《TensorFlow:实战Google深度学习框架》
《TensorFlow:实战Google深度学习框架》
- 《TensorFlow:实战Google深度学习框架》
3. TensorFlow入门
3.1 TensorFlow计算模型——计算图
计算图的概念
计算图是TF最基本的概念。
TF本身,就是一个用计算图表述计算的编程系统:
-
Tensor是张量,在这里可以简单理解为多维数组;
-
Flow是流动的意思,因为张量之间通过计算相互转化。
TF中所有计算,都会被转化为计算图上的节点。节点之间的边(连线),描述了计算之间的依赖关系。
比如运算\(a+b\):
-
a和b都是一个节点,在TF中,常数被转化成一种恒定输出固定值的运算;
-
add也是一个节点,代表加法运算;
-
a和add、b和add之间有边,代表依赖关系。
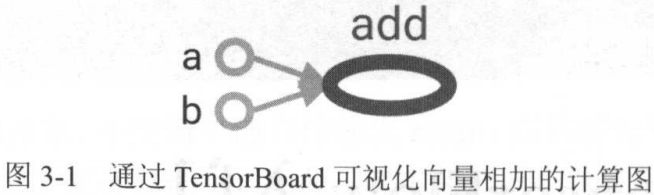
TF会自动将定义的计算转化为计算图上的节点。
计算图的使用
在TF中,系统会自动维护一个默认的计算图,可以通过tf.get_default_graph函数获取:
a= tf.constant([1,2],name="a")
print(a.graph is tf.get_default_graph())
True
还可以通过tf.Graph函数创建新计算图。
不同计算图上的张量和运算都不会共享。
# 在计算图g1中,定义变量v,设初值为0
g1=tf.Graph()
with g1.as_default():
v=tf.get_variable("v",shape=[1],initializer=tf.zeros_initializer)
# 在计算图g2,也定义变量v,但设初值为1
g2=tf.Graph()
with g2.as_default():
v=tf.get_variable("v",shape=[1],initializer=tf.ones_initializer)
# 读取g1计算图中的v
with tf.Session(graph=g1) as sess:
tf.global_variables_initializer().run()
with tf.variable_scope("",reuse=True):
print(sess.run(tf.get_variable("v")))
# 读取g2计算图中的v
with tf.Session(graph=g2) as sess:
tf.global_variables_initializer().run()
with tf.variable_scope("",reuse=True):
print(sess.run(tf.get_variable("v")))
[0.]
[1.]
不仅如此,还可以指定某运算图的GPU,借助tf.Graph.device函数:
g=tf.Graph()
with g.device('/gpu:0'):
result = 1 + 2
在一个计算图中,可以通过集合collection管理不同类别的资源。
这些资源可以是张量、变量或者队列资源等。
TF还自动维护了几种集合,详见P42上半部分。
3.2 TensorFlow数据类型——张量
张量的概念
在TF中,所有数据都通过Tensor表示。
从功能上,Tensor可以简单理解为多维数组。比如零阶张量就是标量scalar,一阶张量就是一个向量等。
实际上张量的实现并非采用保存数组的形式,而是保存计算过程。
a= tf.constant([1,2],name="a")
b= tf.constant([2,3],name="b")
result=tf.add(a,b,name="add")
print(result)
Tensor("add:0", shape=(2,), dtype=int32)
这说明了张量的三大属性:名字,维度和类型。
add:0:add节点输出的第一个结果(编号从0开始)。
张量的使用
我们知道,把一段长指令拆解成短指令,很多时候可以增强可读性。引用张量也有同样的效果。
并且,张量相当于一个中间结果,尤其在构建深层网络时,可以方便获取。
如果需要打印出具体值,需要开启会话,利用tf.Session().run(result)语句。这在后面介绍。
3.3 会话
我们利用Session执行定义好的运算。
Session拥有并管理TF程序运行时的所有资源。
计算完成后,需要结束会话,否则会造成资源泄露。
以下是一般格式:
-
创建会话;
-
用run运算出会话中感兴趣的值;
-
结束会话。
a=tf.constant(1,name="a")
b=tf.constant(2,name="b")
result=a+b
sess=tf.Session()
print(sess.run(result))
sess.close()
3
我们还可以用eval方法直接计算一个张量的值。
注意:
-
eval是张量的方法,run是会话的方法,而会话一般属于默认运算图(如果没有指定)。
-
TF会自动生成默认的运算图,但不会自动生成默认的会话。必须指定。
a=tf.constant(1,name="a")
b=tf.constant(2,name="b")
result=a+b
sess=tf.Session()
print(result.eval(session=sess)) # 必须有session=sess选项,No default session.
sess.close()
3
a=tf.constant(1,name="a")
b=tf.constant(2,name="b")
result=a+b
sess=tf.InteractiveSession() # 该函数自动将生成的会话注册为默认会话
print(result.eval())
sess.close()
3
注意以上3个例程:
-
指定会话,在该会话中run
-
指定会话,在该会话中eval目标张量
-
指定默认会话,直接eval目标张量
上述方式有一个共同问题:
如果程序异常而退出,则close将未执行,最终导致资源没有回收。
为此,我们可以通过PY的上下文管理器使用会话:
所有的运算都是with内部,只要管理器退出,资源就会被自动释放,异常退出同理。
a=tf.constant(1,name="a")
b=tf.constant(2,name="b")
result=a+b
with tf.Session() as sess:
print(sess.run(result))
3
a=tf.constant(1,name="a")
b=tf.constant(2,name="b")
result=a+b
sess=tf.Session()
with sess.as_default(): # 注意设置为默认会话
print(result.eval())
3
最后,ConfigProto Protocol Buffer可以增强配置。
该结构数据序列化工具,可以配置类似并行的线程数、GPU分配策略、运算超时时间等参数。
其中最常用的就是以下两个参数:
-
布尔型参数allow_soft_placement
默认为False。当其为True时,只要以下任意一个条件成立,GPU上的运算都会放到CPU上进行:
-
运算在GPU上无法执行;
-
没有指定GPU资源,比如只有一个GPU,但运算指定在第二个GPU上执行;
-
运算输入包含对CPU运算结果的引用。
-
该参数常设为True,这样可以增强代码的可移植性,可以在GPU异常或数目不确定的情况下正常运行程序。
-
布尔型参数log_device_placement
当其为True时,日志将会记录每个节点被安排在哪个设备上,方便调试。
config = tf.ConfigProto(allow_soft_placement=True,
log_device_placement=True)
sess1 = tf.InteractiveSession(config=config) # 创建默认会话
sess2 = tf.Session(config=config) # 创建一般会话
3.4 TensorFlow实现神经网络
前向传播算法
前向传播算法可以表示为矩阵乘法。例如P52给出的两层网络,两个矩阵乘法可以表示为:
w1=tf.constant([[0.2,0.1,0.4],[0.3,-0.5,0.2]]) # 2x3
w2=tf.constant([[0.6],[0.1],[-0.2]]) # 3x1
x=tf.constant([[0.7,0.9]]) # 注意还是两个中括号
a=tf.matmul(x,w1)
y=tf.matmul(a,w2)
sess=tf.InteractiveSession()
print(y.eval())
sess.close()
[[0.11600002]]
神经网络参数与TensorFlow变量
首先,我们学习神经网络参数随机初始化。
TF中的随机数生成函数见P54上表。
例如要产生一个2x3矩阵,其元素服从均值为0,标准差为2的正态分布:
weights=tf.Variable(tf.random_normal([2,3],stddev=2))
有时候我们希望创建全1矩阵等,比如用于bias。
此时可以用TF的常数生成函数,见P54下表。
其次,我们学习变量的初始化。
在TF中,一个变量的值在被使用前,需要明确调用其初始化过程,否则会报错。
我们可以理解为,之前我们只是定义了一个变量,而要生成运算图必须要初始化。
初始化过程示例见P56的计算图可视化结果,其中Assign操作就是初始化过程。
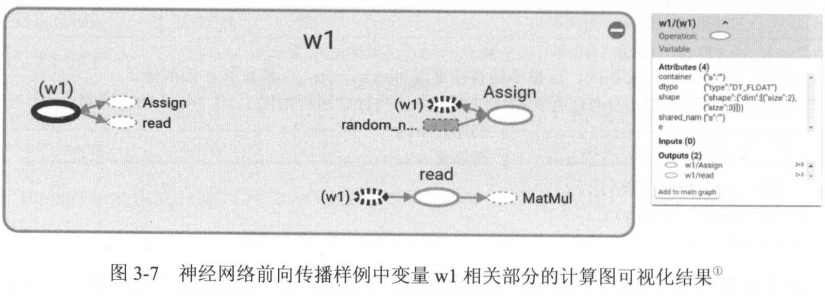
例如,我们希望定义w2,其值是weights的2倍:
w2=tf.Variable(weights.initialized_value()*2.0)
当变量较多时,逐个初始化比较麻烦。
为此,TF提供了初始化函数tf.global_variables_initializer,会自动处理变量之间的依赖关系:
weights=tf.Variable(tf.random_normal([2,3],stddev=2))
sess=tf.InteractiveSession()
init_op=tf.global_variables_initializer()
sess.run(init_op) # 注意是session的方法
print(weights.eval())
sess.close()
[[-4.211412 1.3347764 -1.2104415 ]
[ 0.18525712 -3.060251 -0.73507816]]
上面的写法非常常用!更加常用的写法是:
sess.run(tf.global_variables_initializer())
那么变量究竟是什么呢?
变量是一种特殊的张量,其声明函数tf.Variable是一个运算,运算的输出就是tensor。
因此,变量也具有两大关键属性:shape和type。
一个变量在构建以后,其类型是不可更改的!
比如以下操作就是非法的:
w1=tf.Variable(tf.random_normal([2,3],stddev=1),name="w1") # random_normal的默认类型是float32
w2=tf.Variable(tf.random_normal([2,3],dtype=tf.float64,stddev=1),name="w2")
w1.assign(w2)
会提示:TypeError: Input 'value' of 'Assign' Op has type float64 that does not match type float32 of argument 'ref'.
和type不同,shape是可变的,但需要设置参数validate_shape=False。
x = tf.Variable(0)
y = tf.assign(x, [5,2], validate_shape=False) # 只是定义,并未运行
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
print (sess.run(x))
print (sess.run(y))
print (sess.run(x))
0
[5 2]
[5 2]
用TF训练神经网络
在神经网络优化算法中,最常用的是backpropagation,后叙。
基本流程图见P59。
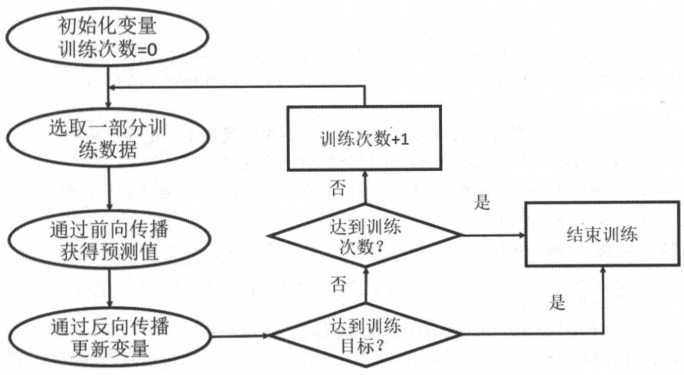
过程:
-
选取batch训练;
-
通过前向传播,得到y;
-
通过反向传播,得到更新的参数;(根据y和label)
-
满足要求或达到迭代次数,则停止迭代;否则继续迭代。
之前我们通过定义常量:tf.constant,来表示一个batch的数据。
问题是,如果我们迭代几百万次,需要定义的常量会特别多,计算图非常大,而利用率很低。
为此,TF引入了placeholder机制,用于输入数据。
placeholder相当于定义一个输入位置,该位置在运行时才输入数据,避免了一次性生成大量常数。
同理,placeholder的type也是不可变的,但shape是可变的,并且可以自动推算出,不需要给定。
w1=tf.Variable(tf.random_normal([2,3],stddev=1,seed=1))
w2=tf.Variable(tf.random_normal([3,1],stddev=1,seed=2))
x=tf.placeholder(tf.float32,shape=(3,2),name="input") # 维度可以不给,但给定可以减小出错概率 3个2维样本
a=tf.matmul(x,w1)
y=tf.matmul(a,w2)
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
print (sess.run(y,feed_dict={x:[[0.7,0.9],[0.1,0.4],[0.5,0.8]]})) # feed value for placeholder 注意是一个dict
[[2.2322333 ]
[0.90483624]
[1.9336841 ]]
神经网络例程见P80-81。
4. 深层神经网络
这一部分的理论知识参见《深度学习》。
4.1 深度学习与深度神经网络
维基百科对深度学习的定义:
Deep learning is a class of machine learning algorithms that use a cascade of multiple layers of nonlinear processing units for feature extraction and transformation.
为什么需要强调非线性呢?如何实现非线性呢?
线性模型的局限性
线性模型:
注意,线性模型中不含多次项和交叉项。
前面学习的、简单的、通过矩阵乘法实现的前向传播算法,完完全全就是一个线性模型。
并且,尽管层数多,但乘起来和单层并没有实质区别,因此表达能力不随层数增加而增强。
如果我们希望模拟一个圆形闭环边界,那么线性模型是无法做到的。因为加权一次项只能学习出直线边界。
但如果使用非线性Activation或非线性特征,那么model就可以逼近一条非直线边界。
Activation去线性化
目前TF支持7种非线性activation。
其中常用的有tf.nn.relu,tf.sigmoid,tf.tanh。
TF还支持自定义激活函数。
比如用relu实现前向传播:
a=tf.nn.relu(tf.matmul(x,w1)+biases1)
y=tf.nn.relu(tf.matmul(a,w2)+biases2)
需要注意两点:
-
使用偏置项。因为前面一层是线性层(仿射变换),不一定经过原点。
-
两个矩阵之间用*相乘,是哈达玛乘积,即元素对应相乘;用tf.matmul才是矩阵相乘。
多层网络解决异或运算
在1958年,Rosenblatt提出了感知机perceptron。
其结构很简单,是一个单层神经网络,没有隐藏层。
activation没有要求。
通过实验我们可以发现,单层网络是无法解决异或问题的,哪怕使用的是non linear activation。
参见:深度学习笔记
通过引入多层网络(主要指隐藏层),允许新特征被构造出来,那么XOR问题就可以用一条直线边界解决了。
4.2 Loss Function
Cross entropy
怎么判断输出向量和期望向量的距离呢?交叉熵是最常用的评价方法。
交叉熵刻画两个概率分布之间的距离。
为什么使用交叉熵而不是最简单的平方差函数作为loss function?
参见:
原因归纳起来有:
-
当使用sigmoid激活函数时,MSE作为代价函数,会导致梯度消失问题(sigmoid函数饱和),尤其在误差较大时下降很慢。
当然,负对数似然可以抵消其中的指数,消除梯度下降问题。这一点,softmax函数作输出单元时也会遇到。
-
最小化KL散度(相对熵的完整版),本质上就是最大化似然。
而最大似然的优点是:当样本数量趋于无穷时,就收敛速率而言,最大似然估计是最好的渐进估计。
-
交叉熵在softmax逻辑回归中是凸函数(在神经网络中不是)。
交叉熵TF语句如下:
cross_entropy=-tf.reduce_mean(y_*tf.log(tf.clip_by_value(y,1e-10,1.0)))
交叉熵实际上是从相对熵(KL散度)简化而来的。
参见:深度学习笔记
当我们使用交叉熵时,实际上默认了P代表真实分布。
因此,其中y是预测值。
要注意,交叉熵不是对称的!使用时要注意y_和y(a)的具体含义,不要混淆!
进一步看,外部的y_是正确label,非0即1,因此整个结果只取决于label=1的预测值,如果预测也为1,那么log1=0,距离为0。
注意交叉熵带负号,使最终结果为正。
tf.clip_by_value类似于MATLAB中的imshow函数,把超出范围的数暴力截断。比如2会变成1,0会变成1e-10。
它保证tf.log不会出现对0求log的错误,也避免了大于1的非概率数。
我们用的乘法是*,是哈达玛乘积,即元素对应相乘。矩阵相乘要用tf.matmul函数。
现在,我们得到的是一个nxm的矩阵,n是一个batch中的样例数目,m是类别数。
显然,最终的loss,也就是交叉熵,应该先把一个样例中的所有类别加起来,再对n个样例作加权平均。
为了方便,我们可以直接对整个矩阵求平均,结果和数学定义相差常数m倍,不影响其数学意义。
tf.reduce_mean函数为我们实现了这个功能。
Softmax
cross entropy中a和y都必须是概率。
为了保证神经网络的输出a是一个概率,我们还需要用Softmax回归。
softmax输出单元的其他好处参见:深度学习笔记
假设神经网络输出有\(y_1,y_2,...,y_n\),则经过处理后的输出为:
即所有\(y_i'\)都在0和1之间,且和为1。此时再用交叉熵计算loss。
在TF中,softmax变成了一个额外的处理层,见P76。
交叉熵往往和softmax搭配使用:最小化KL散度等价于最大化似然,而负对数似然可以抵消softmax中的指数,解决梯度消失的问题。
为此,TF封装了这两个功能于一个函数:tf.nn.softmax_cross_entropy_with_logits:
cross_entropy = tf.nn.softmax_cross_entropy_with_logits(labels = y_, logits = y) # y是预测值
如果分类只有一个正确结果,TF还提供了tf.nn.sparse_softmax_cross_entropy_with_logits加速计算,完整见下一章。
MSE
与分类问题不同,regression问题往往只有一个数值输出,比如预测房价。
如果模型的假设是高斯函数,那么MSE实际上也服从最大似然准则。
尽管可能使得激活函数梯度消失,但由于实现简单,用得也不少。
mse = tf.reduce_mean(tf.square(y_-y))
自定义损失函数以满足特殊偏好
有时候,自定义损失函数可以具有优化效果,接近实际问题需求。
举个例子。我们要给商家预测某产品的销量y',商家根据y'生产。
该产品的成本为1元,利润10元。
如果预测值y'比实际值y大,那么商家就会滞销一部分产品;如果小,那么产品会供不应求,商家错失商机。
显然,在这个问题中,我们更希望预测值偏大,而不是偏小。因为可能错失的利润要远比可能多付出的成本多。
因此,用MSE衡量loss就不太理想了。我们希望赋予权重:
其中:
即:我们严惩预测值y'小于实际需求y的情况出现,因此权重为10。
TF可以这么实现:
loss = tf.reduce_sum(tf.where(tf.greater(v1,v2),(v1-v2)*10,(v1-v2)*1))
tf.greater的输入是两个张量,输出结果仍是张量,返回每一个元素的大小比较结果(是否严格大)。
如果维数不同,会作广播处理:
v1=tf.constant([[1.0,2.0],[3,4]],name="v1")
v2=tf.constant([[2.0,2.5]],name="v2")
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
print(tf.greater(v1,v2).eval())
[[False False]
[ True True]]
tf.where有三个参数。首先是选择判据,如果是True,那么就输出第二个参数,否则输出第三个参数。
现在我们尝试写一个神经网络,看看新的loss function对model产生了什么效果。
假设有两个参数:x1和x2。x1+x2<1的样例都被认为是正样本(比如零件合格),其他都是负样本。
import tensorflow as tf
from numpy.random import RandomState
batch_size=8 # 一次用8个样本训练model参数
##### 定义placeholder,方便输入batch,节省内存
x=tf.placeholder(tf.float32,shape=(None,2),name='x-input') # 两个输入节点:x1和x2
y_real=tf.placeholder(tf.float32,shape=(None,1),name='y-input') # 回归问题,一般只有一个输出节点
##### 随机初始化矩阵参数
w1=tf.Variable(tf.random_normal([2,1],stddev=1,seed=1)) # 只用一个2x1矩阵代表的单层神经网络,随机化
##### 定义运算过程,loss function和train方式
y=tf.matmul(x,w1) # 定义得到y的运算
loss = tf.reduce_sum(tf.where(tf.greater(y,y_real),(y-y_real)*1,(y_real-y)*10)) # 预测值更大惩罚更多
train_step=tf.train.AdamOptimizer(0.001).minimize(loss) # 用Adam优化器,目标是最小化loss,学习率0.001
##### 随机创建容量为128的样本集
rdm=RandomState(1) # 使用同一个种子,创建伪随机数发生器
dataset_size=128
X=rdm.rand(dataset_size,2) # 随机构造128x2的矩阵,每一个元素都在0、1之间均匀分布
# label一定要加噪声,象征着实际需求。
# 实际需求当然不会和理论值一样。否则训练出来的一定是标准的y=x1+x2。
# 当model逼近某一侧时,loss会被严惩,所以会偏向另一侧。
Y=[[x1+x2+rdm.rand()/10.0-0.05] for (x1,x2) in X] # Y存在噪声,噪声为-0.05到0.05
##### 开始训练
with tf.Session() as sess:
sess.run(tf.global_variables_initializer()) # 套路了,把所有变量都初始化 里面的()一定不要丢!!否则报错!!
STEPS=5000
for i in range(STEPS):
start=(i*batch_size)%dataset_size # 取余操作 不会超出dataset_size的范围
end=min(start+batch_size,dataset_size) # 要么+8,要么是128 最后不会包含128的
sess.run(train_step,
feed_dict={x:X[start:end],y_real:Y[start:end]})
print(sess.run(w1)) # 最后看看我们训练得到的直线方程
[[1.0193471]
[1.0428091]]
结果符合预期,model倾向于让\(y=w_1x_1+w_2x_2\)更大一些。
因为在拟合的前提下,由于噪声的存在(实际情况),预测值y稍大于实际值y_real,受到惩罚更小。
其中的train_step定义了反向传播的优化方法。
常用的优化方法有:tf.train.GradientDescentOptimzer,tf.train.AdamOptimizer和tf.train.MomentumOptimizer。
在训练过程中,sess.run(train_step)使得所有在GraphKeys.TRAINABLE_VARIABLES集合中的变量都进行优化,目标是让loss更小。
4.3 神经网络优化算法
Stochastic gradient descent
梯度下降法最大的问题有二:
- 耗时较长
- 可能无法到达全局最优
为了解决第一个问题,我们引入随机梯度下降法:每次选取一个batch用于训练。
上例已经采用了该方法。
指数衰减学习率
为了使学习率逐渐减小,TF提供了学习率的指数衰减法:tf.train.exponential_decay。其代码为:
decayed_learning_rate = learning_rate * decay_rate ^ (global_step / decay_steps)
该函数格式参见TF笔记。
完整的使用方法示例:
global_step = tf.Variable(0) # 初始为0
learning_rate = tf.train.exponential_decay(0.1,global_step,100,0.96,staircase=True)
learning_step = tf.train.GradientDescentOptimizer(learning_rate).minimize(loss,global_step=global_step)
需要注意:
- 由于decay_steps=100,因此实际上是每隔100次迭代,学习率才会乘以0.96,呈现阶梯状。
- global_step需要在训练过程中传出,因此放在minimize参数内。
- 初始学习率、衰减系数和衰减速度等都是根据经验设置的。
Regularization
正则化的思想是:在损失函数中,加入刻画模型复杂程度的指标。
常用的指标有二:
-
\(L^1\)正则化
\[R(w) = \Vert w \Vert_1 = \sum_i \vert w_i \vert \] -
平方\(L^2\)正则化
\[R(w) = \Vert w \Vert_2^2 = \sum_i \vert w_i^2 \vert \]
二者差别在于:
-
前者对参数的惩罚更强。例如参数等于0.001时,由于平方后更小,使得平方项几乎为0,惩罚小。
-
前者计算公式是不可导的,而后者可导。
因此平方\(L^2\)正则化显得更简单一些。
TF提供了两个函数:tf.contrib.layers.l1_regularizer和tf.contrib.layers.l2_regularizer,分别代表两种正则化方法。
其格式见TF笔记。
示例:
weights = tf.constant([[1.0,-2.0],[-3.0,4.0]])
with tf.Session() as sess:
print(sess.run(tf.contrib.layers.l1_regularizer(.5)(weights)))
print(sess.run(tf.contrib.layers.l2_regularizer(.5)(weights)))
5.0
7.5
其中,平方\(L^2\)范数的结果会除以2。
如果神经网络的参数较多,以上计算方法就会显得非常笨拙、臃肿,可读性很差。
强烈建议使用集合进行运算。下面是例子。
import tensorflow as tf
def get_weight(shape, lambda):
var = tf.Variable(tf.random_normal(shape),dtype=tf.float32) # 随机生成一个权重
tf.add_to_collection('losses',tf.contrib.layers.l2_regularizer(lambda)(var)) # 把正则项放入collection: losses
return var
# 即每次生成权重,都先把权重变量放入集合中,再传给神经网络。
x = tf.placeholder(tf.float32,shape = (None,2))
y_label = tf.placeholder(tf.float32,shape = (None,1))
batch_size = 8
layer_dimension = [2,10,10,10,1] # 每一层节点数
n_layers = len(layer_dimension) # 层数
cur_layer = x # 保存当前节点内容 最开始就是输入的数据
in_dimension = layer_dimension[0]
out_dimension = layer_dimension[1]
for i in range(1, n_layers):
weight = get_weight([in_dimension,out_dimension],0.001) # 生成当前层的权重,并加入collection: losses
bias = tf.Variable(tf.constant(0.1,shape=[out_dimension]))
cur_layer = tf.nn.relu(tf.matmul(cur_layer,weight)+bias)
in_dimension = out_dimension
out_dimension = layer_dimension[i+1]
y_pre = cur_layer
mse_loss = tf.reduce_mean(tf.square(y_label - y_pre)) # MSE
tf.add_to_collection('losses',mse_loss)
loss = tf.add_n(tf.get_collection('losses')) # 这才是最终的loss函数,除了原本的loss,还加上了每一个权重的正则化项。
从上例可以看出集合的好处:集合把一系列变量(权重)归纳在一起。
无论其值怎么变化,最后要求和时,可以统一从集合中调用出来,方便批量管理。
滑动平均模型
When training a model, it is often beneficial to maintain moving averages of the trained parameters.
Evaluations that use averaged parameters sometimes produce significantly better results than the final trained values.
为了控制模型更新的速度,TF提供了tf.train.ExponentialMovingAverage函数,来实现滑动平均模型。
简单来说,我们只需要提供一个衰减率decay,来控制模型更新的速度。
滑动平均模型会为原变量提供一个影子变量shadow_variable。
影子变量和初值和原变量相同,其更新公式为:
为了保证模型稳定,decay会设得非常接近于1,如0.999。
问题是,由于decay过大,会导致影子变量在一开始可能更新得太慢。
为此,我们还可以提供num_updates参数,实际衰减率将取最小值:
这里的num_updates可以取迭代步数step。随着step增加,该值会逐渐趋近于1,decay将逐渐占据主导位置。
import tensorflow as tf
v1 = tf.Variable(0,dtype=tf.float32) # 设初值为0
step = tf.Variable(0,trainable=False)
ema = tf.train.ExponentialMovingAverage(0.99,step) # 定义一个滑动平均的类。衰减率为0.99,num_updates参数为step。
maintain_averages_op = ema.apply([v1]) # 定义了一个列表[v1],每次执行该操作时,都会用ema更新列表中的变量v1
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
print(sess.run([v1,ema.average(v1)])) # 验证:初值都为0
sess.run(tf.assign(v1,5))
sess.run(maintain_averages_op)
print(sess.run([v1,ema.average(v1)]))
# 验证:decay = min{0.99,(1+0)/(10+0)} = 0.1, 影子变量为0.1×0+0.9×5 = 4.5 < 5
sess.run(tf.assign(step,10000)) # 当step较大时,decay占主导;0.99的decay导致模型非常稳定。
sess.run(tf.assign(v1,100)) # 原本要直接从5跳到100
sess.run(maintain_averages_op)
print(sess.run([v1,ema.average(v1)]))
sess.run(maintain_averages_op)
print(sess.run([v1,ema.average(v1)]))
[0.0, 0.0]
[5.0, 4.5]
[100.0, 5.454999]
[100.0, 6.400448]
5. MNIST数字识别问题
5.1 MNIST数据处理
MNIST数据集是NIST数据集的子集,包含60000张图片用于训练,10000张图片用于测试。 验证集从训练集中分出。
下载地址见P95。TF会自动下载。
每一张图片都是0到9的手写数字,大小为28×28。
TF提供了封装好的MNIST数据集处理类,可以直接使用。
这个类会自动下载并转化MNIST数据的格式,将数据从原始的数据包中,解析成训练和测试神经网络时使用的格式。
TF会自动将60000张训练图片,分为55000张训练图片和5000张验证图片。
处理后,每一张图片都是长为784的一维数组,方便提供给输入层。
为了加快训练,我们可以利用mnist.train.next_batch函数,来得到训练用的一个batch。
5.2 边训练,边改进
先跑起来
我们采用上一章学过的知识,构建一个完整的TF程序:
import tensorflow as tf
from tensorflow.examples.tutorials.mnist import input_data
# 一个好习惯:常量大写,变量小写
INPUT_NODE = 784
OUTPUT_NODE = 10 # 10个分类
LAYER1_NODE = 500 # 只设一层隐藏层,500个节点
BATCH_SIZE = 100
LEARNING_RATE_BASE = 0.8
LEARNING_RATE_DECAY = 0.99 # 学习率的衰减
REGULARIZATION_RATE = 0.0001
TRAINING_STEPS = 15000
MOVING_AVERAGE_DECAY = 0.99 # 变量的滑动平均衰减,一般设为接近1
def forward_propagation(input_tensor, avg_class, weights1, biases1, weights2, biases2):
if avg_class == None: # 如果没有滑动平均类
layer1 = tf.nn.relu(tf.matmul(input_tensor, weights1) + biases1)
return tf.matmul(layer1, weights2) + biases2 # 暂时没有采用softmax输出单元,因为softmax和cross-entropy有搭配函数
else: # 有滑动平均类
# 把权重和偏置都用滑动平均类处理再输出
layer1 = tf.nn.relu(tf.matmul(input_tensor, avg_class.average(weights1)) + avg_class.average(biases1))
return tf.matmul(layer1, avg_class.average(weights2)) + avg_class.average(biases2)
def train(mnist): # 实际训练函数,由main函数下载好数据后,直接调用
x = tf.placeholder(tf.float32, [None,INPUT_NODE], name = 'x')
y_label = tf.placeholder(tf.float32, [None,OUTPUT_NODE], name = 'y_label')
# 权重和偏置都用正态分布生成,超过两倍标准差的将被舍弃
weights1 = tf.Variable(tf.truncated_normal([INPUT_NODE, LAYER1_NODE],stddev = 0.1))
biases1 = tf.Variable(tf.constant(0.1,shape = [LAYER1_NODE]))
weights2 = tf.Variable(tf.truncated_normal([LAYER1_NODE,OUTPUT_NODE],stddev = 0.1))
biases2 = tf.Variable(tf.constant(0.1,shape = [OUTPUT_NODE]))
# 不使用滑动平均的预测值y_pred
y_pred = forward_propagation(x,None,weights1,biases1,weights2,biases2)
# 使用滑动平均的预测值average_y_pred
global_step = tf.Variable(0,trainable=False) # 迭代次数一般都设为不可训练的参数
variable_averages = tf.train.ExponentialMovingAverage(MOVING_AVERAGE_DECAY,global_step)
variables_averages_op = variable_averages.apply(tf.trainable_variables()) # 对所有可训练参数都使用滑动平均的操作
average_y_pred = forward_propagation(x,variable_averages,weights1,biases1,weights2,biases2)
# softmax输出单元+交叉熵形式的损失函数 argmax返回的是最大值的索引
cross_entropy = tf.nn.sparse_softmax_cross_entropy_with_logits(logits=y_pred,labels=tf.argmax(y_label,1))
cross_entropy_mean = tf.reduce_mean(cross_entropy)
# L2正则化
regularizer = tf.contrib.layers.l2_regularizer(REGULARIZATION_RATE)
regularization = regularizer(weights1) + regularizer(weights2)
# loss function
loss = cross_entropy_mean + regularization
# 学习率
total_steps = mnist.train.num_examples / BATCH_SIZE
learning_rate = tf.train.exponential_decay(LEARNING_RATE_BASE,global_step,total_steps,LEARNING_RATE_DECAY)
# 不带平滑的学习算法
train_op = tf.train.GradientDescentOptimizer(learning_rate).minimize(loss,global_step = global_step)
# 带平滑的学习算法
# 此时的参数更迭(反向传播)比较复杂,需要同时进行滑动平均
# TF提供了以下两种机制:
with tf.control_dependencies([train_op, variables_averages_op]):
train_op_average = tf.no_op(name='train')
# 或:train_op = tf.group(train_step, variables_averages_op)
# 计算带平滑的预测的准确率
correct_vector = tf.equal(tf.argmax(average_y_pred,1),tf.argmax(y_label,1))
accuracy = tf.reduce_mean(tf.cast(correct_vector,tf.float32)) # 先转换类型,再求平均
# 正式启动:带平滑的预测学习
with tf.Session() as sess:
tf.global_variables_initializer().run()
validate_feed = {x:mnist.validation.images, y_label:mnist.validation.labels}
for i in range(TRAINING_STEPS):
if i % 1000 == 0: # 每一千次迭代,输出一次验证集的准确率
validate_acc = sess.run(accuracy,feed_dict = validate_feed) # 这里由于验证集不大,就一次性输入了。小心内存溢出。
print("Step:%d; validation accuracy: %g" % (i,validate_acc))
# 个人认为:该程序不涉及超参数的选择,因此验证集未起到指导作用。
xs,ys = mnist.train.next_batch(batch_size) # 从training set中随机挑选一个batch
sess.run(train_op_average, feed_dict = {x:xs, y_label:ys}) # 跑的是带平滑的训练模型
# 迭代完毕,计算test set结果
test_feed = {x:mnist.test.images, y_label:mnist.test.labels}
test_acc = sess.run(accuracy, feed_dict=test_feed)
print("Step:%d; test accuracy: %g" % (TRAINING_STEPS,test_acc))
def main(argv=None):
mnist = input_data.read_data_sets("/tmp/data",one_hot=True) # 声明用来处理mnist的类 会自动下载数据
train(mnist)
# 主程序入口。如果在主程序中(如交互界面提示符)调用,则执行main函数;若是其余程序调用,则不执行。
if __name__ == '__main__':
tf.app.run()
Extracting /tmp/data/train-images-idx3-ubyte.gz
Extracting /tmp/data/train-labels-idx1-ubyte.gz
Extracting /tmp/data/t10k-images-idx3-ubyte.gz
Extracting /tmp/data/t10k-labels-idx1-ubyte.gz
Step:0; validation accuracy: 0.0632
Step:1000; validation accuracy: 0.9776
Step:2000; validation accuracy: 0.9804
Step:3000; validation accuracy: 0.982
Step:4000; validation accuracy: 0.9828
Step:5000; validation accuracy: 0.9828
Step:6000; validation accuracy: 0.9826
Step:7000; validation accuracy: 0.9816
Step:8000; validation accuracy: 0.9826
Step:9000; validation accuracy: 0.9822
Step:10000; validation accuracy: 0.9816
Step:11000; validation accuracy: 0.982
Step:12000; validation accuracy: 0.9822
Step:13000; validation accuracy: 0.9818
Step:14000; validation accuracy: 0.9824
Step:15000; test accuracy: 0.983
An exception has occurred, use %tb to see the full traceback.
SystemExit
/usr/local/lib/python3.5/dist-packages/IPython/core/interactiveshell.py:2969: UserWarning: To exit: use 'exit', 'quit', or Ctrl-D.
warn("To exit: use 'exit', 'quit', or Ctrl-D.", stacklevel=1)
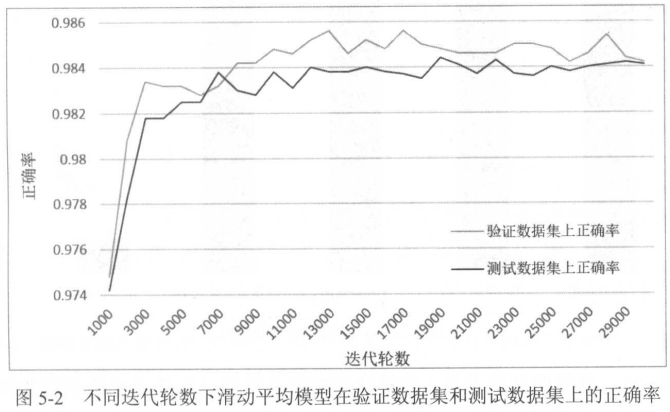
利用验证集
从以上数据可以看出,迭代大概4000次,模型在验证集上的表现就已经开始波动了。
这意味着,只要模型超参数不改,其表现不会发生太大的变化。
最后的测试数据也证明了这一点。
除了简单地使用验证集,我们还可以使用交叉验证的方法。
这种方法一般用于小数据集,考虑到分出验证集后,训练集可能会过小。
面对海量的数据,我们不需要交叉验证。
验证数据的分布与测试数据的分布越接近越好。
此时验证集表现会和测试集表现才能接近,如P103图。
比较试试
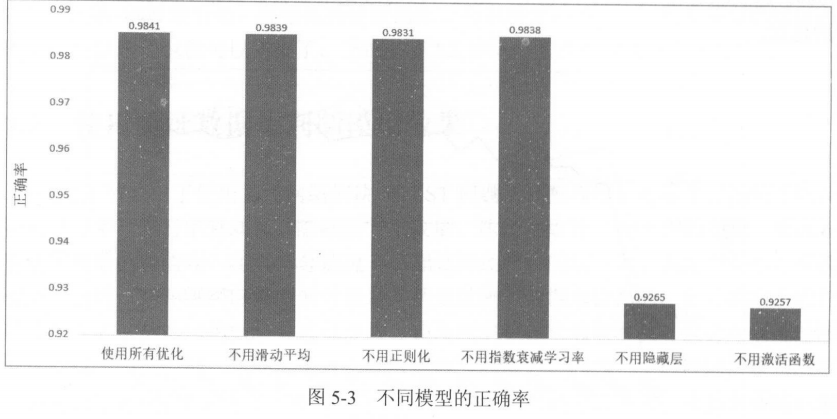
根据P104图,我们发现:如果不采用激活函数,或不采用隐藏层,模型在MNIST数据集上的表现将下降至92%。
而如果只是取消正则化、滑动平均或指书衰减学习率等优化方法,准确率大致相同。
结论:网络结构对模型表现起决定性作用,而不是优化方法。
下一章我们使用卷积网络,可以把准确率提高至99.5%。
实际上,在MNIST问题上,模型的收敛速度是很快的(4000轮左右),因此这些优化方法都无关痛痒。
但是,如果在复杂问题上,平滑处理和学习率衰减,可以将正确率提高不少。
正则化是一个很有趣的问题。
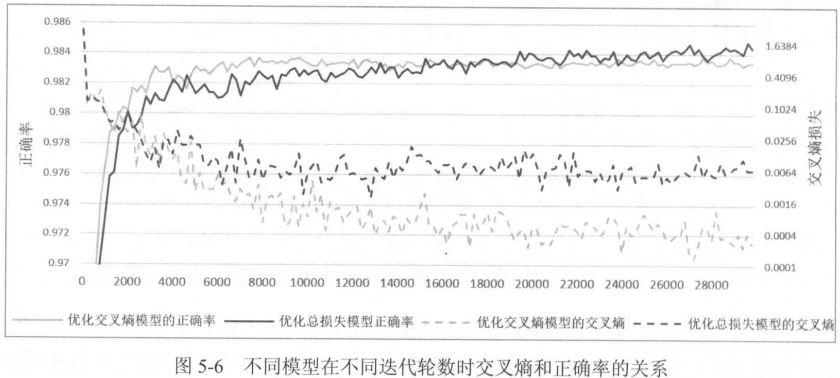
不妨看P106图。尽管未正则化的交叉熵会更小,但测试正确率反而较低。原因就是过拟合。
5.3 变量管理
在前面的例程中,我们把两个权重和两个偏置,全都作为参数输入到forward_propagation函数中计算预测值。
显然,一旦参数多了,这样做就复杂了。
为此,TF提供了一种机制,不需要传参即可使用变量。
这种机制主要通过tf.get_variable和tf.variable_scope实现。
简化变量传递,最简单的方法就是:让变量处于某个变量空间,其变量名加上前缀,变得独一无二,可以直接调用。
我们一步步说。
回忆原来的tf.Variable函数,其命名参数name是可选的。
而如果用tf.get_variable函数定义变量,其命名是必选的:
v = tf.Variable(tf.constant(1.0,shape=[1]),name='v')
v = tf.get_variable("v",shape=[1],initializer=tf.constant_initializer(1.0))
如果缺少名称,或者同名,创建都会报错:
ValueError: Variable v already exists, disallowed. Did you mean to set reuse=True in VarScope?
如果我们为变量创建不同的变量空间,那么彼此之间将互不冲突。
比如我们在"foo"变量空间再创建一个名为v的变量:
with tf.variable_scope("foo"): # foo是一个命名空间
v = tf.get_variable("v",shape=[1],initializer=tf.constant_initializer(1.0))
同理,如果在foo空间再次创建v变量,也会报错。
创建以后,我们需要用tf.variable_scope函数,来直接获取变量。
需要注意的是,命名空间必须设置reuse=True,代表此时tf.get_variable只能获取已存在的变量,而不能创建变量:
with tf.variable_scope("foo",reuse=True): # foo是一个命名空间
v1 = tf.get_variable("v",[1])
print(v1==v)
True
换句话说,tf.get_variable函数在某个命名空间内的功能,由reuse参数决定。
命名空间是可以嵌套的,其reuse参数也是默认传递的。
除非内部空间特别说明,否则子空间的reuse参数和外部一致。
with tf.variable_scope("root"):
print(tf.get_variable_scope().reuse)
with tf.variable_scope("son",reuse=True):
print(tf.get_variable_scope().reuse)
with tf.variable_scope("grandson"):
print(tf.get_variable_scope().reuse)
False
True
True
变量空间的魅力,在于其可以让变量名称变得独一无二。我们做一下实验:
w1=tf.get_variable("w",[1])
print(w1.name)
with tf.variable_scope("space1"):
w2 = tf.get_variable("w",[1])
print(w2.name)
with tf.variable_scope("space2"):
w3 = tf.get_variable("w",[1])
print(w3.name)
w:0
space1/w:0
space1/space2/w:0
进一步,我们可以在任意一个命名空间内,通过完整的名字调用其他命名空间的变量:
with tf.variable_scope("",reuse=True): # 名字为空,这样才不会加前缀,才能比较
w4 = tf.get_variable("space1/space2/w",[1])
print(w4 == w3)
True
现在,我们就可以改进前向传播函数了:
def forwardpropagation(input_tensor, reuse=False):
with tf.variable_scope('layer1',reuse=reuse): # 以后调用时,也把reuse参数传进来,决定是调用还是创建
weights = tf.get_variable("weights",[INPUT_NODE, LAYER1_NODE], initializer=tf.truncated_normal_initializer(stddev=0.1))
biases = tf.get_variable("biases", [LAYER1_NODE],initializer=tf.constant_initializer(0.0))
layer1 = tf.nn.relu(tf.matmul(input_tensor, weights) + biases)
with tf.variable_scope('layer2',reuse=reuse):
weights = tf.get_variable("weights",[LAYER1_NODE, OUTPUT_NODE], initializer=tf.truncated_normal_initializer(stddev=0.1))
biases = tf.get_variable("biases", [OUTPUT_NODE],initializer=tf.constant_initializer(0.0))
layer2 = tf.matmul(layer1, weights) + biases
# 以上,weights和biases都是用get_variable创建的独特变量,layer1和layer2则是普通变量。
return layer2
x = tf.placeholder(tf.float32,[None, INPUT_NODE], name='x-input')
y = forwardpropagation(x)
# 如果我们已经得到了layer1和layer2的权重和偏置,模型只用于预测,那么我们就可以执行:
new_x = ...
pre_y = forwardpropagation(x, True)
5.4 TensorFlow模型持久化
之前我们训练好的模型,只要程序退出以后,就被丢弃了。我们希望能把模型保存下来。
持久化代码实现
TF提供了一个非常简单的API,来保存和还原一个神经网络模型。
这个API是tf.train.Saver类。
import tensorflow as tf
v1 = tf.Variable(tf.constant(1.0,shape=[1]),name="v1")
v2 = tf.Variable(tf.constant(2.0,shape=[1]),name="v2")
result = v1+v2
init_op = tf.global_variables_initializer()
saver = tf.train.Saver() # 声明tf.train.Save类,用于保存模型
with tf.Session() as sess:
sess.run(init_op)
saver.save(sess,"/home/xing/Downloads/tmp/model.ckpt")
saver.save函数将会把TF模型保存到/lab/test/model.ckpt文件中。
该目录下会同时新增4个文件:
-
model.ckpt.meta:计算图的结构
-
model.ckpt.data和model.ckpt.index:每一个变量的取值
-
checkpoint:一个目录下所有的模型文件列表
对应地,加载程序如下:
import tensorflow as tf
v1 = tf.Variable(tf.constant(1.0,shape=[1]),name="v1")
v2 = tf.Variable(tf.constant(2.0,shape=[1]),name="v2")
result = v1+v2
saver = tf.train.Saver()
with tf.Session() as sess:
saver.restore(sess,"/home/xing/Downloads/tmp/model.ckpt")
print(sess.run(result))
INFO:tensorflow:Restoring parameters from /home/xing/Downloads/tmp/model.ckpt
[3.]
注意:直接执行上述加载程序会报错,因为v1会被命名为v1:0,v1_1:0,...,导致result使用的刚定义的、未初始化的新v1。
我们必须重启kernel。实验:
# restart kernel
import tensorflow as tf
v1 = tf.Variable(tf.constant(1.0,shape=[1]),name="v1")
print(v1)
v1 = tf.Variable(tf.constant(1.0,shape=[1]),name="v1")
print(v1)
<tf.Variable 'v1:0' shape=(1,) dtype=float32_ref>
<tf.Variable 'v1_1:0' shape=(1,) dtype=float32_ref>
加载程序还有几点需要注意:
-
加载代码和保存代码基本一致,加载过程也需要定义所有运算、声明tf.train.Save类。原因见第三点。
-
不同之处为,加载过程不需要初始化变量,因为变量值由加载得到。
-
如果我们连运算都不想定义,我们应该加载计算图结构:
# restart kernel
import tensorflow as tf
saver = tf.train.import_meta_graph("/home/xing/Downloads/tmp/model.ckpt.meta")
with tf.Session() as sess:
saver.restore(sess,"/home/xing/Downloads/tmp/model.ckpt")
# 由于没有定义运算,因此我们要自行获取计算图,然后放到图里
print(sess.run(tf.get_default_graph().get_tensor_by_name("add:0")))
INFO:tensorflow:Restoring parameters from /home/xing/Downloads/tmp/model.ckpt
[3.]
tf.train.Saver类支持指定加载某个变量,如v1:
saver = tf.train.Saver([v1])
tf.train.Saver类还支持在保存或加载时给变量重命名。
例如刚刚我们保存的是v1和v2,现在我们重命名为other-v1和other-v2,加载方式如下:
# restart kernel
import tensorflow as tf
other_v1 = tf.Variable(tf.constant(1.0,shape=[1]),name="other-v1")
other_v2 = tf.Variable(tf.constant(1.0,shape=[1]),name="other-v2")
result = other_v1 + other_v2
saver = tf.train.Saver({"v1":other_v1, "v2":other_v2})
with tf.Session() as sess:
saver.restore(sess,"/home/xing/Downloads/tmp/model.ckpt")
print(sess.run(result))
INFO:tensorflow:Restoring parameters from /home/xing/Downloads/tmp/model.ckpt
[3.]
其中,我们向Saver函数输入字典,让函数能找到新、旧变量的对应关系。
我们之前学过影子变量和滑动平均模型。
现在借助变量重命名,我们就可以直接让保存模型中的影子变量映射到加载模型中的新变量,大大方便了我们的使用。
我们先保存影子变量:
import tensorflow as tf
v = tf.Variable(0,dtype=tf.float32,name="v")
ema = tf.train.ExponentialMovingAverage(0.99)
shadow_v = ema.apply(tf.global_variables()) # 实际上集合里只有v
for variable in tf.global_variables():
print(variable) # 注意影子变量的变量名,加载要用
saver = tf.train.Saver()
with tf.Session() as sess:
init_op = tf.global_variables_initializer()
sess.run(init_op)
sess.run(tf.assign(v,10))
sess.run(shadow_v) # 生成影子变量
saver.save(sess,"/home/xing/Downloads/tmp/model.ckpt")
print(sess.run([v,ema.average(v)]))
<tf.Variable 'v:0' shape=() dtype=float32_ref>
<tf.Variable 'v/ExponentialMovingAverage:0' shape=() dtype=float32_ref>
[10.0, 0.099999905]
再加载该模型,重命名影子变量:
# restart kernel
import tensorflow as tf
v = tf.Variable(0,dtype=tf.float32,name="v")
saver = tf.train.Saver({"v/ExponentialMovingAverage":v})
with tf.Session() as sess:
saver.restore(sess, "/home/xing/Downloads/tmp/model.ckpt")
print(sess.run(v))
INFO:tensorflow:Restoring parameters from /home/xing/Downloads/tmp/model.ckpt
0.099999905
可见,v变量加载的是实际上是原v/ExponentialMovingAverage变量。
由于这种操作很常用,TF的tf.train.ExponentialMovingAverage类提供了一个variables_to_restore函数,来生成所需字典:
# restart kernel
import tensorflow as tf
v = tf.Variable(0,dtype=tf.float32,name="v")
ema = tf.train.ExponentialMovingAverage(0.99) # 需要再声明ema
saver = tf.train.Saver(ema.variables_to_restore()) # 自动生成字典
with tf.Session() as sess:
saver.restore(sess, "/home/xing/Downloads/tmp/model.ckpt")
print(sess.run(v))
INFO:tensorflow:Restoring parameters from /home/xing/Downloads/tmp/model.ckpt
0.099999905
前面已经学过,如果我们不想再次定义变量,我们可以加载计算图,然后设为默认。
但是,如果我们需要得到一个变量值,仍然需要重新计算。
现在,我们既不想再次定义变量,也不想重新计算。
为此,TF提供了convert_variables_to_constants函数,将变量及其值保存成常量。
此时,整个计算图会被保存在一个文件里。
import tensorflow as tf
from tensorflow.python.framework import graph_util
v1 = tf.Variable(tf.constant(1.0,shape=[1]),name="v1")
v2 = tf.Variable(tf.constant(2.0,shape=[1]),name="v2")
result = v1+v2
init_op = tf.global_variables_initializer()
with tf.Session() as sess:
sess.run(init_op)
graph_def = tf.get_default_graph().as_graph_def() # 导出计算图的GraphDef部分,该部分可以完全表示计算
output_graph_def = graph_util.convert_variables_to_constants(sess, graph_def, ['add'])
# 将图中变量转换成常量,同时去掉不必要的节点(与计算无关的,见下一节),add是保存节点的名字
model_filename = "/home/xing/Downloads/tmp/model.pb"
with tf.gfile.GFile(model_filename,"wb") as f:
f.write(output_graph_def.SerializeToString()) # 将导出模型存入文件
INFO:tensorflow:Froze 2 variables.
Converted 2 variables to const ops.
import tensorflow as tf
from tensorflow.python.platform import gfile
with tf.Session() as sess:
model_filename = "/home/xing/Downloads/tmp/model.pb"
# 读取模型,将文件解析成对应的Graph Protocol Buffer
with gfile.FastGFile(model_filename, 'rb') as f:
graph_def = tf.GraphDef()
graph_def.ParseFromString(f.read())
# 将graph_def中保存的图加载到当前图中。
result = tf.import_graph_def(graph_def, return_elements=["add:0"])
# 保存时是计算节点的名称:add,加载时是张量的名称:add:0
print(sess.run(result))
[array([3.], dtype=float32)]
持久化原理及数据格式
上一节我们了解到:TF通过生成4个文件,让模型得以保存(持久化)。
这一节详细介绍了这4个文件的内容和数据格式。具体内容参见课本P117~,这里只摘录一些重要概念。
我们首先要知道,TF是一个通过图的形式表述计算的编程系统。所有计算都是图上的节点。
TF通过元图MetaGraph来记录节点的信息和运算节点所需元数据。
而元图又由MetaGraphDef Protocol Buffer定义。
保存MetaGraphDef信息的文件,默认以.meta为后缀,如上一节中的model.ckpt.meta。
这种文件允许以.json格式导出,即model.ckpt.meta.json文件。
除了持久化计算图的结构,持久化变量的取值也很重要,由model.ckpt.index和model.ckpt.data-...-of-...文件保存。
其中model.ckpt.data文件是SSTable格式,可以理解为key-value列表。
TF提供了tf.train.NewCheckpointReader类来查看变量信息:
import tensorflow as tf
reader = tf.train.NewCheckpointReader('/home/xing/Downloads/tmp/model.ckpt') # 注意没有index和data
global_variables = reader.get_variable_to_shape_map() # 获取了一个key-shape字典:global_variables
for variable_name in global_variables:
print(variable_name, global_variables[variable_name])
print(reader.get_tensor("v1")) # 也可以直接获取变量的值
v1 [1]
v2 [1]
[1.]
程序读取的是5.2小节第一个例程保存的ckpt文件。
tf.train.NewCheckpointReader既可以读字典,也可以读值。
最后一个文件是checkpoint,由tf.train.Saver类自动生成、维护。
其内容为该类持久化模型所用到的所有文件名。
model_checkpoint_path属性保存了最新的TF模型文件的文件名;all_model_checkpoint_paths属性列出了未被删除的文件的文件名。
5.5 TensorFlow最佳实践例程
最后,我们重写数字识别模型。
首先,变量管理提高程序的可读性;其次,持久化帮助我们保存中间结果,防止意外终止导致训练资源的浪费。
具体而言,我们将程序分为3大部分:
- mnist_inference.py:定义了前向传播过程及神经网络参数。
- mnist_train.py:定义了训练过程。
- mnist_eval.py:定义了测试过程。
mnist_inference.py
# -*- coding: utf-8 -*-
import tensorflow as tf
INPUT_NODE = 784
LAYER1_NODE = 500
OUTPUT_NODE = 10
# 生成权重矩阵
def get_weight_variable(shape, regularizer):
# 使用tf.get_variable函数生成。也可以用tf.Variable函数,区别参考变量管理。
weights = tf.get_variable("weights", shape, initializer=tf.truncated_normal_initializer(stddev=0.1))
# 如果有正则项,那么加入losses集合
if regularizer != None:
tf.add_to_collection('losses', regularizer(weights))
return weights
# 定义前向传播
def inference(input_tensor, regularizer):
# 第一层
with tf.variable_scope('layer1'):
weights = get_weight_variable([INPUT_NODE, LAYER1_NODE], regularizer)
biases = tf.get_variable("biases", [LAYER1_NODE], initializer=tf.constant_initializer(0.0))
layer1 = tf.nn.relu(tf.matmul(input_tensor, weights) + biases)
with tf.variable_scope('layer2'):
weights = get_weight_variable([LAYER1_NODE, OUTPUT_NODE], regularizer)
biases = tf.get_variable("biases", [OUTPUT_NODE], initializer=tf.constant_initializer(0.0))
layer2 = tf.matmul(layer1, weights) + biases
return layer2
上述文件,无论在训练环节还是测试环节都可以调用。
mnist_train.py
# -*- coding: utf-8 -*-
import os
import tensorflow as tf
from tensorflow.examples.tutorials.mnist import input_data
import mnist_inference
BATCH_SIZE = 100
LEARNING_RATE_BASE = 0.8
LEARNING_RATE_DECAY = 0.99
REGULARIZATION_RATE = 0.0001
TRAINING_STEPS = 30000
MOVING_AVERAGE_DECAY = 0.99
MODEL_SAVE_PATH = '/home/xing/Downloads/tmp/'
MODEL_NAME = "model.ckpt"
def train(mnist):
# x和label的placeholder
x = tf.placeholder(tf.float32, [None, mnist_inference.INPUT_NODE], name='x-input')
y_label = tf.placeholder(tf.float32, [None, mnist_inference.OUTPUT_NODE], name='y-label')
# 定义正则化项
regularizer = tf.contrib.layers.l2_regularizer(REGULARIZATION_RATE)
# 前向传播得到y_pred
y_pred = mnist_inference.inference(x, regularizer) # 注意有两个inference!
# 滑动平均所有可训练变量
global_step = tf.Variable(0, trainable = False)
variable_averages = tf.train.ExponentialMovingAverage(MOVING_AVERAGE_DECAY, global_step)
variables_averages_op = variable_averages.apply(tf.trainable_variables()) # 统一平滑
# 定义loss
cross_entropy = tf.nn.sparse_softmax_cross_entropy_with_logits(logits=y_pred, labels = tf.argmax(y_label, 1))
cross_entropy_mean = tf.reduce_mean(cross_entropy)
loss = cross_entropy_mean + tf.add_n(tf.get_collection('losses'))
# 指数衰减学习率
learning_rate = tf.train.exponential_decay(LEARNING_RATE_BASE, global_step,
mnist.train.num_examples / BATCH_SIZE, LEARNING_RATE_DECAY)
# 定义训练算法
train_op = tf.train.GradientDescentOptimizer(learning_rate).minimize(loss, global_step=global_step)
# 一边滑动平均(variables_averages_op)一边训练(train_op),得到滑动平均的训练算法(train_op_average)
with tf.control_dependencies([train_op, variables_averages_op]):
train_op_average = tf.no_op(name='train')
saver = tf.train.Saver()
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
for i in range(TRAINING_STEPS):
xs, ys = mnist.train.next_batch(BATCH_SIZE)
# 同时跑
_, cost, step = sess.run([train_op_average, loss, global_step], feed_dict={x:xs, y_label:ys})
if i % 1000 == 0:
print("Round: %4d | cost on training batch: %g" % (step, cost))
saver.save(sess, os.path.join(MODEL_SAVE_PATH, MODEL_NAME), global_step=global_step)
# 这样可以在文件名后加入训练次数,如model.ckpt-3000
def main(argv=None):
mnist = input_data.read_data_sets("/tmp/data",one_hot=True) # 声明用来处理mnist的类 会自动下载数据
train(mnist)
# 主程序入口。如果在主程序中(如交互界面提示符)调用,则执行main函数;若是其余程序调用,则不执行。
if __name__ == '__main__':
tf.app.run()
在文件所在目录下,用命令行执行:
python3 mnist_train.py # python 可能没有tensorflow模块
犯过三个错:
-
y_pred = mnist_inference.inference(x, regularizer)错写成mnist_inference(x, regularizer),导致module无法调用.
-
jupyter kernel未关,导致tensorflow只能在CPU下执行,发生错误。
-
输出层不能使用relu函数;这会导致负输出都变为0。
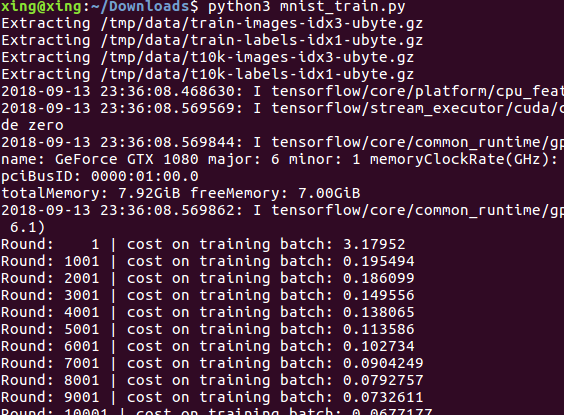
训练结果如图:
mnist_eval.py
# -*- coding: utf-8 -*-
import time
import tensorflow as tf
from tensorflow.examples.tutorials.mnist import input_data
import mnist_inference
import mnist_train
EVAL_INTERVAL_SECS = 10 # 测试间隔时间
def evaluate(mnist):
with tf.Graph().as_default() as g:
x = tf.placeholder(tf.float32, [None, mnist_inference.INPUT_NODE], name='x-input')
y_label = tf.placeholder(tf.float32, [None, mnist_inference.OUTPUT_NODE], name='y-label')
validate_feed = {x: mnist.validation.images, y_label: mnist.validation.labels}
y_pred = mnist_inference.inference(x, None)
# 由于get_variables函数会直接输出训练好的weights,因此不需要正则化
correct_prediction = tf.equal(tf.argmax(y_pred,1), tf.argmax(y_label, 1))
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
# 加载模型时重命名设置
variable_average = tf.train.ExponentialMovingAverage(mnist_train.MOVING_AVERAGE_DECAY)
variables_to_restore = variable_average.variables_to_restore()
saver = tf.train.Saver(variables_to_restore)
while True:
with tf.Session() as sess:
ckpt = tf.train.get_checkpoint_state(mnist_train.MODEL_SAVE_PATH) # 找到最新模型的文件名
if ckpt and ckpt.model_checkpoint_path: # 如果找到且path存在
saver.restore(sess, ckpt.model_checkpoint_path)
global_step = ckpt.model_checkpoint_path.split('/')[-1].split('-')[-1] # 取出数字
accuracy_score = sess.run(accuracy, feed_dict = validate_feed)
print("Round: %s | accuracy on validaton set: %g" % (global_step, accuracy_score))
else:
print('No checkpoint file found')
return
time.sleep(EVAL_INTERVAL_SECS)
def main(argv=None):
mnist = input_data.read_data_sets("/tmp/data",one_hot=True) # 声明用来处理mnist的类 会自动下载数据
evaluate(mnist)
# 主程序入口。如果在主程序中(如交互界面提示符)调用,则执行main函数;若是其余程序调用,则不执行。
if __name__ == '__main__':
tf.app.run()
运行同理。
注意,由于测试程序和训练程序是分离的,因此训练和测试可以同时进行。
如果训练不如测试快,那么测试往往会对同一个模型重复操作。
6. 图像识别与卷积神经网络
6.1 图像识别问题及其经典数据集
卷积神经网络(Convolutional Neural Network, CNN)在MNIST上表现非常突出,其识别率和人类几乎相同。
在更复杂的数据集上,CNN的表现更为突出,如CIFAR数据集。
CIFAR数据集分为两类:CIFAR-10和CIFAR-100,都是32×32彩色图像。
它们都是Visual Dictionary项目中800万张图片中的一个子集。
和MNIST类似,每一个图片只有一个标签和分类。不同的是,CIFAR数据为彩色图像。
人类标注准确率仅有94%,难度不小。而截至2014年,最好的算法已经达到95.59%的准确率。该算法正是使用了卷积神经网络。
CIFAR存在两个问题:
-
低分辨率;现实中往往会更清晰。
-
同一张图片往往会有多个对象和不同分类。
由斯坦福大学李飞飞教授牵头整理的ImageNet,在很大程度上解决了这些问题。
ImageNet是基于WordNet(语义库)的大型图像数据库。
在ImageNet中,近1500万张图片被关联到WordNet中大概20000个名词同义词集上,即可以认为是20000个分类。
ImageNet中的图像不仅包含多个实体,而且包含bounding box,如图。

ImageNet每年都会举办图像识别相关竞赛:ImageNet Large Scale Visual Recognition Challenge, ILSVRC。
本书着重介绍用得最广泛的ILSVRC2012图像分类数据集,包含1000个类别、120张图片,且每张图片都只有一个分类。
由于图片是从网络上爬取的,因此图片大小不等。
6.2 卷积神经网络简介
我们之前介绍的网络都属于全连接网络。顾名思义,两个相邻层之间的所有节点都有边相连。
而我们将要学习的卷积神经网络和循环网络,都不是全连接的。
实际上,全连接网络用于图像分类,在原理上是可行的。但实际应用会遇到两个问题:
-
图片一般较大,导致参数数量太大,计算慢,训练难;
-
参数多还容易导致过拟合。
下图给出了卷机神经网络的框架图:
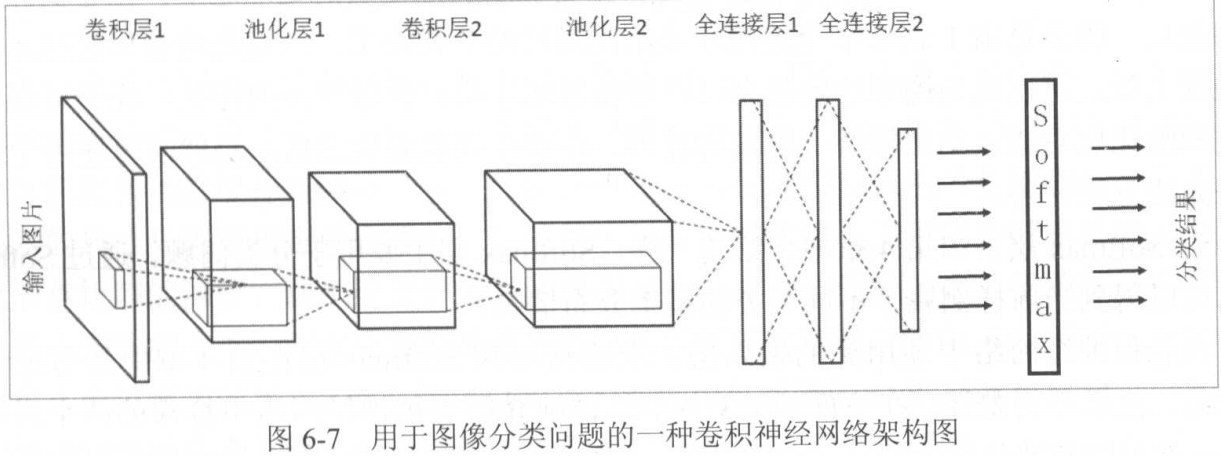
有以下特点和环节:
-
前几层的节点都组织为三维矩阵,第三个分类就是通道,如RGB通道。
-
经过卷积层后,节点矩阵会更深。原因是不同通道之间也存在连接。
-
池化不改变矩阵深度(即在单个通道内进行),但可以缩小矩阵大小。
-
我们已经得到了高度抽象的特征,再输入全连接层。此时的输入节点是比较少的,因此不难。
-
对于分类问题,我们最后采用Softmax输出。
下一节我们重点讲解卷积层和池化层。
6.3 卷积神经网络常用结构
卷积层
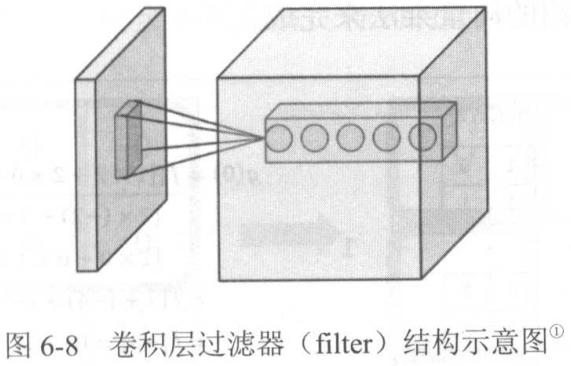
卷积层中的filter or kernel如图所示。
功能:将一个子节点矩阵,转化为下一层神经网络上的一个单位节点矩阵(长、宽为1,但深度不限)。
原理:
首先,该子节点矩阵的大小,又即过滤器尺寸,需要人工指定。常用的有3×3和5×5。
而子节点矩阵深度不需要指定,和该层深度一致。
其次,过滤器深度,即输出单位节点矩阵的深度,是需要指定的。
注意过滤器尺寸是对输入子节点矩阵而言,而深度又是对输出单位节点矩阵而言的。
我们下面举一个例子。假设我们要处理2×2×3的节点矩阵,目标是1×1×5的单位节点矩阵。
一个过滤器的前向传播过程与全连接层相似,因此需要(2×2×3+1)×5个参数,其中有5个偏置项。
设\(g(i)\)为输出单位节点矩阵中的第\(i\)个元素,则计算公式为:
其中\(a\)是输入子节点矩阵,\(w_{x,y,z}^i\)是连接强度,\(b^i\)是偏置参数,\(f\)是激活函数。
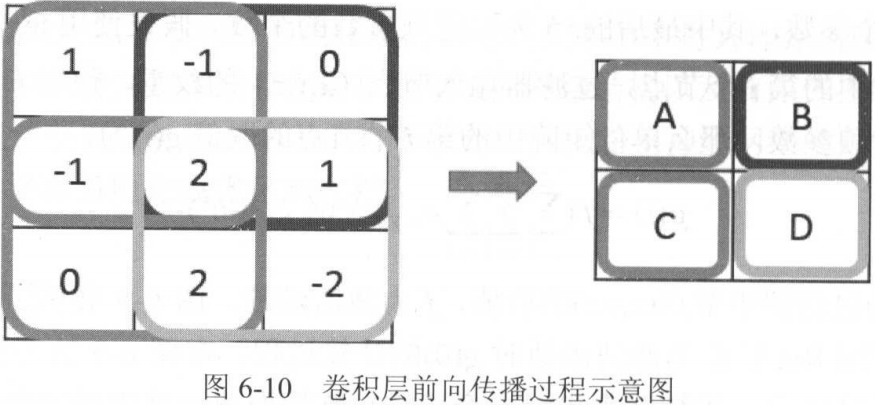
我们再假定取值,其计算过程具体如图:

只要过滤器尺寸不为1×1,卷积结果会越来越小。
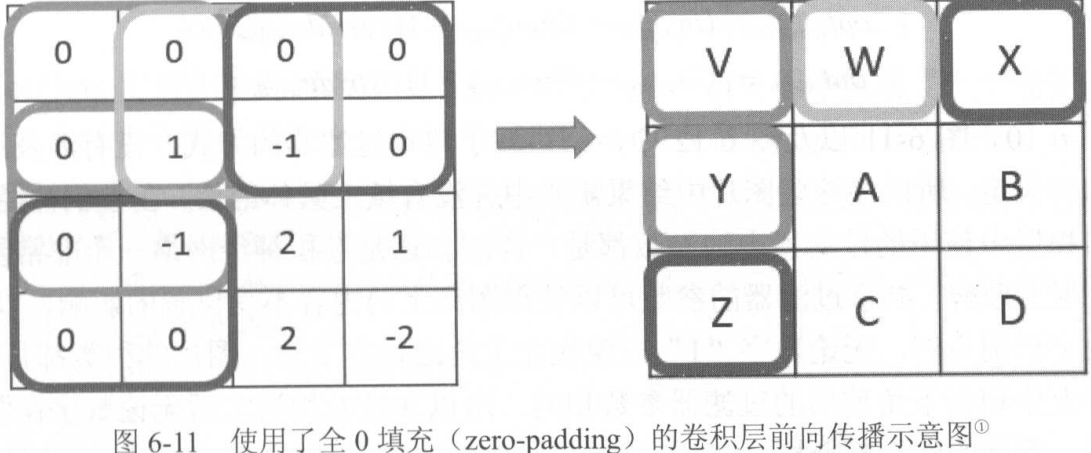
为了保持卷积前后矩阵大小不变,我们可以进行zero-padding:
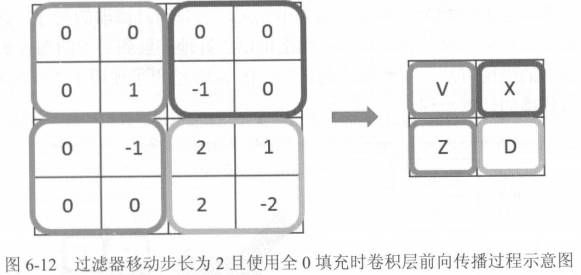
如果改变过滤器移动步长,结果也会不同:
在CNN中,每一个卷积层中使用的过滤器的参数都是一样的,即参数共享。好处在于:
-
参数大幅减少。
-
对于特定特征(类似模板匹配),无论在图像的哪个位置出现,检测效果都是一致的。即具有平移等变性。
-
参数数量与输入图像大小无关,而只与人工指定的过滤器深度和尺寸,以及输入深度有关。
最后我们给出一个相对完整的卷积运算示意图:
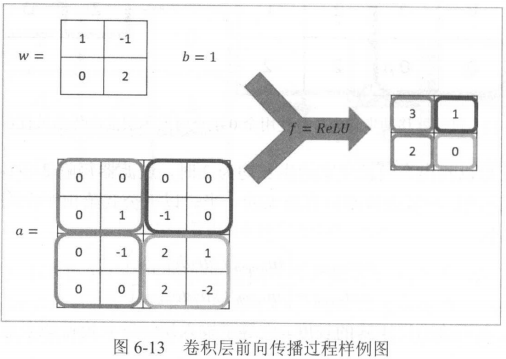
TensorFlow对CNN提供了很好的支持。代码示例:
filter_weight = tf.get_variable('weights',[5,5,3,16],initializer=tf.truncated_normal_initializer(stddev = 0.1))
# 过滤器尺寸为5×5,当前层深度为3,过滤器深度为16。
biases = tf.get_variable('biases',[16],initializer=tf.constant_initializer(0.1))
# 一个深度有一个偏置。
conv = tf.nn.conv2d(input, filter_weight, strides=[1,1,1,1], padding='SAME')
# input是一个四维矩阵,后三维是一幅图片,第一维是样本索引(第几张图片)。
# strides提供各维度上的步长。第一个和最后一个数必须是1,因为步长只对矩阵的长和宽有效。
# padding有两个选项:SAME(全0填充)和VALID(不添加)。
conv_add_bias = tf.nn.bias_add(conv, biases)
# 由于参数共享,因此不能直接相加。
actived_conv = tf.nn.relu(conv_add_bias)
# 计算结果去线性化
池化层
池化主要用于减小矩阵的尺寸,极少用于减小矩阵深度。
池化的作用和参数共享类似,都可以减少参数数量。但池化会引入小范围的平移不变性,而参数共享会引入平移等变性。
常用的池化有max pooling和average pooling。其他池化使用较少。
操作图解和卷积类似,但注意输入的是卷积输出的子节点矩阵。
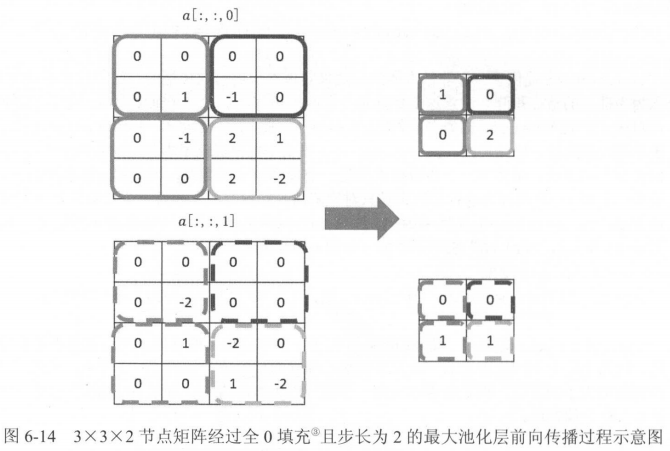
注意,在TF中全0填充先填右下方。
最大池化的实现如下:
pool = tf.nn.max_pool(activated_conv,kszie=[1,3,3,1],strides=[1,2,2,1],padding='SAME')
# 实际中常用[1,3,3,1]和[1,2,2,1]。
# 图中正是采用了stride = 2。
# 还有tf.nn.avg_pool函数,格式相同。
6.4 经典卷积网络模型
LeNet-5 模型
LeNet-5模型是Yann LeCun教授于1998年在论文Gradient-based learning applied to document recognition中提出的。
它是第一个应用于数字识别问题的卷积神经网络,在MNIST数据集上可以实现99.2%的正确率。
LeNet-5一共有7层,如图:
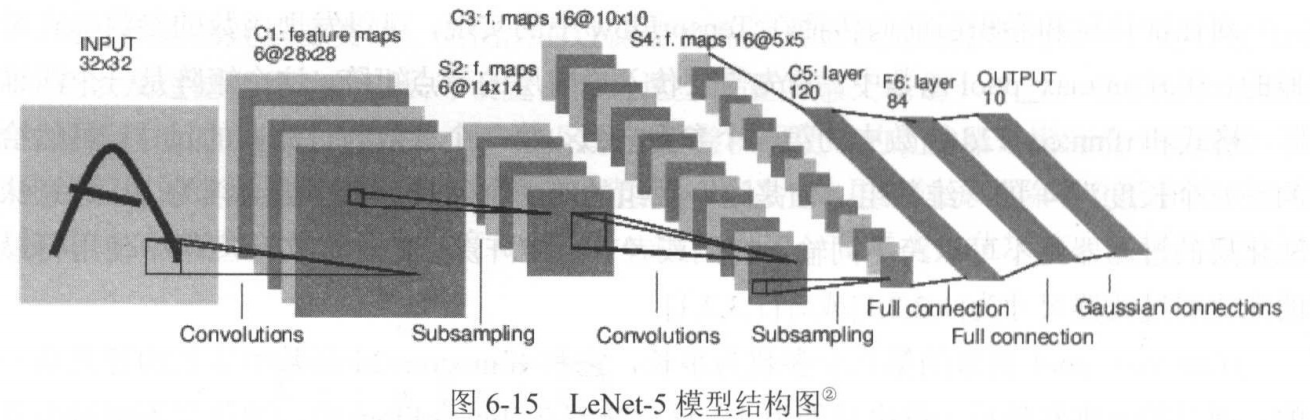
Layer1:卷积层
输入格式为32×32×1,过滤器尺寸为5×5,深度为6,不使用填充,步长为1。
因此输出尺寸为(32-5+1)×(32-5+1)=28×28。
加上6个偏置,一共有(5×5+1)×6=156个参数。
输入节点有32×32×1=1024个,输出节点有28×28×6=4704个。
Layer2:池化层
过滤器尺寸为2×2,长和宽的步长均为2,因此输出矩阵尺寸为(28/2)×(28/2)=14×14,深度仍为6。
Layer3:卷积层
输入格式为14×14×6,过滤器尺寸为5×5,深度为16,不使用填充,步长为1。
因此输出尺寸为(14-5+1)×(14-5+1)=10×10。
加上16个偏置,一共有(5×5×6+1)×16=2416个参数。
Layer4:池化层
过滤器尺寸为2×2,长和宽的步长均为2,因此输出矩阵尺寸为(10/2)×(10/2)=5×5,深度仍为16。
Layer5:全连接层
Yann的论文中称之为卷积层,但过滤器尺寸也是5×5,因此实际上就是全连接。
将输入的5×5×6的矩阵,伸展成长度为150的向量,这样更明显。
输出节点有120个。
Layer6:全连接层
输出节点有84个。
Layer7:全连接层
输出节点有10个,即十个数字分类。
书上给的代码,准确率只有11%左右,存在问题。
经过一天的排查,居然是因为基础学习率0.8太高了!!!调成0.01,准确率马上就上去了。
程序如下:
# mnist_train_CNN.py
# -*- coding: utf-8 -*-
import os
import tensorflow as tf
from tensorflow.examples.tutorials.mnist import input_data
import numpy as np # 改动1/6 reshape需要
import mnist_inference_CNN # 改动2/6 注意文件名
BATCH_SIZE = 100
LEARNING_RATE_BASE = 0.01
LEARNING_RATE_DECAY = 0.99
REGULARIZATION_RATE = 0.0001
TRAINING_STEPS = 30000
MOVING_AVERAGE_DECAY = 0.99
MODEL_SAVE_PATH = '/home/xing/Downloads/tmp/'
MODEL_NAME = "model.ckpt"
def train(mnist):
# x和label的placeholder
x = tf.placeholder(tf.float32,
[BATCH_SIZE,mnist_inference_CNN.IMAGE_SIZE,
mnist_inference_CNN.IMAGE_SIZE,mnist_inference_CNN.NUM_CHANNELS], # batch数量,图片尺寸(长、宽),通道数(深度)
name='x-input') # 改动3/6
y_label = tf.placeholder(tf.float32, [None, mnist_inference_CNN.OUTPUT_NODE], name='y-label')
# 定义正则化项
regularizer = tf.contrib.layers.l2_regularizer(REGULARIZATION_RATE)
# 前向传播得到y_pred
y_pred = mnist_inference_CNN.inference(x,1,regularizer) # 注意有两个inference! 改动4/6,标记是训练过程
# 滑动平均所有可训练变量
global_step = tf.Variable(0, trainable = False)
variable_averages = tf.train.ExponentialMovingAverage(MOVING_AVERAGE_DECAY, global_step)
variables_averages_op = variable_averages.apply(tf.trainable_variables()) # 统一平滑
# 定义loss
cross_entropy = tf.nn.sparse_softmax_cross_entropy_with_logits(logits=y_pred, labels = tf.argmax(y_label, 1))
cross_entropy_mean = tf.reduce_mean(cross_entropy)
loss = cross_entropy_mean + tf.add_n(tf.get_collection('losses'))
# 指数衰减学习率
learning_rate = tf.train.exponential_decay(LEARNING_RATE_BASE, global_step,
mnist.train.num_examples / BATCH_SIZE, LEARNING_RATE_DECAY)
# 定义训练算法
train_op = tf.train.GradientDescentOptimizer(learning_rate).minimize(loss, global_step=global_step)
# 一边滑动平均(variables_averages_op)一边训练(train_op),得到滑动平均的训练算法(train_op_average)
with tf.control_dependencies([train_op, variables_averages_op]):
train_op_average = tf.no_op(name='train')
saver = tf.train.Saver()
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
for i in range(TRAINING_STEPS):
xs, ys = mnist.train.next_batch(BATCH_SIZE)
reshaped_xs = np.reshape(xs,(BATCH_SIZE,mnist_inference_CNN.IMAGE_SIZE,
mnist_inference_CNN.IMAGE_SIZE,mnist_inference_CNN.NUM_CHANNELS)) # 改动5/6
# 同时跑
_, cost, step = sess.run([train_op_average, loss, global_step], feed_dict={x:reshaped_xs, y_label:ys})
# 改动6/6
if i % 1000 == 0:
print("Round: %4d | cost on training batch: %g" % (step, cost))
saver.save(sess, os.path.join(MODEL_SAVE_PATH, MODEL_NAME), global_step=global_step)
# 这样可以在文件名后加入训练次数,如model.ckpt-3000
def main(argv=None):
mnist = input_data.read_data_sets("/tmp/data",one_hot=True) # 声明用来处理mnist的类 会自动下载数据
train(mnist)
# 主程序入口。如果在主程序中(如交互界面提示符)调用,则执行main函数;若是其余程序调用,则不执行。
if __name__ == '__main__':
tf.app.run()
# mnist_inference_CNN.py
# -*- coding: utf-8 -*-
import tensorflow as tf
# 卷积网络参数
IMAGE_SIZE = 28
NUM_CHANNELS = 1
CONV1_SIZE = 5
CONV1_DEEP = 32
CONV2_SIZE = 5
CONV2_DEEP = 64
# 神经网络参数 输入节点数要考虑池化等,计算得到
FC_SIZE = 512
OUTPUT_NODE = 10
def inference(input_tensor, train, regularizer):
# 卷积层
with tf.variable_scope('layer1-conv1'):
weights = tf.get_variable("weight", [CONV1_SIZE,CONV1_SIZE, NUM_CHANNELS, CONV1_DEEP],
initializer = tf.truncated_normal_initializer(stddev=0.1))
biases = tf.get_variable("bias", [CONV1_DEEP], initializer=tf.constant_initializer(0.0))
conv1 = tf.nn.conv2d(input_tensor, weights, strides=[1,1,1,1],padding='SAME')
layer1 = tf.nn.relu(tf.nn.bias_add(conv1, biases))
# 池化层
with tf.name_scope('layer2-pool1'):
pool1 = tf.nn.max_pool(layer1, ksize=[1,2,2,1],strides=[1,2,2,1],padding='SAME')
with tf.variable_scope('layer3-conv2'):
weights = tf.get_variable("weight", [CONV2_SIZE,CONV2_SIZE, CONV1_DEEP, CONV2_DEEP],
initializer = tf.truncated_normal_initializer(stddev=0.1))
biases = tf.get_variable("bias", [CONV2_DEEP], initializer=tf.constant_initializer(0.0))
conv2 = tf.nn.conv2d(pool1, weights, strides=[1,1,1,1],padding='SAME')
layer3 = tf.nn.relu(tf.nn.bias_add(conv2, biases))
with tf.name_scope('layer4-pool2'):
pool2 = tf.nn.max_pool(layer3, ksize=[1,2,2,1],strides=[1,2,2,1],padding='SAME')
# 转换为向量
pool_shape = pool2.get_shape().as_list() # 得到输出的格式
nodes = pool_shape[1]*pool_shape[2]*pool_shape[3]
reshaped_tensor = tf.reshape(pool2, [pool_shape[0], nodes]) # pool_shape[0]是一个batch的容量
# 全连接层(神经网络)
with tf.variable_scope('layer5-fc1'):
weights = tf.get_variable("weight",[nodes, FC_SIZE],
initializer=tf.truncated_normal_initializer(stddev=0.1))
biases = tf.get_variable("biases", [FC_SIZE], initializer=tf.constant_initializer(0.1))
fc1 = tf.nn.relu(tf.matmul(reshaped_tensor, weights) + biases)
if regularizer != None: # 只有全连接层的权重才需要加入正则化
tf.add_to_collection('losses', regularizer(weights))
if train: # 如果是训练,那么就采用dropout方法。测试时不使用。
fc1 = tf.nn.dropout(fc1, 0.5)
with tf.variable_scope('layer6-fc2'):
weights = tf.get_variable("weight",[FC_SIZE, OUTPUT_NODE],
initializer=tf.truncated_normal_initializer(stddev=0.1))
biases = tf.get_variable("biases", [OUTPUT_NODE], initializer=tf.constant_initializer(0.1))
logit = tf.matmul(fc1, weights) + biases
if regularizer != None:
tf.add_to_collection('losses', regularizer(weights))
return logit
# mnist_eval_CNN.py
# -*- coding: utf-8 -*-
import time
import tensorflow as tf
import numpy as np
from tensorflow.examples.tutorials.mnist import input_data
import mnist_inference_CNN # 文件名都有改动
import mnist_train_CNN
EVAL_INTERVAL_SECS = 10
def evaluate(mnist):
with tf.Graph().as_default() as g:
x = tf.placeholder(tf.float32, [mnist.validation.num_examples, mnist_inference_CNN.IMAGE_SIZE, # None无法feed,会报错
mnist_inference_CNN.IMAGE_SIZE, mnist_inference_CNN.NUM_CHANNELS], name='x-input')
y_label = tf.placeholder(tf.float32, [None, mnist_inference_CNN.OUTPUT_NODE], name='y-label')
reshaped_x = np.reshape(mnist.validation.images, (mnist.validation.num_examples, mnist_inference_CNN.IMAGE_SIZE, # 不能用tf.reshape,否则将得到tensor
mnist_inference_CNN.IMAGE_SIZE, mnist_inference_CNN.NUM_CHANNELS))
validation_feed = {x: reshaped_x, y_label: mnist.validation.labels}
y_pred = mnist_inference_CNN.inference(x, 0, None) # 注意是x,因为实际用的是feed的值reshaped_x。
correct_prediction = tf.equal(tf.argmax(y_pred, 1), tf.argmax(y_label, 1))
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
variable_average = tf.train.ExponentialMovingAverage(mnist_train_CNN.MOVING_AVERAGE_DECAY)
variables_to_restore = variable_average.variables_to_restore()
saver = tf.train.Saver(variables_to_restore)
while True:
with tf.Session() as sess:
ckpt = tf.train.get_checkpoint_state(mnist_train_CNN.MODEL_SAVE_PATH)
if ckpt and ckpt.model_checkpoint_path:
saver.restore(sess, ckpt.model_checkpoint_path)
global_step = ckpt.model_checkpoint_path.split('/')[-1].split('-')[-1]
accuracy_score = sess.run(accuracy, feed_dict= validation_feed)
print("Round: %s | accuracy on validaton set: %g" % (global_step, accuracy_score))
else:
print('No checkpoint file found')
return
time.sleep(EVAL_INTERVAL_SECS)
def main(argv=None):
mnist = input_data.read_data_sets("/tmp/data", one_hot=True)
evaluate(mnist)
if __name__ == '__main__':
tf.app.run()
注意几点:
-
只有全连接层的权重才需要正则化。
-
dropout只用于训练时的全连接层,随机地使部分节点输出为0,避免过拟合。不用于测试和其它层。
-
由于加入了池化等因素,全连接层的输入节点数最好是自动计算的。
该模型比较简单,在处理ImageNet这样的较大数据库时,就会遇到难题。但以上结构是经典的:
输入层→(卷积层→池化层? ++)→全连接层 ++
2012年ImageNet第一名AlexNet,2014年第二名VGGNet等都采用上述模型。VGGNet曾经尝试过许多组合:
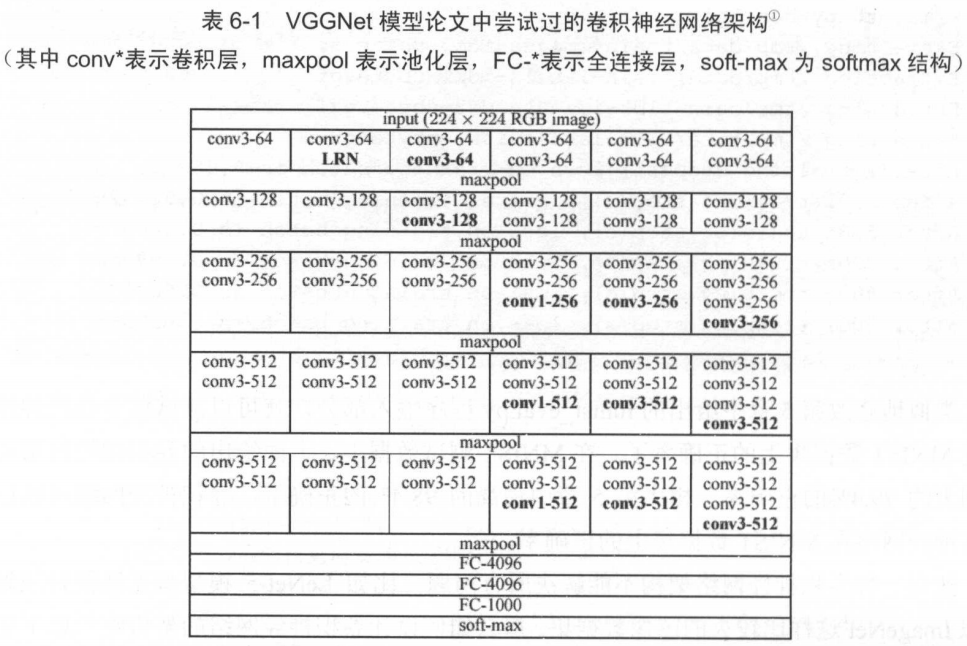
从上表可以看出:
-
过滤器尺寸一般在1到3之间,很少超过5。
-
过滤器深度逐层递增,乘2。
大部分卷积网络中,一般最多连续使用3层卷积层。
池化层虽然可以减少参数防止过拟合,但有论文指出,其作用可以由卷积层欠采样(增加步长)实现。
Inception-v3模型
在Inception-v3模型中,不同卷积层是并联的。这称为Inception结构:
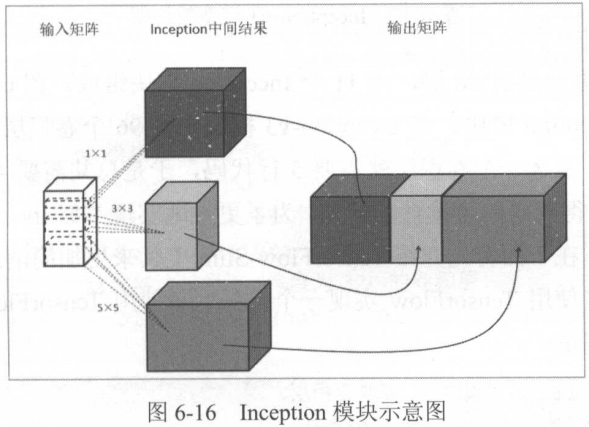
其最显著的特征是:Inception结构同时使用了边长为1、3、5等多种不同尺寸的滤波器。
尽管尺寸不同,但只要使用填充,并且步长都为1,那么结果就是相同的。
如图,3个结果拼成了一个大矩阵。
当然,这只是个简单的例子。
完整图:
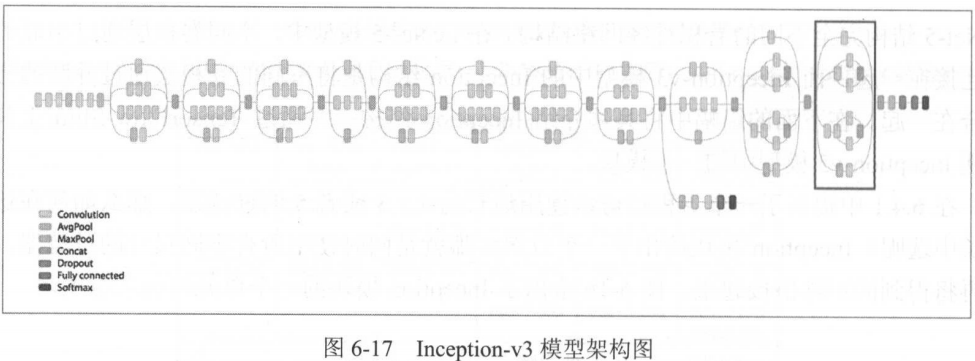
Slim工具可以大大简化代码量,见P158-160。
6.5 卷积神经网络迁移学习
训练复杂的卷积神经网络需要大量标记数据。
如ImageNet分类图像有120万张,为了达到96.5%的正确率,ResNet达到了惊人的152层。
显然我们面临两大问题:
-
数据少;
-
训练慢。
所谓迁移学习,就是指将一个适用于某个问题的模型,通过简单调整用于其他问题。
一般而言,迁移学习的准确率会低一些。详情看书。
7. 图像数据处理
本章介绍的图像预处理技术,旨在提高图像识别的精度和训练速度。
同时,为了减小预处理对训练速度的影响,我们也会学习TensorFlow中的多线程处理输入数据的技术。
7.1 TFRecord输入数据格式
TFRecord是TF提供的一种统一输入格式。具体格式见P171。
其中要注意的是,其属性可以是字符串(BytesList)、实数列表(FloatList)或整数列表(Int64List)。
我们以MNIST为例:
import tensorflow as tf
from tensorflow.examples.tutorials.mnist import input_data
import numpy as np
# 两种属性生成函数
def _int64_feature(value):
return tf.train.Feature(int64_list=tf.train.Int64List(value=[value]))
def _bytes_feature(value):
return tf.train.Feature(bytes_list=tf.train.BytesList(value=[value]))
# 属性提取
mnist = input_data.read_data_sets("/tmp/data", dtype=tf.uint8, one_hot=True)
images = mnist.train.images
labels = mnist.train.labels
pixels = images.shape[1] # 把分辨率也作为一个属性 shape = 55000x784(55000个列向量的形式)
# 保存路径
filename = "/tmp/output.tfrecords"
# 创建一个writer
writer = tf.python_io.TFRecordWriter(filename)
for index in range(mnist.train.num_examples):
# 将一个图像转换为字符串
image_raw = images[index].tostring()
# 产生Example Protocol Buffer数据结构
example = tf.train.Example(features = tf.train.Features(feature = {
'pixels': _int64_feature(pixels),
'label': _int64_feature(np.argmax(labels[index])),
'image_raw': _bytes_feature(image_raw)
}))
# 将其写入TFRecord文件
writer.write(example.SerializeToString())
writer.close()
Extracting /tmp/data/train-images-idx3-ubyte.gz
Extracting /tmp/data/train-labels-idx1-ubyte.gz
Extracting /tmp/data/t10k-images-idx3-ubyte.gz
Extracting /tmp/data/t10k-labels-idx1-ubyte.gz
当数据量较大时,还可以将数据存入多个TFRecord文件。
读取方法如下:
import tensorflow as tf
# 创建一个reader
reader = tf.TFRecordReader()
# 创建一个队列来维护输入文件列表
filename_queue = tf.train.string_input_producer(["/tmp/output.tfrecords"])
# 读一个 读多个应该用read_up_to函数
_, serialized_example = reader.read(filename_queue)
# 解析一个 解析多个应该用parse_example函数
# tf.FixedLenFeature的解析结果是一个Tensor,tf.VarLenFeature的解析结果是一个SparseTensor,用于处理稀疏数据。
features = tf.parse_single_example(serialized_example,
features = {
'image_raw': tf.FixedLenFeature([],tf.string),
'pixels': tf.FixedLenFeature([],tf.int64),
'label': tf.FixedLenFeature([],tf.int64)
})
# 从字符串转换回图像
image = tf.decode_raw(features['image_raw'],tf.uint8)
label = tf.cast(features['label'], tf.int32)
pixels = tf.cast(features['pixels'], tf.int32)
sess = tf.Session()
# 多线程处理
coord = tf.train.Coordinator()
threads = tf.train.start_queue_runners(sess=sess, coord=coord)
print(sess.run([image, label, pixels]))
[array([ 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 97,
96, 77, 118, 61, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 90, 138, 235, 235, 235, 235, 235,
235, 251, 251, 248, 254, 245, 235, 190, 21, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 140, 251, 254, 254, 254, 254,
254, 254, 254, 254, 254, 254, 254, 254, 254, 254, 189, 23, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 226, 254, 208, 199,
199, 199, 199, 139, 61, 61, 61, 61, 61, 128, 222, 254, 254,
189, 21, 0, 0, 0, 0, 0, 0, 0, 0, 0, 38, 82,
13, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 34,
213, 254, 254, 115, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 84, 254, 254, 234, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 84, 254, 254, 234, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 106, 157, 254, 254, 243, 51, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 25, 117, 228, 228, 228, 253, 254, 254, 254, 254, 240,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 68, 119, 220, 254, 254, 254, 254, 254, 254, 254, 254,
254, 142, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 37, 187, 253, 254, 254, 254, 223, 206, 206, 75, 68,
215, 254, 254, 117, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 113, 219, 254, 242, 227, 115, 89, 31, 0, 0,
0, 0, 200, 254, 241, 41, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 169, 254, 176, 62, 0, 0, 0, 0,
0, 0, 0, 48, 231, 254, 234, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 18, 124, 0, 0, 0, 0,
0, 0, 0, 0, 0, 84, 254, 254, 166, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 139, 254, 238, 57, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 210, 250, 254, 168, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 242, 254, 239,
57, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 89, 251,
241, 86, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 5,
206, 246, 157, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 4, 117, 69, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0], dtype=uint8), 7, 784]
每次运行上述程序,都会读取一个。当所有样例都读完了以后,程序会从头读取。
7.2 图像数据处理
图像编码和解码
如果要从一般图像格式中(jpg,png等)获取图像矩阵,必须经过解码。以下是jpg jpeg格式的例程:
import matplotlib.pyplot as plt # 这是一个python画图工具
import tensorflow as tf
image_raw_data = tf.gfile.FastGFile("/home/xing/Pictures/head portrait.jpg","rb").read()
with tf.Session() as sess:
img_data = tf.image.decode_jpeg(image_raw_data) # 解码后为张量
# print(img_data.eval())会输出矩阵
plt.imshow(img_data.eval())
plt.show() # 需要调用show()方法,不然图像只会在内存中而不显示出来
# 编码,写到桌面
encoded_image = tf.image.encode_jpeg(img_data)
with tf.gfile.GFile("/home/xing/Desktop/head portrait.jpg","wb") as f:
f.write(encoded_image.eval())

图像大小调整
由于神经网络是固定的,因此我们往往需要调整图像大小。
为此,TF提供了4种方法,统一封装到了tf.image.resize_images函数中:
with tf.Session() as sess:
img_data = tf.image.decode_jpeg(image_raw_data) # 解码后为张量
# 从0-255转换为0.0-1.0
img_data = tf.image.convert_image_dtype(img_data, dtype=tf.float32)
img_resized0 = tf.image.resize_images(img_data,[1000,1000],method=0) # Bilinear interpolation
img_resized1 = tf.image.resize_images(img_data,[1000,1000],method=1) # Nearest neighbor interpolation
img_resized2 = tf.image.resize_images(img_data,[1000,1000],method=2) # Bicubic interpolation
img_resized3 = tf.image.resize_images(img_data,[1000,1000],method=3) # Area interpolation
plt.subplot(221), plt.imshow(img_resized0.eval()), plt.title('Bilinear interpolation')
plt.subplot(222), plt.imshow(img_resized1.eval()), plt.title('Nearest neighbor interpolation')
plt.subplot(223), plt.imshow(img_resized2.eval()), plt.title('Bicubic interpolation')
plt.subplot(224), plt.imshow(img_resized3.eval()), plt.title('Area interpolation')
plt.show()

裁剪或空白填充功能如下:
with tf.Session() as sess:
img_data = tf.image.decode_jpeg(image_raw_data)
img_data = tf.image.convert_image_dtype(img_data, dtype=tf.float32)
img_croped = tf.image.resize_image_with_crop_or_pad(img_data,1400,700) # 自动裁剪中央部分
plt.subplot(121), plt.imshow(img_croped.eval()), plt.title('crop')
img_padded = tf.image.resize_image_with_crop_or_pad(img_data,2000,2000) # 自动填充0,即黑色
plt.subplot(122), plt.imshow(img_padded.eval()), plt.title('pad')
plt.show()

还可以按比例调整:
with tf.Session() as sess:
img_data = tf.image.decode_jpeg(image_raw_data)
img_data = tf.image.convert_image_dtype(img_data, dtype=tf.float32)
img_central_cropped = tf.image.central_crop(img_data, 0.5)
plt.imshow(img_central_cropped.eval())
plt.show()

上面介绍的主要都是从图像中央开始操作的。
还有其他函数,如tf.image.crop_to_bounding_box和tf.image.pad_to_bounding_box函数,可以指定区域。
图像翻转
with tf.Session() as sess:
img_data = tf.image.decode_jpeg(image_raw_data)
img_data = tf.image.convert_image_dtype(img_data, dtype=tf.float32)
img_flipped = tf.image.flip_up_down(img_data)
plt.subplot(121), plt.imshow(img_flipped.eval()), plt.title('flipped')
img_transposed = tf.image.flip_left_right(img_data)
plt.subplot(122), plt.imshow(img_transposed.eval()), plt.title('transposed')
plt.show()

在训练神经网络时,可以随机翻转训练图片,让模型泛化能力得以增强。
TF提供了随机翻转API:
flipped = tf.image.random_flip_up_down(img_data)
flipped = tf.image.random_flip_left_right(img_data)
图像色彩调整
同理,我们也可以随机调整图像的色相、对比度、亮度等。下面是简单调整方法:
with tf.Session() as sess:
img_data = tf.image.decode_jpeg(image_raw_data)
img_data = tf.image.convert_image_dtype(img_data, dtype=tf.float32)
# 亮度变化
img_adjusted = tf.image.adjust_brightness(img_data,-0.5)
# 需要注意的是,这种操作可能会使图像超出0-1而无法显示。我们需要进行截断处理。
img_adjusted = tf.clip_by_value(img_adjusted,0.0,1.0)
plt.subplot(131), plt.imshow(img_adjusted.eval()), plt.title('-0.5')
# 需要注意的是,如果图像有多步操作,应该在最后截断。
img_adjusted = tf.image.adjust_brightness(img_data,-0.5)
img_adjusted = tf.image.adjust_brightness(img_adjusted,0.7)
img_adjusted = tf.clip_by_value(img_adjusted,0.0,1.0)
plt.subplot(132), plt.imshow(img_adjusted.eval()), plt.title('multi-steps')
plt.show()
# 在[-max_delta,max_delta]范围内随机调整
img_adjusted = tf.image.random_brightness(img_data,max_delta=0.5)
plt.subplot(133), plt.imshow(img_adjusted.eval()), plt.title('random')
plt.show()


对比度、色相、饱和度等调整见P180-181。
除此之外,TF还提供图像标准化操作(亮度均值为0,方差为1):
with tf.Session() as sess:
img_data = tf.image.decode_jpeg(image_raw_data)
img_data = tf.image.convert_image_dtype(img_data, dtype=tf.float32)
img_adjusted = tf.image.per_image_standardization(img_data)
plt.imshow(img_adjusted.eval())
plt.show()

处理标注框
比如我们想标注图中人的头部和人体:
with tf.Session() as sess:
img_data = tf.image.decode_jpeg(image_raw_data)
# 先缩小,再转换为实数
img_resized = tf.image.resize_images(img_data, [500,500], method=1)
img_resized = tf.image.convert_image_dtype(img_resized, dtype=tf.float32)
# 增维。函数要求输入一个batch,即四维矩阵
batch = tf.expand_dims(img_resized, 0)
# 标记框,分别是y_min,x_min,y_max,x_max的相对位置
box = tf.constant([[[50.0/500,200.0/500,450.0/500,400.0/500]
,[50.0/500,250.0/500,180.0/500,380.0/500]]])
result = tf.image.draw_bounding_boxes(batch,box)
plt.subplot(121), plt.imshow(img_data.eval()), plt.title('original')
plt.subplot(122), plt.imshow(result[0].eval()), plt.title('result')
plt.show()

和随机翻转图片、随机调整颜色类似,随机截取图片上的信息位置也是一种提高泛化能力的方法。详见P182-183。
组合随机化处理
见P183-184。
7.3 多线程输入数据处理框架
为了避免复杂的预处理拖慢训练过程,我们需要边处理边训练。其经典流程为:
-
指定原始数据的文件列表
-
创建文件列表队列
-
从文件中读取数据
-
数据预处理
-
整理成Batch作为网络输入
队列与多线程
在TF中,队列和变量相似,都是计算图上有状态的节点。
要修改队列的状态,主要有Enqueue, EnqueueMany, Dequeue操作。
import tensorflow as tf
# 创建一个先入先出队列,并且最多只有2个元素,类型为整数:
q = tf.FIFOQueue(2, "int32")
# 初始化队列中的元素
init = q.enqueue_many(([0,10],))
# 输出第一个元素
x = q.dequeue()
y = x + 1
# 把y加入队列
q_inc = q.enqueue([y])
with tf.Session() as sess:
init.run()
for buf in range(5):
v,buf = sess.run([x,q_inc])
print(v)
0
10
1
11
2
如果我们希望随机输入训练数据,那么可以使用RandomShuffleQueue函数。
在TF中,队列不仅仅是一种数据结构,更是一种异步计算张量取值的重要方式。
比如,我们可以使用多线程,从一个队列中读数据,同时向另一个队列写数据。
我们一步步来,首先了解如何实现多线程。
import tensorflow as tf
import numpy as np
import threading
import time
# 假设我们一共有5个线程
# 每一个线程都可以提出终止所有线程的请求:request_stop
# should_stop函数会返回True
# 每一个线程需要一直查询should_stop函数,当收到True时,自动退出
# 请求随机提出
# 每一个线程的功能:打印自己的序号
# 线程的功能
def MyLoop(coord, worker_id):
# 每一个线程需要一直查询should_stop函数,当收到True时,自动退出
while not coord.should_stop: # 未收到通知
# 随机提出终止请求
if np.random.rand()<0.1:
print("Stoping from id: %d\n" % worker_id)
# 通知其他线程也要停止
coord.request_stop()
else:
print("Working on id: %d\n" % worker_id)
# 暂停1秒
time.sleep(1)
# 声明一个tf.train.Coordinator类,来协同多个线程
coord = tf.train.Coordinator()
# 创建5个线程,将coord传进去
threads = [threading.Thread(target=MyLoop, args=(coord, i, )) for i in range(5)]
# 正式启动线程
for t in threads:
t.start()
# 等待线程停止
coord.join(threads)
除了用于多线程协同的tf.Coordinator类,TF还提供了tf.QueueRunner类来启动多线程操作同一个队列:
import tensorflow as tf
queue = tf.FIFOQueue(100,"float")
enqueue_op = queue.enqueue([tf.random_normal([1])]) # shape = [1]的正态分布
# 需要启动5个进程,每个进程都是enqueue_op操作
qr = tf.train.QueueRunner(queue, [enqueue_op]*5)
# 将qr加入默认的tf.GraphKeys.QUEUE_RUNNERS集合。
tf.train.add_queue_runner(qr)
# 出队操作
out_tensor = queue.dequeue()
with tf.Session() as sess:
coord = tf.train.Coordinator()
# 每一个线程,都往同一个队列queue中输入1个随机数,共输入5个随机数。
# 原理: 自动启动tf.GraphKeys.QUEUE_RUNNERS集合中的所有QueueRunner。所以前面才需要加入该集合。
threads = tf.train.start_queue_runners(sess=sess, coord=coord)
for _ in range(3):
print(sess.run(out_tensor)[0]) # 获取输出队列中的第一个值,即当前取值
# 停止所有线程
coord.request_stop()
coord.join(threads)
0.09585315
-1.9874468
-1.1195158
输入文件队列
我们在第一节已经学过,把训练数据转换成TFRecord格式存起来。
当数据量较大时,我们可以把数据分成多个TFRecord文件。
我们可以用一些函数来管理多个文件。
-
tf.train.match_filenames_once函数:获取符合一个正则表达式的所有文件
-
tf.train.string_input_producer函数:管理文件
具体而言,它会创建一个输入队列,里面的元素都是初始化提供的文件列表。输入队列可以作为文件读取函数的参数,每次调用时会自动判断是否存在或读完,自动读取下一个文件。通过设置shuffle参数,可以随机打乱文件列表中文件的出队顺序。该队列还可以被多个线程同时读取,文件会均分给不同的线程。所有文件读完后,会重新初始化。最大重载次数可以通过设置num_epochs参数确定。比如在测试网络时,数据只会用1次。
在演示前,我们先生成样例数据:
import tensorflow as tf
def _int64_feature(value):
return tf.train.Feature(int64_list=tf.train.Int64List(value=[value]))
num_shards = 2 # 总共写入2个文件
instances_per_shard = 2 # 每个文件中有2个数据
for i in range(num_shards):
filename = ('/home/xing/Downloads/tmp/data.tfrecords-%.5d-of-%.5d' % (i, num_shards))
# 如00000-of-00002 表示2个文件中的第1个 方便正则表达式
writer = tf.python_io.TFRecordWriter(filename)
# 封装成Example结构并写入TFRecord文件
for j in range(instances_per_shard):
example = tf.train.Example(features = tf.train.Features(feature = {
'i': _int64_feature(i),
'j': _int64_feature(j)})) # 只记录文件序号和数据序号
writer.write(example.SerializePartialToString())
writer.close()
两个数据文件已经生成,现在我们演示两个函数:
import tensorflow as tf
# 使用tf.train.match_filenames_once获取文件列表
files = tf.train.match_filenames_once("/home/xing/Downloads/tmp/data.tfrecords-*")
# 使用tf.train.string_input_producer创建队列,不随机打乱
filename_queue = tf.train.string_input_producer(files, shuffle=False) # 现实应用中一般为True
# 读取和解析文件 和7.1节对图片的操作一样,但注意是从filename_queue中读
reader = tf.TFRecordReader()
_, serialized_example = reader.read(filename_queue)
features = tf.parse_single_example(serialized_example,
features={
'i': tf.FixedLenFeature([], tf.int64),
'j': tf.FixedLenFeature([], tf.int64),
})
with tf.Session() as sess:
# 虽然没有声明变量,但tf.train.match_filenames_once函数要求初始化
tf.local_variables_initializer().run()
print(sess.run(files))
coord = tf.train.Coordinator()
threads = tf.train.start_queue_runners(sess=sess, coord=coord)
for i in range(5):
print(sess.run([features['i'],features['j']]))
coord.request_stop()
coord.join(threads)
[b'/home/xing/Downloads/tmp/data.tfrecords-00001-of-00002'
b'/home/xing/Downloads/tmp/data.tfrecords-00000-of-00002']
[1, 0]
[1, 1]
[0, 0]
[0, 1]
[1, 0]
为什么要启动线程?因为filename_queue队列只有在启动后才会被输入元素(文件名)。
组合训练数据batching
上一节介绍的是:从文件列表中读取单个样例。
在这一节我们介绍:将单个样例组织成batch的方法。
-
tf.train.batch
-
tf.train.shuffle_batch,会打乱
import tensorflow as tf
files = tf.train.match_filenames_once("/home/xing/Downloads/tmp/data.tfrecords-*")
filename_queue = tf.train.string_input_producer(files, shuffle=False) # 现实应用中一般为True
reader = tf.TFRecordReader()
_, serialized_example = reader.read(filename_queue)
features = tf.parse_single_example(serialized_example,
features={
'i': tf.FixedLenFeature([], tf.int64),
'j': tf.FixedLenFeature([], tf.int64),
})
# 如果是一张图像,那么i可以是像素矩阵,j是对应的标签。
example, label = features['i'], features['j']
batch_size = 3
# batching也使用队列的方式执行。
# capacity是batching队列的容量。太大内存紧张,太小可能无法batch。这是一个通用设置方式。
capacity = 1000 + 3 * batch_size
example_batch, label_batch = tf.train.batch([example, label], batch_size, capacity=capacity)
with tf.Session() as sess:
tf.local_variables_initializer().run()
coord = tf.train.Coordinator()
threads = tf.train.start_queue_runners(sess=sess, coord=coord)
for i in range(2):
print(sess.run([example_batch, label_batch]))
coord.request_stop()
coord.join(threads)
[array([1, 1, 0]), array([0, 1, 0])]
[array([0, 1, 1]), array([1, 0, 1])]
为什么是上面的结果呢?因为example和label分别是:
-
1,0
-
1,1
-
0,0
-
0,1
循环一下就知道了。
下面是shuffle用法。
注意有一个参数min_after_dequeue。如果所剩元素太少,就没必要随机打乱了,没意义。此时会先入队,再打乱。
import tensorflow as tf
files = tf.train.match_filenames_once("/home/xing/Downloads/tmp/data.tfrecords-*")
filename_queue = tf.train.string_input_producer(files, shuffle=False) # 现实应用中一般为True
reader = tf.TFRecordReader()
_, serialized_example = reader.read(filename_queue)
features = tf.parse_single_example(serialized_example,
features={
'i': tf.FixedLenFeature([], tf.int64),
'j': tf.FixedLenFeature([], tf.int64),
})
example, label = features['i'], features['j']
batch_size = 3
capacity = 1000 + 3 * batch_size
example_batch, label_batch = tf.train.shuffle_batch([example, label], batch_size,
capacity=capacity, min_after_dequeue=30)
with tf.Session() as sess:
tf.local_variables_initializer().run()
coord = tf.train.Coordinator()
threads = tf.train.start_queue_runners(sess=sess, coord=coord)
for i in range(2):
print(sess.run([example_batch, label_batch]))
coord.request_stop()
coord.join(threads)
[array([0, 1, 1]), array([0, 0, 1])]
[array([0, 1, 0]), array([0, 1, 1])]
7.4 数据集Dataset
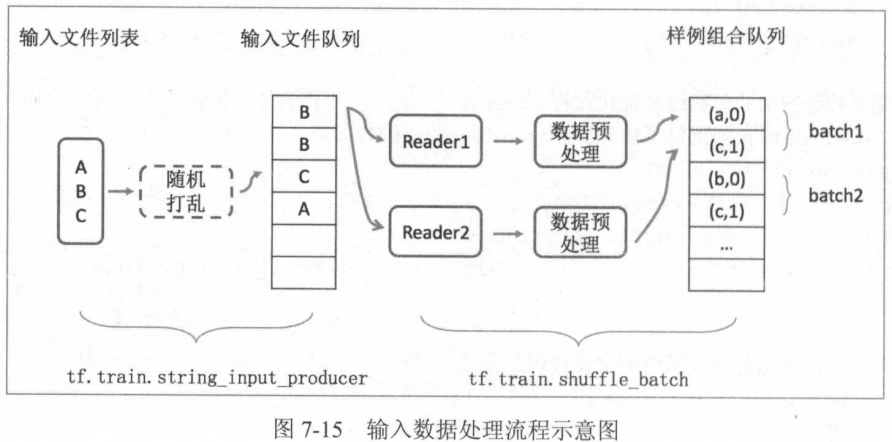
上一节介绍的是:通过队列进行多线程输入的方法,完整样例见P196-198,示意图为:
实际上队列方法非常繁琐。本节介绍的数据集方法,是TF提供的高级数据处理框架,也是TF的核心组件(tf.data)。
数据集的基本使用方法
每一个数据集代表一个数据来源:张量,TFRecord文件,文本文件,或是经过sharding的文件等等。
为什么说是”来源“呢?因为一个数据集是一个迭代器iterator。该功能一并代替了队列的dequeue操作和Reader的read操作。
与队列相同的是,数据集也是计算图中的一个节点。
简单举例:由一个张量,创建一个数据集,遍历,求平方。
import tensorflow as tf
input_data = [1,2,3,5,8]
dataset = tf.data.Dataset.from_tensor_slices(input_data)
iterator = dataset.make_one_shot_iterator()
x = iterator.get_next()
y = x * x
with tf.Session() as sess:
for i in range(len(input_data)):
print(sess.run(y))
1
4
9
25
64
如果一个数据放在一个文本文件中,如自然语言处理任务,则可以用以下方式:
input_files = ["path1","path2",...]
dataset = tf.data.TextLineDataset(input_files)
和图像相关的任务中,输入数据通常以TFRecord形式存储。此时使用TFRecordDataset函数。
要注意的是,由于每个TFRecord的feature格式不尽相同,因此读取时需要提供语义解析函数parser:
import tensorflow as tf
def parser(record):
features = tf.parse_single_example(record, features={
'fea1': tf.FixedLenFeature([], tf.int64),
'fea2': tf.FixedLenFeature([], tf.int64),
})
return features['fea1'],features['fea2']
input_files = ["path1","path2",...]
dataset = tf.data.TFRecordDataset(input_files)
# map: 对每一条数据都调用同样的parser进行解析
dataset = dataset.map(parser)
iterator = dataset.make_one_shot_iterator()
fea1,fea2 = iterator.get_next()
with tf.Session() as sess:
for i in range(len(input_data)):
print(sess.run([fea1, fea2]))
以上例子都使用了one_shot_iterator来遍历数据集。
此时要求数据集中所有参数都是确定的,因此不需要初始化。
如果使用placeholder,那么就要用到initializable_iterator:
import tensorflow as tf
def parser(record):
...
input_files = tf.placeholder(tf.string) # 稍后再提供具体路径 这样定义就有鲁棒性
dataset = tf.data.TFRecordDataset(input_files)
dataset = dataset.map(parser)
iterator = dataset.make_initializable_iterator()
fea1,fea2 = iterator.get_next()
with tf.Session() as sess:
sess.run(iterator.initializer,
feed_dict = {input_files: ["path1","path2",...]})
while True: # 因为数据集是迭代器,其容量是未知的,只能用此方式
try:
print(sess.run([fea1, fea2]))
except tf.errors.OutOfRangeError:
break
此外还有reinitializable_iterator和feedable_iterator两种更灵活的迭代器,这里跳过。
数据集的高层操作
dataset = dataset.map(parser) # 解析操作
dataset = dataset.shuffle(buffer_size) # 随机打乱操作 buffer_size就是min_after_dequeue参数
dataset = dataset.batch(batch_size) # batching操作
dataset = dataset.repeat(N) # 复制N份
etc
需要注意:
-
map是一个很牛逼的操作。
比如我们有用于图像预处理的preprocess_for_train函数,原做法和现做法对比如下:
distorted_image = preprocess_for_train(decoded_image, image_size, image_size, None) dataset = dataset.map(lambda x : preprocess_for_train(x, image_size, image_size, None))二者代码长度差不多,但意义很不相同!!!dataset只是一个迭代器,再其上可以继续调用其他高级操作。也就是说,我们的代码始终在数据集上操作,而以前总在队列和图片张量上来回切换,代码不简洁。
注意,lambda函数只有一个变量x,其余都是需要给出的常量。
-
在batch操作中,假设image是[300,300]的张量,label维度是[],batch_size=128,那么batching的结果就是:
[128,300,300], [128] -
repeat的是迭代器,不是结果(不保证结果一致)。特别当前面有shuffle的情况下。
-
preprocess_for_train是用于训练的,测试时不动图片。
例程见P204-207。
8. 循环神经网络
本章要介绍重要的recurrent neural network, RNN和long short-term memory, LSTM。
8.1 循环神经网络简介
详细知识参见《深度学习》。
我们以下图为例:
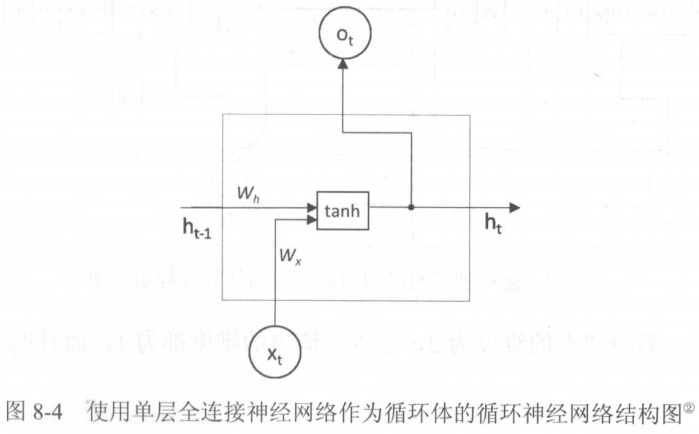
如图,RNN的输入有两部分,一部分是上一时刻的状态,另一部分是当前时刻的输入。
对于时间序列数据而言,这些状态和输入可以是某时刻的销售量、一句话中的单词等。
该例中,循环体使用的是单层全连接神经网络。
假设输入为\(n\)维,隐藏状态为\(x\)维,那么总输入就是两个向量的拼接:\(n+x\)维。
注意,在编程时为了方便区分,我们通常把两个向量分开写,因此权重矩阵也是分开的,但运算本质是相同的。
单层全连接网络将\(n\)维的输入转换为\(n\)维的输出,因为要实时反映状态。
因此全连接网络的隐藏层参数(循环体参数)有\([(n+x)+1]*n\)个。
计算示意图如下:
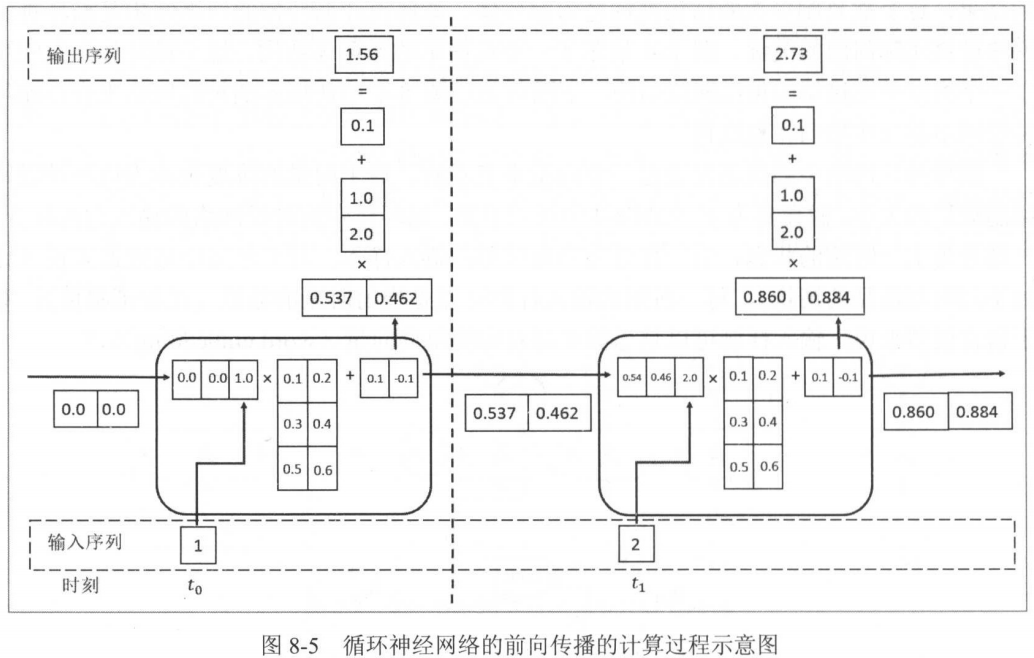
注意:输出层也有对应的参数矩阵和偏置,但不非线性化。
循环神经网络的总损失是所有时刻的损失之和。
在实际训练中,如果序列过长,内存会吃紧,同时可能出现梯度消失或爆炸的问题。
这一问题统称为长期依赖long-term dependencies问题。
该问题的优化,需要借助渗漏单元,门控RNN等。参见《深度学习》和下一节内容。
8.2 长短时记忆网络LSTM
继上节。当遇到复杂的序列问题时,仅仅根据短期依赖无法解决问题。
LSTM的出现就是为了解决上述问题。其结构示意图如下:
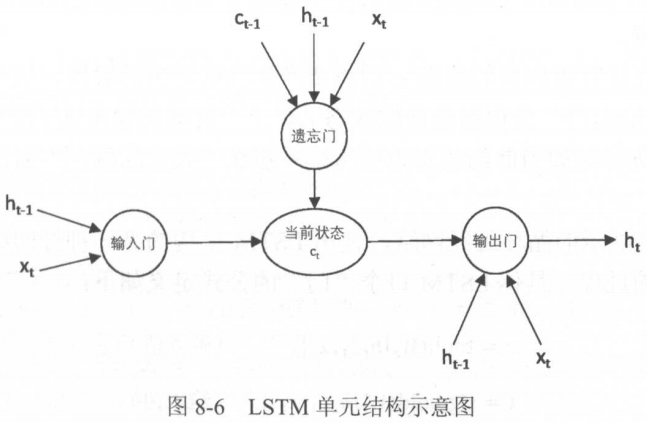
其独特之处在于3个门结构。
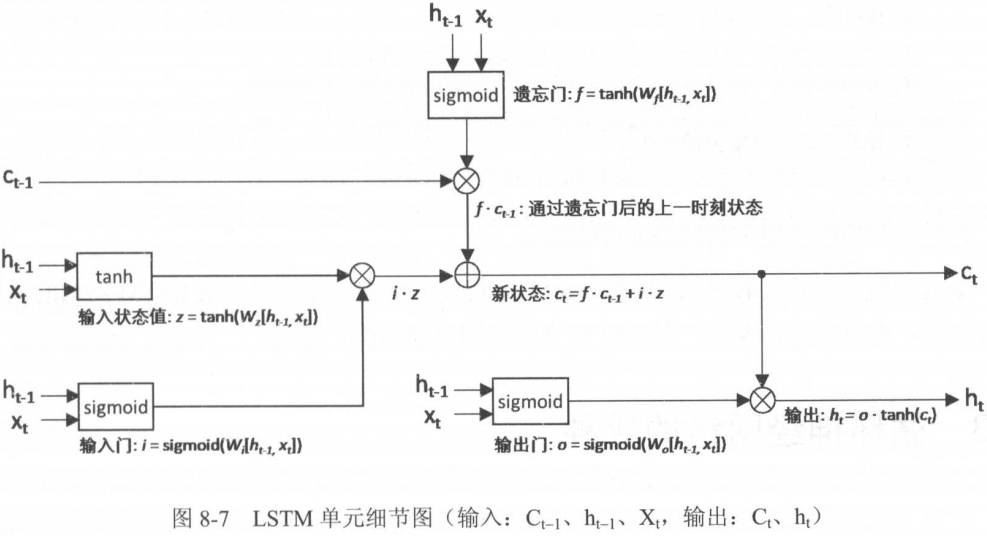
所谓的门结构,就是sigmoid神经网络。其输出位于0和1之间,对应“开关程度”。
LSTM的前向传播比较复杂,大致如下(省略偏置项):
TF对LSTM提供了非常强大的支持:
import tensorflow as tf
# 该函数自动定义所有LSTM需要的变量
lstm = tf.nn.rnn_cell.BasicLSTMCell(lstm_hidden_size)
# 将LSTM的状态全部0初始化,借助BasicLSTMCell类提供的zero_state函数
state = lstm.zero_state(batch_size, tf.float32)
# state是LSTMStateTuple类,包含两个张量:state.c和state.h,分别对应输出状态h和循环体状态c
# 训练时同样是按batch训练
# 定义损失函数
loss = 0.0
# 定义训练过程
for i in range(length): # length是序列长度。如果是变长的,需要dynamic_rnn,在第九章。
if i > 0 : # 在最开始声明变量,在之后的时刻重复使用
tf.get_variable_scope().reuse_variables()
# 迭代
lstm_output, state = lstm(current_input, state)
# 状态输出和最终输出之间还有一个全连接层
final_output = fully_connected(lstm_output)
loss += calc_loss(final_output, expected_output)
8.3 循环神经网络的变种
双向循环神经网络和深层循环神经网络
双向循环神经网络bidirectional RNN如图:

其结构无非是两层不同方向的循环体,然后输出由两个循环体状态同时决定。
Deep RNN如图:
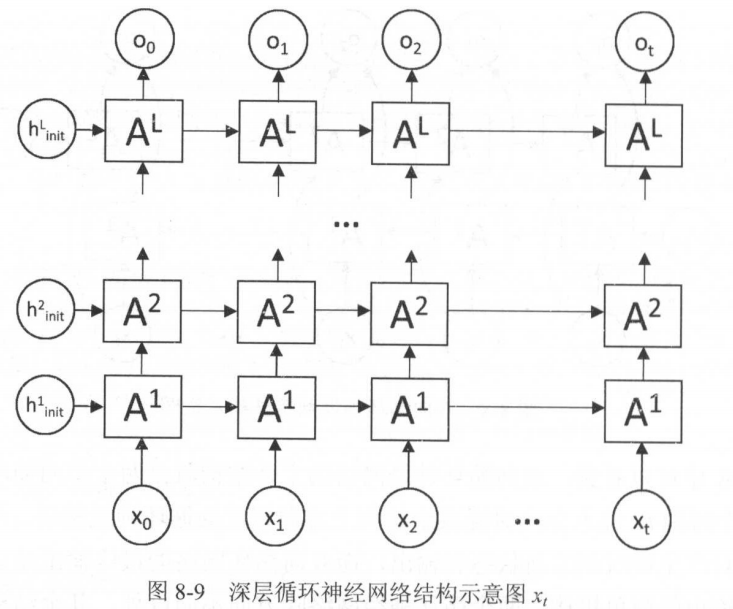
循环体从一层变成了多层,表达能力增强~
TensorFlow提供了MultiRNNCell类来实现:
import tensorflow as tf
lstm_cell = tf.nn.run_cell.BasicLSTMCell
# 定义Deep RNN的前向传播过程 只有此处不同
stacked_lstm = tf.nn.run_cell.MultiRNNCell([lstm_cell(lstm_size) for _ in range(num_of_layers)])
# 不能用lstm_cell(lstm_size)*N,否则每一层的参数也会共享
state = stacked_lstm.zero_state(batch_size, tf.floats)
for i in range(length):
if i > 0 :
tf.get_variable_scope().reuse_variables()
lstm_output, state = stacked_lstm(current_input, state)
final_output = fully_connected(lstm_output)
loss += calc_loss(final_output, expected_output)
RNN的dropout
在卷积神经网络CNN中,我们曾经使用过dropout(注意只在最后的FC层使用,随机使某些节点输出为0,抑制过拟合)。
在循环神经网络RNN中,我们也可以使用dropout,但只在不同层循环体结构之间使用,同一层内不使用!
如图,虚线就是dropout使用处:

在TensorFlow中,dropout功能由tf.nn.run_cell.DropoutWrapper类实现:
import tensorflow as tf
lstm_cell = tf.nn.run_cell.BasicLSTMCell
stacked_lstm = tf.nn.run_cell.MultiRNNCell(
[tf.nn.runn_cell.DropoutWrapper(lstm_cell(lstm_size)) for _ in range(num_of_layers)])
# dropout概率由该类的两个参数:input_keep_prob或output_keep_prob控制。
state = stacked_lstm.zero_state(batch_size, tf.floats)
for i in range(length):
if i > 0 :
tf.get_variable_scope().reuse_variables()
lstm_output, state = stacked_lstm(current_input, state)
final_output = fully_connected(lstm_output)
loss += calc_loss(final_output, expected_output)
8.4 RNN样例
目标:预测函数sinx的取值。
# -*- coding: utf-8 -*-
import numpy as np
import tensorflow as tf
from matplotlib import pyplot as plt
HIDDEN_SIZE = 30 # 一个cell内有30个隐藏单元
NUM_LAYERS = 2 # 有2层
TIMESTEPS = 10 # 输入序列长度为10
TRAINING_STEPS = 11000
BATCH_SIZE = 32
TRAINING_EXAMPLES = 10000
TESTING_EXAMPLES = 1000
SAMPLE_GAP = 0.01
# 前面都是函数,最后才是执行
def generate_data(seq):
X = []
y = []
for i in range(len(seq)-TIMESTEPS):
X.append([seq[i: i + TIMESTEPS]]) # 长度为TIMESTEPS的序列都是输入
y.append([seq[i + TIMESTEPS]]) # 一个点为待预测的真实值
return np.array(X, dtype=np.float32), np.array(y, dtype=np.float32)
def lstm_model(X, y, is_training):
# 创建2层的LSTM结构
cell = tf.nn.rnn_cell.MultiRNNCell([
tf.nn.rnn_cell.BasicLSTMCell(HIDDEN_SIZE) for _ in range(NUM_LAYERS)])
# 将2层LSTM结构组合成RNN,并定义了前向传播
outputs, _ = tf.nn.dynamic_rnn(cell, X, dtype=tf.float32)
output = outputs[:,-1,:] # 只关注最后一个时刻的输出,就可以训练了
# outputs是顶层LSTM每一步的输出,维数为[batch_size, time, HIDDEN_SIZE]
# 输出前的全连接层
predictions = tf.contrib.layers.fully_connected(output, 1, activation_fn=None)
# 参数分别是:inputs,num_outputs,activation_fn=tf.nn.relu等
# 如果是测试,现在就返回,不需要反向
if not is_training:
return predictions, None, None
loss = tf.losses.mean_squared_error(labels=y, predictions=predictions)
train_op = tf.contrib.layers.optimize_loss(loss, tf.train.get_global_step(),
optimizer='Adagrad', learning_rate=0.1)
return predictions, loss, train_op
def train(sess, train_X, train_y):
# 创建数据集
dataset = tf.data.Dataset.from_tensor_slices((train_X, train_y))
dataset = dataset.repeat().shuffle(1000).batch(BATCH_SIZE)
# (序列和真实值)组合被打乱顺序,然后再按32组合成多个batch输出 要repeat,否则会OutOfRange
iterator = dataset.make_one_shot_iterator()
# 定义数据产生方式
X,y = iterator.get_next()
# 定义loss等
with tf.variable_scope("model"):
predictions, loss, train_op = lstm_model(X, y, True)
# 初始化
sess.run(tf.global_variables_initializer())
# 正式跑,只需要输出loss,但train_op也得跑
for i in range(TRAINING_STEPS):
_, loss_value = sess.run([train_op, loss])
if i % 1000 == 0:
print("step:"+str(i)+" | loss:"+str(loss_value))
def run_eval(sess, test_X, test_y):
dataset = tf.data.Dataset.from_tensor_slices((test_X, test_y))
dataset = dataset.batch(1)
iterator = dataset.make_one_shot_iterator()
X,y = iterator.get_next()
with tf.variable_scope("model", reuse=True):
prediction, _, _ = lstm_model(X, [0.0], False)
predictions = []
labels = []
for i in range(TESTING_EXAMPLES):
pre, loss_value = sess.run([prediction, y])
predictions.append(pre)
labels.append(loss_value)
# 计算测试RMSE误差
predictions = np.array(predictions).squeeze()
labels = np.array(labels).squeeze()
rmse = np.sqrt(((predictions - labels) ** 2).mean(axis=0))
print("Root Mean Square Error: %f" % rmse)
# 画图,对比真实sin和预测值
plt.figure()
plt.plot(predictions, label='predictions')
plt.plot(labels, label='real_sin')
plt.legend()
plt.show()
# 数据采集
# 我们连续采一大段,前面用于train,后面用于test
train_end = (TRAINING_EXAMPLES + TIMESTEPS) * SAMPLE_GAP
test_end = train_end + (TESTING_EXAMPLES + TIMESTEPS) * SAMPLE_GAP
train_X, train_y = generate_data(np.sin(np.linspace(
0, train_end, TRAINING_EXAMPLES + TIMESTEPS, dtype=np.float32)))
test_X, test_y = generate_data(np.sin(np.linspace(
train_end, test_end, TESTING_EXAMPLES + TIMESTEPS, dtype=np.float32)))
# linespace生成等差数列,前3个参数分别代表:起点,终点,数列长度
# 一定要给generate_data输入(所需样本数+序列长度)个点的序列
# 正式训练和测试
with tf.Session() as sess:
train(sess, train_X, train_y)
run_eval(sess, test_X, test_y)
step:0 | loss:0.41758543
step:1000 | loss:0.0013505007
step:2000 | loss:0.00041286822
step:3000 | loss:5.7305755e-05
step:4000 | loss:2.6154925e-05
step:5000 | loss:1.1315211e-05
step:6000 | loss:7.277693e-06
step:7000 | loss:7.344668e-06
step:8000 | loss:4.446717e-06
step:9000 | loss:4.218645e-06
step:10000 | loss:4.4619073e-06
Root Mean Square Error: 0.002183

 浙公网安备 33010602011771号
浙公网安备 33010602011771号