Paper | Taskonomy: Disentangling Task Transfer Learning
Taskonomy: Disentangling Task Transfer Learning
1. 问题
如果我们已知某些视觉任务之间的关联性,那么我们就更好地设计我们的方案。例如,我们可以在这些有关联的任务中,共享监督信息,从而减少对训练数据的需求以及计算量,降低任务系统的复杂度。
关于关联性的挖掘,我们着重介绍Taskonomy: Disentangling Task Transfer Learning这篇文章,来自于斯坦福和伯克利大学,是CVPR2018的best paper。
本文出发点:视觉任务之间是否具有关联性?关联性有多强,怎么衡量?
在本文中,这种关联性及其强弱由一个有向网状结构衡量。作者原话是:
Here what we mean by "structure" is a collection of computationally found relations specifying which tasks supply useful information to another, and by how much.
该结构如图:
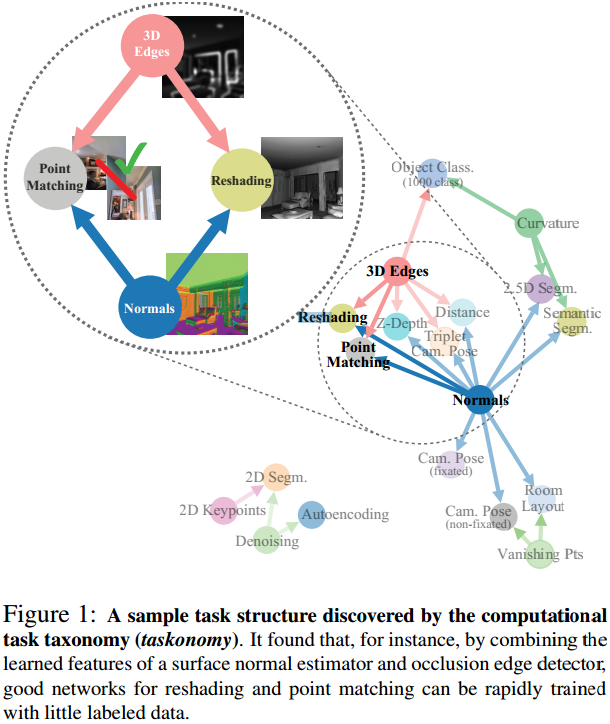
图中有23个任务,但在本文中一共研究了26个任务之间的相关性(作者称这26个任务的集合为一个词典)。
这其中有low-level的任务,如去噪,也有high-level的任务,如图像理解Semantic tasks。
有向箭头的起始节点称为“源任务(Source)”,汇入节点称为“目标任务(Task)”。
2. 方法
那么这个结构是如何得到的呢?下图给出了基本流程:
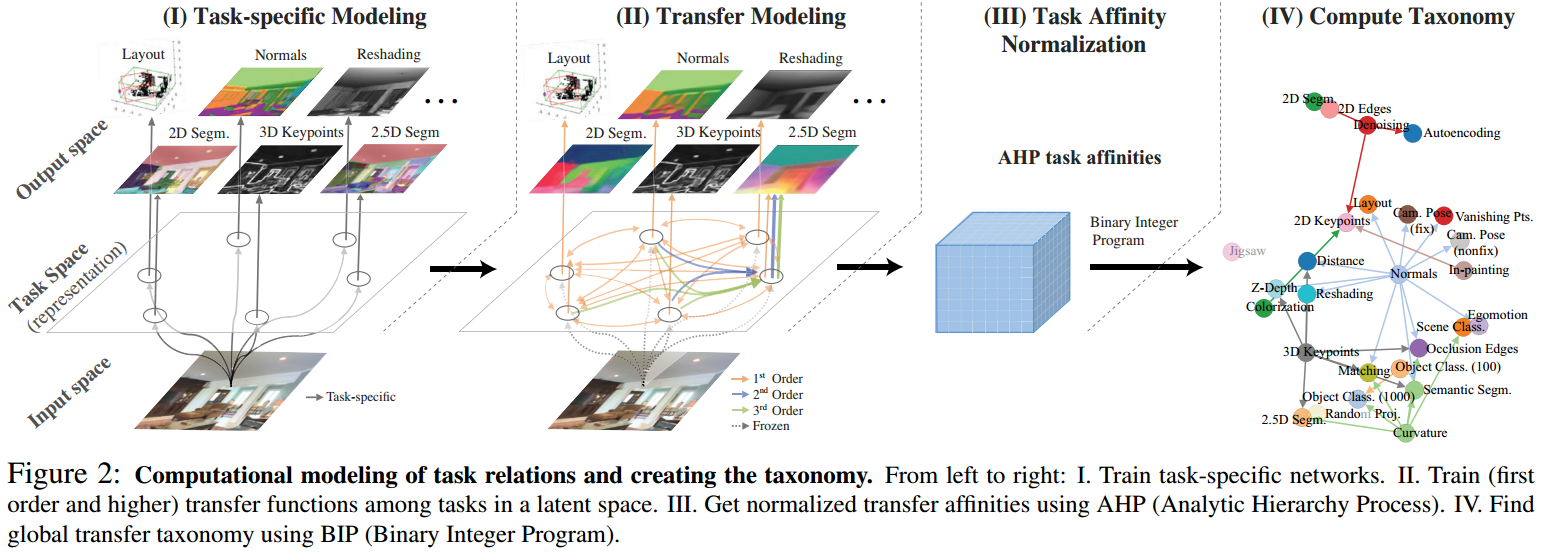
-
第一步,对每一个源任务分别进行训练,得到各自的模型和结果。
这一步和我们通常做的一样,我们继续看。
-
第二步,我们把刚刚分别训练得到的多个模型的中间结果取出来。
我们可以认为这些中间结果代表:在各自任务下,对输入图像的抽象表示(Representation),与源任务是一一对应的。
然后,我们将这些源任务的Representation,迁移到目标任务上。具体方法是,将源任务中间结果作为输入,输入到一个目标任务(与源任务不同)的网络中,继续训练,并得到最终模型。 -
第三步,测试已经训练好的模型。
可以想像,如果源任务和目标任务的关联性较强,那么迁移就会比较成功,测试结果就会比较理想;反之,若关联性不强,那么迁移就可能不理想,测试结果很糟糕。我们看一个例子:

上一排的源任务是曲线法线任务,下一排的源任务是2.5D分割任务。可见,迁移到不同目标任务的效果是不同的,其中Reshade效果最佳。有趣的是,Reshade效果比Scratch效果还好,Scratch是没有迁移的模型,并且数据量是迁移训练的60倍。
因此,本文用迁移模型的测试结果,作为衡量关联性的一个指标。
归一化后,以源任务和目标任务为两个坐标,我们得到源任务和目标任务之间的关联性矩阵(Affinity matrix)。 -
最后一步,我们通过BIP算法,得到最优迁移策略。
优化目标的是总体的和表现(Summation)最佳(回忆,我们通过测试表现来衡量关联性,反之亦然,我们通过关联性矩阵来量化预期性能),限制条件(可行域)是给定的监督预算(Supervision budget),在本文中定义为从零学习的源任务数目。最后,我们就得到了关联结构。
注意事项:
-
第一步为了控制变量,Encoder网络是统一的Res-Net50模型。
-
在迁移时,迁移网络应该浅(约2层),数据量少(只有迁移前训练的\(\frac{1}{8}\)到\(\frac{1}{120}\))。反之,各目标任务的效果都将会很理想(网络复杂,训练集大,怎么能不理想),无法比较可迁移性。
-
迁移后,由于目标任务的不同(分类问题或pixel-to-pixel问题等),Decoder网络会略有不同。
-
源任务包括多个任务的组合(作者称为High-order transfer,阶数即任务组合数),迁移时的组合方法即合并通道再输入。显然26个任务是任意组合是非常多的,因此作者对每一个目标任务,只考虑其1阶迁移时表现好的前几个任务。
-
作者研究了多次迁移(a→b→c),发现和一次迁移(a→c)效果接近,因此在本文中不考虑多次迁移。
-
测试loss不可以直接作为关联性指标,否则会出现下图左所示的情况:loss值域不一致。
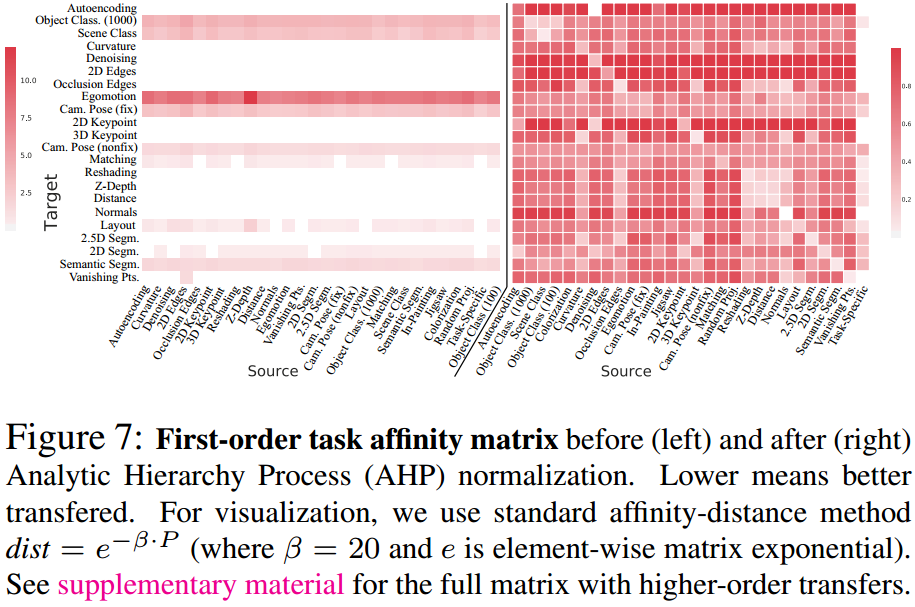
那么可以线性拉伸到\([0,1]\)吗?不可以,因为loss和模型表现不具有线性关系。两个模型,前者loss为0.01,后者loss为0.02,并不意味着前者是后者的两倍好。
因此,作者首先进行了相对优劣测试。对于同一个目标任务,在同样的测试集上,两两测试迁移模型的表现,计算二者的相对胜率。比如,迁移模型1在60%的测试图片上胜出,迁移模型2在40%的测试图片上胜出,那么迁移模型1就比迁移模型2强\(\frac{60}{40}\)倍,迁移模型2就比迁移模型1强\(\frac{40}{60}\)倍。然后,利用AHP方法,就可以将相对权重转换为绝对权重,并且这些绝对权重是在\([0,1]\)之间的。这些绝对权重就是所谓的关联性指标。
-
我们还可以给不同的目标任务以不同的重要性(权重),或者量化标注任务难度,来调整我们的BIP优化策略。
3. 实验设计
最后,作者是怎么设计实验来验证该方法的呢?
首先作者强调,本文的重点不在“超越state-of-the-art",因此只拿了Depth estimator模型和state-of-the-art进行对比,发现胜率达到88%,loss也更少。本文训练的很多task-specific网络的性能都超越了state-of-the-art。
其次,作者分两部分验证方法的有效性:
- 解决一组词典中的任务
- 解决一个只有少量标注数据的新任务
3.1 解决词典内部(一组已知)任务的能力
首先,我们来看解决词典中目标任务的能力。结果如图:

实验中有两种限制。第一个是最高迁移阶数(Transfer order),作者实验了最多允许一阶、二阶和四阶迁移的情况。
第二个限制是监督预算(Supervision budget),即最多可以训练的源任务的数目。当监督预算小于26时,由BIP决定谁可以作为源任务。
我们看到,当监督预算为26,即词典中所有26个源任务都可以被利用时(此时所有的26个任务也都分别进行了task-specific训练),仍有一些迁移箭头。这些箭头意味着,这些迁移模型比Fully supervised task-specific训练得到的模型还要好!回忆!我们在迁移模型上用的数据,是Task-specific的\(\frac{1}{8}\)到\(\frac{1}{120}\)!
进一步,作者设置了两个量化指标:
- 迁移获利(Gain):迁移/不迁移所用的数据量一样多(都很少),来比一比胜率。
为什么都要少而不是都多?因为如果数据量很大,迁移与否很难观察出差别,可迁移性难以观测。 - 迁移质量(Quality):迁移所用数据少,不迁移所用数据多(120k图片),来比一比胜率。
结果如图:

可见,当训练数据相同时,迁移模型可以完爆非迁移模型,甚至在预算很小的时候。当训练数据差距很大时,迁移模型也可以和非迁移模型打个平手。
3.2 解决新任务(少量标记数据)的能力
将任务词典里的一个任务抓出来作为目标任务,其他任务作为源任务。迁移训练数据量只有16K。
和上一个实验的区别在于,该目标任务没有源任务训练的Representation。
结果如图:
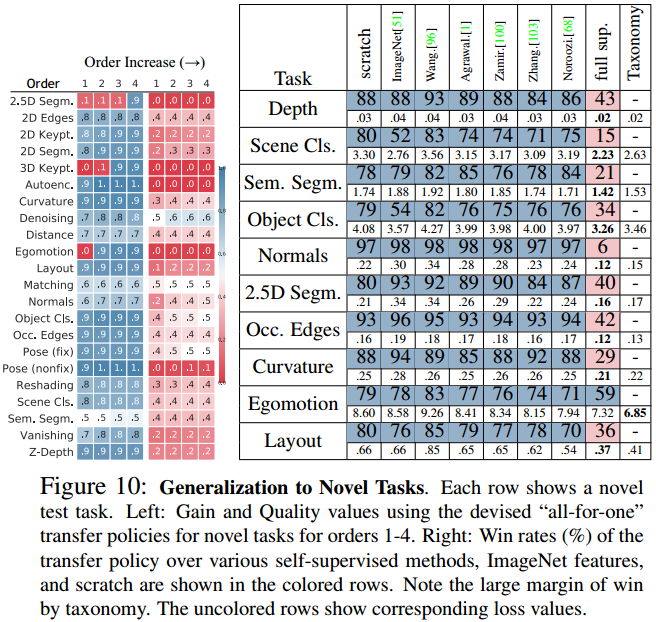
左图是获利和质量,依旧表现亮眼;注意这里是不限制监督预算的,只考虑阶数限制。
右图是比较在不同pretrained特征上迁移得到的模型。这些pretrained特征包括被广泛使用的ImageNet特征,以及从零学习的scratch特征。此外,还有一个Fully supervised network (gold standard)参与比较。
其中值得注意的是,Tax的迁移策略下提供的Representation,比从ImageNet获得的特征要好得多,也比单纯从零学习的模型要好。
最后,作者提供了一个关联树,该树基于Affinity matrix绘制:
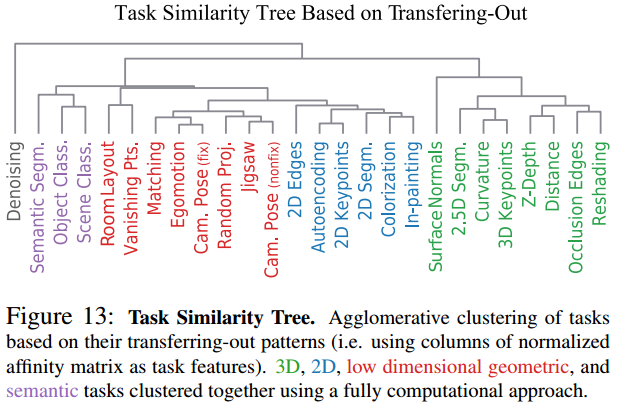
我们可以发现,该树和BIP的输出结果具有很强的相关性。
并且注意到,3D、2D、低维几何和语义问题可以联系在一起。
4. 讨论和启发
优点:
-
本文的方法是fully computational的,不掺杂任何主观因素。
这一点很有意义。因为直觉(强加的先验知识prior)可能会导致错误,比如法线 (Surface Normals) 可以由深度 (Depth) 求导得到,但实际上反向推导更容易由神经网络完成。 -
借助得到的关联结构,作者发现,在解决一个由10个视觉任务组成的任务集合时,所需标注数据量是单独训练所需的三分之一,同时保持性能接近。
缺点:
-
计算量巨大。为了得到关联结构,作者在云端训练了约3000个神经网络,GPU耗时超过47886小时(若单GPU,为5.5年)。从零学习消耗了120k图片,迁移学习消耗16k图片。
所以,如果我们要探究一个新任务和其他任务的关联性,仍然需要通过训练网络、对比测试的方法来实现。 -
为了得到关联性,其实我们已经将监督预算花光了。因此,本文的意义更着重于挖掘任务之间的相关性。
展望:
-
训练M个Encoder,用于N>M个Decoder。
-
指导多任务系统,可能减少数据量。
-
人的视觉系统优于计算机,有一个很可能的原因是:人的多种视觉能力可以互相纠错和矫正。
例如,如果人产生了对物体深度的错误认识,可以借助其对物体的识别和理解进行调整。
因此,我们也许可以将多个任务的网络联合在一起,同时训练,联合优化。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号