Paper | Non-Local ConvLSTM for Video Compression Artifact Reduction
Non-Local ConvLSTM for Video Compression Artifact Reduction
【这是MFQE 2.0的第一篇引用,也是博主学术生涯的第一篇引用。最重要的是,这篇文章确实抓住了MFQE方法的不足之处,而不是像其他文章,随意改改网络罢了。】
在MFQE的基础上,作者提出了一个问题:“好”帧里的块的质量就好吗?“差”帧里的块的质量就差吗?显然不一定,因为帧的好/坏是由整张图像的综合质量决定的(如PSNR)。
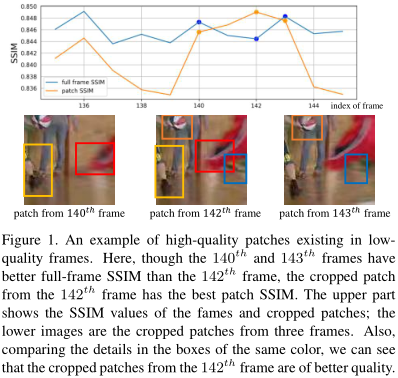
为了解决这个问题,作者提出用non-local结合ConvLSTM的思路。众所周知,NL是很耗时的,因此作者提出了一种近似计算帧间相似性的方法,从而加速NL过程。由于使用了ConvLSTM,因此本方法不再需要精确的MC。
1. 方法
1.1 框图
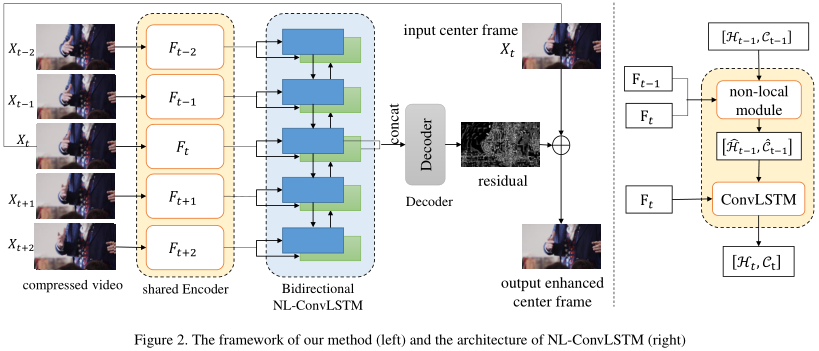
图画得很清楚。这是一个典型的Conv-LSTM,会连续输入多帧的卷积特征。在输出端,当前帧对应的双向隐藏层特征被拼接,进一步处理,最后作为残差与输入相加,即得到输出。
关键在于Conv-LSTM细胞的改进。由于去掉了MC组分,因此如果存在较大的运动位移,LSTM对运动的建模很可能失败。为此,作者引入了NL机制来建模运动位移。但是注意,这里的NL用来捕捉特征图间像素的相似性,而不是特征图内像素的相似性。因此,上一特征图\(F_t\)也要输入NL模块,但不输入Conv-LSTM细胞!
1.2 NL流程
我们具体讲一下改进后Conv-LSTM的工作流程。以下都以单向举例。
首先,ConvLSTM的经典输入输出格式是:输入当前特征图\(F_t\)、上一时刻隐藏层状态\(H_{t-1}\)和上一时刻细胞状态\(C_{t-1}\),输出当前时刻的隐藏层状态\(H_{t}\)和细胞状态\(C_{t}\):
为了让LSTM更好地建模运动位移,尤其是大尺度运动,作者在Conv-LSTM前引入NL技术,但是是特征图间的NL:
\(S_t\)代表像素相似性,计算公式为:
其中,\(S_t(i,j)\)说的是 \(t-1\)特征图的第\(i\)个元素 与 当前\(t\)特征图的第\(j\)个元素 的相似度。显然要求关于\(i\)求和为1,因此用分母归一化。
NL的第二步,就是基于计算出的相似度,执行扭曲:
具体操作很简单:
【论文中的公式(4)有误,时刻写错了?】
1.3 加速版NL
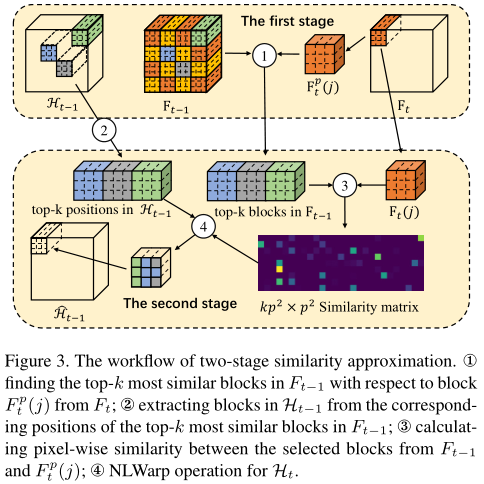
如果严格按照以上步骤算,运动复杂度会很高。为此,作者引入了两步NL方法来近似 欧几里得距离\(D_t\) 和 特征图间像素相似度\(S_t\)。
-
首先,对输入的特征图\(F_{t-1}\)和\(F_t\),我们作\(p \times p\)的平均池化,得到\(F^p_{t-1}\)和\(F_t^p\)。实验取\(p = 10\)。
-
然后我们再算它们的欧几里得距离矩阵\(D_t^p\)。此时,我们就能得到最相关的k个点。实验取\(k = 4\)。
-
这k个点对应原\(F_{t-1}\)的\(k \times p^2\)个点。后续操作就和上面一致了。
换句话说,这里有两点加速:(1)并不考虑所有点的相互关系,而只考虑前k个(其他的S为0);(2)先池化,在低维度上计算相似度。一个点代表一个块。
2. 实验
-
表2的前两列说明:输入多帧比输入单帧效果更好。作者还尝试了输入前后共20帧,结果比表2第4列还好。
-
作者尝试将NL换成了MC,结果不如NL,在dpsnr上差了20%。
-
NL找到的相似块也比较准。参见论文图4,红框是黄框的检测相似框。
-
Conv-LSTM耗时很猛,比对比算法高出好几倍,是MFQE 1.0的6-7倍。原因是要处理相邻多帧。但作者的加速已经很有效了,比原始NL加速了4倍。
3. 总结
本文对Fig1中阐释的问题进行了一定程度的处理。原因是:1、光流很难顾及全局关系,但相关度矩阵很擅长处理远距离关系。这就类似于GNN相比于传统CNN的优势。2、输入更多的相邻帧。
因此,本文的核心贡献是:在用Conv-LSTM建模时序和空域关系的同时,加入NL辅助完成了类似MC的功能。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号