Paper | Multi-scale Dense Networks for Resource Efficient Image Classification
Multi-scale Dense Networks for Resource Efficient Image Classification
发表在ICLR 2018,Oral。
摘要:
In this paper we investigate image classification with computational resource limits at test time. Two such settings are: 1. anytime classification, where the network’s prediction for a test example is progressively updated, facilitating the output of a prediction at any time; and 2. budgeted batch classification, where a fixed amount of computation is available to classify a set of examples that can be spent unevenly across “easier” and “harder” inputs. In contrast to most prior work, such as the popular Viola and Jones algorithm, our approach is based on convolutional neural networks. We train multiple classifiers with varying resource demands, which we adaptively apply during test time. To maximally re-use computation between the classifiers, we incorporate them as early-exits into a single deep convolutional neural network and inter-connect them with dense connectivity. To facilitate high quality classification early on, we use a two-dimensional multi-scale network architecture that maintains coarse and fine level features all-throughout the network. Experiments on three image-classification tasks demonstrate that our framework substantially improves the existing state-of-the-art in both settings.
结论:
We presented the MSDNet, a novel convolutional network architecture, optimized to incorporate CPU budgets at test-time. Our design is based on two high-level design principles, to generate and maintain coarse level features throughout the network and to inter-connect the layers with dense connectivity. The former allows us to introduce intermediate classifiers even at early layers and the latter ensures that these classifiers do not interfere with each other. The final design is a two dimensional array of horizontal and vertical layers, which decouples depth and feature coarseness. Whereas in traditional convolutional networks features only become coarser with increasing depth, the MSDNet generates features of all resolutions from the first layer on and maintains them throughout. The result is an architecture with an unprecedented range of efficiency. A single network can outperform all competitive baselines on an impressive range of computational budgets ranging from highly limited CPU constraints to almost unconstrained settings.
As future work we plan to investigate the use of resource-aware deep architectures beyond object classification, e.g. image segmentation (Long et al., 2015). Further, we intend to explore approaches that combine MSDNets with model compression (Chen et al., 2015; Han et al., 2015), spatially adaptive computation (Figurnov et al., 2016) and more efficient convolution operations (Chollet, 2016; Howard et al., 2017) to further improve computational efficiency.
亮点:
-
第一个提出具有early-exit机制的动态(自适应)图像分类CNN。
-
该网络可以大幅度节省运算时间,同时保证分类精度。
Note:本文的arXiv版本名字不同,并且写得很烂……看来response是很有意义的啊。
故事背景
CNN大法好,但是在很多实时场景下推理速度无法满足要求,例如自动驾驶。并且复杂推理还会导致能源消耗,例如在移动终端耗电。
作者认为,我们可以对简单样本简化推导,对复杂样本加强推导,从而达到综合省时的目的。如图:

左边的马识别显然要简单,右边就要难得多。
作者提出了一个问题:凭什么网络就得是静态的?对于简单样本,我们不得不浪费时间和能量;对于复杂样本,我们又有可能推导不足。我们希望解决静态网络的这一问题。
方法
两种加速策略
作者提出了两种推导策略,来解决这一问题。
- 限制网络对每一个样本的推导时间,作者称为anytime prediction模式。
在此模式下,时间上限是超参数。通常我们根据实际应用需求,决定该参数取值。例如,每一款手机的性能不同,因此我们应该对不同手机设置不同的帧速率要求,而不应该作统一要求。 - 限制网路对一批样本的推导总时间,作者称为budgeted batch classification模式。在这种模式下,网络对简单和困难样本的推导时间可以不同(并且最好不同),从而达到总体准确率与总体运算耗时的权衡。此时有两个超参数:batch总运算时间上限和推导结束阈值,怎么定?看下一节。
网络设计
进一步,作者提出了对网络的要求:要么在规定时间内结束推导,要么达到了一定的置信度(confidence)从而结束推导。以上机制统称为early-exit机制。
对于传统的静态网络中,有两个问题需要解决:
-
传统网络中,分类器加在网络最末端。如果希望提前结束,那么分类器和对应特征该如何联系?
-
前端特征比较精细(fine, low-level features),而末端特征比较粗糙(coarse, high-level features)。我们不希望提前结束时,特征全都是精细的;我们也希望有粗糙的特征出现在前端网络。
为此,作者设计了如下网络:
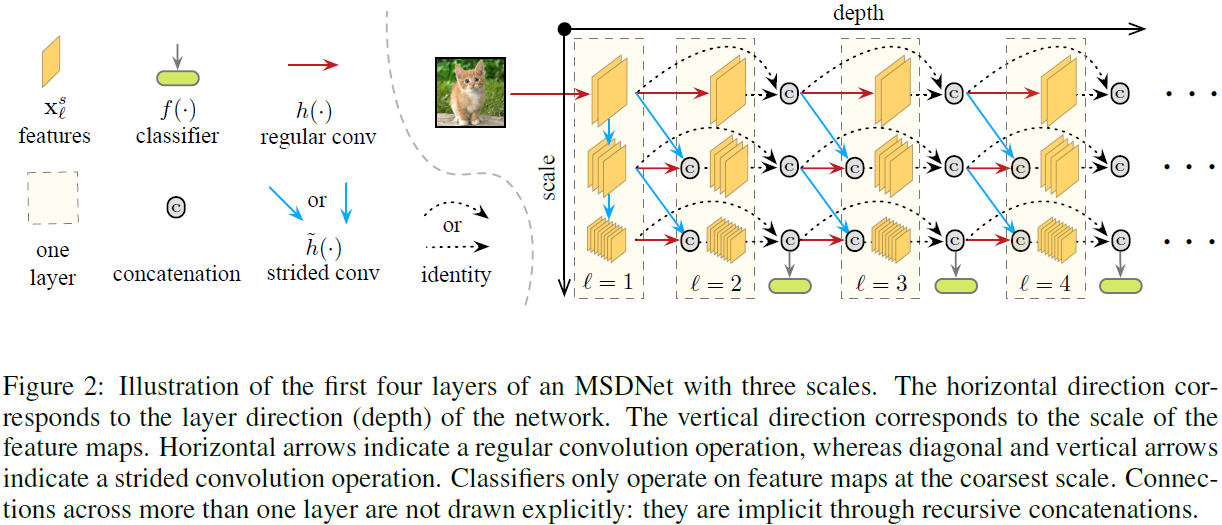
-
从第二层开始,每一层都有一个分类器。这些分类器与大量特征图稠密连接。
-
对于每一层的分类器,其输入特征都是粗糙的,是精细特征经过多层卷积得到的。
具体而言,第一层采用了跨步卷积(步长为2)的方式,产生了3个scale的通道。跨步or正常卷积、稠密连接(拼接)方式如图:
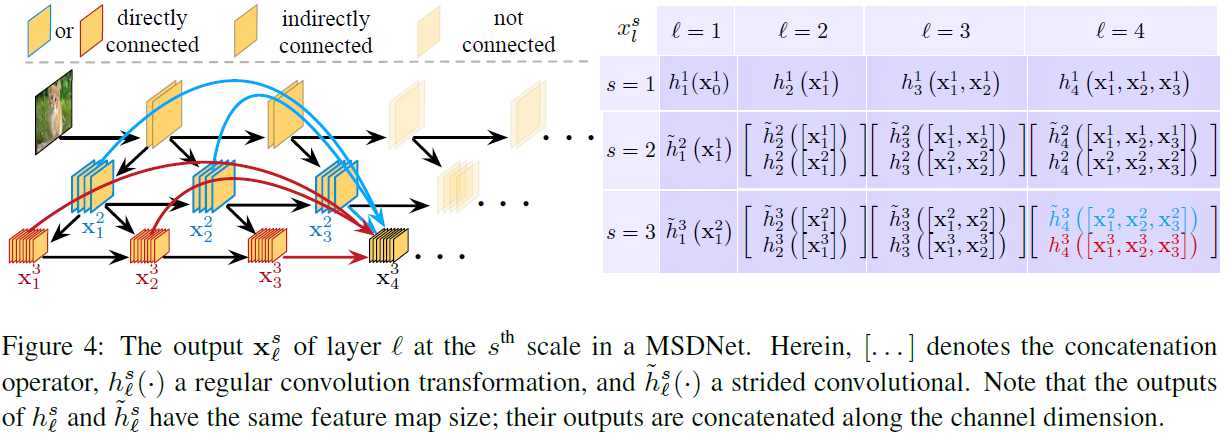
其中,\(x_l^s\)说的是第\(l\)层第\(s\)级scale的输出,\(\tilde{h}\)是跨步卷积。
对于第\(l\)层的分类器,它会使用前面所有层在最后一个scale(最coarse)的特征图。每个分类器有两层卷积、一层平均池化以及一个线性层。
-
在anytime模式下,到时即停(until the computational budget is exhausted),输出能达到的最高层的分类器的结果(most recent prediction)。时间根据实际需求定。
-
在batch budget模式下,我们同样要给出时间上限,此时是对整个batch的时间。但我们还需要设计exit阈值:只要某个分类器的置信度(本文采用分类器的概率)超过这一阈值,推导就结束。
那么如何设计阈值呢?
-
我们可以预知一个样本在不同层结束推导时,所消耗的运算资源:\(C_k\),表示在第\(k\)层退出时,所消耗的运算资源。
-
我们计算一下在第\(k\)层结束推导的概率:假设在每一层都有概率\(p\)的可能结束(假设每一层都一样),那么在第\(k\)层结束推导的概率就是\(q_k = (1-q)^{k-1}q\)。注意,我们要保证所有层的退出概率和为1,因此要乘一个常数进行归一化,这里先省略。
-
此时,总体运算耗时就是\(|num_{test}| \sum_k q_k C_k \le B\),\(B\)是预先设定的总耗时上限。该式只有未知数\(q\),因此就可以求出可行的\(q\)。该\(q\)是下一步的理论参考。
-
我们根据验证集,调整每一层的阈值\(\theta_k\)。如果\(\theta_k\)较低,那么真实的\(q\)就会较高。我们根据上一步的理论\(q\)动态调整。
训练时,损失是在所有分类器上的损失的加权平均。实际操作时为算术平均。
网络优化
我们可以感觉到,MSDNet还是有一点冗余的。原因在于:
-
传统的DNN是逐层抽象的,而精细尺度只存在于低层。
-
有一些精细尺度是冗余的,不影响下一层分类器的判决。
为此,我们采取了一种逐层剔除精细尺度的block-wise网络:
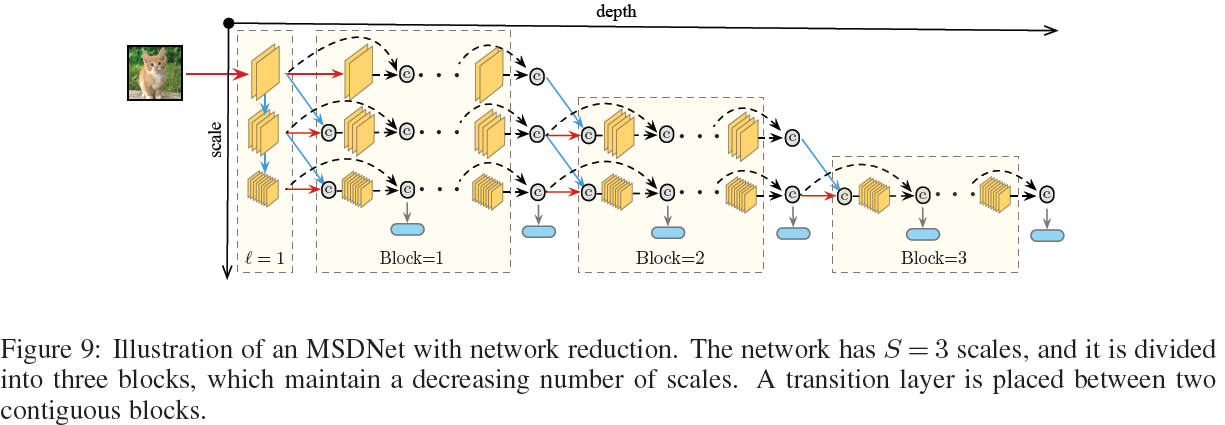
此时要在block之间加入传输层,采用\(1 \times 1\)的卷积核。
失败设计
设计1:如果我们想让简单的样本简单处理,复杂的样本复杂处理,最简单的思路是:
设计很多个网络,从简到难。如果简单网络置信度较低,那么再执行复杂网络。
在策略一下,多个网络同时工作,到时间后看看谁的置信度高,就输出谁(时间是红线)。
在策略二下,只要有一个网络的置信度足够高,我们就结束预测(置信度需要调整,最终目标是平均耗时)。
缺点:复杂样本会被多个网络预测,计算消耗很大。
设计2:我们可以采用级联(cascade)网络,让早期分类器的输入特征,重复用于后续分类器。
缺点:分类器接在fine特征上,效果不好。并且,早期分类器和后期分类器之间存在干扰。
作者这里采用实验方式说明。
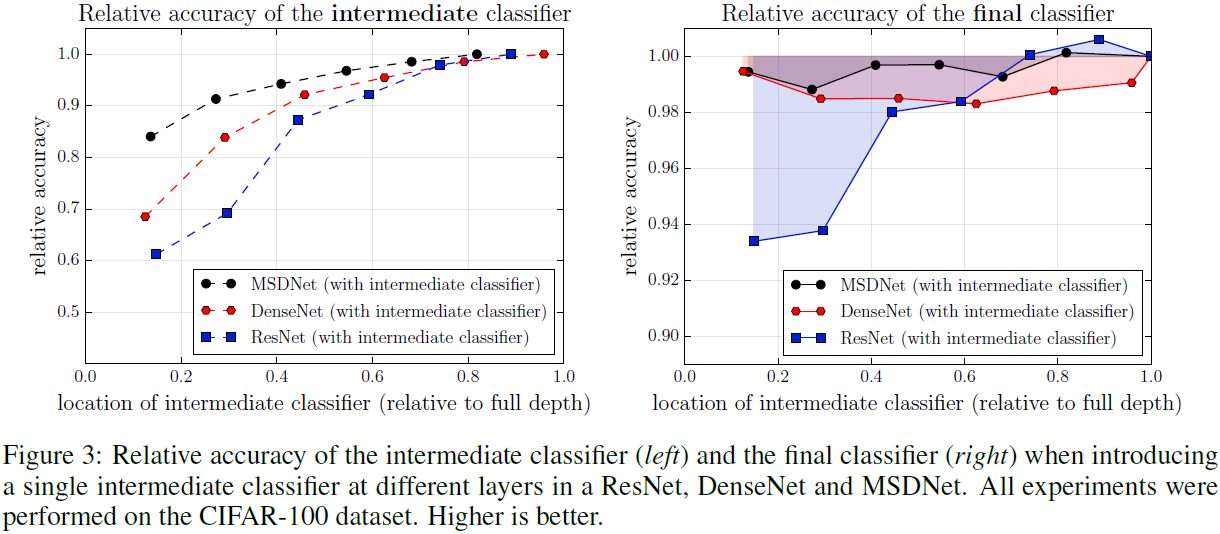
作者在ResNet和DenseNet上的六个均匀分布的地点,加入了分类器。
左图:随着分类器位置的降低,其相对(最终分类器的)准确率越来越低;很简单,因为特征抽象程度不足。
右图:随着分类器位置的降低,最终分类器的准确率也会受到影响,绝大时候会变差。
说白了,失败的原因就是:在中间层甚至更低层引入分类器,会导致低层网络被迫学习用于分类器的较抽象特征,非线性化过程被提前打乱,导致非线性不足。而稠密连接策略,以及在每一层引入更多的滤波器,可以缓解这种干扰性。
回头品味
其实网络设计的思路很简单:在以往,我们会学习一个简单的映射,借助一个较深的CNN网络。现在,我们想在中间输出简单样本的分类结果。由于浅层特征太精细,如果我们直接在浅层特征图上加分类器,会导致分类效果很差而且会影响网络的拟合,因此我们就需要对浅层特征进行一定深度的处理。
因此,整体网络就具有了两个维度的深度。为了加强特征的共享,作者进一步采用了稠密连接。
实验
数据集和数据处理
实验在三种数据集上进行:CIFAR-10,CIFAR-100和ILSVRC 2012。
作者从两个CIFAR数据库中拿出了5000张作为验证集,并进行以下图像拓充:在每个边填4个零;随机裁剪产生\(32 \times 32\)的图像;按概率0.5水平翻转;按通道减均值并除以标准差。
作者还从ImageNet(ILSVRC 2012)数据库中拿出50000张作为验证集,用来决策分类器阈值。在测试时,这些图像从中间裁剪成\(224 \times 224\),然后被放缩至\(256 \times 256\)。
结果
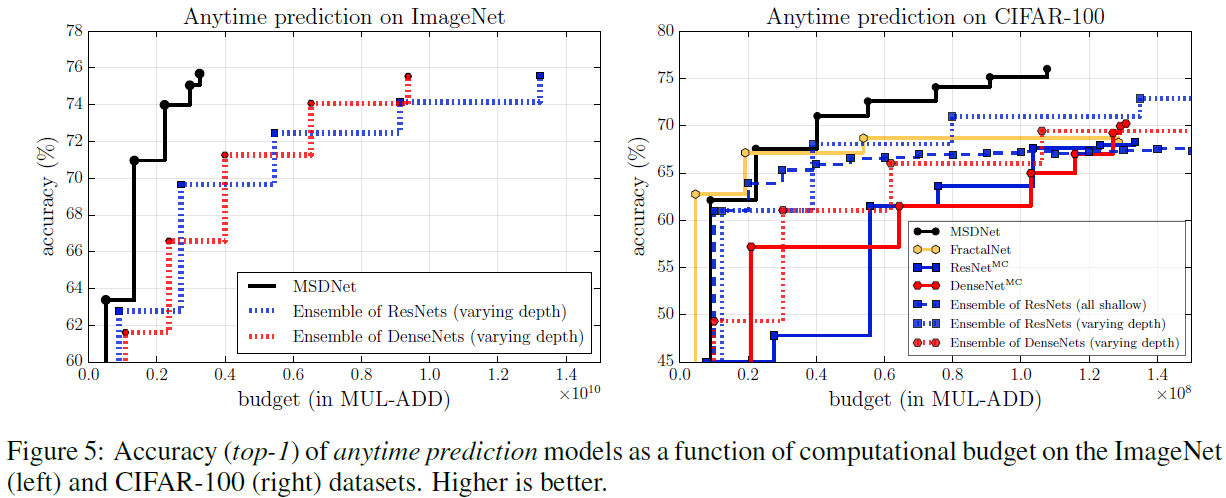
在anytime模式下,在相同计算资源条件下,MSDNet都能胜出。
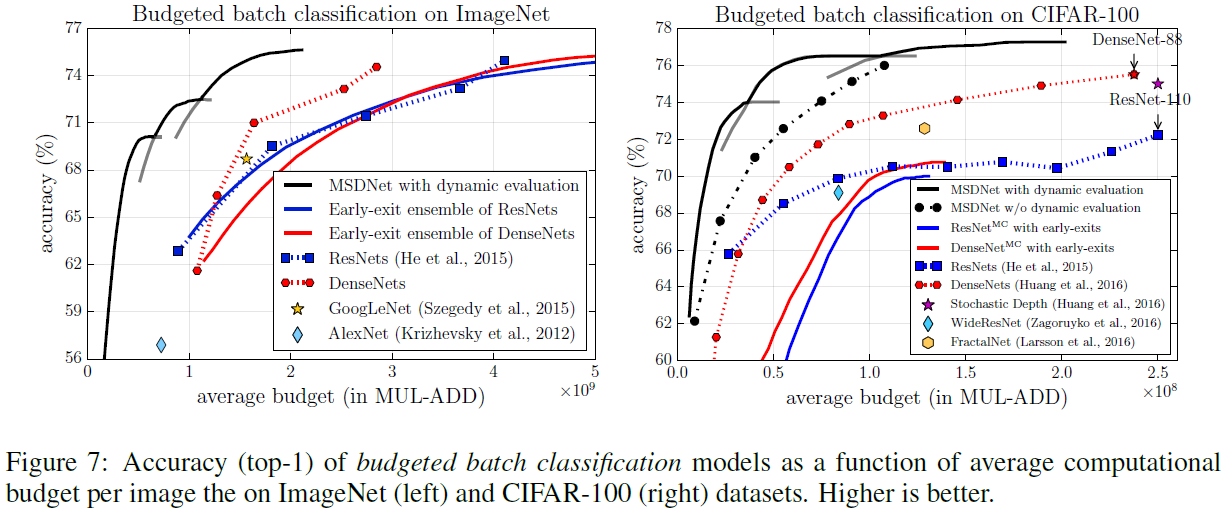
在batch budget条件下,作者尝试了三种深度的MSDNet,因此有三条曲线。
作者还可视化展示了:什么是网络觉得简单的样本,什么是网络觉得困难的样本。如图:

第二次阅读
本文不是第一个提出early exit思想的
-
本文的思想在传统方法中已经有所体现:Viola and Jones算法是用于人脸检测的著名方法,其将多个弱分类器级联,实现递进判决、提前退出。本质是一颗退化决策树。
-
而采用early-exit策略作预测、检测的机器学习方法也有很多很多,例如2016年Zamir等人采用循环预测方法。但MSDNet由于设计更出色,因此性能更好。
写作流畅
最近几年对识别任务的需求很大,如无人车和图片搜索 =>
这种需求的增长,一部分是由于看到了CNN在多个数据集上的突出表现,如COCO =>
但在这些数据集比赛中,网络规模往往都很大,消耗资源并且耗时,对实际应用是不友好的 =>
如图示,我们发现有一些简单样本不需要如此复杂的网络。这就是本文的简化思路 =>
对于资源稀缺的应用场景,有两种策略是很有利的:(1)anytime prediction,例如不同性能的安卓手机;(2)budgeted batch classification,例如图像搜索引擎。因此我们的算法将在这两种策略下进行训练和测试。
网络回顾
-
降采样是通过跨步卷积实现的。
-
第l层的分类器会拼接从第1到第l层所有最小scale的特征,然后执行两次卷积。
-
在batch budget模式下,early exit阈值\(\theta_k\)是在验证集上估算得到的!估算方法是:假设在某种设定阈值下(每一个层都有各自的阈值),某样本在各分类器exit的概率是一样的,设为q;根据总预算,算出每一层最多能输出的样本数;然后根据验证集上的实验,设置每一个分类器的exit阈值。
-
其他设置见附录。
其他
-
作者对DenseNet分析发现,原来的DenseNet的growth rate是固定的,在batch budget模式下效果不是最好。如果让growth rate在每一次过渡后都翻倍,那么效果更好。因为,这样会使得低分辨率通道有更多的滤波器,而不必要把计算量浪费在高分辨率通道上。
-
感悟:一篇论文,哪怕质量略差,也一定有其优点可以借鉴。特别是对于好的论文,过一段时间一定要不厌其烦地第二次阅读,肯定有所收获,无论是读方法、读故事、还是读写作。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号