Paper | U-Net: Convolutional Networks for Biomedical Image Segmentation
U-Net: Convolutional Networks for Biomedical Image Segmentation
发表在2015 MICCAI。原本是一篇医学图像分割的论文,但由于U-Net杰出的网络设计,得到了8k+的引用。
摘要:
There is large consent that successful training of deep networks requires many thousand annotated training samples. In this paper, we present a network and training strategy that relies on the strong use of data augmentation to use the available annotated samples more efficiently. The architecture consists of a contracting path to capture context and a symmetric expanding path that enables precise localization. We show that such a network can be trained end-to-end from very few images and outperforms the prior best method (a sliding-window convolutional network) on the ISBI challenge for segmentation of neuronal structures in electron microscopic stacks. Using the same network trained on transmitted light microscopy images (phase contrast and DIC) we won the ISBI cell tracking challenge 2015 in these categories by a large margin. Moreover, the network is fast. Segmentation of a 512x512 image takes less than a second on a recent GPU. The full implementation (based on Caffe) and the trained networks are available at http://lmb.informatik.uni-freiburg.de/people/ronneber/u-net.
结论:
The u-net architecture achieves very good performance on very different biomedical segmentation applications. Thanks to data augmentation with elastic deformations, it only needs very few annotated images and has a very reasonable training time of only 10 hours on a NVidia Titan GPU (6 GB). We provide the full Caffe[6]-based implementation and the trained networks. We are sure that the u-net architecture can be applied easily to many more tasks.
要点:
-
U-Net能对有限的数据,进行非常强有效的处理和利用。即所谓的strong use of data augmentation。
-
该网络处理速度也比较快:借助GPU处理一张\(512 \times 512\)的图像,耗时不到一秒。
故事背景
现有的CNN突破,大多集中在两点:1,数据量大,如ImageNet;2,网络参数多,如[7]的网络具有百万参数。
但是在大多数问题中,如医学图像处理,数据是稀缺品,标注数据更是稀缺品。
为了解决这一问题,[1]采用如下方式:将patch输入网络训练,而不是整图输入。测试也按patch测。
优点:
-
扩大了训练集:patch的数量显然比图像数量多得多。
-
对patch处理,可以更好地考虑局部细节。
缺点:
-
patch太小了,上下文(context)不足。
-
非常耗时,并且重叠patch导致了冗余。
U-Net
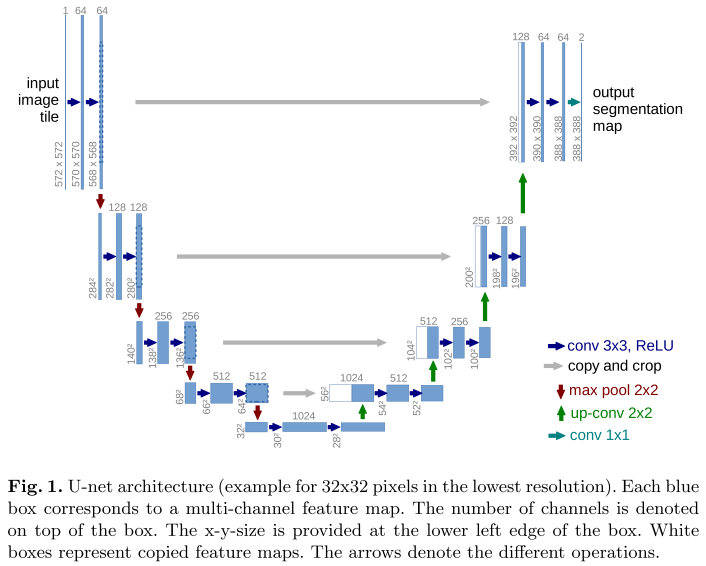
U-Net的使命是:利用很少的数据,实现很好的效果。
U-Net的基础是全卷积网络[9],其核心思想是:连续CNN处理会导致尺寸的收缩和分辨率下降;为此,我们将池化层改为升采样层。为了更好地处理局部特征(localize),在前端收缩通路(contracting path)的特征与后端升采样的输出(upsampled output)进行拼接。
在这篇工作里,作者的主要改进是:在升采样通路,U-Net也设置了大量的特征图。这样就使得上下文信息(context information)得以通过BP传递至高分辨率的收缩通路。因此整体上看,U-Net是一个U型的、较为对称的网络。
我们知道,现在的GPU能力有限,无法处理任意大的输入。此时,我们只能采取块处理:
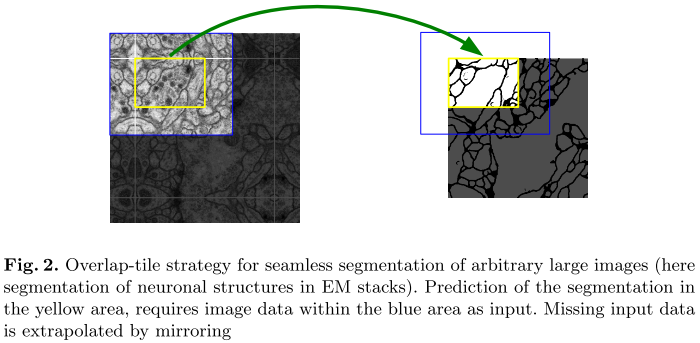
但这样处理有一个缺点:多多少少会丢失一些上下文信息。为此,作者引入了overlap-tile策略。如图,为了获得黄框的分割结果,U-Net的输入必须略大一些:蓝框,使得周围上下文信息得到一定的保持。如果边缘信息不存在,那么就简单地镜像扩展,如左图。
具体结构
左侧称为收缩通路(contracting path),右侧称为扩张通路(expansive path)。
-
我们看收缩通路。收缩通路由重复的两层\(3 \times 3\)卷积和ReLU激活组成,不补零(如蓝色箭头)。这导致图像在每一层尺寸(长或宽)都会减2(左右各减1)。一共重复5次,即10次卷积。
-
在每一次2层卷积后,都执行步长为2的\(2 \times 2\)的最大池化,效果为\(\frac{1}{2}\)降采样(如图红色箭头)。一共执行4次。
-
在每一次降采样后,第一层卷积的输出通道数翻倍。
-
我们再看扩张通路。首先经过\(2 \times 2\)的升卷积(up-conv),通道尺寸拓展为4倍;其次,从收缩通路中短连接过来的特征图经过裁剪,与之拼接;最后,执行2层\(3 \times 3\)的卷积和ReLU激活。同理也会越来越小。
-
最后一层,我们采用\(1 \times 1\)的卷积,即尺寸不变,但通道数减小为目标类别数。可以注意到,输入图像尺寸比输出尺寸要大。
网络一共有23层卷积(包括\(3 \times 3\)不补零卷积、\(2 \times 2\)升采样卷积和\(1 \times 1\)卷积)。
注意,输入图像(tile或者patch)的长和宽必须是偶数,这样才可以让\(2 \times 2\)升采样卷积真正实现2倍升采样。
损失
作者特别强调了不同分类之间的边界像素点。因此在设置损失函数时,作者对每一个像素点设置了不同的权重,见式2。如果该像素离最近的两个分类的距离之和小,说明该像素接近边界,则其权重会较大。
数据扩充
作者采取了弹性变形(elastic deformations)对有限的数据进行扩充。这能促使网络具有变形不变性。
具体而言,我们根据一个高斯分布(方差为10),随机生成一个位移向量,然后对像素点在\(3 \times 3\)的格点内进行位移。位移后执行双三次插值,即得到了最终的弹性形变结果。
此外,在收缩通路的最后,我们还采用了drop-out层。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号