Paper | MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications
MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications
本文提出了一种轻量级结构MobileNets。其基础是深度可分离卷积操作。
MobileNet具有两个超参数,可以调节精度(accuracy)和延迟(latency)之间的权衡。
1. 故事
现有的模型越来越深,越来越复杂,效率却有可能越来越低。这在实际应用中是无法接受的。
本文于是推出了一种网络,包含两个超参数,可以根据需求适配。
历史工作大多考虑让网络更小,即关注size而非latency。本文提出的网络同时关注这两点。
2. MobileNet
2.1 深度可分离卷积
深度可分离卷积 将 标准卷积操作 分解为 深度卷积 和 \(1 \times 1\)逐点卷积。
在 MobileNet中,深度卷积是对每一个通道分别卷积,逐点卷积就是对 深度卷积的输出通道 进行\(1 \times 1\)整合。【前者是空域的,后者是通道域的,二者完全解耦】
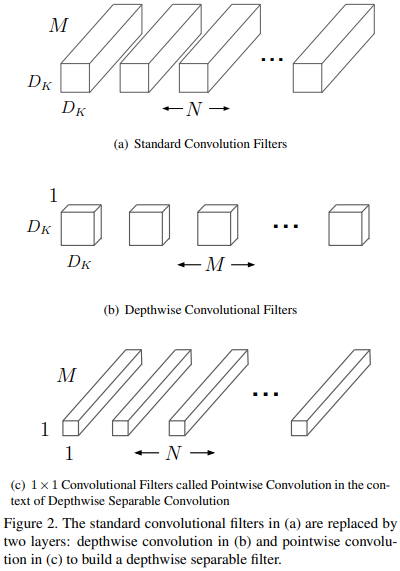
如图,先对\(M\)个输入通道分别空域卷积,得到\(M\)张特征图;然后再整合这些特征图,一共有\(N\)种整合方式,即得到\(N\)张特征图。
具体而言,深度卷积采用的是\(3 \times 3\)卷积核。
2.2 网络结构
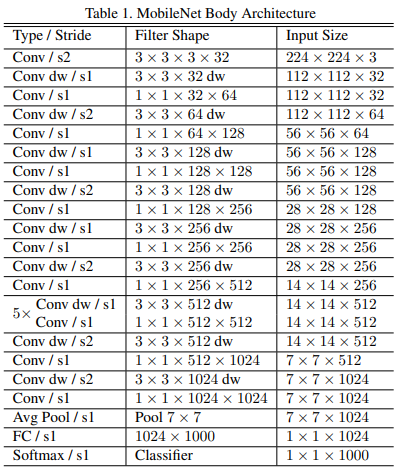
网络整体结构如表:
-
每一个卷积层都跟着一个BN和ReLU激活,除了最后一层。表中的dw就是深度卷积,如图:

-
其中的降采样是通过步长卷积实现的(正常卷积默认步长为1)。
-
最后是全局池化(每个通道的尺寸直接变为\(1 \times 1\)) => FC层。
-
一共有28层卷积。
-
【规律:通道尺寸不断下降;深度可分离卷积几乎是和正常卷积交替使用的;升通道数都用\(1 \times 1\)卷积完成;在低分辨率通道上卷积层数较多】
最后,我们不应该只关注乘法-加法的数量。我们还应该关注这些操作能否被有效实施。其中,\(1 \times 1\)卷积就是非常高效的矩阵乘法算子,并且对显存要求很低。这归功于GEMM函数。我们统计一下:
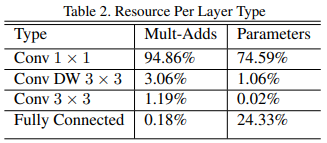
\(1 \times 1\)卷积的运算量和参数规模都是最大头的,这对网络有好处。
最后作者发现,由于深度可分离卷积的参数量不大,因此不应该使用weight decay。
2.3 引入两个超参数
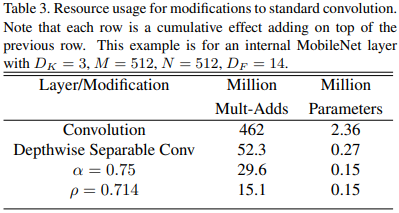
首先引入的是通道数瘦身超参数(width multiplier)。在乘以该超参数后,输入和输出通道数都会变成原来的\(\alpha\)倍。典型值为0.75和0.5。
其次引入分辨率瘦身超参数(resolution multiplier)。不用过多解释了。
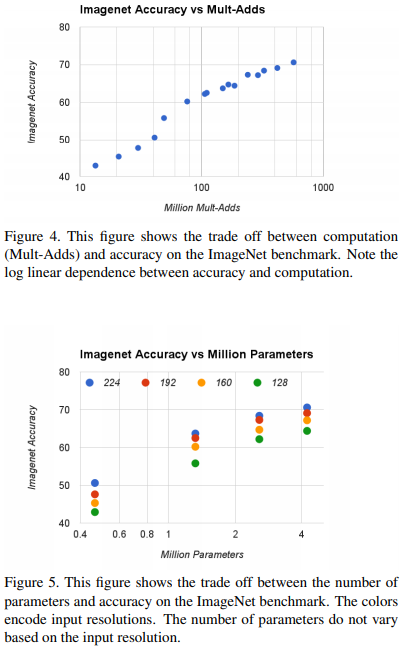
我们看看效果:
3. 实验
我们就看在ImageNet上的例子。效果不重要,关键是灵活的权衡方式。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号