Paper | FFDNet: Toward a Fast and Flexible Solution for CNN based Image Denoising
FFDNet: Toward a Fast and Flexible Solution for CNN based Image Denoising
发表在2018 TIP。
摘要:
Due to the fast inference and good performance, discriminative learning methods have been widely studied in image denoising. However, these methods mostly learn a specific model for each noise level, and require multiple models for denoising images with different noise levels. They also lack flexibility to deal with spatially variant noise, limiting their applications in practical denoising. To address these issues, we present a fast and flexible denoising convolutional neural network, namely FFDNet, with a tunable noise level map as the input. The proposed FFDNet works on downsampled subimages, achieving a good trade-off between inference speed and denoising performance. In contrast to the existing discriminative denoisers, FFDNet enjoys several desirable properties, including (i) the ability to handle a wide range of noise levels (i.e., [0, 75]) effectively with a single network, (ii) the ability to remove spatially variant noise by specifying a non-uniform noise level map, and (iii) faster speed than benchmark BM3D even on CPU without sacrificing denoising performance. Extensive experiments on synthetic and real noisy images are conducted to evaluate FFDNet in comparison with state-of-the-art denoisers. The results show that FFDNet is effective and efficient, making it highly attractive for practical denoising applications.
结论:
In this paper, we proposed a new CNN model, namely FFDNet, for fast, effective and flexible discriminative denoising. To achieve this goal, several techniques were utilized in network design and training, such as the use of noise level map as input and denoising in downsampled sub-images space. The results on synthetic images with AWGN demonstrated that FFDNet can not only produce state-of-the-art results when input noise level matches ground-truth noise level, but also have the ability to robustly control the trade-off between noise reduction and detail preservation. The results on images with spatially variant AWGN validated the flexibility of FFDNet for handing inhomogeneous noise. The results on real noisy images further demonstrated that FFDNet can deliver perceptually appealing denoising results. Finally, the running time comparisons showed the faster speed of FFDNet over other competing methods such as BM3D. Considering its flexibility, efficiency and effectiveness, FFDNet provides a practical solution to CNN denoising applications.
要点:
- 将噪声方差图作为CNN的输入,可以让网络更健壮,适应不同程度的噪声输入。
- 在降采样的子图像上操作,计算量更低。
亮点:
-
作者提供了一个insight:可以尝试将噪声参数和其他网络参数剥离开(独立),使得单一网络可以用于多种噪声尺度。
-
具体来说,作者将噪声标准差图作为额外的输入,输入去噪网络。并且作者通过正交初始化,尝试减小滤波器之间的相关性。
-
套用了SPMC中的思想:处理降采样的子图像而不是原始尺寸的图像,节省计算,并且提升了感受野面积。
局限:
-
根本无法做到盲去噪!居然是肉眼观察,选择最佳!本质问题:在实际应用时,你根本不知道噪声程度是多少(甚至可能不是高斯噪声),因此只能猜测和组合处理。
The non-blind FFDNet model can be viewed as multiple denoisers, each of which is anchored with a noise level. Accordingly, it has the ability to control the trade-off between noise removal and detail preservation which in turn facilitates the removal of real noise to some extent
作者辩解:由于实际噪声模型不是AWGN,因此与其采用不精确的噪声水平预测器,不如直接采用一系列(不同噪声水平的)FFDNet,得到一系列结果,取最好的结果。在实验部分他们才说清楚(这一点非常可恶,在摘要把盲去噪诱惑人,实验里却说盲去噪不是重点):
Instead of adopting any noise level estimation methods, we adopt an interactive strategy to handle real noisy images. First of all, we empirically found that the assumption of spatially invariant noise usually works well for most real noisy images. We then employ a set of typical input noise levels to produce multiple outputs, and select the one which has best trade-off between noise reduction and detail preservation.
还有第十页:
The noise levels at other regions are then interpolated from the noise levels of the typical regions to constitute an approximated non-uniform noise level map. Our FFDNet focuses on non-blind denoising and assumes the noise level map is known. In practice, some advanced noise level estimation methods [62], [64] can be adopted to assist the estimation of noise level map. In our following experiments, unless otherwise specified, we assume spatially invariant noise for the real noisy images.
-
理想状况下,模型的参数应该与噪声程度独立,从而实现可调节处理。但这一点很难做到。
-
子图像的获取方法很粗糙(简单的reshape函数),还原为完整图像的方法更粗糙,效果不敢苟同。
故事背景
作者给出了几点去噪任务的意义:
- 噪声在图像成像阶段,以及一些计算机视觉任务中是难以避免的,如[1,2]。
- 从贝叶斯观点出发,去噪是检验图像先验模型和优化方法的任务,如[3-5]。
- 图像去噪任务可以作为其他图像恢复任务中的模块,如[6-9]。
历史工作的共同局限性:通常会给定噪声的形式(如AWGN)和噪声程度。
核心思想
CNN是一个典型的静态结构。相比于传统优化方法,这种结构是比较死板的:一旦训练集的噪声程度给定,那么模型就只适用于这一噪声水平。
换句话说,我们学习的是映射\(f(y, \theta)\),其中\(\theta\)是噪声水平。我们可以将\(\theta\)单独拎出来,作为独立于训练集的参数,方便人为调整。理想状态下,我们训练的模型应该与\(\theta\)无关。文中是这么阐释的:
In the DnCNN model \(x = F(y; \theta_σ)\), the parameters \(\theta_σ\) vary with the change of noise level \(σ\), while in the FFDNet model, the noise level map is modeled as an input and the model parameters \(\theta\) are invariant to noise level. Thus, FFDNet provides a flexible way to handle different noise levels with a single network.
具体而言,本文引入了一个新的CNN输入:噪声图(noise level map)\(M\)。
FFDNet
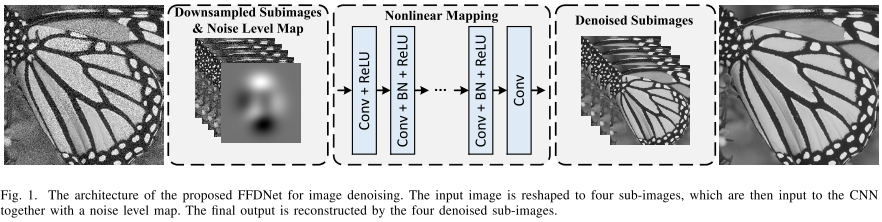
如图:
- 输入有噪图像被reshape至四张子图像。
- 四张子图像和噪声水平图一起,输入CNN网络。
- 得到四张去噪的子图像,再拼接得到最终输出图像。
网络设置
-
卷积层都是\(3 \times 3\),结构与DnCNN相似。不同的是,这里不采用短连接。
-
对于灰度图像,网络层数设置为15,每一层有64个通道;对于彩色图像则为12和96。原因:作者认为,RGB图像的三通道之间是有关联的,使用更浅的层,有利于挖掘其内部相关性;此外,彩色通道的输入更大,因此计算量也会更大;最重要的是,实验发现宽度比深度对彩图更重要。
噪声水平图
第四页在讲道理,刷公式。具体做法就一句话:对于确定的、标准差为\(\sigma\)的AWGN噪声,\(M\)的每一个元素都是\(\sigma\)。
有考虑非均匀的\(M\)吗?有,后面看。
对子图像的去噪
现在有两个策略,可以很快地降低计算量,但有缺点:
- 浅层网络。显然不行。
- 空洞卷积。作者发现会导致块效应,特别是在锐利边缘附近。
实际上,对子图像的处理借鉴了[39]中SPMC层用于超分辨的思路。这里的子图像是输入图像的\(\frac{1}{4}\)大。
对子图像处理,还可以提升感受野。
保证噪声水平图的有效性
前面也提到,作者希望噪声方差图能独立于模型参数。因此,强迫这种独立性就显得尤为重要。
正交正则化(orthogonal regularization)是一种消除滤波器相关性的方法。在本文中,作者采用的是正交初始化。
如何盲处理
作者辩称:我们可以将多个FFDNet(不同噪声下训练)用于处理未知程度的噪声,而不像DnCNN一样混合训练(作者说那样效果不好)。
为啥不用短连接
一句话:近期的一些工作[44,49]证实,当网络比较深时,RL意义不大。因此为了简单,作者这里也没用RL。但作者采用了Adam,BN和ReLU。
裁剪像素范围
我们知道,8bits数字图像应该在0到255之间取整。但有些工作没有这么做。本文也没有。
实验
对于时空不变噪声,我们用加性噪声AWGN建模;对于时空变化的噪声,我们用时空不变噪声AWGN与图像像素的点乘建模,见C。
一般性的实验略。
关于噪声水平图的敏感性
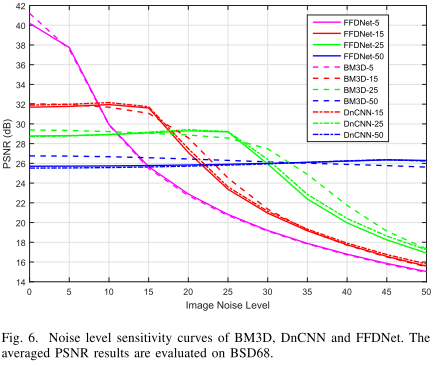
这里做了一个实验。例如FFDNet-20,即我们告诉FFDNet网络(输入噪声水平图的)噪声标准差为20。但输入图像的真实噪声标准差从0到50变化。有三个发现:
-
当输入图像的噪声标准差,等于噪声图的标准差时(例如都是20),DnCNN、BM3D和FFDNet的效果近似。
-
并且,此时效果是最好的。
-
当真实标准差小于输入标准差时,对性能没有什么影响。但反之,效果会迅速变差。这告诉我们:输入噪声图的噪声标准差可以激进(估高),但不要保守(估低)。
盲处理
按照标准差间隔为5,测试得到多个输出。其余标准差下的输出通过插值得到。肉眼挑出最好的???!!!作者还一本正经地强调原因:
Instead of adopting any noise level estimation methods, we adopt an interactive strategy to handle real noisy images. First of all, we empirically found that the assumption of spatially invariant noise usually works well for most real noisy images. We then employ a set of typical input noise levels to produce multiple outputs, and select the one which has best trade-off between noise reduction and detail preservation. Second, the spatially variant noise in most real-world images is signal-dependent. In this case, we first sample several typical regions of distinct colors. For each typical region, we apply different noise levels with an interval of 5, and choose the best noise level by observing the denoising results. The noise levels at other regions are then interpolated from the noise levels of the typical regions to constitute an approximated non-uniform noise level map. Our FFDNet focuses on non-blind denoising and assumes the noise level map is known. In practice, some advanced noise level estimation methods [62], [64] can be adopted to assist the estimation of noise level map. In our following experiments, unless otherwise specified, we assume spatially invariant noise for the real noisy images.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号