Paper | One-to-Many Network for Visually Pleasing Compression Artifacts Reduction
One-to-Many Network for Visually Pleasing Compression Artifacts Reduction
发表于2017年CVPR。
目标:JPEG图像去压缩失真。
主要内容:
-
同时使用感知损失、对抗损失和JPEG损失(已知量化间隔,惩罚落在间隔外的值),让恢复图像主客观质量都更好。
-
对像素进行平移-均值化处理,进一步抑制块效应。
亮点:解释了one-to-many的合理性:由于图像恢复是欠定问题,因此理应有多张潜在的高质量图像 可供选择。但是最终没有体现one-to-many啊摔!而是加权组合了这三个损失函数,没有多输出。
故事
-
有损压缩被广泛使用,但是带来伪影。 => 去除伪影(压缩失真)是很重要的,因为伪影会导致用户观感下降 和 视觉任务精度下降。 => 当前,深度学习已经展示了强大的性能,但普遍导致过度平滑。
-
JPEG压缩失真主要是由于每个块的独立量化导致的边缘不连续(块效应)。量化是一个多对一的映射,然而目前的网络大多是一对一映射。因此,对于一张有损图像,我们应该得到多张潜在的高质量图像,再挑选。因此,一对多映射是更好的学习方式。毕竟,一千个人心中有一千个哈姆雷特。
-
一对多映射,就涉及到多个衡量标准。 => 首先,per-pixel损失是不够的。很简单的例子:我们将图像平移一下,per-pixel损失就会特别大。但二者的本质是一样的。 => 因此,我们引入感知质量。感知质量可以衡量高层语义上的距离。 => 但是,感知质量也不够:它对粗糙纹理的辨别能力不强【这里的论证太弱】。因此我们引入对抗损失,可以将网络引向更逼真的纹理细节。 => 在像素域上也希望有约束,因此引入JPEG损失,对落在量化间隔外的样本进行惩罚(已知量化水平和量化表)。
-
最后,作者还引入了平移-均值化(shift-and-average)方法,进一步抑制块效应(grid-like artifacts)。
网络设计
网络前端
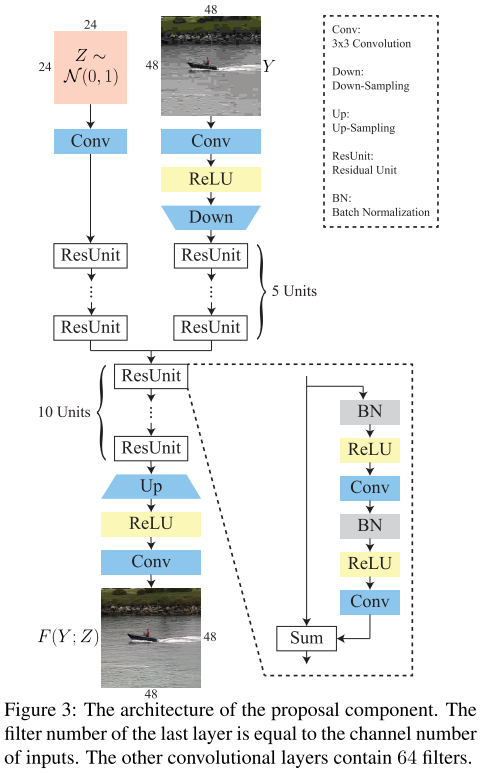
-
\(Z\)是AWGN,经过卷积后,会与 有损图像\(Y\)的卷积 相加,目的是让网络更健壮。有点意思。
-
一句话挺有意思:
As JPEG compression is not optimal, redundant information neglected by the JPEG encoder may still be found in a compressed image.
-
其中的降采样是步长为2的\(4 \times 4\)卷积,升采样是步长为2的\(4 \times 4\)反卷积。之所以降采样:(1)降低计算量;(2)增大感受野。
升采样中的平移-均值化
这里作者介绍了为什么要、如何做 平移-均值化。
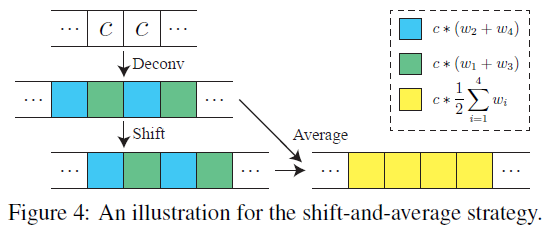
假设该信号中每一个值都是常数c。做步长为2的\(4 \times 4\)反卷积的步骤:首先插2个零,变成c00c,然后在卷积时就是平移取互相关。
作者发现,若我们平移一位再做反卷积,然后两个结果求平均,那么结果就是我们想要的常数结果。否则,结果非处处为常数。
当然,作者没有详细说明这样做的合理性。这不过是一个成功的例子。
网络度量
感知损失借助[39]的VGG-16,对抗损失借助[34]的DCGAN。
JPEG损失具体:计算有损图像\(Y\)和重建图像\(\hat{X}\)在每个像素点的距离。理想情况下,如果无损图像某个点的值是\(X\),那么其量化后的值\(Y\)不会超过其正负半个量化间隔。即,二者距离不会超过半个量化间隔。同理,计算出来的结果也应该在半个量化间隔内。
如果超过量化间隔的一半,就作为损失惩罚;若不大于一半,那么就为0。即取一个\(max(dis, 0)\)函数。
训练
果不其然,训练是综合三个损失函数,并非多输出。这怎么能叫one-to-many???

 浙公网安备 33010602011771号
浙公网安备 33010602011771号