Paper | Deep Residual Learning for Image Recognition
Deep Residual Learning for Image Recognition
ResNet的意义已经不需要我在这里赘述。该文发表在2016 CVPR,至今(2019.10)已有3万+引用。由于ResNet已经成为大多数论文的baseline,因此我们着重看其训练细节、测试细节以及bottleneck等思想。
核心:
We explicitly reformulate the layers as learning residual functions with reference to the layer inputs, instead of learning unreferenced functions.
性能:在ImageNet数据集上,我们的残差网络是152层——比VGG深8层,但复杂度却更低。
比赛:赢得了ILSVRC 2015的冠军,囊括分类、定位、检测和分割。
1. 故事
最近的文献表明:深度是很重要的。
但是:
Is learning better networks as easy as stacking more layers?
即:我们为了得到更好的网络,不应只是简单地堆砌层。原因是深度网络存在梯度消失/爆炸的问题。
前人怎么做?正则初始化 和 中间层特征正则化。
还有一个问题:随着深度增加,网络的性能会逐渐饱和,然后恶化。这不是因为过拟合,因为作者在实验中发现训练误差也很高:
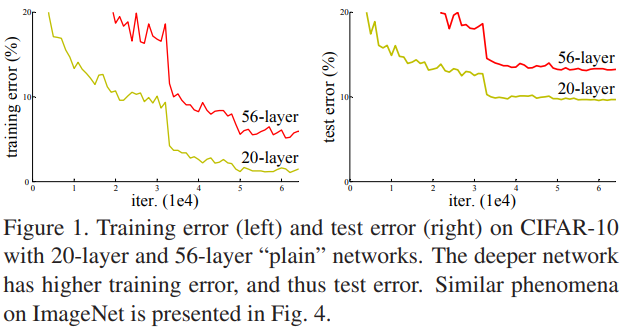
作者诞生了一个很惊人的深层网络构造方式【当然也有可能是事后解释,但是也很insightful】:我们在浅层网络的基础上,加入多层恒等映射(identify mapping)。此时网络就变成了深度网络,并且该深度网络的性能至少不低于浅层网络。然而,我们却没有一种方法能够实现这种构造方式。
进一步,作者就提出了实现这种设想的方式:残差学习block和网络。由于学习的是残差,因此更趋近于学习恒等映射,网络学习起来会更轻松。
实际上,残差学习在传统方法中是存在的,但用于CNN学习还是第一次。
2. 残差学习网络
2.1 残差块
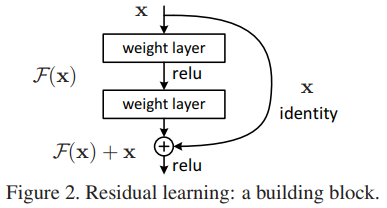
作者的想法在网络实现上非常简单,如图。短连接没有增加任何参数,并且可以BP。
同期的还有highway networks,加入了门限来控制短连接。然而门限是有参数的。并且,当门限值接近0时,短连接相当于是断开的。因此,highway network并没有在当网络深度超过100层时,展现出性能加分。
在实际操作中,作者设置了多个block,在每个block内加入头尾短连接。比如在上图中,一个block内就有两层。注意,第二个ReLU非线性化是在求和以后,如上图。
如果输入和输出的维度不匹配,我们只好对输入作一个线性变换,再求和。
2.2 ResNet
如图是ResNet-34和对比网络:
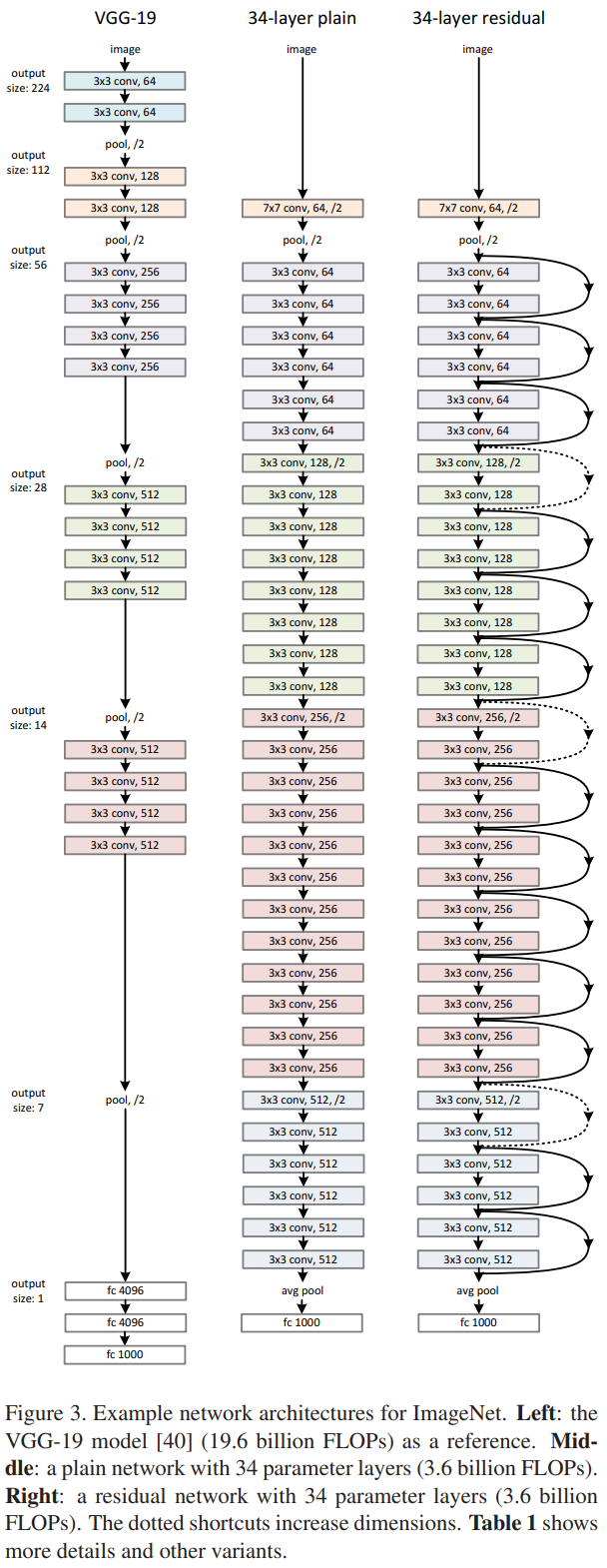
值得一提的是:
-
VGG-19有19.6b的FLOPs,而ResNet-34只有3.6b。
-
其中的降采样是通过步长为2的卷积实现的。
-
图中虚线连接的头、尾特征图的尺寸就不一样。为了完成短连接,作者考虑了两种方案:(1)多余的补零;(2)短连接时要经过一个projection,即线性变换。
2.3 细节
-
在每一次卷积后、非线性激活前,我们采用BN。
-
优化方法为SGD,mini-batch容量为256。学习率从0.1开始。当误差停滞不下降时,我们将学习率除以10。
-
SGD的weight decay是0.0001,momentum是0.9。
-
不采用dropout。【因为数据集够大,很难过拟合】
-
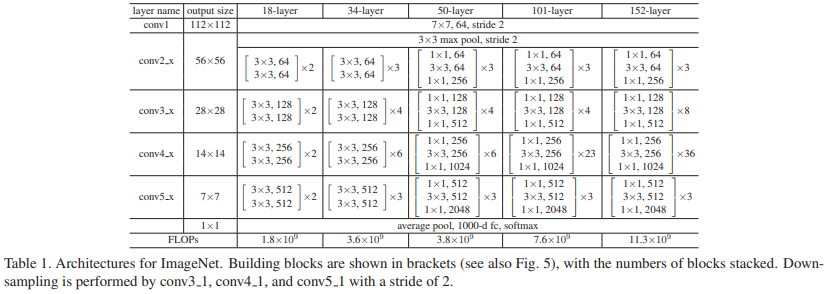
其他变种的配置和FLOPs:
3. 实验
3.1 短连接网络与plain网络
如图,对于plain网络,加深没有带来收益,反而有害;但对ResNet,加深作用明显:

plain network的结果是因为梯度问题吗?作者认为不是,因为plain network也配置了BN。并且作者也确认了梯度没有问题。
原因未知,作者猜测可能是收敛速率的问题。并且速率是指数型慢,无法通过简单的学习率加倍 或 延长训练时间 得到解决。
3.2 Projection解决短连接维度不匹配问题
作者比较了三种方案:(A)补零,这样就不增加参数;(B)维度不匹配的Projection;(C)全部都改成Projection。结果如表:
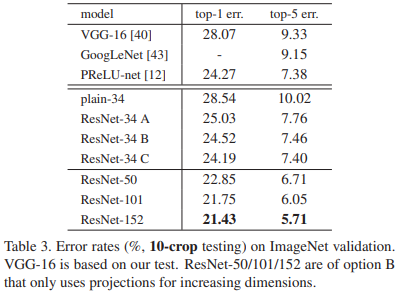
这说明:无论是哪种方法,效果都比plain更好。其中C方案是最好的,但是它引入了最多的参数。作者认为,ABC差距不大,引入参数没有必要。
3.3 更深的bottleneck结构
我们为了增加效率,引入了bottleneck结构。但作者指出,这种结构可能会导致和plain一样的恶化问题。
对于每个block,原本我们只用2层卷积,现在我们用3层:\(1 \times 1 \to 3 \times 3 \to 1 \times 1\),如图:
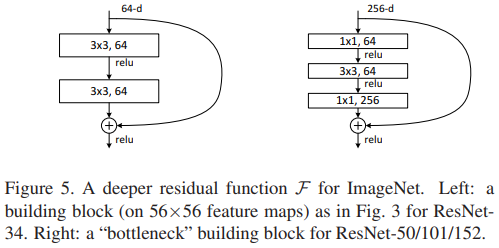
前后的\(1 \times 1\)卷积,是为了先降低通道数,最后再恢复通道数,使得中间卷积操作在较低通道数上运行,节省参数量。
我们回去观察表1,其中的34层以上的ResNet都含有大量的bottleneck结构。在表3和表4中同样观察了它们的表现,没有发现恶化问题。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号