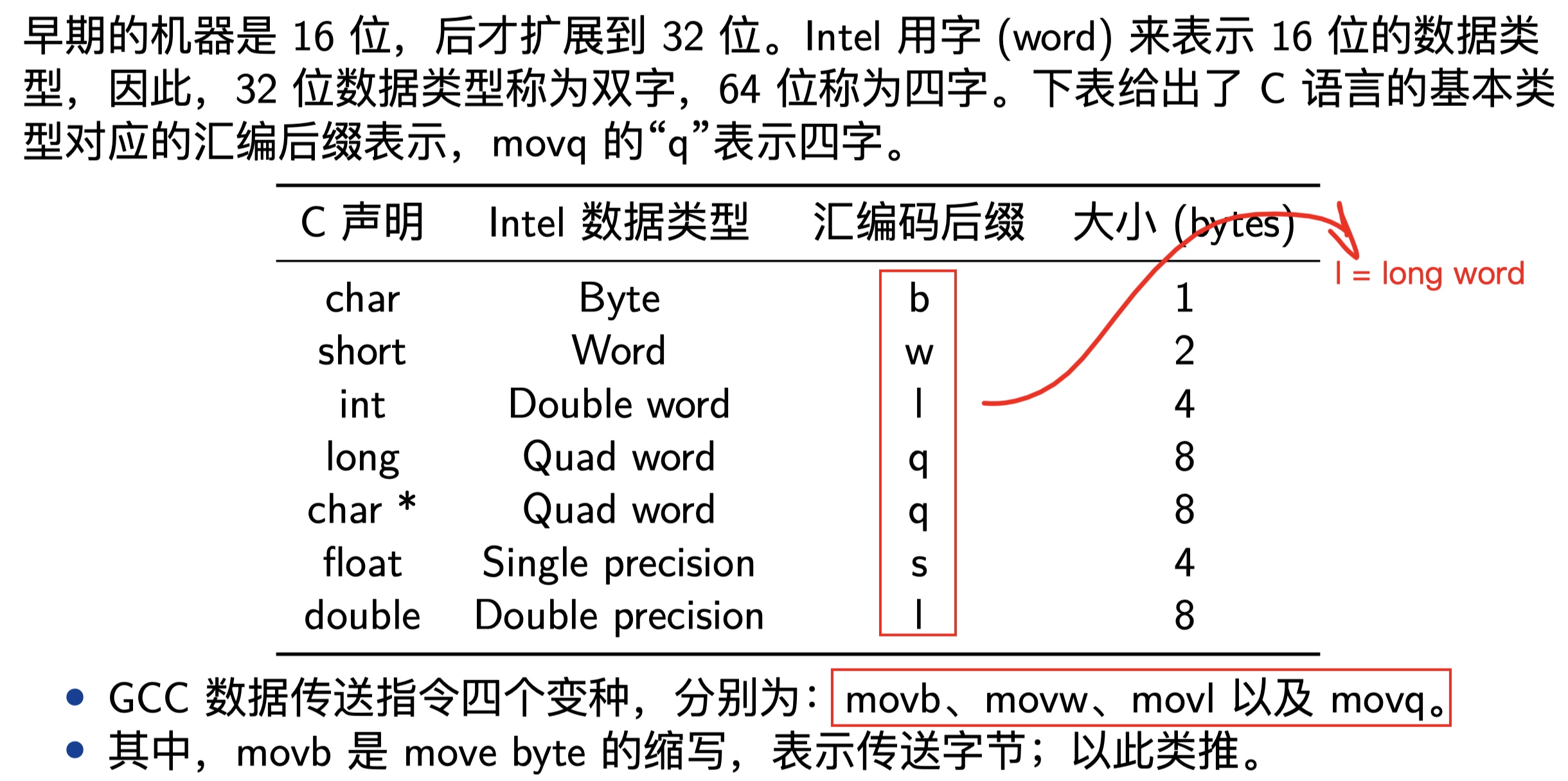
继续分析我们的代码,根据上面不同寄存器具有不同功能得知,mulstore函数的三个参数分别保存至rdi、rsi、rdx中:

那么call则是调用mult2函数,可以看到rbx寄存器外加了括号,这类似C语言中指针解引用,说明rbx存放的是地址,我们通过地址寻找到具体地址中存放的值,即代码中dest指针指向的值,然后将rax寄存器的值移动至rbx中,rax存放着mult2函数的返回值。最终将rbx寄存器通过popq恢复。
一开始提到objdump反汇编操作,首先通过gcc -Og -c mstore.c生成mstore.o二进制机器代码文件,然后通过objdump -d mstore.o将二进制机器代码反汇编至汇编代码,具体结果如图,在我的CentOS 7.3中贴图如下:


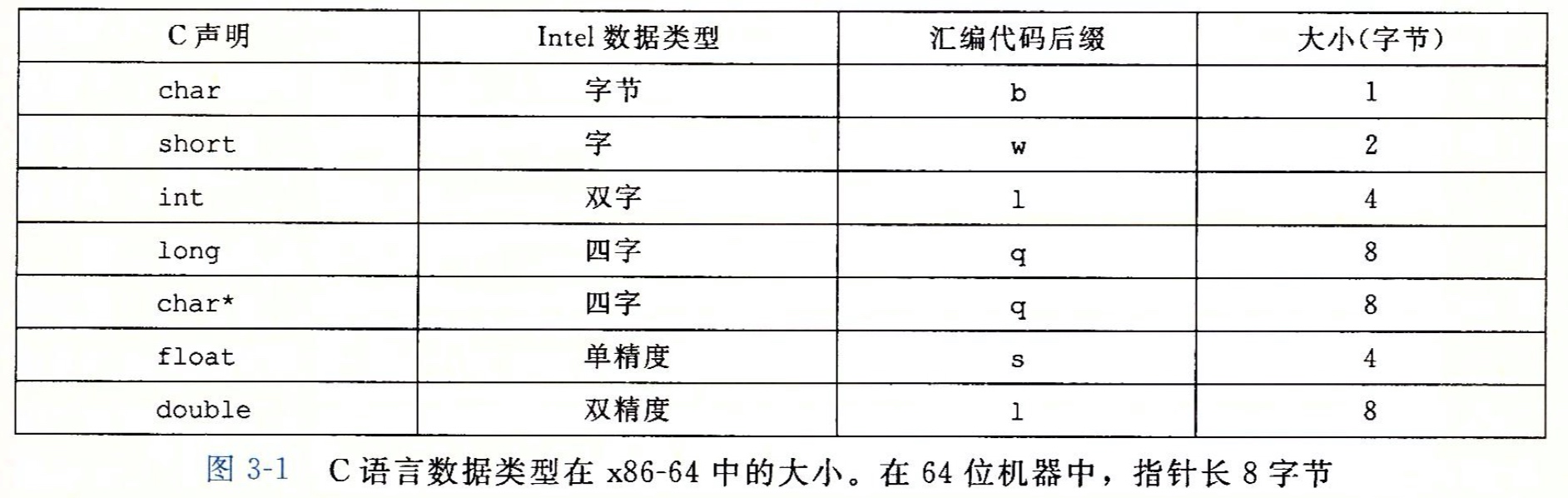
寄存器指令,大多数指令包含两部分:操作码和操作数。大多数指令具有一个或多个操作数,ret返回指令则没有操作数。在AT&T格式汇编中,立即数以$符号开头,后跟一个C语言定义的整数。操作数是寄存器的情况,即使在64位的处理器上,不仅64位的寄存器可以作为操作数,32位、16位甚至8位的寄存器都可以作为操作数。3寄存器带小括号表示内存引用。我们通常将内存抽象成一个字节数组,当需要从内存中存取数据时,需要获得目的数据的起始地址addr,以及数据长度b。为了简便,通常会省略下标b。
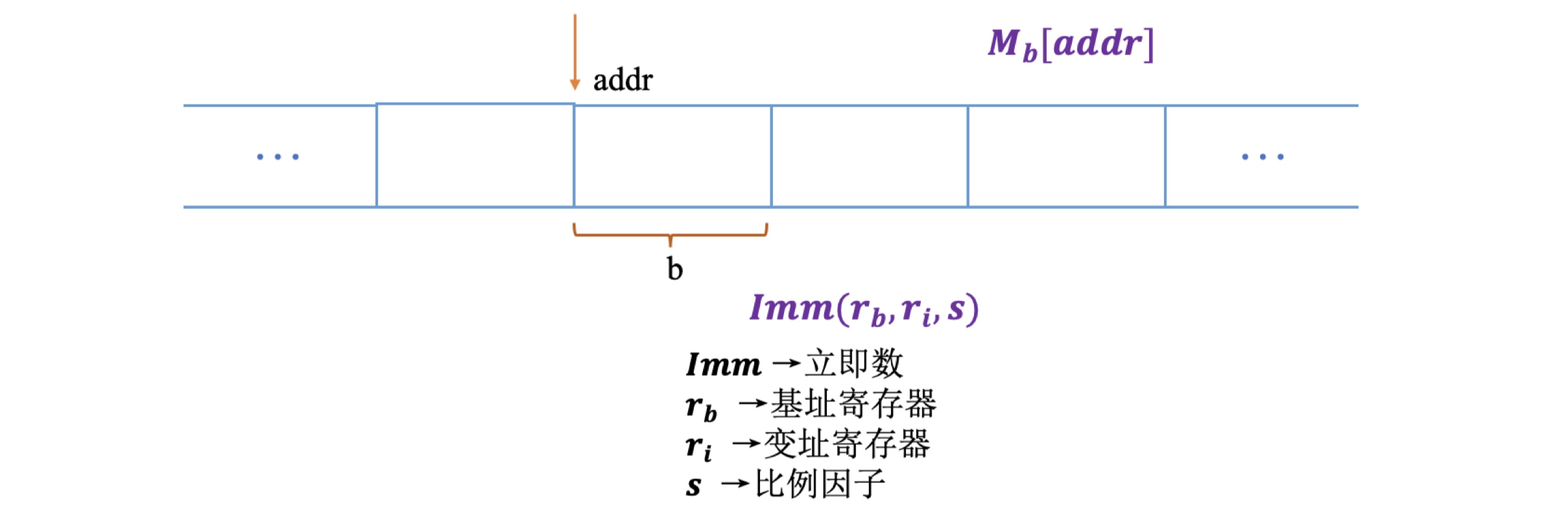
有效地址是通过立即数与基址寄存器的值相加,再加上变址寄存器与比例因子的乘积。
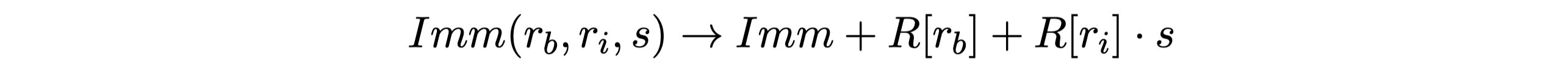
需要注意,比例因子s取值必须是1、2、4、8。实际上比例因子的取值是与源代码中定义的数组类型的是相关的,编译器会根据数组的类型来确定比例因子的数值,例如:定义char类型的数组,比例因子就是1,int类型,比例因子就是4,至于double类型比例因子就是8。
寻址方式
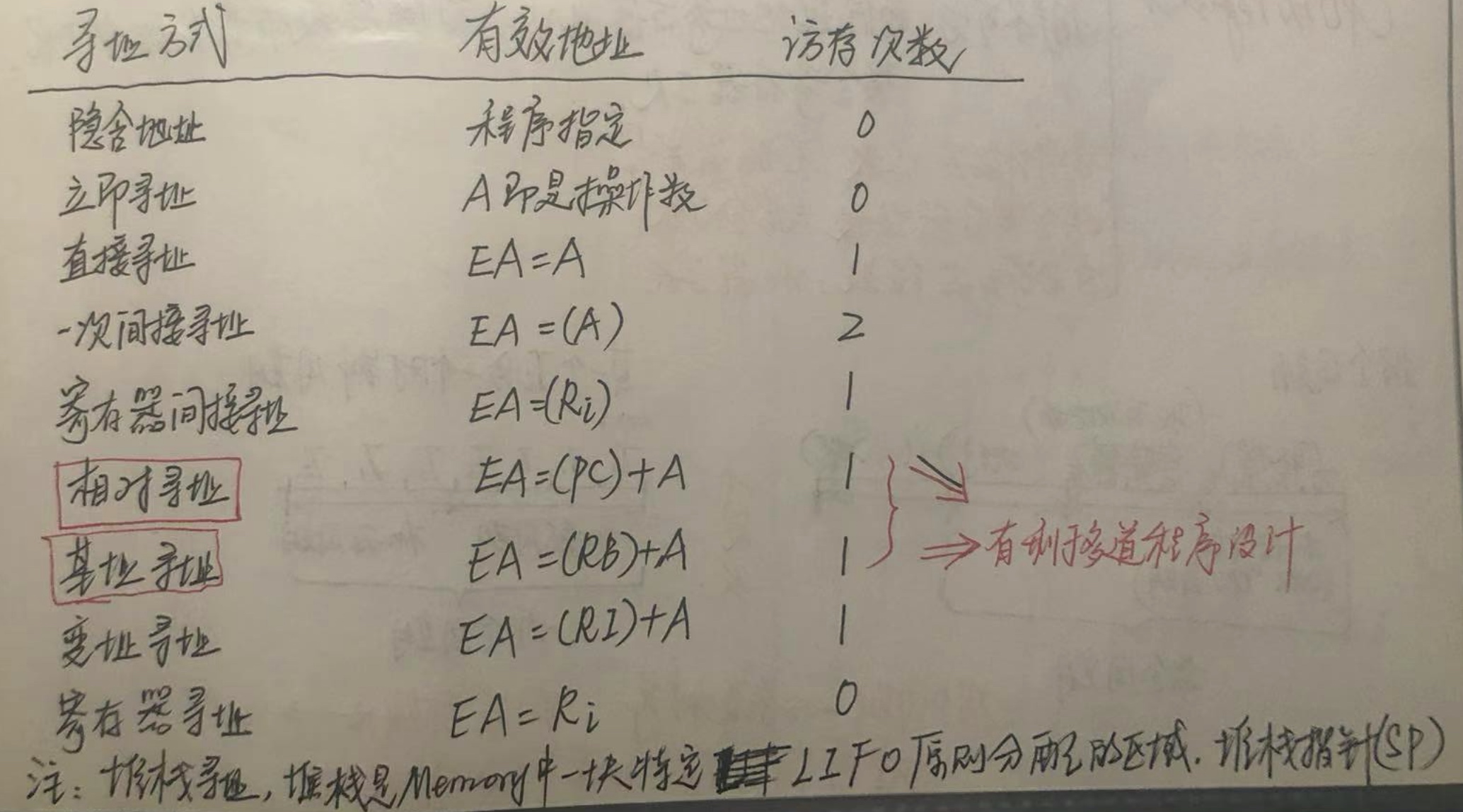
上图中,RB是基址寄存器、RI是变址寄存器。
mov指令
mov含有两个操作数,一个是源操作数,另一个是目的操作数。源操作数可以是立即数、寄存器、内存引用等。目的操作数是用来存放源操作数内容的,因此目的操作数可为寄存器或内存引用等,目的操作数不能是立即数。我们在mov指令后经常看到movq、movw、movb等的形式,代表移动的位数,指令mov的后缀一定要和寄存器的大小进行匹配,如果是32位寄存器,就需要movl;如果是64位寄存器,就需要movq:
需要注意,x86_64处理器有一条限制,mov指令的源操作数和目的操作数不能都是内存的地址,当需要将一个数从内存的一个位置复制到另一个位 置时,需要两条mov指令来完成;第一条指令将内存源位置的数值加载到寄存器;第二条指令再将该寄存器的值写入内存的目的位置。

mov指令源操作数是立即数Imm时,立即数只能32位补码,对该32位源操作数进行符号位扩展,传送至64位目的位置(可以是寄存器也可以是内存)。
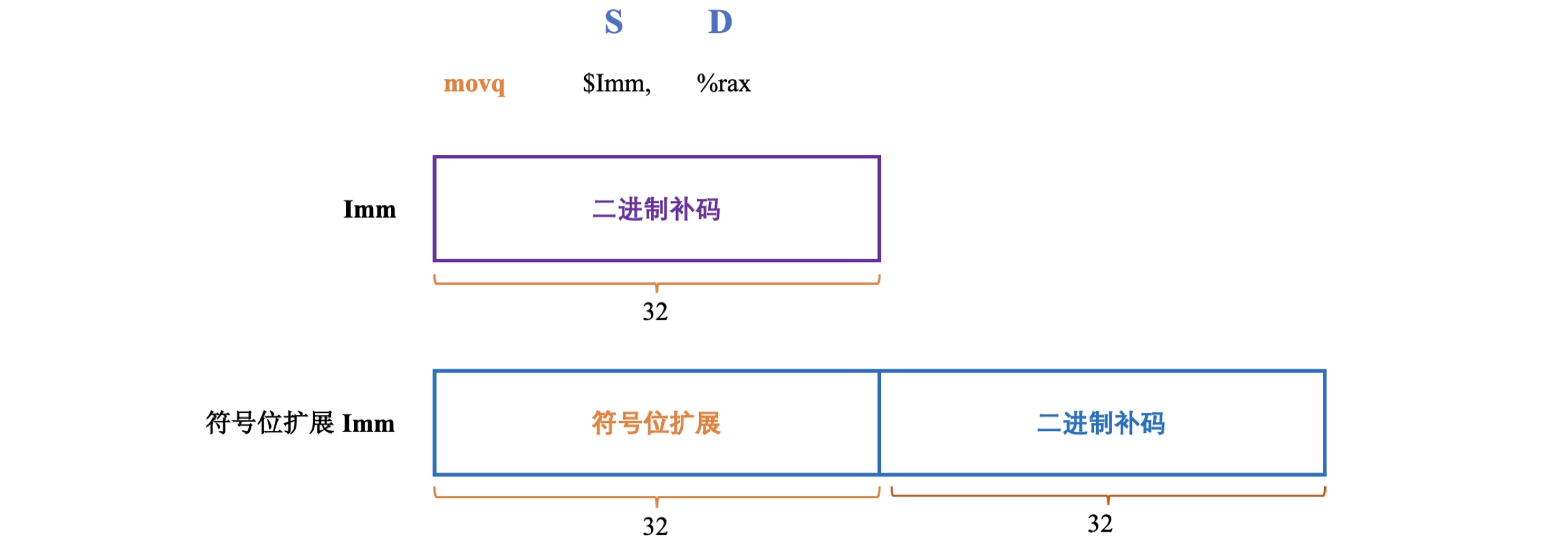
如果要将64位补码移动至寄存器(而不能是内存)中,可以使用movabsq指令,该指令只能将64位补码移动至寄存器中而非内存,这里需要注意。
mov指令如何修改目的寄存器的内容?
movabsq $0x0011223344556677, %rax,指的是将立即数存放至寄存器中,如下图所示:

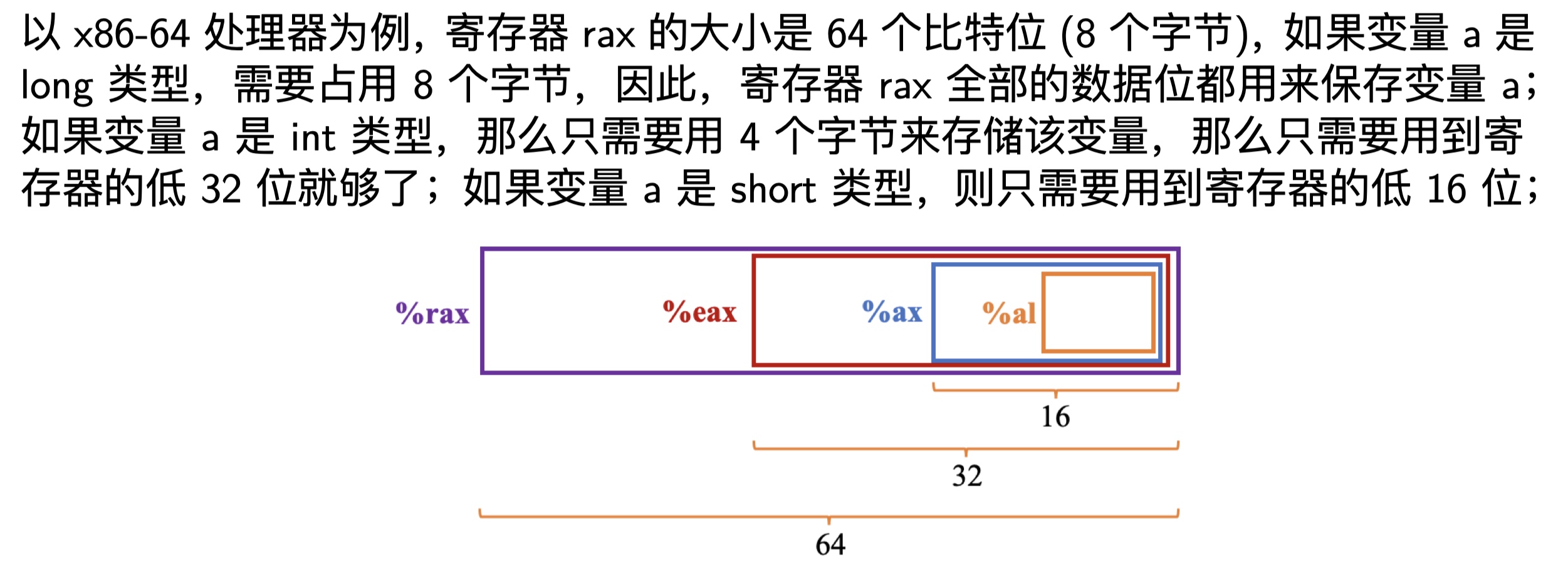
现在要将一个只有8位的立即数-1复制到寄存器al当中,那么首先什么是al寄存器?其实在寄存器发展当中,随着寄存器位数的增加,很多寄存器的低位依然保留原来的名字,高位衍生出新的名字具体如下:

所以al寄存器实际上就是rax寄存器的低8位,那么回到刚才,将8位立即数-1复制到寄存器al中,使用movb指令:movb $-1, %al,寄存器低8位发生改变,那么为什么是全F呢,因为-1的补码是全F,寄存器存放的是立即数的补码:

那如果要将低16位的立即数-1复制到寄存器中,首先得复制ax寄存器,ax寄存器是rax寄存器的低16位,其次要用到命令movw,即movw $-1, %ax:

我们上面说到如果64位寄存器rax中,移入32位的立即数,那么要进行符号位扩展,但是目前我们是将32位立即数移动至32位寄存器eax当中,那么寄存器高4字节应当置0,这是x86_64处理器的规定,比如现在要将32位立即数-1复制到32位寄存器eax当中,使用movl指令,movl $-1, %eax:

总结如下:

以上介绍了mov指令的位扩展等操作,但是都基于一个前提那就是源操作数与目的操作数的数位相同。
当源操作数位小于目的操作数的数位时,需要对目的操作数剩余字节进行零扩展或符号位扩展,具体是哪种扩展,与指令相关。零扩展数据传送指令有5条,指令后z是zero的缩写;符号位扩展传送指令有6条,指令后s是sign的缩写。接下来的第一个字母是源操作数大小,第二个字母表示目的操作数的大小,指令如图所示:
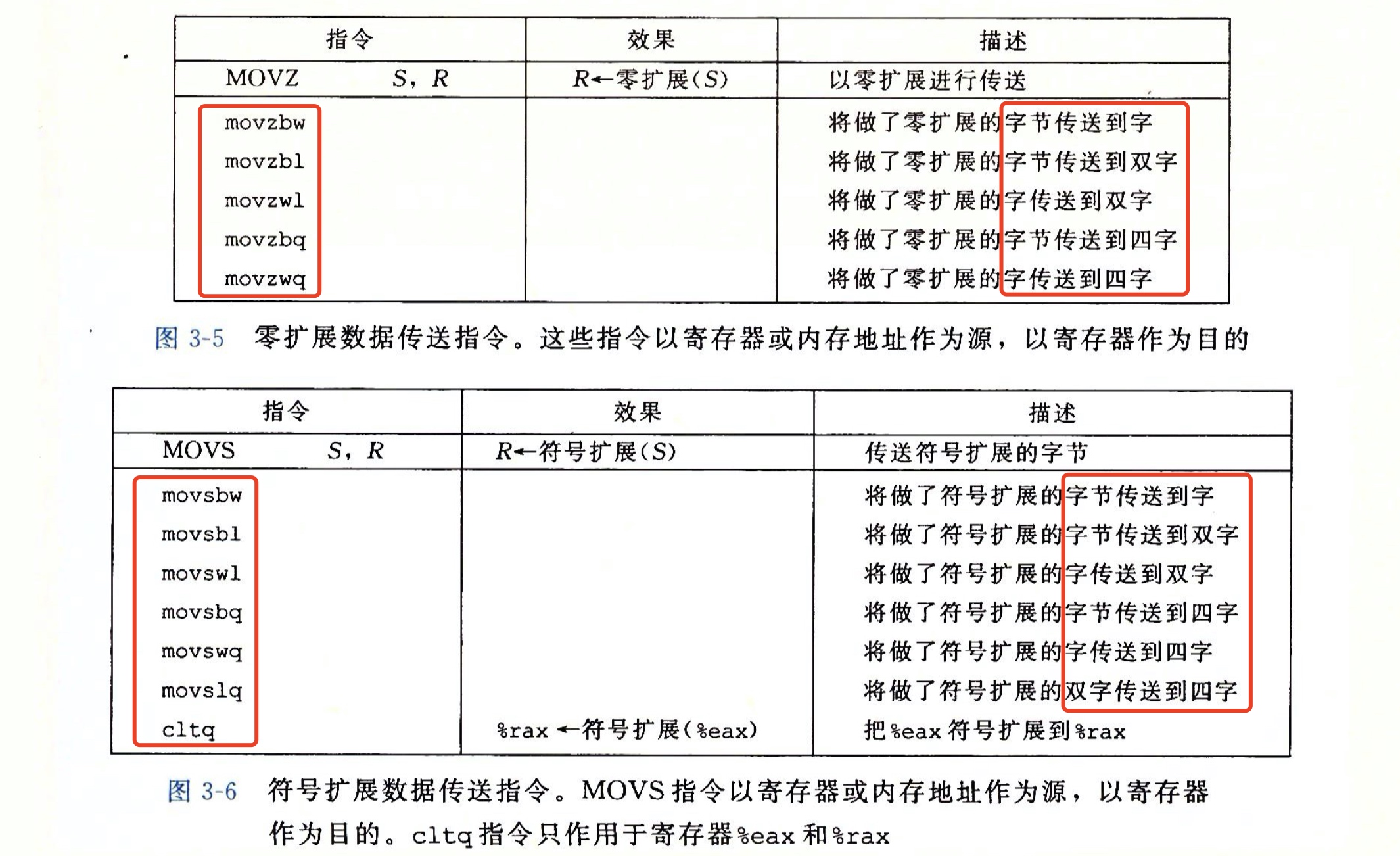
可以看到符号扩展比零扩展多一条4字节到8字节的扩展指令movslq,为何零扩展无movzlq?是因为movl指令可实现该扩展,即我们上面提到的,如movl $-1, %eax,当低32位使用F填充后,高32位必须置0,即movl实现了类似于movzlq的功能,所以无需指令movzlq。同时需要说明符号位扩展中的cltq指令,该指令的源操作数总是寄存器eax,目的操作数总是寄存器rax,cltq的效果等价于执行了movslq %eax, %rax,即将eax高32位用符号位扩展。
数据传送
对一个执行的程序而言,若要计算加法\(c = a+b\),那么需要将数据通过内存总线和系统总线从内存中写入寄存器中,然后通过CPU内部的逻辑运算单元ALU来计算a和b的加法,将返回值写给rax、eax、ax、al等相关位数寄存器(具体使用哪个和数据类型字宽有关),需要再次说明,之所以ALU的结果放到rax中,因为rax这个特定寄存器的功能就是用来存放返回值的。
举个例子,我们来看下如下代码,分析其汇编执行流程:

我们使用gcc -Og -S exchange.c单独对exchange函数进行汇编,生成汇编代码主要指令如下:
exchange:
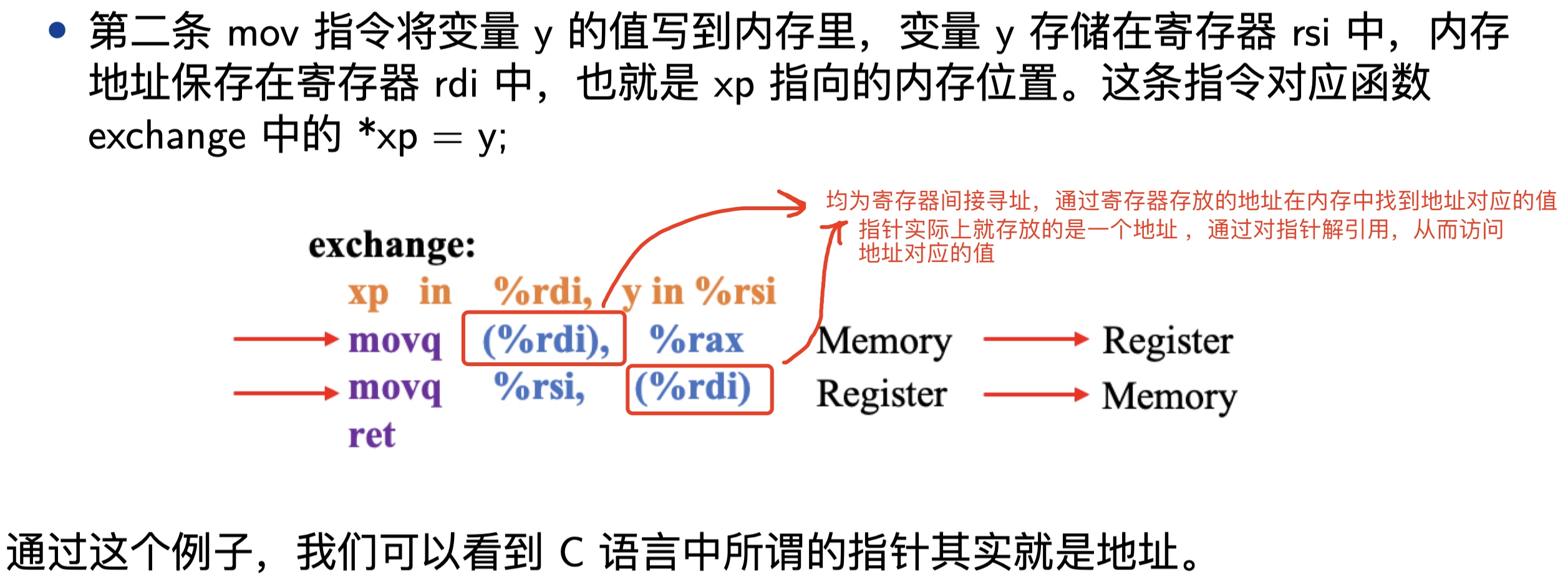
movq (%rdi), %rax
movq %rsi, (%rdi)
ret
根据之前的学习,我们知道第一个参数存放的位置在rdi中,第二个参数存放的位置在rsi中(均为long四字类型)。所以xp指针指向的值的地址保存在rdi中,y的值存放在rsi中,函数exchange主要有三条指令实现,包括两条数据传送指令和一条返回指令。

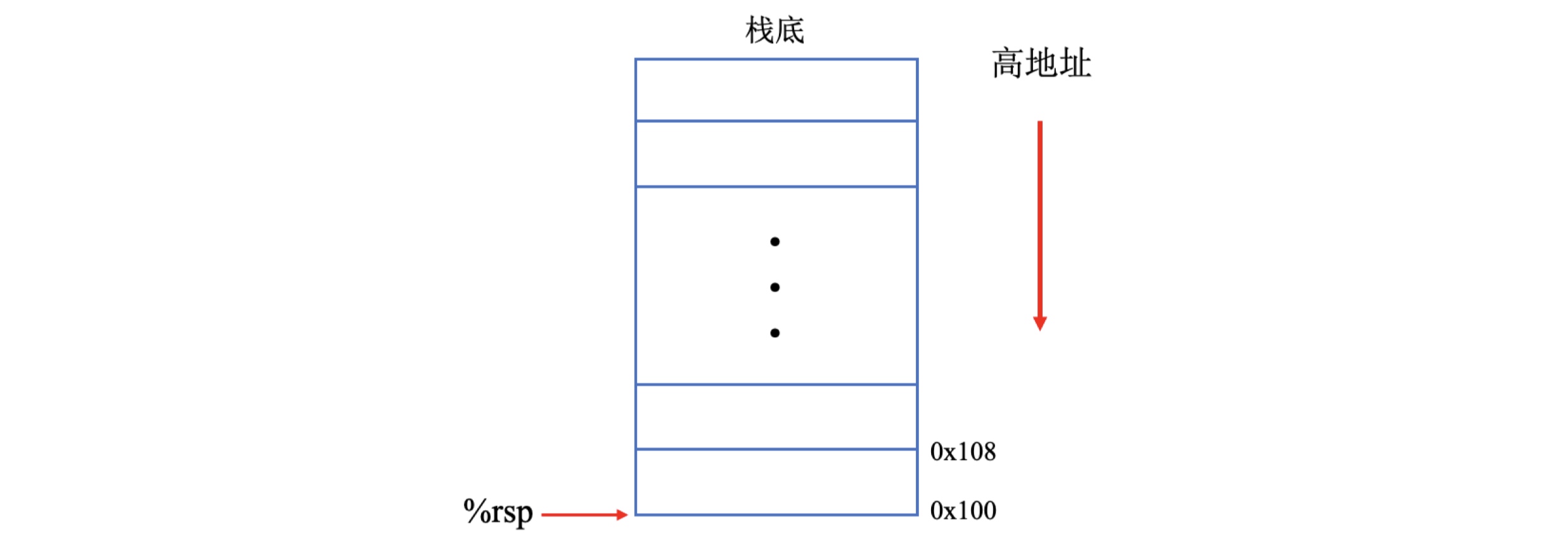
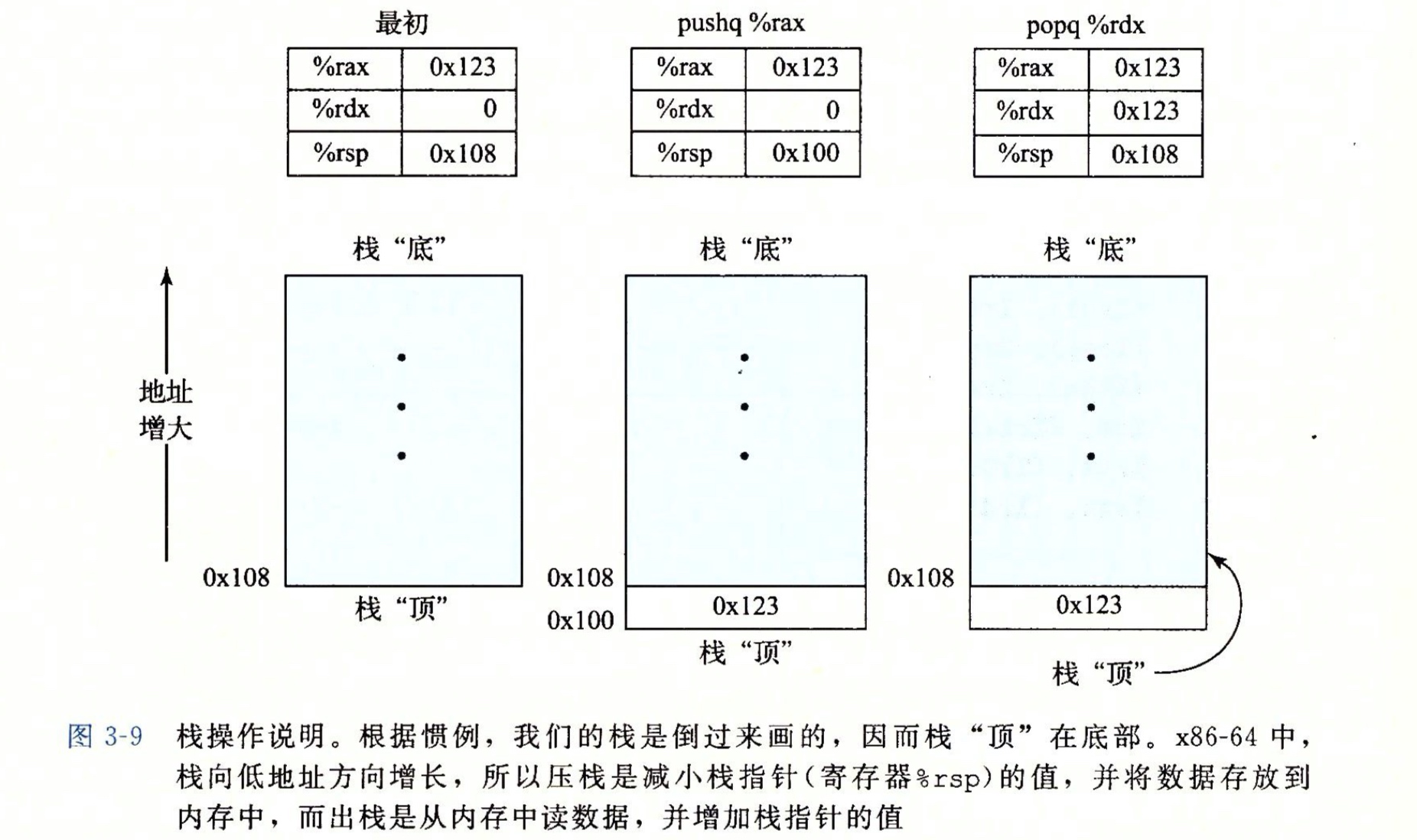
此外,还有两个数据传送指令需要借助程序栈,程序栈本质上是内存中的一个区域。栈的增长方向是从高地址向低地址,因此,栈顶的元素是所有栈中元素地址中最低的。根据惯例,栈是倒过来画的,栈顶在图的底部,栈底在顶部,rsp是栈顶寄存器。
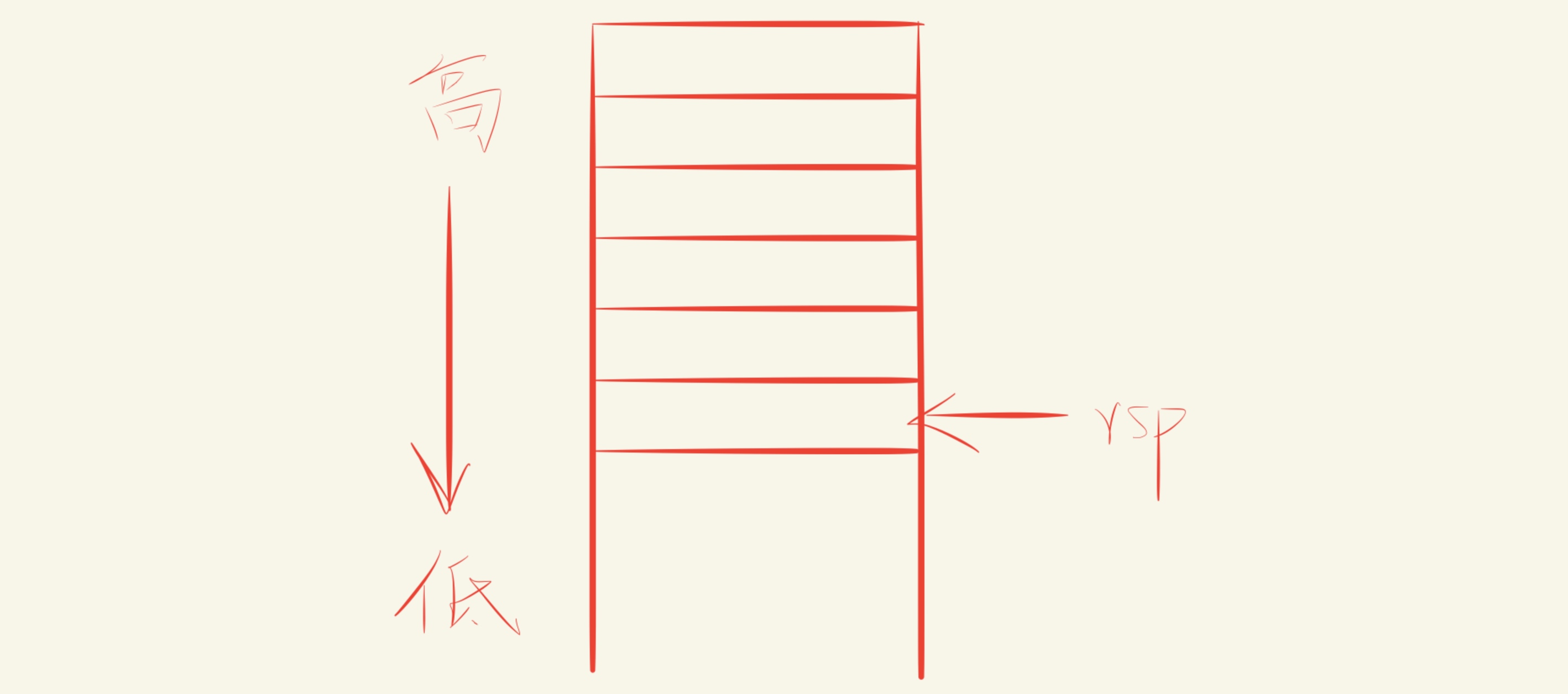
例如现在我们需要保存寄存器rax内存储的数据0x123,可以使用pushq指令把数据压入栈内。若要将数据弹出,则使用popq指令,这些指令只有一个操作数(压入的数据源和弹出的数据目的)。

我们首先来看下一个入栈的操作过程:
- 首先指向栈顶的寄存器的
rsp进行一个减法操作,例如压栈之前,栈顶指针rsp指向栈顶的位置,此处的内存地址0x108;压栈的第一步就是寄存器rsp的值减8,此时指向的内存地址是0x100。
- 然后将需要保存的数据复制到新的栈顶地址,此时,内存地址
0x100处将保存寄存器rax内存储的数据0x123。实际上pushq的指令等效于subq和movq这两条指令。它们之间的区别是在于pushq这一条指令只需要一个字节,而subq和movq这两条指令需要8个字节。所以执行subq %rax意味着执行了两个操作,首先是将栈顶地址减8,然后再将rax寄存器存放的值存放至栈顶指针rsp指向的位置。
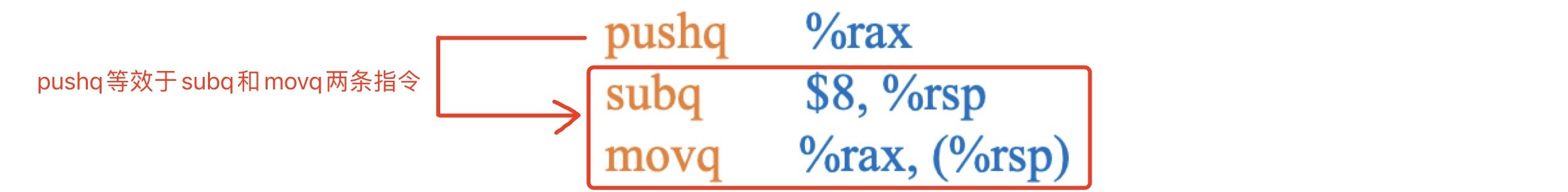
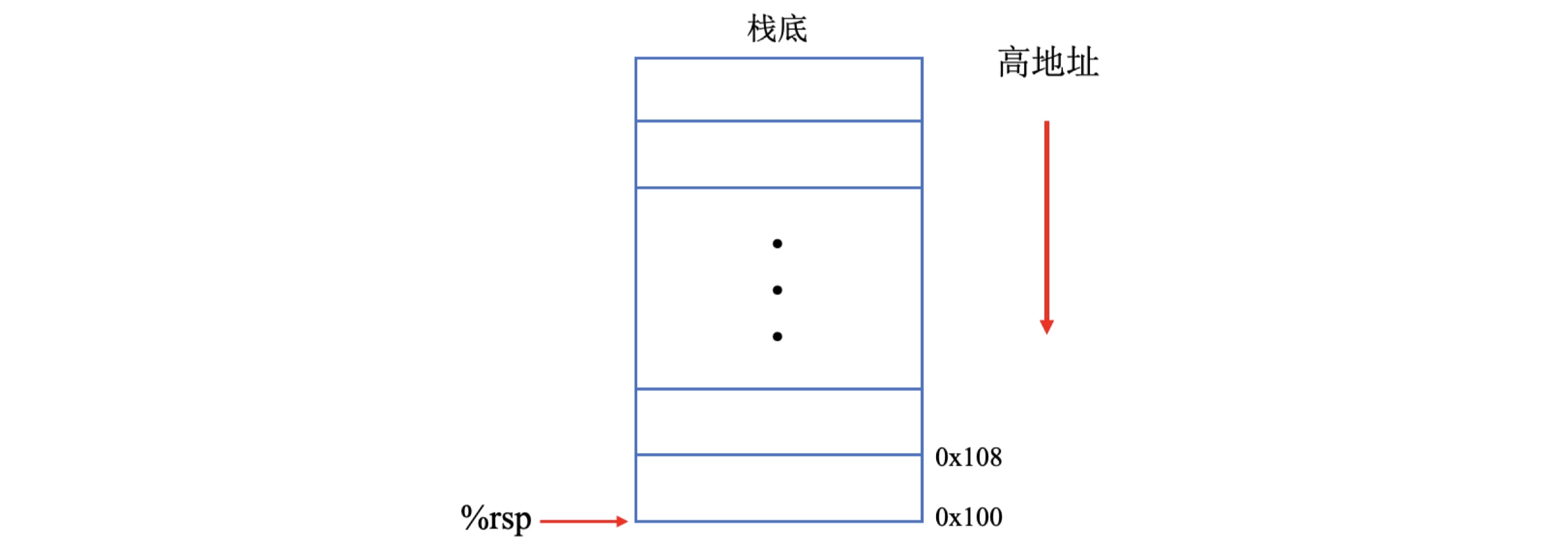
说到底,push指令的本质还是将数据写入到内存中,那么与之对应的pop指令就是从内存中读取数据,并且修改栈顶指针。例如图中这条popq指令就是将栈顶保存的数据复制到寄存器rbx中。
那么pop操作也可分解为两部分:
- 首先从栈顶的位置读出数据,复制到寄存器
rbx(被调用者保存寄存器)。此时,栈顶指针rsp指向的内存地址是0x100。
- 然后将栈顶指针加
8,pop后栈顶指针rsp指向的内存地址是0x108。
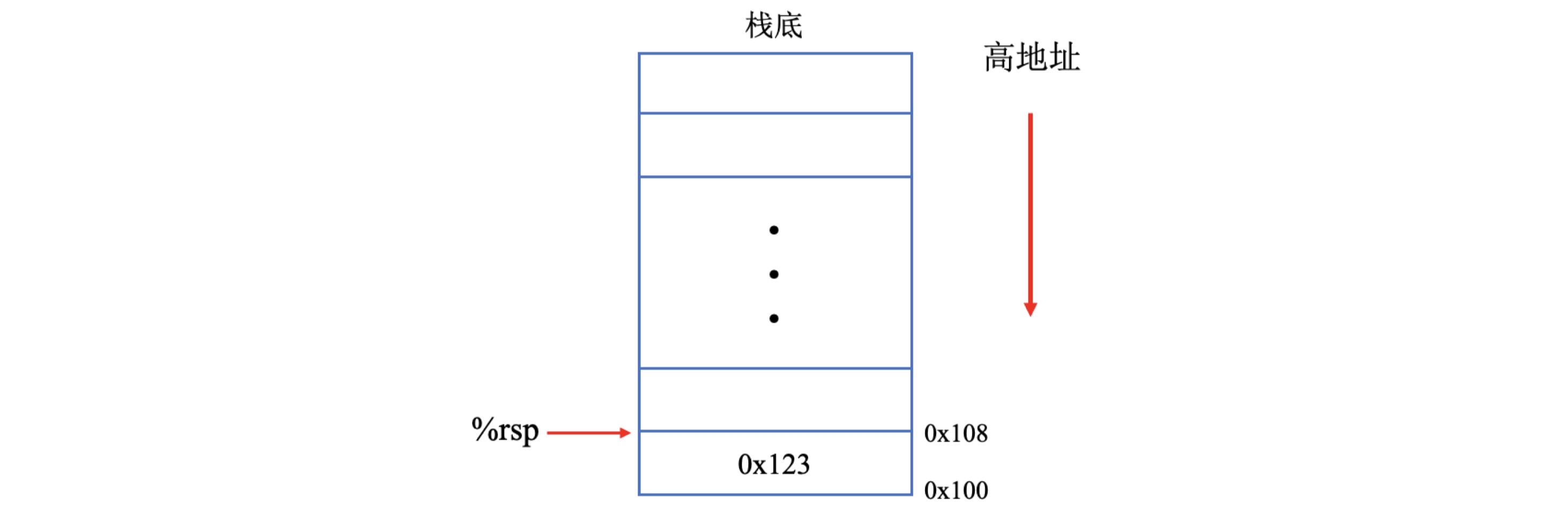
因此pop操作也可以等效movq和addq这两条指令。实际上pop指令是通过修改栈顶指针所指向的内存地址来实现数据删除的,此时,内存地址0x100内所保存的数据0x123仍然存在,直到下次push操作,此处保存的数值才会被覆盖。
leaq指令
加载有效地址(load effective address)指令leaq实际上是movq指令的变形,它的指令形式是从内存读数据到寄存器当中,但实际根本未引用内存,它的第一个操作数看上去是内存引用,但该指令并不是从指定位置读入数据,而是将有效地址写入到目的操作数。


以上为leaq指令将有效地址值写入寄存器中的过程,即加载有效地址。leaq不仅可以加载有效地址,还可表示加法和有限乘法运算,对下述代码进行编译:

通过gcc -O1 -S a.c,得到的汇编代码指令如下:
scale:
leaq (%rdi,%rsi,4), %rax
leaq (%rdx,%rdx,2), %rdx
leaq (%rax,%rdx,4), %rax
ret
x存放在rdi寄存器中,y存放在rsi寄存器中,z存放在rdx寄存器中,那么第一条指令将rdi+4*rsi放入rax中,即表示x+4y;第二条指令表示将3z写入rdx寄存器;第三条指令则是将rax存放的x+4y与4rdx相加结果写入rax,此时rax存放的是x+4y+12z的结果,最终rax寄存器作为返回值返回即可。
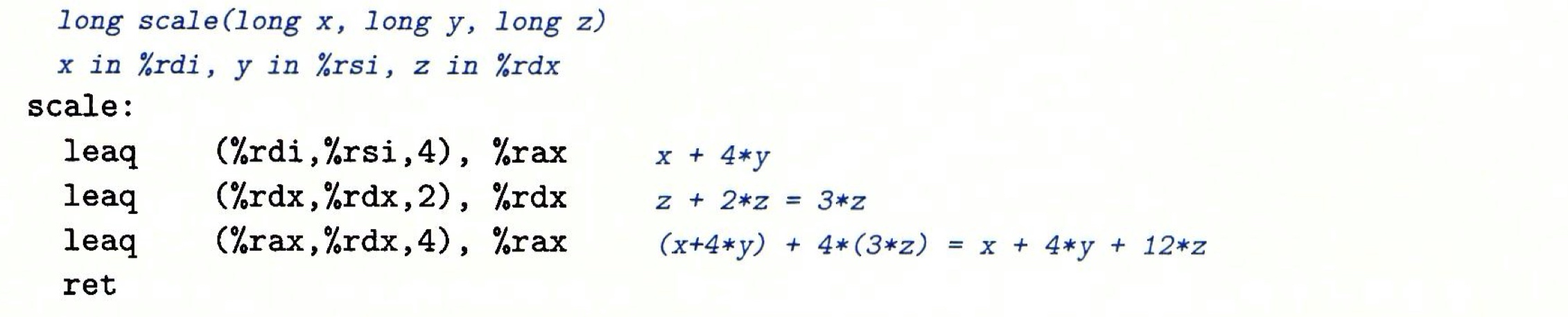
leaq指令能执行加法和有限的乘法,在编译如上简单的算术表达式时,是很有用处的。

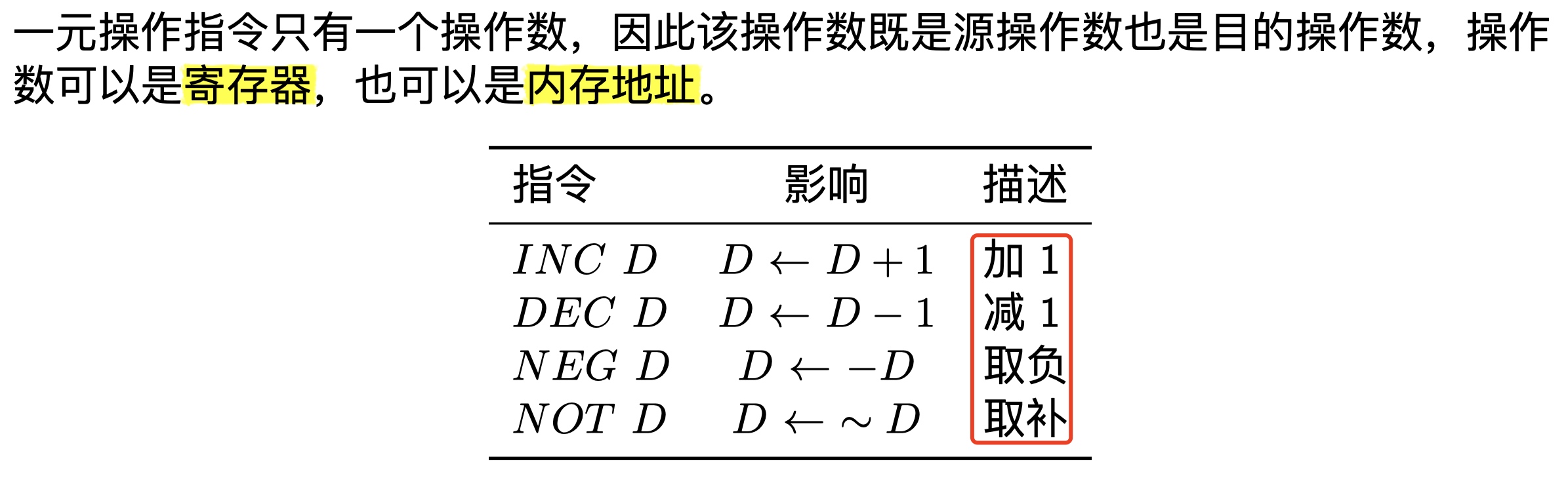
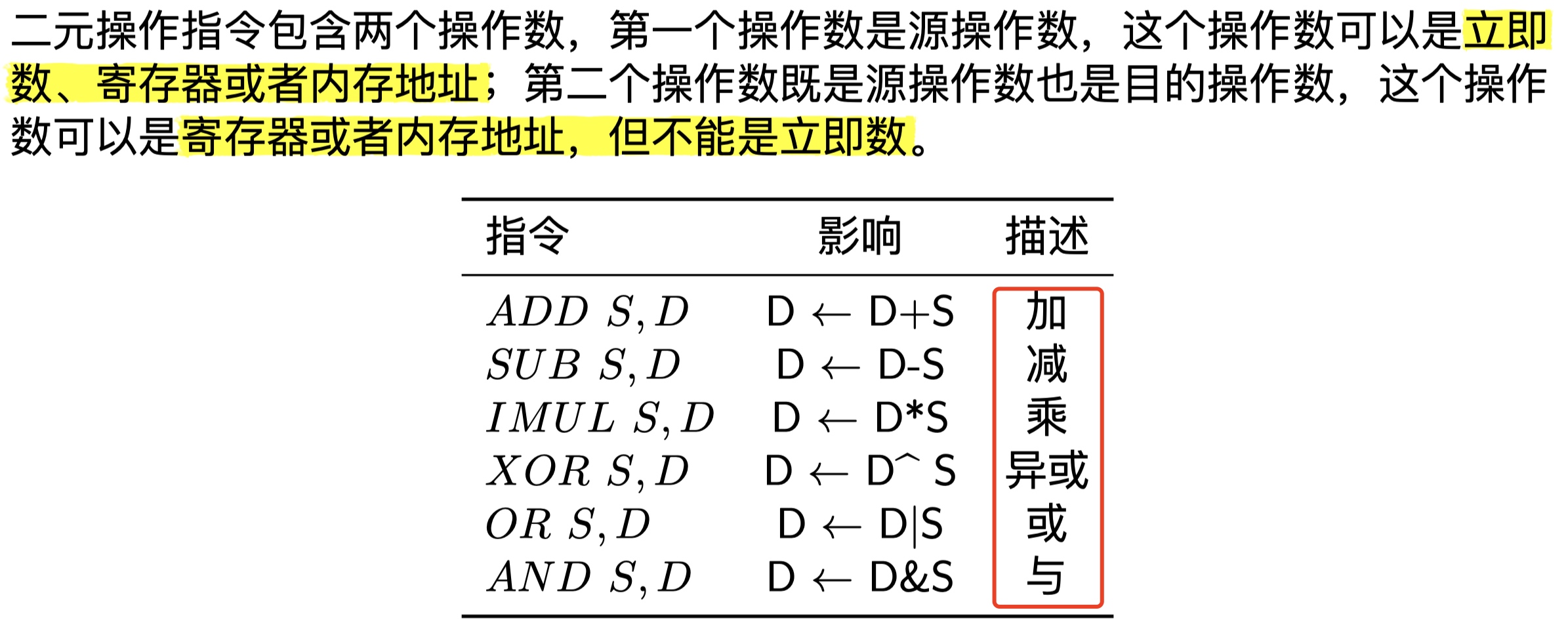
一元和二元操作、移位操作、特殊算术操作
移位操作:

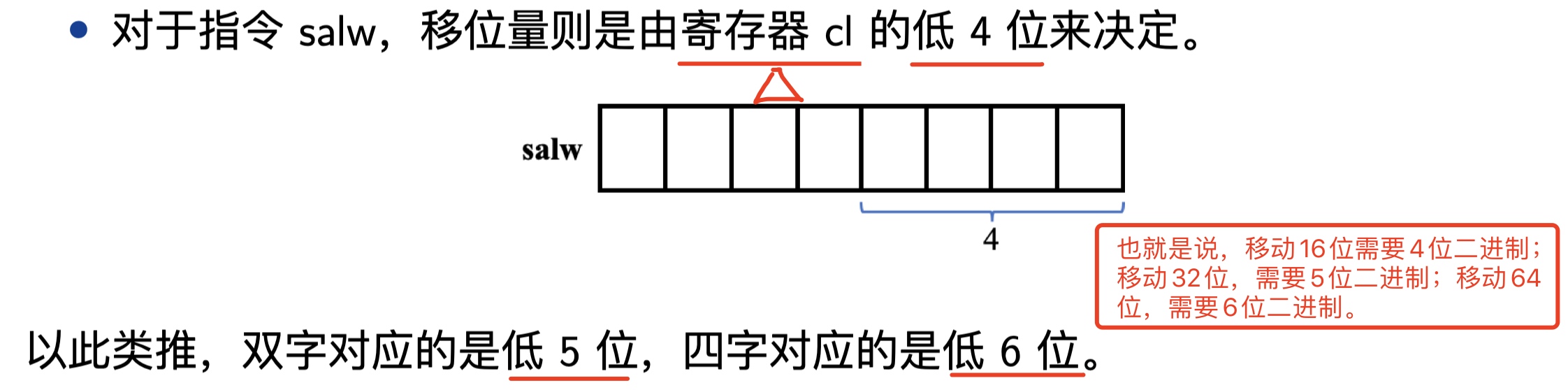
我们根据具体代码举例说明移位操作,示例如下:

我们分析一下这个代码第3行,对应的汇编指令:
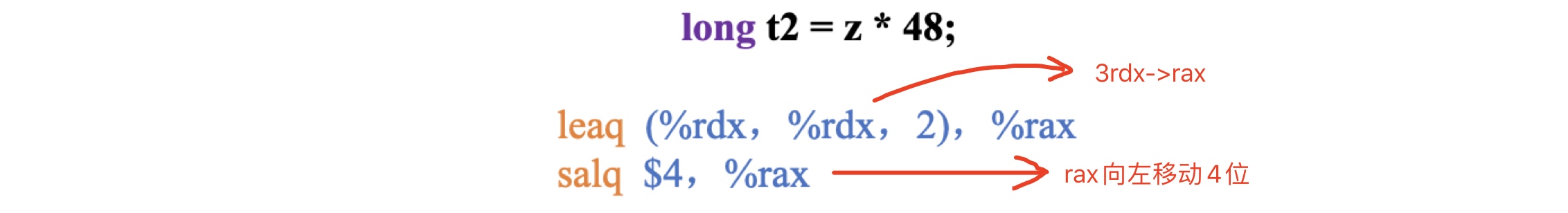
上图rdx的值为z,rax通过第一条指令,存放3z的值,然后第二条指令左移4位等同于乘以\(2^4 = 16\),所以这两条指令最终计算的是48z的值,存放至rax寄存器中。为什么编译器不直接使用乘法指令来实现这个运算呢?主要是因为乘法指令的执行需要更长的时间,因此编译器在生成汇编指令时,会优先考虑更高效的方式。
一元、二元操作、移位操作指令总结:
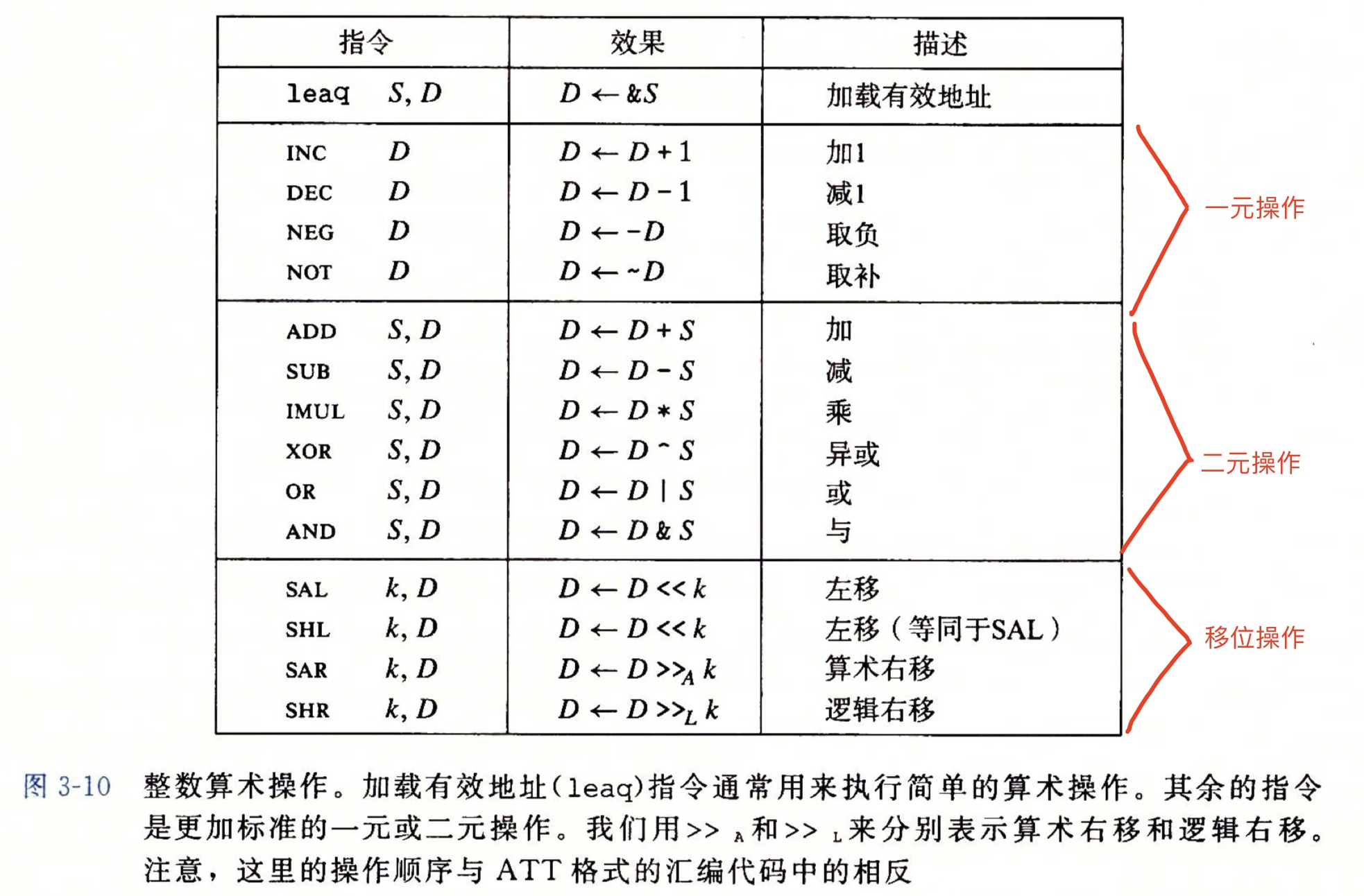
特殊算数操作指令:

条件码
关于条件码寄存器的各个字段,之前博客也有介绍过(Link),主要以8086寄存器为例说明。
条件码寄存器其实也称为标志寄存器,其具有三种作用:
- 用来存储相关指令的某些执行结果;
- 用来为CPU执行相关指令提供行为依据;
- 用来控制CPU的相关工作方式。

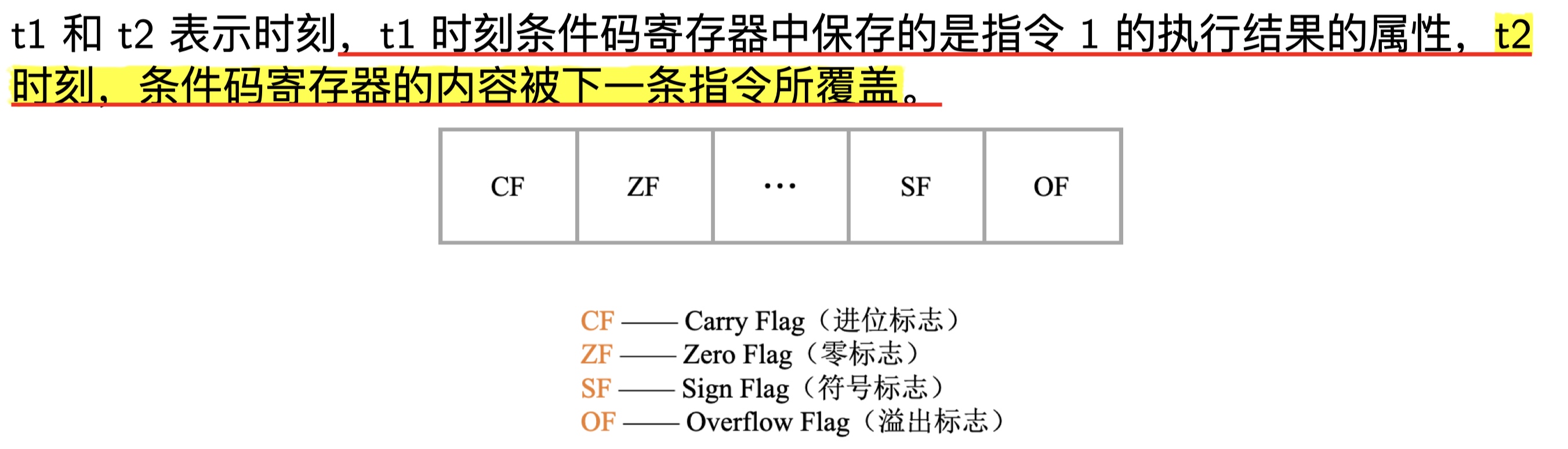
以下是8086相关标志位:


条件码寄存器(状态寄存器)的值是由ALU在执行算术和运算指令时写入的,下图中的这些算术和逻辑运算指令都会改变条件码寄存器的内容:
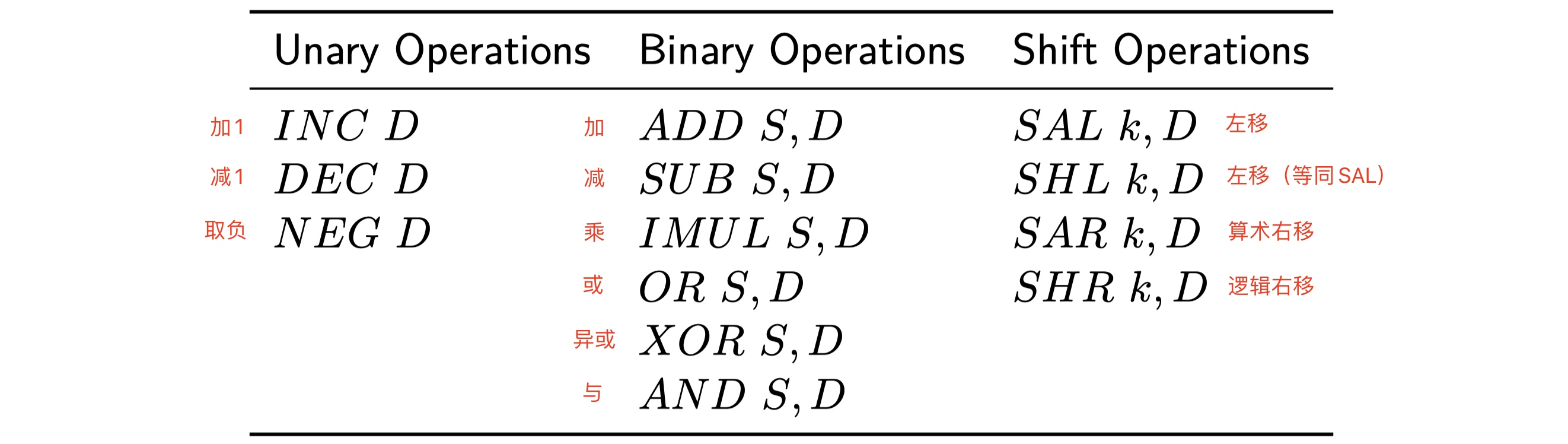
对于不同的指令也定义了相应的规则来设置条件码寄存器。例如:
- 逻辑操作指令
xor,进位标志(CF)和溢出标志(OF)会置0; - 对于
inc加一指令和dec减一指令会设置溢出标志(OF)和零标志(ZF),但不会改变进位标志(CF)。

关于条件码使用,我们举例看下如下代码以及其汇编指令:

gcc -Og -S a.c得到汇编指令为:
comp:
cmpq %rsi, %rdi
sete %al
movzbl %al, %eax
ret
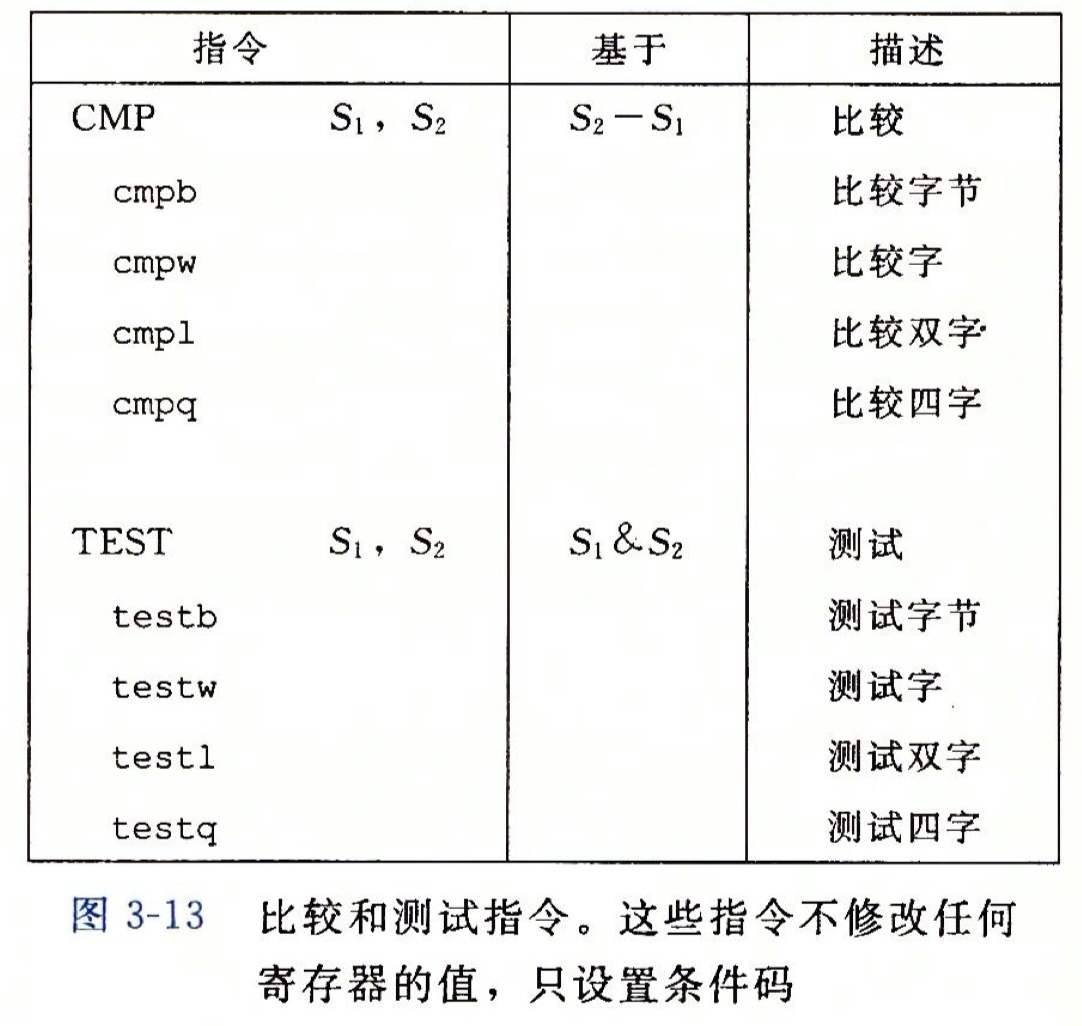
上面已经介绍了cmp指令,cmp指令是根据两个操作数的差来设置条件码寄存器。cmp指令和减法指令sub类似,也是根据两个操作是的差来设置条件码,二者不同的是cmp指令只是设置条件码寄存器,并不会更新目的寄存器的值。
在这个例子中,指令sete根据需标志(ZF)的值对寄存器al进行赋值,后缀e是equal的缩写。如果零标志等于1,指令sete将寄存器al置为1;如果零标志等于0,指令sete将寄存器al置为0。
然后mov指令对寄存器al进行零扩展,最后返回判断结果,存放至rax寄存器中。
下面看一个复杂例子,代码如下:

转成汇编指令后:



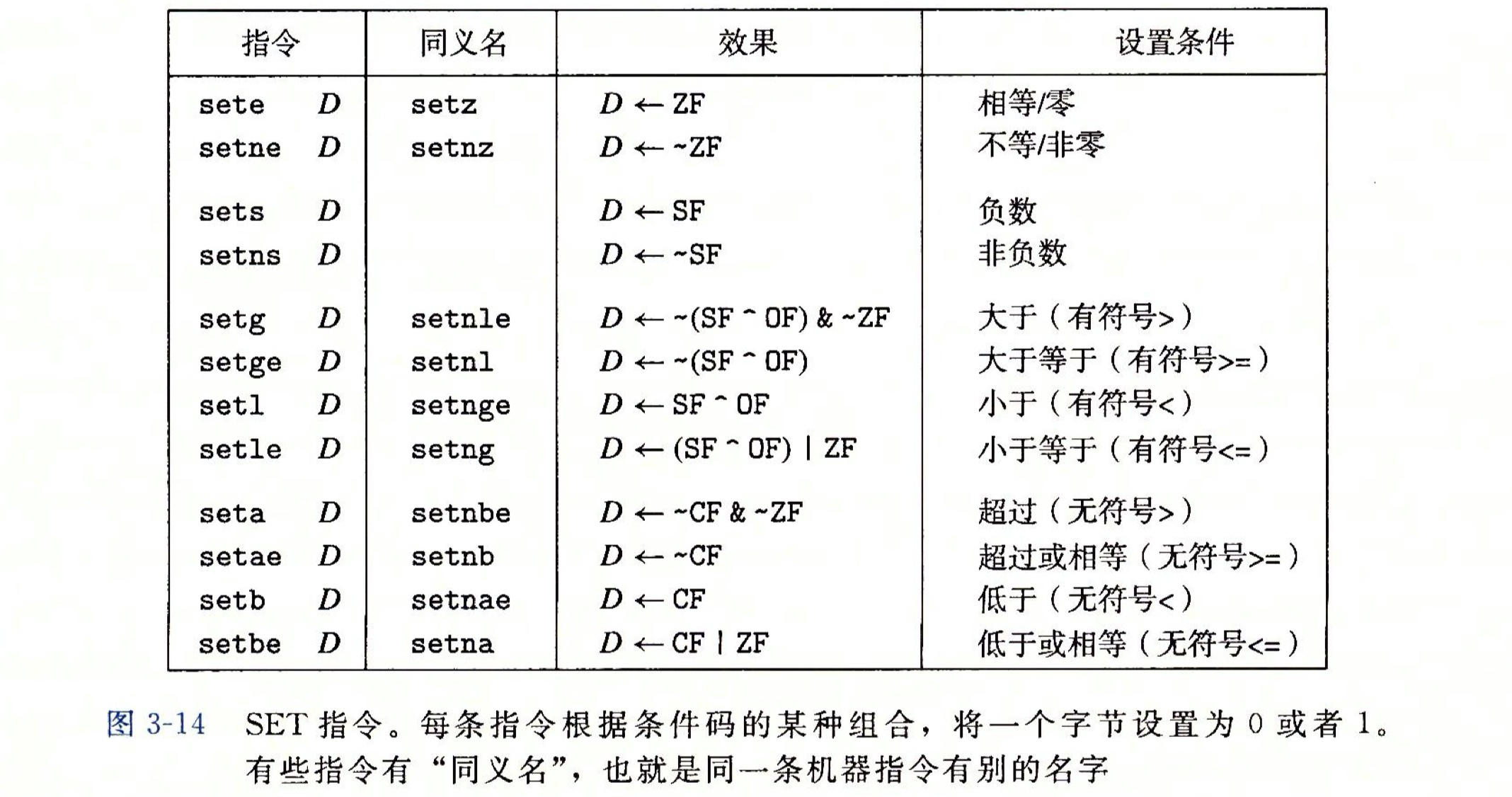
判断a<b是否为真,需要首先判断a-b的值,a-b<0设置SF=1,反之SF=0,然后判断是否正溢出或负溢出,溢出置OF=1,反之OF=0;计算SF^OF,若结果为1,则a<b为true;反之a<b为false。所以,综上可发现,根据符号标志(SF)和溢出标志(OF)的异或结果,可以对a小于b是否为真做出判断。更多相关set指令如下:
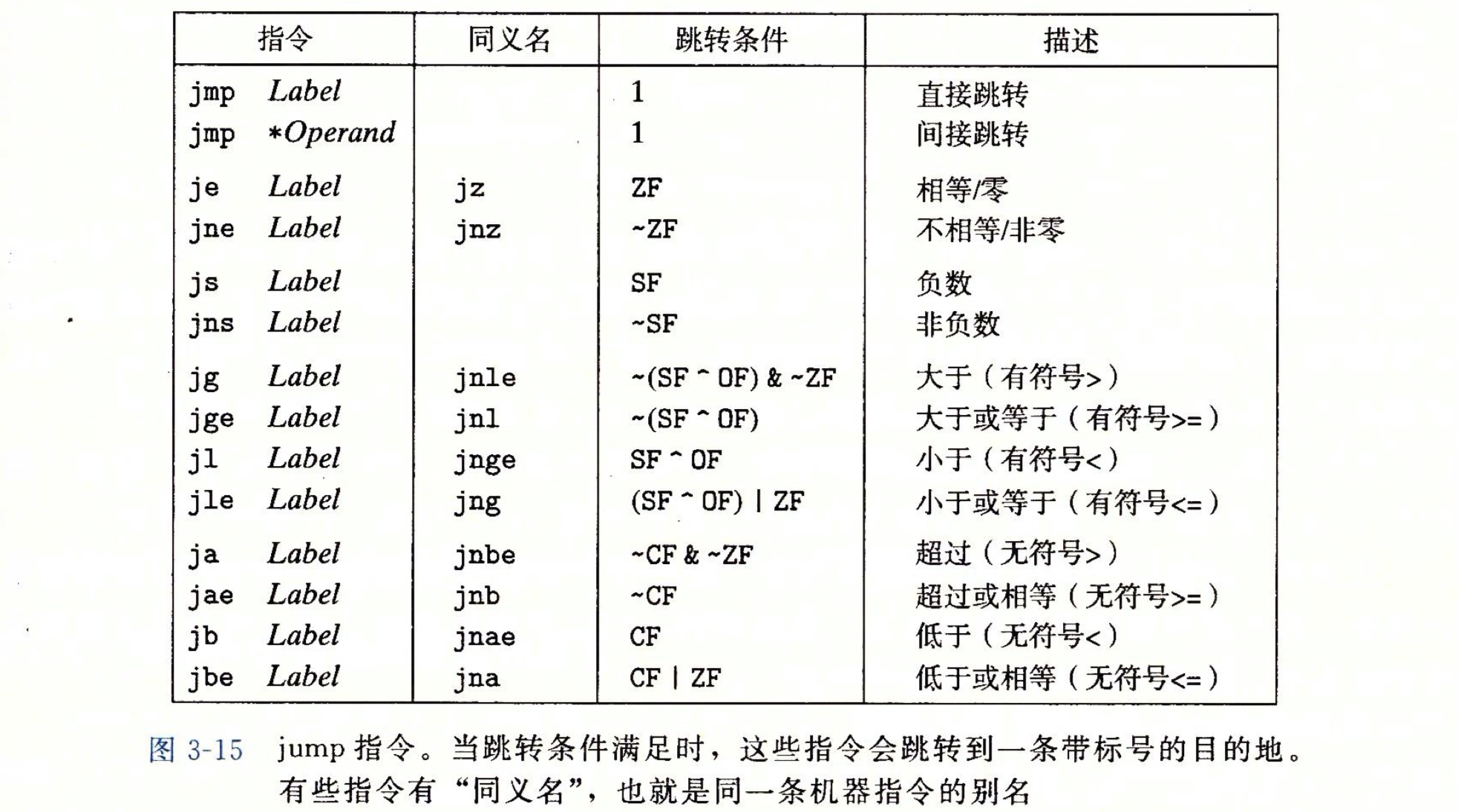
跳转指令
接下来看下跳转指令相关代码及汇编指令:
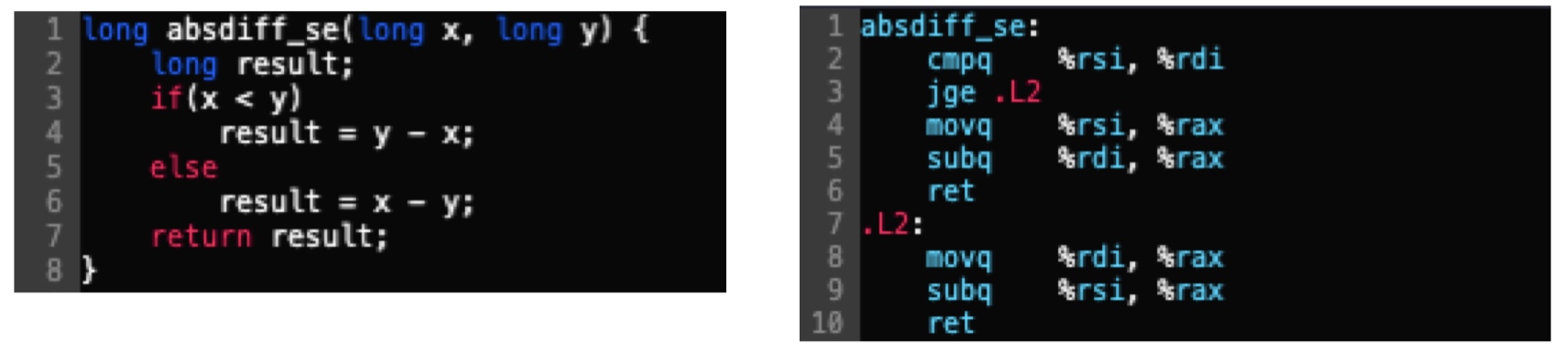
通过cmp指令首先设置x<y对应的标志寄存器的符号标志(SF)和溢出标志(OF),然后跳转指令进行相应的位运算来判断其布尔值的真假,以此来判断是否发生跳转至.L2处,位运算计算方法如下图:
只不过,相比于代码中的x < y,汇编指令通过jge判断x是否大于等于y,ge是greater >和equal =的缩写。对于代码中的if-else语句,当满足条件时,程序洽着一条执行路径执行,当不满足条件时,就走另外一条路径。这种机制比较简单和通用,但是在现代处理器上,它的执行效率可能会比较低。针对这种情况,有一种替代的策略,就是使用数据的条件转移来代替控制的条件转移。还是针对两个数差的绝对值问题,给出了另外一种实现方式,我们既要计算y-x的值,也要计算x-y的值,分别用两个变量来记录结果,然后再判断x与y的大小,根据测试情况来判断是否更新返回值。这两种写法看上去差别不大,但第二种效率更高。具体如下所示:

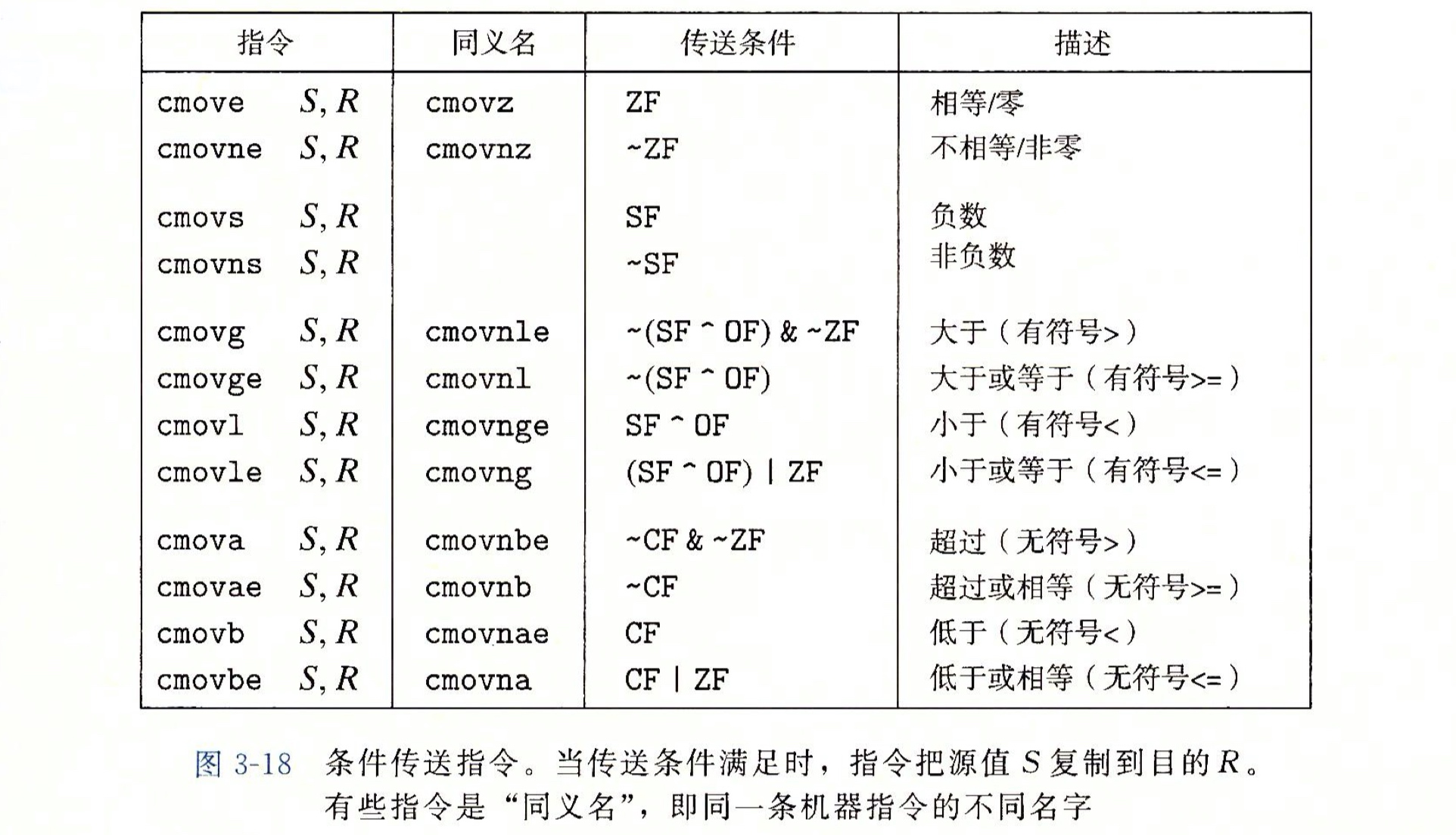
上图c前面这几条指令都是普通的数据传送和减法操作。cmovge是根据条件码的某种组合来进行有条件的传送数据,当满足规定的条件时,将寄存器rdx内的数据复制到寄存器rax内。在这个例子中,只有当x大于等于y时,才会执行这一条指令。
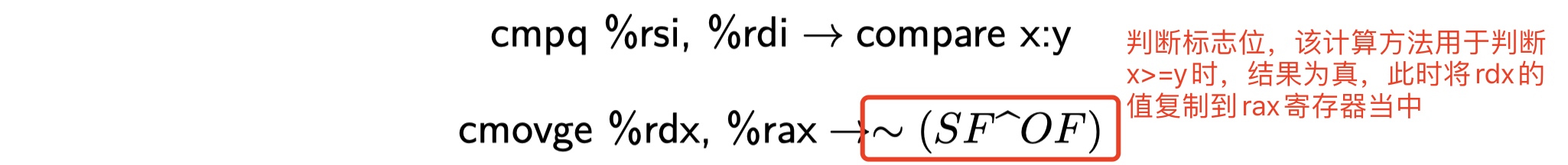
更多传送指令如下所示:
为什么基于条件传送的代码会比基于跳转指令的代码效率高呢?这里涉及到现代处理器通过流水线来获得高性能。当遇到条件跳转时,处理器会根据分支预测器来猜测每条跳转指令是否执行,当发生错误预测时,会浪费大量的时间,导致程序性能严重下降。
循环
do-while


while

对比一下for与while的汇编代码:

可以发现除了这一句跳转指令不同,其他部分都是一致的。这两个汇编代码是采用-Og选项产生的。综上所述,三种形式的循环语句都是通过条件测试和跳转指令来实现。以上则是三种循环的示例说明。
swich语句

对于上面的代码,汇编代码如下:

cmpq指令设置状态寄存器,ja指令判断是否超过6,超过的话跳转至default对应的L8程序段,case0、case6可通过跳转表访问不同分支。代码跳转表声明为一个长度为7的数组,每个元素都是一个指向代码位置的指针,具体关系如下图所示:



在这个例子中,程序使用跳转表来处理多重分支,甚至当switch有上百种情况时,虽然跳转表的长度会增加,但是程序的执行只需要一次跳转也能处理复杂分支的情况,与使用一组很长的if-else相比,使用跳转表的优点是执行switch语句的时间与case的数量是无关的。因此在处理多重分支的时,与一组很长的if-else相比,switch的执行效率要高。
程序调用过程相关知识
为了方便讨论,以C语言代码函数调用为例,假设函数P调用函数Q,函数Q执行完毕后返回函数P,这一系列操作包括图中一个或多个机制:

C语言过程调用机制的关键特性在于使用栈数据结构提供FIFO内存管理原则,在过程P调用过程Q的例子中,可以看到当Q在执行时,P以及所有在向上追溯到P的调用链中的过程都被暂时挂起。当Q运行时,它只需要为局部变量分配新的存储空间,或设置到另一个过程的调用。另一方面,当Q返回时,任何它所分配的局部存储空间都可被释放。因此,程序可以用栈来管理它的过程所需要的存储空间,栈和程序寄存器存放着传递控制和数据、分配内存所需要的信息。当P调用Q时,控制和数据信息添加到栈尾。当P返回时,这些信息会被释放掉。
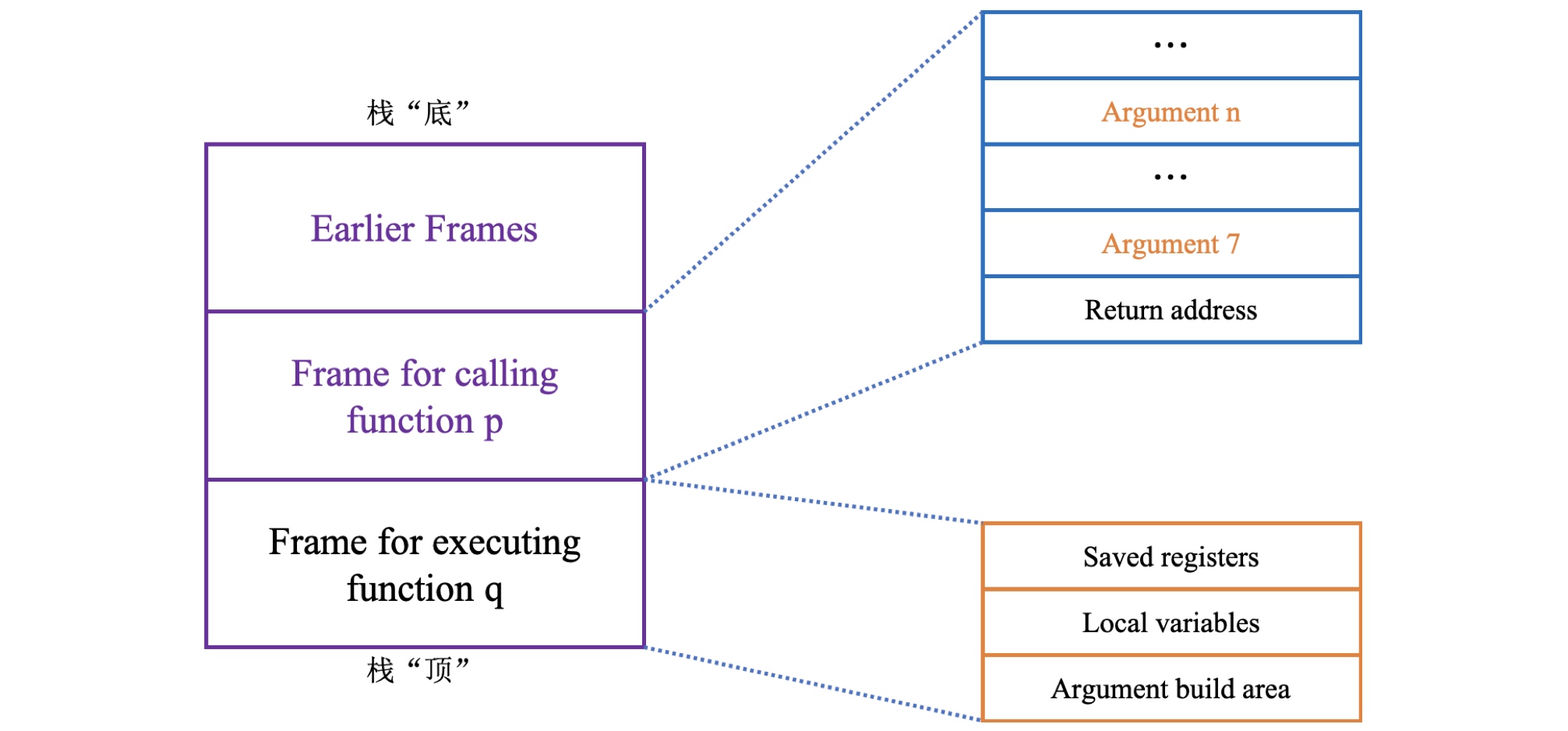
函数P调用函数Q时,会把返回地址压入栈中,该地址指明了当函数Q执行结束 返回时要从函数P的哪个位置继续执行。这个返回地址的压栈操作并不是由指令push来执行的,而是由函数调用call来实现的。具体以multstore代码为例我们可以查看返回地址细节:


编译并使用命令objdump进行反汇编,查看其具体调用情况:
gcc -Og -o prog main.c multstore.c
objdump -d prog
查看部分反汇编代码:
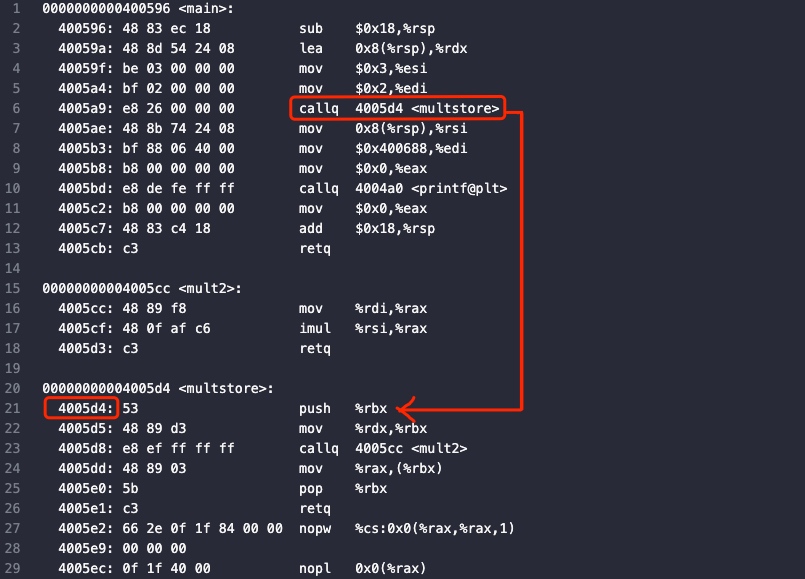
上图可知中4005a9: e8 26 00 00 00 callq 4005d4 <multstore>这一行,指令call不仅要将函数multstore的第一条指令的地址写入到程序指令寄存器rip中,以此实现函数调用,同时还要将返回地址压入栈中。
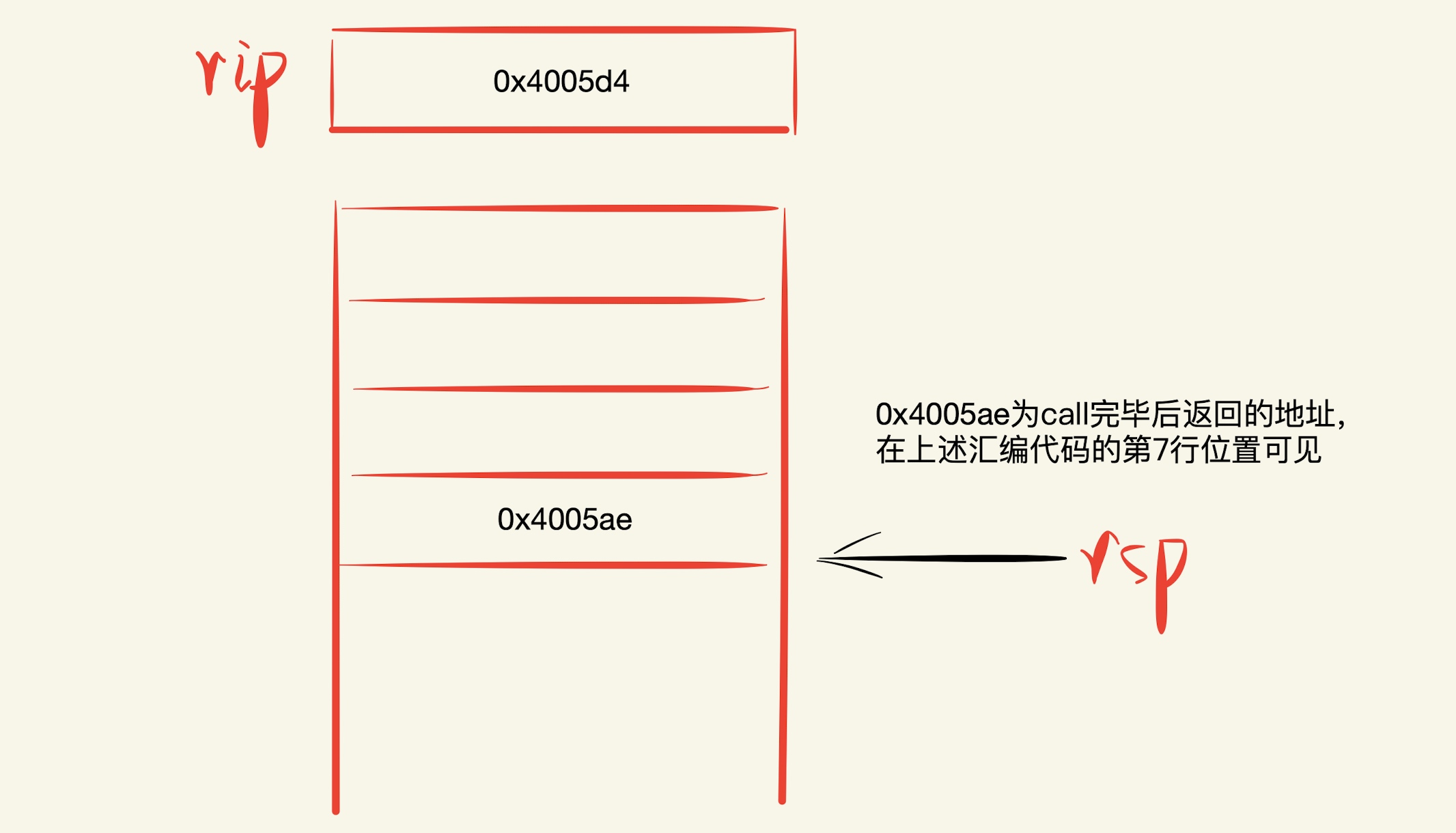
当函数multstore调用完毕后,指令ret从栈中返回地址弹出,写入程序指令寄存器rip中:

函数返回,继续执行上面反汇编代码中main函数第7行相关的操作。以上整个过程就是函数调用与返回所涉及的操作。那么函数调用的参数传递是如何实现的呢?在一开始我们知道,函数传递参数分别通过6个寄存器可以实现,但是如果传递的参数大于6个呢?超出的参数就会通过压栈来实现存储。
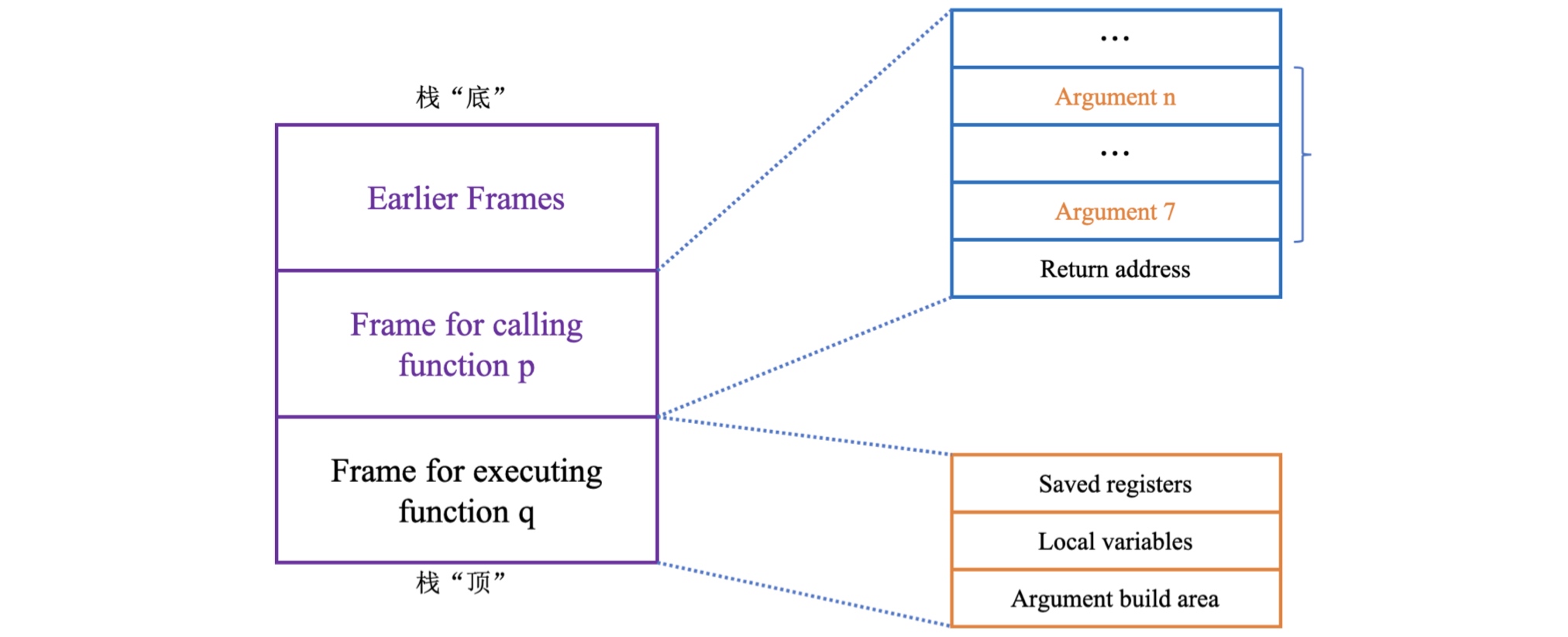

以下面代码为例,探讨参数传递过程:

代码中函数有8个参数,包括字节数不同的整数以及不同类型的指针,参数1到参数6是通过寄存器来传递,参数7和参数8是通过栈来传递。

这里补充说明:
通过栈来传递参数时,所有数据的大小都是向8的倍数对齐,虽然变量a4只占一个字节,但是仍然为其分配了8个字节的存储空间。由于返回地址占用了栈顶的位置,所以这两个参数距离栈顶指针的距离分别为8和16。


栈局部存储:
当代码中对一个局部变量使用地址运算符时,我们需要在栈上为这个局部变量开辟 相应的存储空间,接下来我们看一个与地址运算符相关的例子。


函数caller定义了两个局部变量arg1和arg2,函数swap的功能是交换这两个变量的值,最后返回二者之和。我们通过分析函数caller的汇编代码来看一下地址运算符的处理方式:

subq $16, %rsp第一条减法指令将栈顶指针减去16,它表示的含义是在栈上分配16个字节的空间。
我们再来看一个较为复杂的栈上存放局部变量的例子,代码如下:
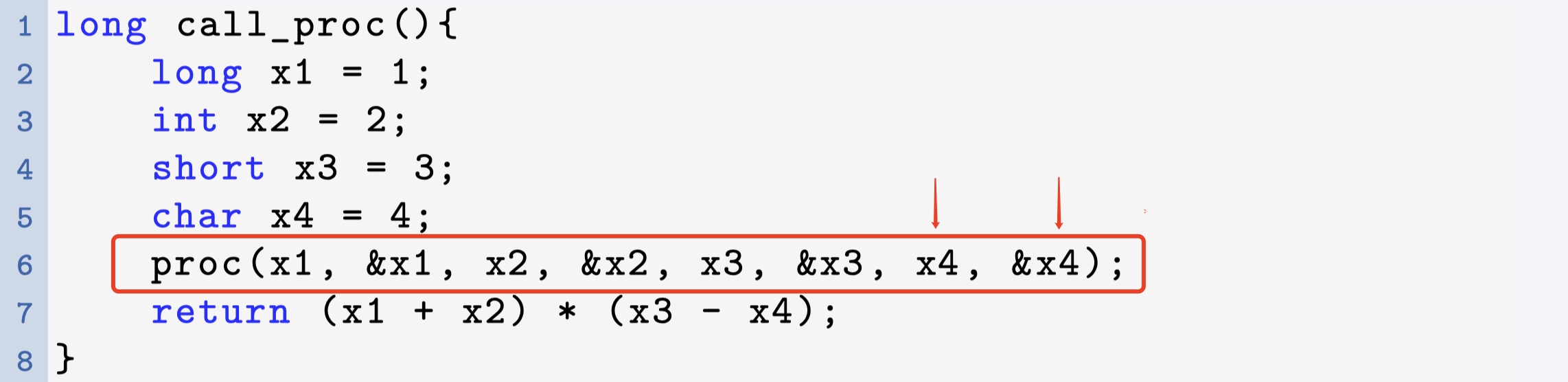
根据上面的C代码,我们来画一下这个函数的栈帧。根据变量的类型可知x1占8个字节,x2占4个字节,x3占两个字节,x4占一个字节,因此,这四个变量在栈帧中的空间分配如图所示。
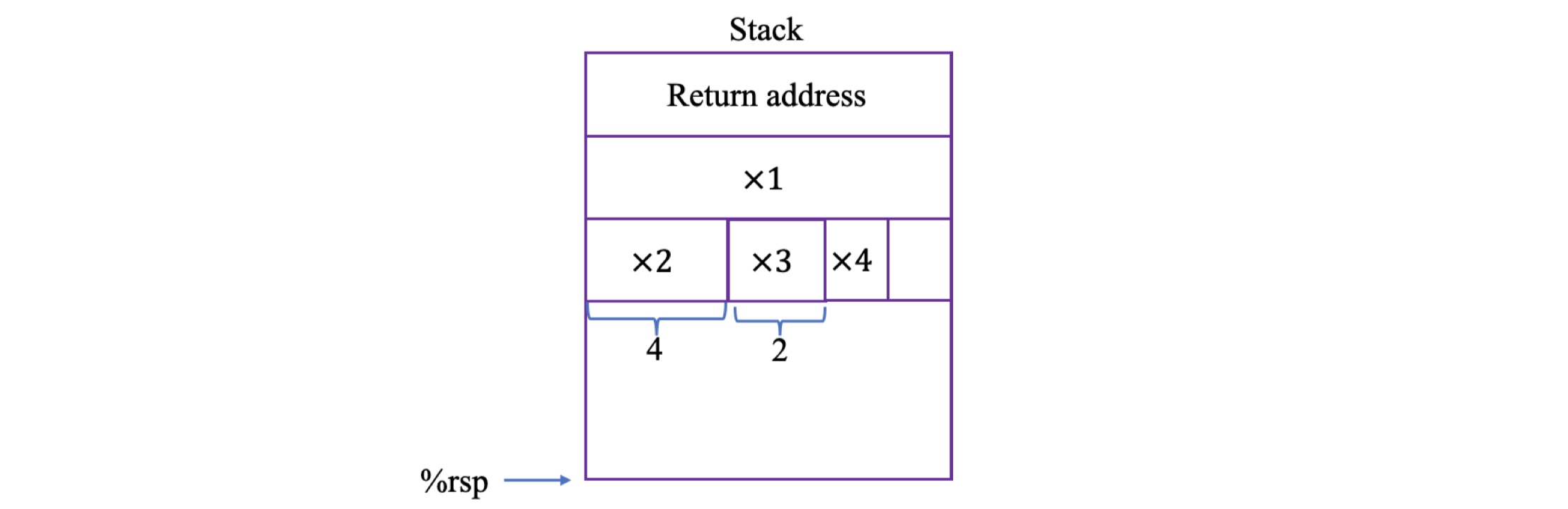
由于上面call_proc代码中第6行调用的函数proc需要8个参数,因此参数7和参数8需要通过栈帧来传递。注意,传递的参数需要8个字节对齐,而局部变量是不需要对齐的。
关于寄存器中的局部存储空间,其实之前已经提到过,在说明调用者保存寄存器和被调用者保存寄存器时已经举例,这里不再赘述。

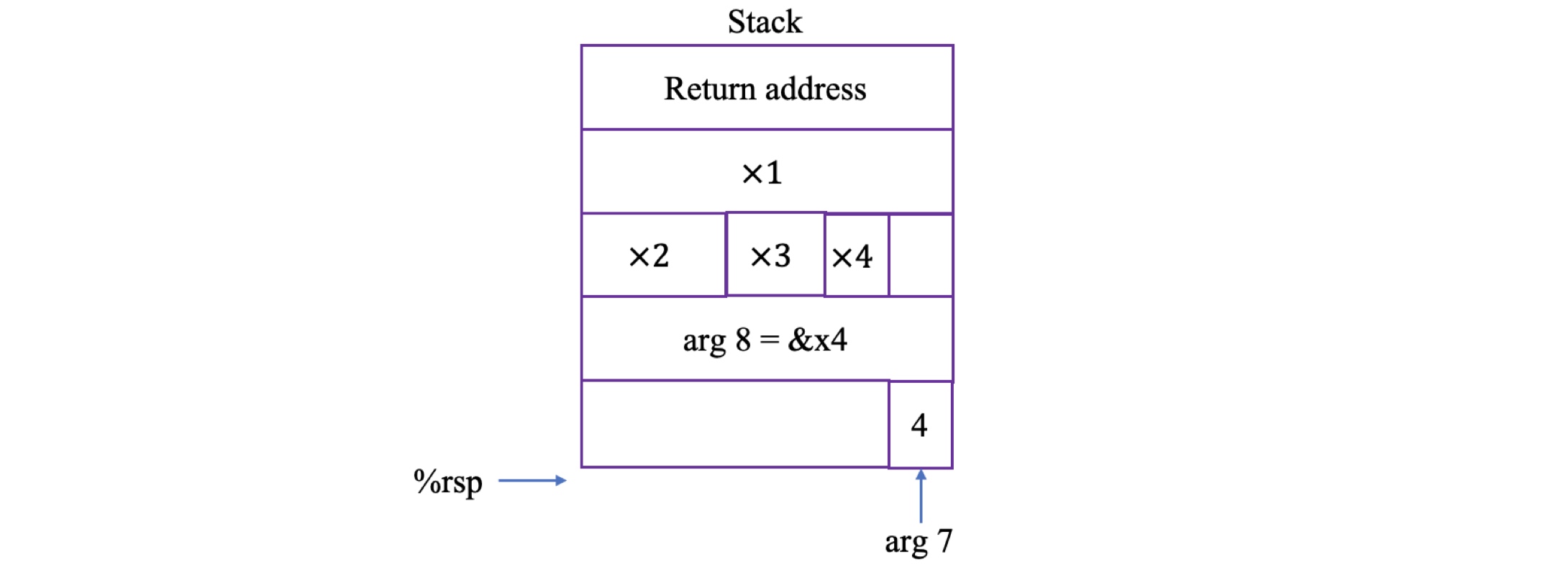
递归程序调用过程
以斐波那契数列递归调用代码为例:
数组、指针内存访问
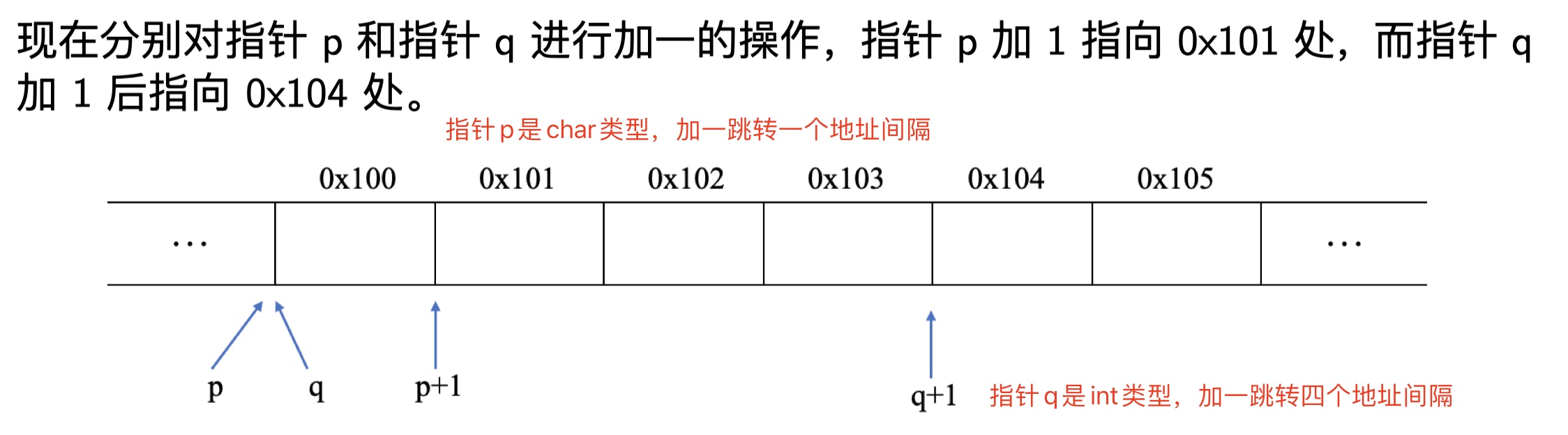
数组在内存中是一段连续的空间,至于其每个单元的地址间距,与其单个元素类型字长有关。指针在内存中的加一跳转与指针的类型有关,若指针是char类型,每次加一仅跳转一个地址单元,若指针是int类型,则每次加一跳转四个地址单元,如下图:
二维数组的存放如下图所示:

所以可以看到,数组行号不变,按行遍历效率要高于列号不变按列去遍历。
结构体对齐的计算不再说明,总结就是,结构体元素类型的排列顺序会影响其最终的结果,结构体内存对齐的设计也是为了提升寻址效率;相比于结构体的内存对齐,联合体的设计更加巧妙,并且节约空间,联合体中多个元素共享同一块地址空间。关于内存对齐的细节,可此参考文章:[Link]
避免栈缓冲区溢出攻击的方法措施
缓冲区溢出攻击的普遍发生给计算机系统造成了很多麻烦,现代编译器和操作系统实现了很多机制来尽量避免这种攻击,限制入侵者通过缓冲区溢出攻击获得系统控制的方式,这里有一种避免缓冲区溢出的方法:栈随机化。以下是书中对栈随机化的介绍,避免安全单一化,每次程序执行前,在栈上提前分配若干字节空间,后续程序栈地址就会发生改变,以此来达到随机化的目的,避免入侵者确定栈空间具体位置。

第二种方法则是栈破坏检测,若栈发生"下溢",则可以在将函数的返回地址压栈的时候,加上一个随机产生的整数,如果出现了数组越界,那么这个整数将被修改,这样在函数返回的时候,就可以通过检测这个整数是否被修改,来判断是否有"下溢"发生。这个随机的整数被称为"canary",它的原意是金丝雀,这种鸟对危险气体的敏感度超过人类,所以过去煤矿工人往往会带着金丝雀下井,如果金丝雀死了,矿工便知道井下有危险气体,需要撤离。
那怎么加上这个canary呢,只需要在gcc编译的时候,加入"-fstack-protector"选项即可。一个函数对应一个stack frame,每个stack frame都需要一个canary,这会消耗掉一部分的栈空间。此外,由于每次函数返回时都需要检测canary,代码的整执行时间也势必会增加。

那么以上则是对csapp中程序机器级表示的相关总结。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号