Paper | Highway Networks
Highway Networks
解决的问题:在当时,人们认为 提高深度 是 提高精度 的法宝。但是网络训练也变得很困难。本文旨在解决深度网络训练难的问题,本质是解决梯度问题。
提出的网络:本文提出的网络结构统称为highway networks,允许在多层之间的无障碍信息流动【不仅是梯度,也是特征图的流动】。
特别之处:借鉴了LSTM的思想,使用可学习的门机制,调控信息流,即提供information highways。
1. 网络结构
高速网络的每一层都有一个门\(\mathbf{T}\),其输入就是该层的输入。若输出为\(\mathbf{1}\),则执行变换(transform);若输出为\(\mathbf{0}\),则执行搬运(carry),即恒等变换。
数学表达是这样的:
H是highway的意思,T是transform的意思。注意是element-wise相乘。
有几点问题:
-
要求每一层的输入\(\mathbf{X}\)、输出\(\mathbf{Y}\)、变换输出\(H (\mathbf{X}, \mathbf{W}_\text{H})\)和门输出\(T (\mathbf{X}, \mathbf{W}_\text{T})\)是相同维度的。当维度不同时,我们可以简单地借助补零或降采样。本文中,作者借助一个额外的卷积层完成维度变换。
-
所有\(\mathbf{H}\)(\(\mathbf{T}\))的权值是共享的。
-
在初始化\(\mathbf{T}\)时,其偏置\(\mathbf{b}_{\text{T}}\)设为负数。这是希望网络一开始就主动寻求信息流的搬运,只在必要时执行变换。这与Gers等人的LSTM的初始化思路很像。实验证明这种初始化方法非常有效!
实验略。
2. 分析
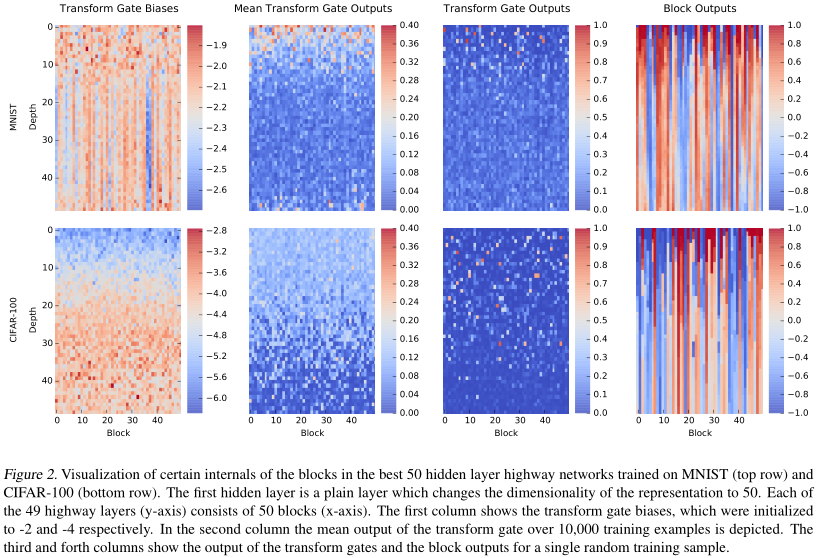
通过对权值的可视化发现:
-
训练后,初始为负值的偏置不但没有上升,反而变得更负【第一排第一列的偏置初始化为-2,现在更低了;第二排初始化为-4,也更低了】。但随着深度增加,CIFAR的偏置有所提升【第二排的偏置随着深度增加在降低】。
-
CIFAR变换门的输出却随着深度增加而降低趋于0【第二列第二排和第一列对比】。这说明,一开始强烈的负偏置并没有让门都为0,而是促进其选择性。
-
对同一个输入,变换门表现得非常稀疏,如第三列所示。
-
如第四列所示,大多数样本随着深度增加并不会发生太大变化。主要变化发生在网络浅层。
综上,高速网络最大的意义在于:跳过没有用的层,加快信息传递。而这种没有用的层在深度网络和简单任务中是非常常见的。
还有一篇补充论文《Training Very Deep Networks》发表在2015年NIPS。有时间再看~

 浙公网安备 33010602011771号
浙公网安备 33010602011771号