Paper | A Pseudo-Blind Convolutional Neural Network for the Reduction of Compression Artifacts
A Pseudo-Blind Convolutional Neural Network for the Reduction of Compression Artifacts
总结
问题:HEVC压缩视频的盲恢复。
背景:
- 当前方法都需已知量化参数QP,intra/inter coding,prediction unit sizes,deblocking filter on/off等。
- 作者认为,盲QP系统比非盲QP系统更实际,并且非盲系统的QP未必能真实反应图像质量。因此盲QP是必要的。
- 作者认为HEVC要比JPEG更复杂,不能套用JPEG方法。
解决方法:一个QP判决器,级联上四个并联的网络,每个网络服务1个QP。
评价:
- 这是第一个尝试盲QP图像恢复的论文,但实际上是伪盲(pseudo-blind)的。
- 方法上也没有HEVC的特性,背景3站不住脚。(ps. 作者后来又水了一篇IEEE ACCESS,就做JPEG)
非盲图像恢复子网络
首先介绍非盲的图像恢复网络IACNN。整体上看:
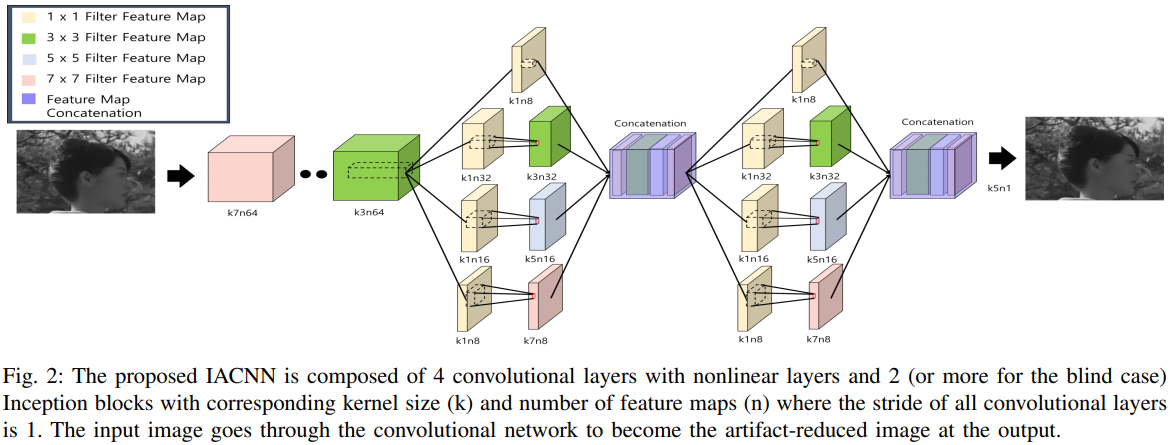
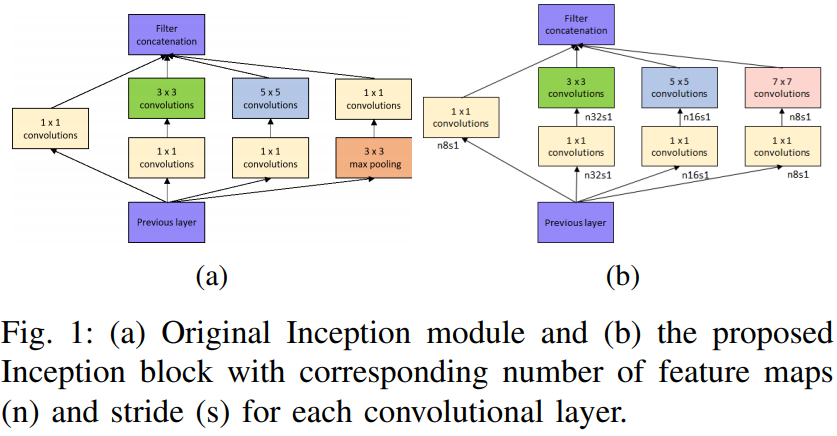
局部的Inception module:
作者对AVC考虑了5个QP:34、37、42、47、51,对MPEG-2和HEVC考虑了4个QP。即,整体框架中将有4/5个IACNN。
压缩系数预测子网络
这是一个19层、\(3 \times 3\)卷积的VGG网络,参数量高达5.8M。
作者先将图像分为块(patch),然后根据块的判决结果来决定该图像的QP。
训练时注意两点:
(1)我们不使用平滑区域的块,原因是:这些块的判决结果与QP几乎无关(任意QP,其结果几乎是一样的)。因此我们考虑具有丰富纹理的块,即具有较大方差(边缘和纹理)的块。
(2)连续帧可能有多个相似的块。为了避免冗余,我们隔50帧取一帧。
测试时注意三点:
(1)同样要选取方差较大(纹理较丰富)的块。
(2)对于JPEG等图像恢复任务,我们少数服从多数即可。对于视频恢复任务,为保证时序连续性,我们要让一个邻域内的所有帧都参与投票,附加权值。
(3)当邻域帧结果差异过大时,作者采用邻域为3的检测区间,避免场景切换的影响。【个人保持怀疑态度】
最终大网络就是这个样子,很简单都不需要多解释:
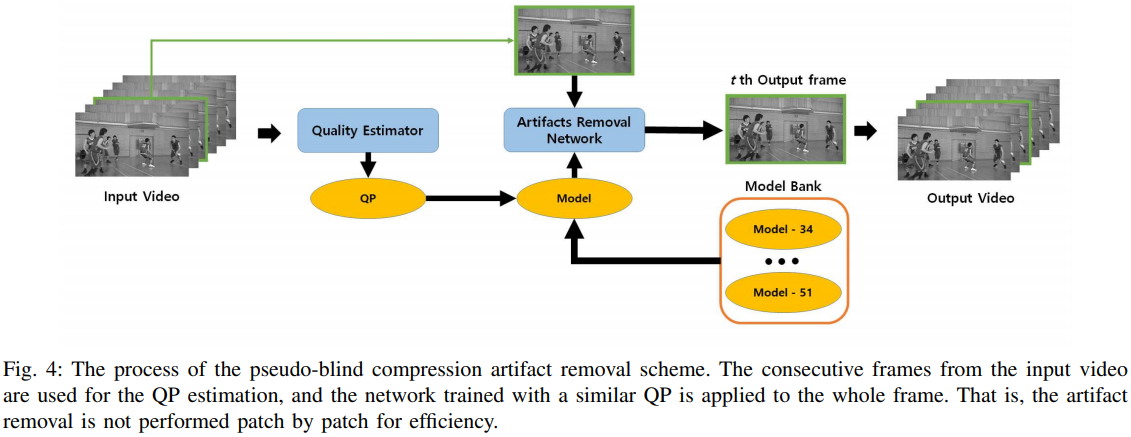
实验
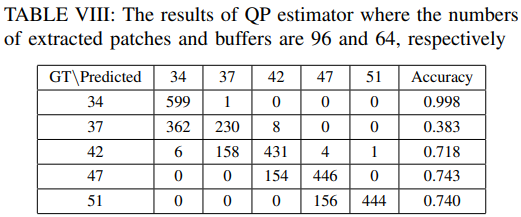
我们只看分类器的准确率:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号