Paper | Deep Mutual Learning
Deep Mutual Learning
【算法和公式很simple,甚至有点naive,但文章的写作不错】
为了让小网络具有大能力,我们通常使用蒸馏。这篇文章提出了一种新方法:深度相互学习(deep mutual learning, DML)。与蒸馏法不同,相互学习中存在多个学生共同学习,并且每个学生之间要互相学习。实验还发现了一个惊人的结果:我们不需要piror powerful的教师网络,而只需要一群简单的学生网络共同学习,性能就能超越蒸馏学习。
1. 动机详述和方法简介
模型精简化有很多手段:精简的网络设计,模型压缩,模型剪枝,二元化(binarisation)以及最有趣的模型蒸馏。
模型蒸馏的动机是:小网络的表达能力与大网络相似,但是训练起来却不如大网络简单。换句话说,小网络的训练问题不在于尺寸,而在于优化。
因此,模型蒸馏法中设置了一个教师模型。较小的学生模型试图去模仿教师模型的分类概率或特征表达,而不再通过传统的监督目标来学习。教师模型是提前训练好的,因此蒸馏学习是单向学习。
而本文的做法不同。本文设置了一系列学生网络,共同学习。每一个学生网络都在2个损失函数下进行训练:一个是传统的监督学习的损失;另一个是模仿损失(mimicry loss),将其他学生的分类概率作为该学生的先验概率。
..., and a mimicry loss that aligns each student’s class posterior with the class probabilities of other students.
意义有三方面:(1)每一个学生网络的性能,都要比单独学习更好,也要比蒸馏学习更好;(2)不再需要一个强大的教师;(3)让三个大型网络相互学习,也比一个大型网络单独学习效果更好。即哪怕我们不考虑模型规模,只考虑精度,深度相互学习也能派上用场。
有没有理论解释呢?恐怕没有。即:到底增量归功于何者?首先,相互学习和蒸馏学习一样,都是给学生网络提供了额外的信息指导,即让学生网络落入更加合理的、共同的局部最优解。【有点像dropout,但不是对网络结构的健壮性改造,而是对优化策略的健壮性改造】
作者在行人重识别和图像分类上都进行了实验,效果比蒸馏学习更好。此外还有几点发现:
-
这种方法对多种网络结构都有效,或者对于多种大小网络的组合有效;
-
随着合作网络数目的增加,性能也有所提升。
-
这对半监督学习有帮助,因为模仿损失既对有标签数据有效,也对无标签数据有效。
2. 相关工作
相比于蒸馏学习,本文直接扔掉了教师网络的概念,并且允许一堆学生网络共同、相互学习。
相比于协同学习,本文中每个网络的目标是一样的。而现有的协同学习旨在解决不同任务的协同。
3. 方法
3.1 Formulation
如图,看的很明白。
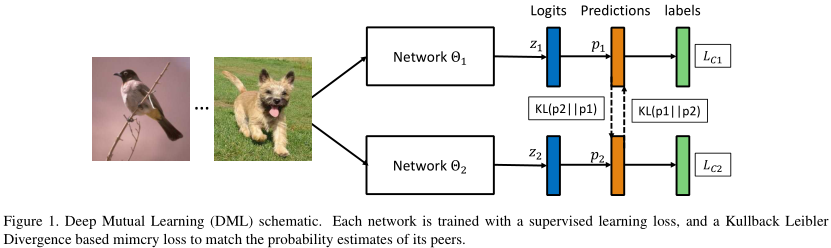
假设有\(M\)个分类\(N\)个样本\(\{ x_i \}_{i=1}^N\),对应标签为\(\{ y_i \}_{i=1}^N\)。
最后的监督学习损失\(L_C\)就是预测概率与真实标签之间的KL散度。网络的预测概率要通过softmax归一化。
此外,我们引入另一个随机初始化的网络,定义 网络1 参考 网络2 的模仿损失:
解释:如果二者概率相同,那么损失为零;否则,只要二者趋势不同(一个趋于0,一个趋于1),损失都是正值。
当然,我们也可以用对称KL损失,即\(\frac{1}{2}\left(D_{K L}\left(\boldsymbol{p}_{1} \| \boldsymbol{p}_{2}\right)+D_{K L}\left(\boldsymbol{p}_{2} \| \boldsymbol{p}_{1}\right)\right)\)。实验发现效果没区别。【博主怀疑公式7写错了】
最终的损失就是上述 模仿损失 和 监督学习损失 的直接求和。
3.2 实现
每一个网络可以在独立的GPU上计算。
当更多网络加入时,模仿损失要取均值。
还有一种优化方法:让其他所有学生网络的概率取均值(即统一作为一个教师),然后计算均值概率与该学生网络概率分布的KL散度。
实验发现这样做不好。可能的原因是:均值化操作降低了教师提供的先验熵【理解为随机性就行】。
3.3 弱监督学习
实现方法很简单:如果是有标签数据,那么就基于监督学习损失进行优化;如果是无标签数据,那么就基于模仿损失进行优化。
4. 实验
4.1 基本实验
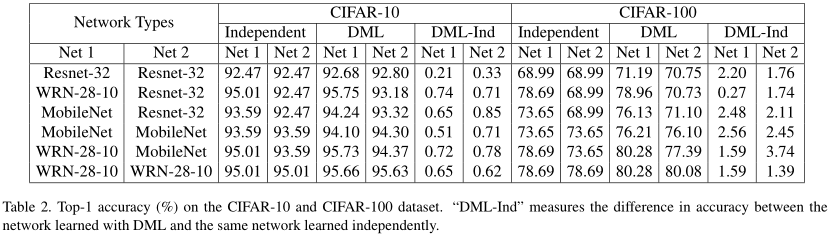
如表,作者尝试了很多网络结构。当交互学习时,准确率有所提升(DML-Ind是正值)。其中还包括各种网络的配对组合。作者还尝试了行人重识别任务,精度也得到了提升。
在训练过程中,DML也有助于更快、更好地收敛。
作者尝试了两种迭代策略:一种是序列化迭代,即第一个网络迭代完再迭代第二个;第二种是并行化策略,即同时迭代。作者发现第二种更好。并且第二种由于并行化,效率也更高。
作者还比较了蒸馏学习,效果要远比DML差。
作者还考察了学生网络数量对最终效果的影响。总体上呈现增长趋势,并且方差也更小。
4.2 深入实验
那么DML为什么有效呢?作者还实施了一些实验。
[4,10]指出:落入宽谷(wide valleys)的网络,通常比落入窄缝(narrow crevices)的网络泛化能力更好。为什么呢?因为当输入扰动时,处于宽谷的网络不会产生较大变化,但后者会。而DML就充当了一个协助者的角色,协助网络冲出窄缝。
作者无法证明这一点,但进行了一个实验:和[4,10]一样,作者在网络权重上加上了高斯噪声。结果,原网络的训练误差剧烈上升,而DML训练网络的训练误差只有较小提升。
此外,DML是一种均值化教师网络的操作。我们看看这种均值化是不是有好处。作者发现,DML的加入使得网络的预测没有这么肯定了。这是类似于熵正则化方法[4,17],能够帮助网络寻找更宽的局部极小值点。但与[4]相比,DML的效果更好。
实验发现,无论有没有DML,不同初始化网络学出来的特征都不尽相同。因此,差异性服务于随机性,也就服务于健壮性。进一步,如果我们强迫特征相似,那么最终结果不增反降。作者尝试加入了关于特征的L2损失,结果效果更差。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号