福大软工1816 · 第二次作业-个人项目
Part 1.卷首语
本次的开发环境
- Windows 10 64bit + Eclipse + JProfiler
Part 2.PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | --- | --- |
| · Estimate | · 估计这个任务需要多少时间 | 10 | 20 |
| Development | 开发 | ||
| · Analysis | · 需求分析 (包括学习新技术) | 120 | 150 |
| · Design Spec | · 生成设计文档 | 20 | 30 |
| · Design Review | · 设计复审 | 10 | 20 |
| · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 20 | 20 |
| · Design | · 具体设计 | 60 | 40 |
| · Coding | · 具体编码 | 700 | 1320 |
| · Code Review | · 代码复审 | 30 | 30 |
| · Test | · 测试(自我测试,修改代码,提交修改) | 30 | 60 |
| Reporting | 报告 | ||
| · Test Repor | · 测试报告 | 40 | 60 |
| · Size Measurement | · 计算工作量 | 20 | 20 |
| · Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 20 | 60 |
| 合计 | 1080 | 1830 |
Part 3.解题思路
首先问题的大致要求是需要统计文本中的各参数数量与词频,整体的先后思路如下:
- 1.首先要做的事情就是将.txt中的文本转换为可操作的字符串(结果还需要写入.txt文件中),这个过程关系到文件流操作;
- 2.对于可操作的字符串,要对其进行筛选、转化、切割、选择(开头4个字母后含若干个字母数字的形式);
- 3.对于处理后的单词集,需要对其进行词频统计,并在统计结束后排序好先后顺序传回主函数,基本任务完成。
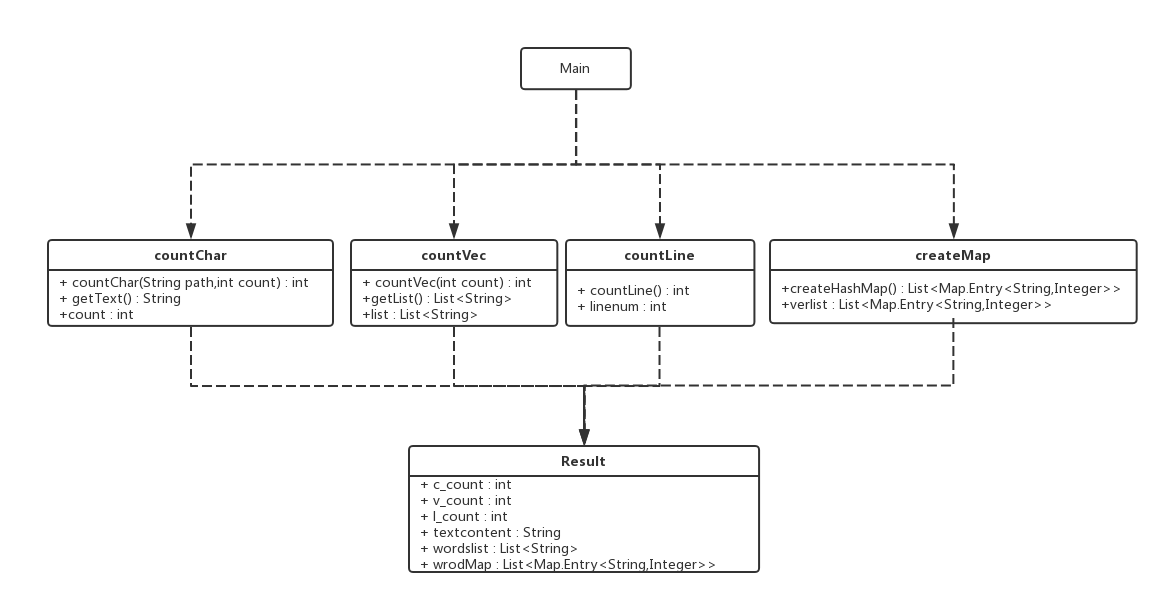
Part 4.实现过程
- countChar:负责字符数的统计;
- countVec:负责单词数的统计;
- countLine:负责行数的统计;
- createMap:负责处理HashMap词频表的建立
Part5.关键代码展示
简单的列出主要花费自己心思去写的两部分代码,其余的详细请见github上的源码。
对于单词的选择,我主要利用的是正则匹配的方式来选择,先将内部不符合的元素用某一符号代替,而这一符号将作为下一次分隔符标志,利用Pattern和Matcher去除非英文数字字符,而后进一步对单词的样式进行约束,对于符合正则表达式的单词加入列表中提供给后续使用
public static int countwords(int count,String text){
list.clear(); //做初始化清空字符集处理
String regex ="[^0-9a-zA-Z]"; //剔除文本中的非字母和数字的部分并以!作为暂时的分隔符
Pattern pat = Pattern.compile(regex);
Matcher mat = pat.matcher(text);
text = mat.replaceAll("!");
String [] textArray = text.split("!+"); //按照分隔符划分
String v_regex = "^[a-z]{4}[a-z0-9]*$"; //对单词形式进行约定
for(String i:textArray){
Pattern v_pat = Pattern.compile(v_regex);
Matcher v_mat = v_pat.matcher(i);
if(v_mat.matches())
list.add(i);
}
return list.size();
}
对于词频分类和统计,这里利用了HashMap,简单且易查找,<Key,Value>的形式很好的记录了<单词本身,出现次数>这样的记录。最后将记录好的Map进行排序,按照题给要求,先以Value值做参考,在Value值相同的情况下,以Key值优先为准。
public static List<Map.Entry<String,Integer>> createHashMap(List<String>list){
Map<String,Integer> ver = new HashMap<String, Integer>();
for(String i:list){
if(!ver.containsKey(i))
ver.put(i, 1);
else{
Integer num = ver.get(i);
ver.put(i, num+1);
}
}
List<Map.Entry<String,Integer>> verlist = new ArrayList<Map.Entry<String,Integer>>(ver.entrySet());
Collections.sort(verlist,new Comparator<Map.Entry<String, Integer>>(){
public int compare(Map.Entry<String, Integer> o1,Map.Entry<String, Integer> o2) {
if(o1.getValue()==o2.getValue()){
return (o1.getKey()).compareTo(o2.getKey());
}
return o2.getValue()-o1.getValue();
}
});
return verlist;
}
下面主要是我对于IO操作的异常进行处理的基本形式
public static int countChar(String path,int count) throws IOException{
try {
...
} catch (FileNotFoundException e) {
e.printStackTrace();
}finally{
...
}
return count;
}
Part6.性能分析

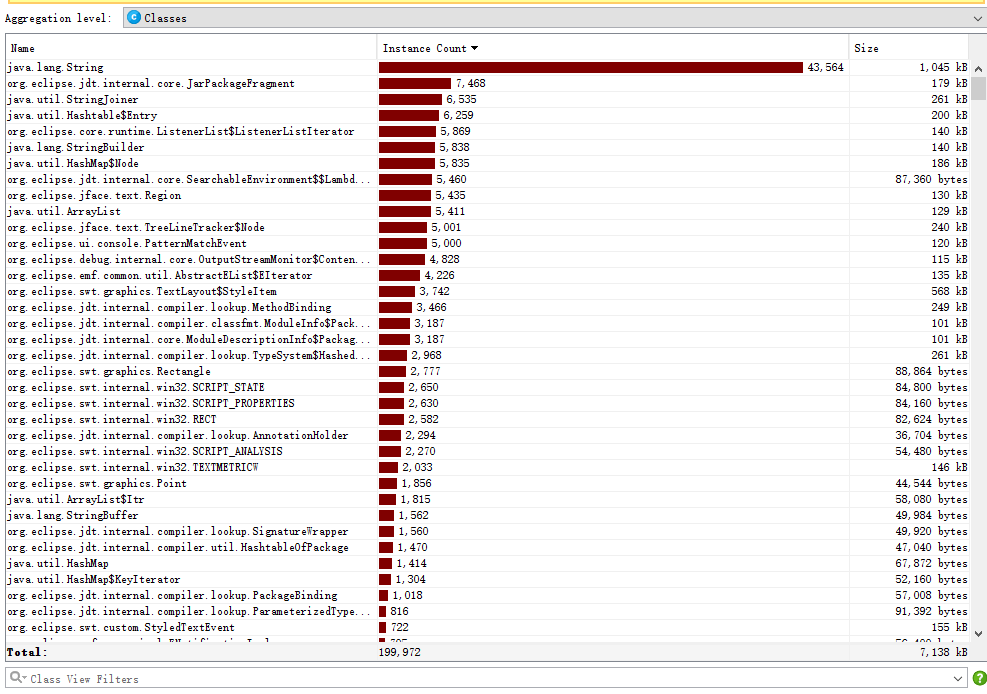
以下主要是调用各个不同类中的接口,所以Main中的覆盖率会为0,整体的情况符合正常的操作结果。
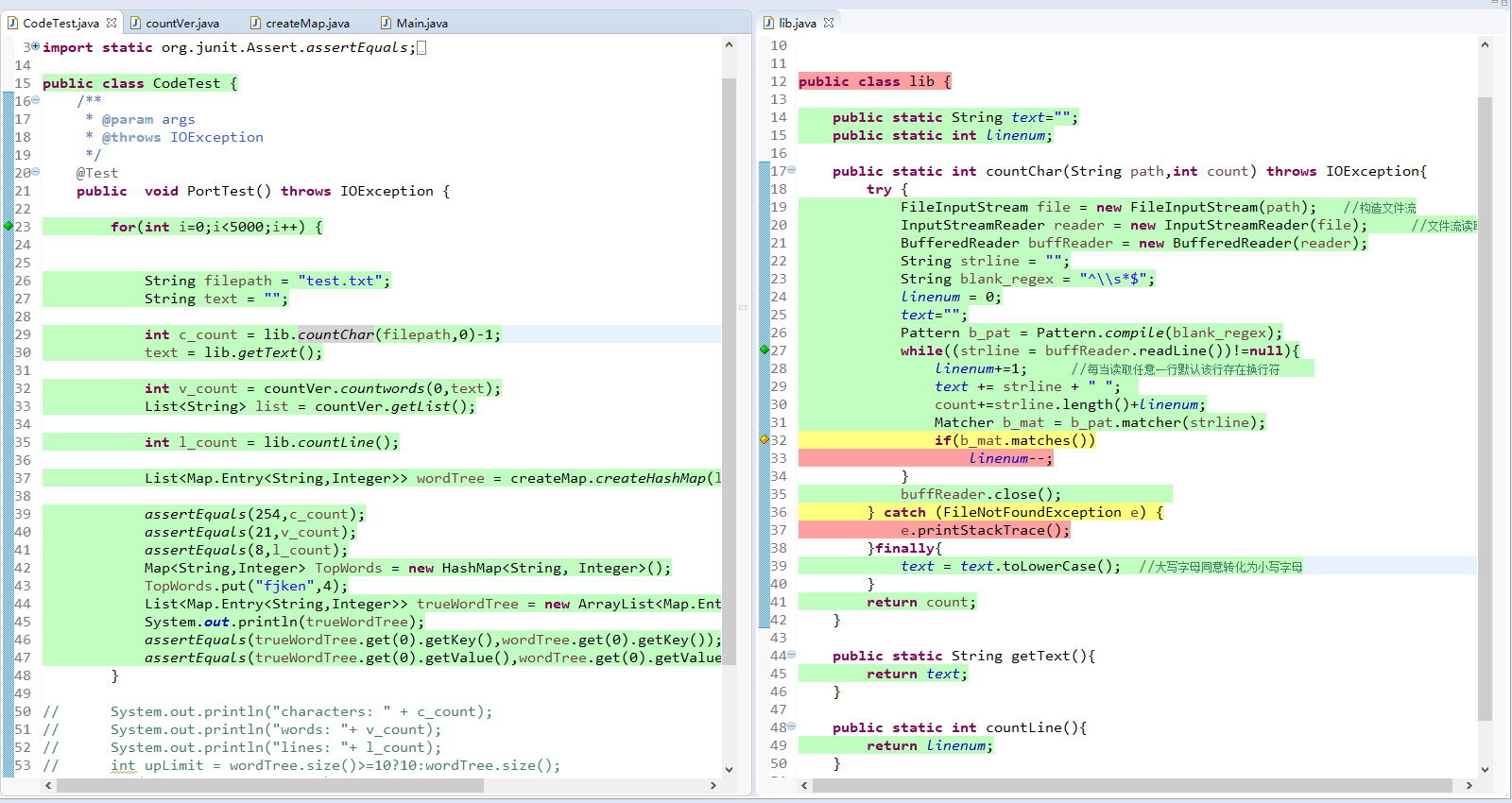
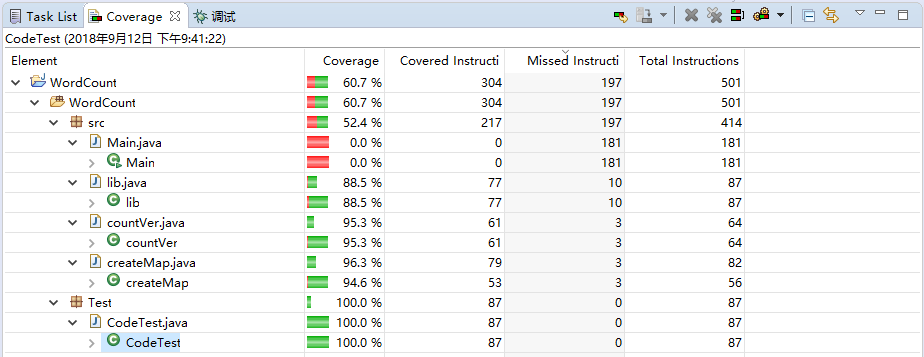
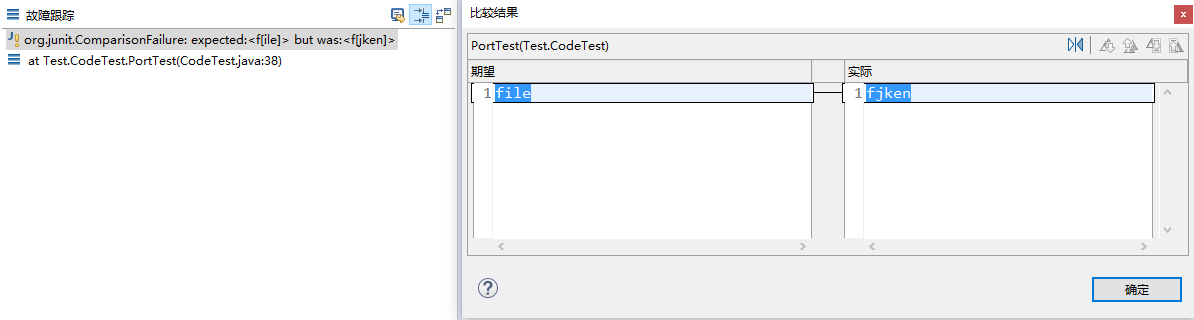
进行单元测试的过程中,可通过如下的报错来寻找自己的疏漏之处,每一环节都能够很好的定位到。
Part7.感想
有了初步的构思以后,边学习边敲java代码,实践中去逐步的完善自己,总体来说,我对自己的表现还是挺满意的。过程中接触了单元测试,找到了自己许多原先疏漏的小细节,在逐步改进之下完善着自己的代码。怎么说呢,可能还是自己的慢性子的原因,每天都在投入时间去边敲边改,但是很遗憾,得出最终成果的时间还是压到了接近与deadline之前一些些,所以我对自己下一次任务的期望是自己能够有更高的效率,达到更好的效果,以上。
也希望大家能够对我提出宝贵的意见,谢谢大家,小废的程序员之路道阻且长......
Part8.后记
后续在完成作业以后,看到了许多同学都有意识的去讨论测试数据的大小问题,所以自己也做了一下大型文本的测试,果然发现出错。总结一下自己得出的结论:String对于连接操作(“+”)效率很低,因此导致了我程序一直没办法正常运行,后改用StringBuilder,利用.append()方法来进行文本的逐行拼接,成功解决了上述所困扰我的问题。(更新代码内容详见github源码部分),后续将会对为什么String效率低的问题分析好后作出解释,暂告一段落,谢谢(附上大型数据测试情况)
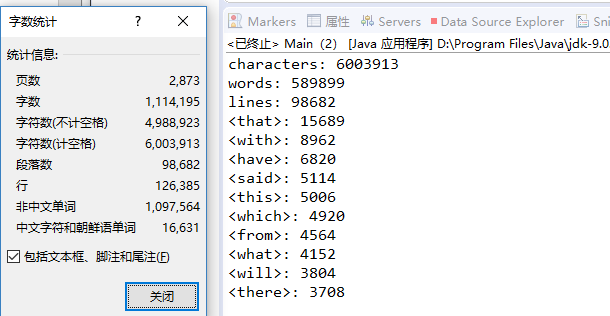
这里简单的结合office word自带的字数统计功能校验如下: