Paper | Fast image processing with fully-convolutional networks
Fast image processing with fully-convolutional networks
发表在2017年ICCV。
核心任务:加速图像处理算子(accelerate image processing operators)。
核心方法:将算子处理前、后的图像,训练一个全卷积CNN网络,从而代替传统算子。
核心贡献:作者选择了一种CNN结构,在10种算子上表现优异。
故事
-
历史上已经有很多图像处理算子,解决各种各样的图像处理问题。比如双边带滤波器等。但它们的普遍问题是慢,难以实时。
-
有些人尝试:将图像降采样,再进行处理,最后再升采样。这种办法一是会导致性能下降,因为高频细节在降采样时丢掉了;二是即便这样也很难实时。
-
本文的方法:将算子处理前、后的图像,用于训练一个全卷积CNN网络。然后我们就用CNN处理图像啦!再也不用降采样啦!
-
此外,在选择网络结构时,作者综合考虑了它们(1)近似图像处理算子的精度,(2)运行时间,(3)结构复杂性(如参数规模,使得能够存储在移动设备上),并最终选择了一个效果最好的网络结构。作者同时考虑了10种图像处理算子。
-
最后,作者还提出了一个很有意思的实验:由于CNN将这些算子参数化了,因此我们可以在测试阶段调整这些参数,从而实现交互式图像处理。
方法
直接看原文中比较重要的一段:
We have experimented with a large number of network architectures derived from prior work in high-level vision, specifically on semantic segmentation. We found that when some of these high-level networks are applied to low-level image processing problems, they generally outperform dedicated architectures previously designed for these image processing problems. The key advantage of architectures designed for high-level vision is their large receptive field. Many image processing operators are based on global optimization over the entire image, analysis of global image properties, or nonlocal information aggregation. To model such operators faithfully, the network must collect data from spatially distributed locations, aggregating information at multiple scales that are ultimately large enough to provide a global view of the image.
重点:作者尝试将一些 原本用于high-level任务(如图像分割)的网络 用于图像处理任务,发现性能很好。原因可能是:这些网络的感受野通常比较大,因此在全局特征提取上做得比较好。而传统图像算子也很强调这一点,比如NL方法。
作者最终选择了[78]中提出的网络结构【该文三作也是[78]的作者。[78]谷歌引用2k+】,最初用于语义分割。
首先,输入和输出尺寸相同,都是\(m \times n \times w\)。中间特征的获取流程都是:\(3 \times 3\)空洞卷积(dilated convolution) => 自适应正则化 => LReLU非线性激活。
其中:
-
空洞卷积的好处是:特征图的尺寸不会随着深度下降而变小,因此我们可以增大深度,从而增大感受野。最后一层不用空洞卷积,而是采用\(1 \times 1\)卷积,并且不使用非线性激活。
-
自适应正则化先对特征BN,然后再作线性变换。注意有两个分支:一个是恒等分支,还有一个是BN分支。

网络中不含任何短连接,因此最大内存消耗只有前后两个卷积结构。
训练采用的是MSE损失。作者声称:尽管MSE被认为在感知质量方面不够理想,但其PSNR和SSIM精度表现好。作者尝试了其他损失,如对抗损失,结果发现近似精度不高。
实验
首先看拟合精度:

然后看速度和参数规模:
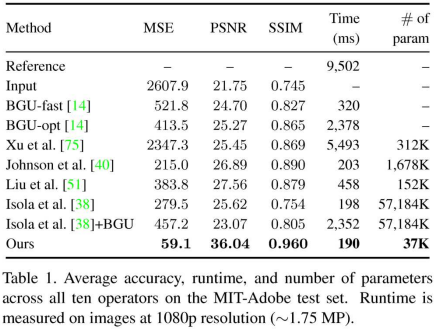
其他的不看了。我们看看如何交互。在本文中,作者是增加了一个可调整的输入通道,来实现交互。
最后最后,作者尝试用一个网络实现10个功能。做法:
-
增加了10个输入通道。每个通道都是一个二值通道,来指示任务选择。
-
训练时随机切换任务和训练对象。
效果一般。如论文中表2。
这篇文章怎么能引用近100次的???把一篇2k+引用文章里的网络拿来,也能发一篇ICCV,实在没明白。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号