

十件你需要知道的事,关于openstack-trove(翻译)
开源数据库即服务OpenStack Trove应该知道的10件事情
作者:Ken Rugg,Tesora首席执行官
Ken Rugg是Tesora的创始人,CEO和董事会成员。 Ken的大部分职业都是在数据库的技术,战略和业务发展方面。 Tesora是OpenStack Trove项目的主要贡献者。
谈到DBaaS(数据库即服务),当今的公共云市场领导者,亚马逊,正在展示这一业务在客户价值和利益方面的重要性。去年年底,亚马逊网络服务(AWS)数据库业务的年收入运行速度为10亿美元。毫不奇怪,在同一时间框架中,AWS最受欢迎的招聘类别是84个职位的数据库和数据分析。
看到这种成功,OpenStack云(公共和私有)的运营商也希望能够为用户提供这种功能也不足为奇。 OpenStack Trove允许他们这样做。 Trove是数据库作为OpenStack的服务组件,使管理员和DevOps专家使用公共基础架构管理不同数据库管理系统(DBMS)的多个实例,包括关系数据库和NoSQL。它使数据库的容量可按需使用,并处理完整的数据库生命周期管理。
如果你对OpenStack和数据库即服务感兴趣,那么这里有一些你应该知道的事情。
1. 简单来说,OpenStack Trove的目标是快速,轻松地部署和管理各种数据库。
OpenStack Trove项目任务声明是“为关系型和非关系型数据库引擎提供可扩展和可靠的云数据库即服务的供应功能,并继续改进使其成为功能齐全,可扩展的开源框架。”为了实现这一点, Trove有自动化且复杂的数据库管理任务,包括部署,配置,修补,备份,恢复和监控。 Trove允许IT专业人员通过单一一致的接口集为用户提供配置和管理各种关系数据库和非关系数据库的能力。
Trove DBaaS极大地提高了敏捷性。虽然快速配置数据库的价值相当可观,但IT客户可以轻松地丢弃数据库并提供新数据库这一事实同样重要。这使得可以通过实验,以快速达到正确的长期的解决方案,而没有不必要的妥协。已经是请求数据库服务器并等待几个星期或几个月进行配置的天数。用户只需请求数据库实例,具有复制或群集的一些实例,以实现可扩展性。
2.只有OpenStack Trove提供了一个框架,可以以一致的方式操作13种不同的DBMS技术。
451 Research的一项调查指出,当涉及到数据库时,企业可能会有不同的供应商来使用不同的用途。这些将包括SQL和NoSQL数据存储,它们针对操作和分析工作负载以及开源数据库和商业数据库产品进行了优化。随着这些企业转向私有,公共和混合云实施,他们也同时带来了这些数据库。
虽然企业现在使用大量的数据库,但他们的管理平台传统上是技术特定的。这一趋势在很大程度上继续下去,因为数据库管理已经转移到云中,而单一数据库DBaaS产品主导了这一趋势。其示例包括Azure SQL数据库(Microsoft SQL Server),MongoLab(MongoDB)和Cloudant(CouchDB)。虽然Amazon的关系数据库服务(RDS)支持少量不同的数据库,但它们都是具有相似架构的传统关系数据库。而且,AWS提供了完全不同的管理技术,以分别支持使用Redshift和DynamoDB的数据仓库和NoSQL数据管理。
Trove采用了一种根本不同的方法,通过创建一个可插入的架构,可以从公共基础架构支持许多不同类型的数据库。 OpenStack Trove目前支持Cassandra,CouchBase,CouchDB,DataStax Enterprise,DB2,MariaDB,MongoDB,MySQL,Oracle,Percona Server,PostgreSQL,Redis和Vertica。
3. Trove独特的架构是支持各种各样的数据库技术的关键,同时展示每一个数据库最好的。
OpenStack Trove架构具有许多独特的功能,可以支持许多不同的数据库技术。这种架构的关键要素是Trove控制器(Trove Controller),客户代理(Guest Agent)和客户映像(Guest Images)。
在系统的中心是Trove控制器,是数据库不可知的。用户通过GUI或API与控制器交互,以管理各种数据库。如果用户想要执行备份或创建数据库的副本,则他们不必担心为某些特定数据库引擎执行此操作所需的特定调用。
客户代理是“数据库适配器”,它将Trove控制器接收的命令转换为特定数据库的语言。为了支持新类型的数据库,一个可以实现新的客户代理来实现必要的API,允许用户以标准方式管理该数据存储。
为了便于快速部署数据库实例,按需为每个数据存储库的每个版本提供客户映像。这些客户映像仅仅是将数据库服务器软件与客户代理代码捆绑在一起的虚拟机映像。
当客户映像引导时,它会自行解包,并生成一个完整服务的即用型数据库实例,从而无需从头开始配置和配置数据库。客户映像可以由操作员配置或从公共来源下载。
此外,客户映像可以预先构建在优化的配置中,这些优化的配置经过调整以提供最佳性能,并符合行业最佳实践的安全性和可靠性。这些标准化配置还使IT人员更容易管理这些系统。当数据库供应商发出新的安全警报以解决新发现的漏洞时,可以用修补的版本替换访客映像,并且可以批量更新所有受此问题影响的系统。
4.除了基本配置,Trove自动化它规定的数据库实例的生命周期管理。
当人们首先考虑数据库作为服务时,他们通常只想到开发人员能够从基于Web的UI按需启动数据库服务器的能力。虽然Trove一定能做到这一点,它也可以做更多。 Trove提供API来自动执行备份,群集,复制和故障转移等任务,并以一种方式利用其支持的底层数据库引擎的本机工具。
当然,在MongoDB实例或Cassanda集群上执行像备份这样的管理任务可能使用与备份Oracle或MySQL实例非常不同的方法。然而Trove架构确保管理员不必担心这个细节。这样,可以通过标准的一组接口来统一和简化各种数据库技术集的管理和操作。例如,当需要备份时,管理员只需通过API,命令行或Web GUI发出trove backup-create命令,并且Trove将为要备份的特定数据存储启动适当的本地进程。
5. Trove允许您像单个实例一样轻松地管理数据库集群。
如前所述,Trove经常与Amazon RDS进行比较。 OpenStack Trove超越亚马逊RDS(或其他简单的DBaaS产品)提供的一个领域是集群管理。 用户可以通过Trove GUI或API直接创建,增长和收缩数据库集群。 该接口具有足够的灵活性,可以容纳从关系数据库(如支持主主复制的传统并行数据仓库,如Veritca)到对等分布式NoSQL键值对存储(如Redis)的各种群集架构。 目前,对于MongoDB,Vertica,MySQL和Redis,集群支持可用,Cassandra和Couchbase将在下一个版本中提供。
6.通过基于Web的GUI,命令行界面或一组RESTful API,可以访问Trove的所有功能。
虽然Trove经常通过其基于Horizon的Web面板来配置和管理数据库,Trove提供的所有功能也可以使用Trove命令行界面或通过一组完整的RESTful API。 这使得自动化管理任务变得容易。 Trove可以内置到必须启动大量数据库服务器以适应不同使用场景的自动化测试系统中。
7. Trove可以在您自己的公司数据中心操作,以确保符合公司政策,如数据保留和隐私。
当OpenStack Trove在数据中心内部作为私有云部署时,它由公司的IT人员操作,该人员可以确保其遵守企业最佳实践和策略(如数据保留,数据隐私,加密和备份)。虽然基于公共云的DBaaS产品可能提供相同的工具,但确保这些工具适当地应用通常落在配置数据库的个别开发人员身上。这可能导致与企业或甚至监管政策的不一致遵守。当在公司治理和数据安全的范围内运行Trove时,用户可以放心,他们部署的配置已经过IT审查,以验证他们遵循行业最佳实践,公司政策和适用的数据保护法律数据。
8. Trove是历史上增长最快的开源项目的一部分。
在这一点上,开源软件的好处是很好理解的。随着社区的广泛参与,它可以产生更高质量,更安全的代码,同时消除供应商锁定。由于Trove是OpenStack的一部分,它受益于成为历史上增长最快的开源社区的一部分。根据OpenHUB,OpenStack项目已经有来自超过3500个人的贡献,近一半的数字贡献在过去一年。
Trove是一个非常健康的开源项目,来自40个不同公司的超过200个人在该项目的整个生命周期内做出贡献。虽然许多贡献来自支持OpenStack或Trove像Red Hat,HP和Tesora的公司,使用该平台的企业也是积极的贡献者。例如,eBay已经为多个数据库添加了支持并在项目中实施了初始集群支持。
9. Trove利用OpenStack的核心组件和共享服务,使企业能够轻松部署DBaaS。
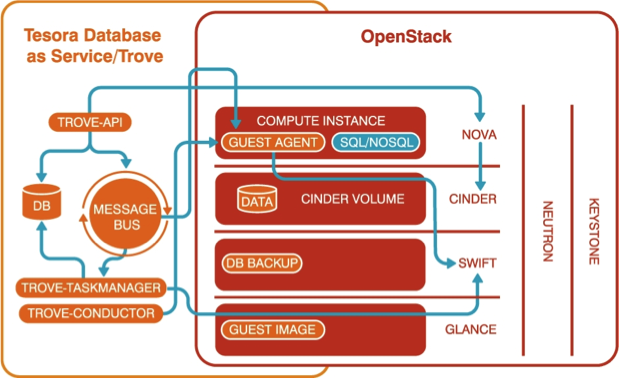
转述Sy Sperlling的Hair Club for Men,(冒着展示我的年龄的风险)“Trove不仅是一个OpenStack项目,而且它也是一个客户端。”例如,Trove使用Nova计算服务创建虚拟机,运行数据库服务器,Cinder块存储配置数据库存储以及Swift的对象存储来捕获备份,如图所示。由于Trove是这些核心服务的分层,其用户可以利用这些服务,而无需任何特殊的定制。他们还可以受益于对OpenStack的底层核心服务的任何增强。例如,如果Nova被配置为通过OpenStack Ironic服务提供裸机资源,Trove可以利用它。此外,重要的是,使用开源软件通过减少对技术供应商的依赖,以及价格波动的潜在风险,从私有云实现中消除了大量的风险。
10.很容易开始使用OpenStack和Trove,有很多资源可以帮助
OpenStack Trove是一个DBaaS平台的开源实现,由一个积极和多样化的开发社区支持,继续扩展其功能。所有以下选项,以及其他信息和链接,可以在“如何开始使用OpenStack”页面找到。
尝试在这里列出的世界上生产的许多OpenStack公共云之一。
使用devstack在您的笔记本电脑(甚至在虚拟机中)上运行OpenStack云。这对于从管理员或用户角度看看OpenStack的外观是非常理想的。
通过商业软件分发安装OpenStack。你可以找到这里列出的。
具体到Trove,在这里你可以找到一个分步指南安装和入门OpenStack Trove。 Tesora还在我们的网站上提供了一组Trove资源。
如果你想采取下一步和贡献的项目,也有很多方法来做到这一点。作为一个开源项目,Trove欢迎参与。我对那些想要参与的人的建议是简单的,做到。我遇到的大多数“想要贡献”的人认为这很难,或者他们必须写很多代码。这不是真的。贡献不一定是复杂的代码,功能或蓝图。例如,代码审查非常有价值,它们是了解社区,代码和Trove本身的好方法。阅读文档,使用产品,贡献错误,草拟可用于改进文档的简短写法,以及与他人分享您自己的使用Trove的提示和技巧。这些都是参与的好方法。
原文地址:http://www.odbms.org/2016/02/10-things-you-should-know-about-openstack-trove-the-open-source-database-as-a-service/
此文章属博客园用户S-tec原创作品,受国家《著作权法》保护,未经许可,任何单位及个人不得做营利性使用;若仅做个人学习、交流等非营利性使用,应当指明作者姓名、作品名称,原文地址,并且不得侵犯作者依法享有的其他权利。

