Paper | Squeeze-and-Excitation Networks
Squeeze-and-Excitation Networks
本文的贡献点在于:通过显式建模特征注意力机制,达到了很好的效果。这是以往被默认隐式学习的操作。并且注意,此时建模出来的注意力是非线性分布的。
最重要的是,SE block非常轻巧,而且有比赛冠军的实验保证。
神经网络对你说:你让我学得简单又轻松,我就会反馈给你更好的结果哦。
1. 故事
现有的卷积操作:在局部感受野内,提取空域(spatial-wise)和通道域(channel-wise)信息。
这篇文章希望提高网络的表示能力,提出了一个称为“挤压-激活(Squeeze-and-Excitation, SE)”块,能够通过显式建模通道依赖性,重新校准通道域特征。
【我猜是一种通道注意力机制】
该SENet在2017年ILSVRC分类比赛上获得第一名。
对于深度学习优化,有两种科研方向:(1)改进推理结构;(2)改进表示结构和方法。本文是后者。
2. SENet
2.1 概况
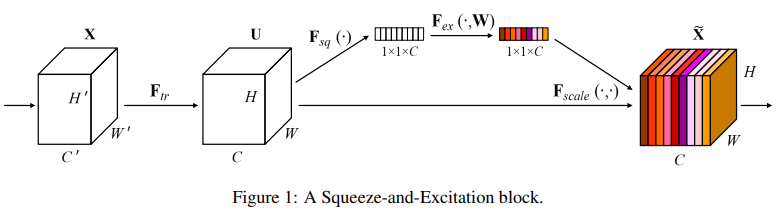
一个SE block如图。对于任意变换\(F_{tr}: X \to U\)(例如一组或多组卷积),我们都可以采用后续操作,来重新校准(recalibrate)通道:
-
首先通过一个挤压算子\(F_{sq}\),每个通道都被挤压成一个表示元素。\(C\)个通道就有\(C\)维向量。
-
通过一个激活算子\(F_{ex}\),学习每一个通道的权重。
-
最终输出是\(U\)的原通道加权放缩后的通道。权值就是上一步学习的。
整个SENet就是多个SE block的堆叠。
这种SE block可以作为插件,在任意深度嵌入(drop-int)。但作者发现,在不同层嵌入的作用也是不同的:
-
在浅层嵌入,SE block可以帮助激活有用的、与类别没有太大关系的特征,从而帮助增强共享的底层特征。
-
在深层嵌入,SE block对类别更敏感,会起到一种(与类别有关的)特征选择的作用。
因此,如果在整个网络中堆叠使用,效果更佳哦。
2.2 具体
-
挤压:在某通道上,取该通道的全局均值。简单有效。
-
激活:两层FC,中间有一次ReLU非线性激活,最后是逻辑回归。在第一次FC,\(C\)层通道减少至\(C/r\);第二次FC,通道数又恢复至\(C\)。这相当于一个bottleneck,目的是为了降低复杂度。\(r\)的选取见第四节,取16。
最终,我们将SE block嵌入Inception和ResNet试试:
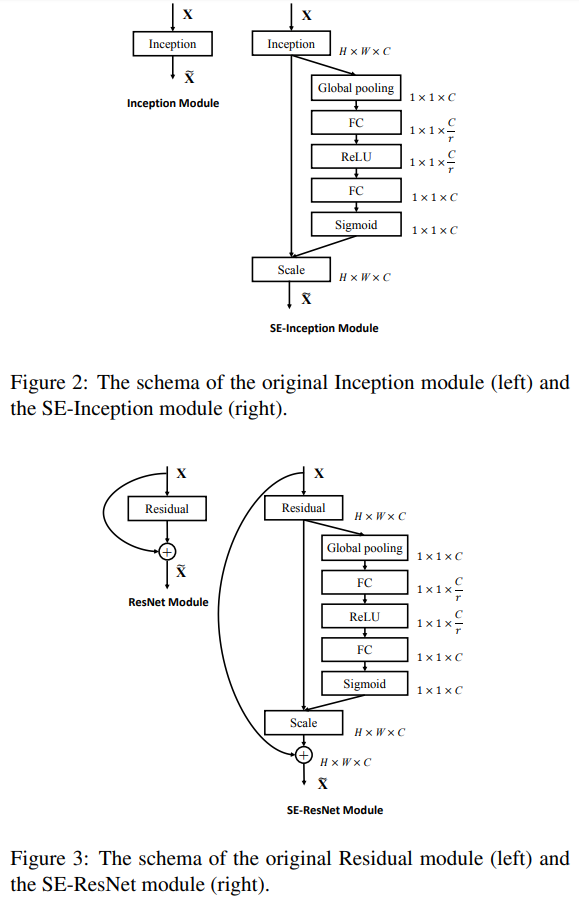
在选择激活方法时,我们不希望让输出变成one-hot向量,即不希望通道权重是互斥的。
3. 实验
作者不仅考察了装载SE block前后的精度,还考察了前后计算效率,如表:
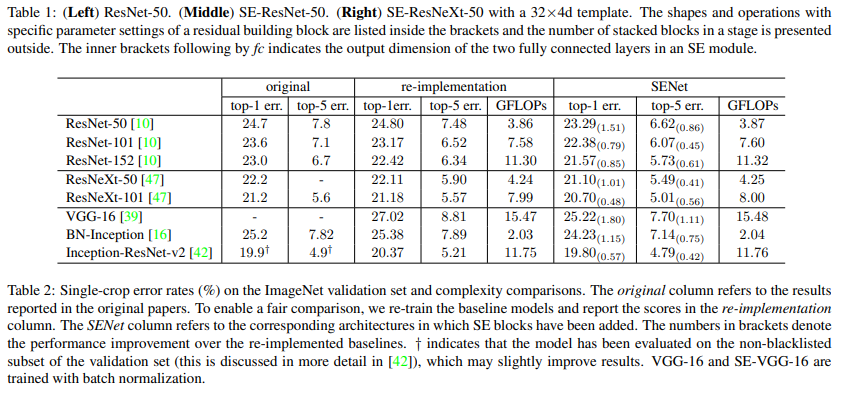
可见,在err下降的同时,GFLOPs上升微乎其微。
不仅如此,SE block还能让MobileNet和ShuffleNet显著改善:

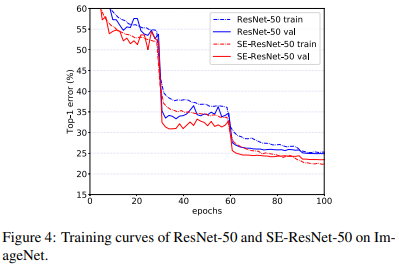
收敛过程也更快:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号