Paper | D3: Deep Dual-Domain Based Fast Restoration of JPEG-Compressed Images
D3: Deep Dual-Domain Based Fast Restoration of JPEG-Compressed Images
发表于2016年CVPR。
摘要
-
既利用了CNN,又考虑了JPEG压缩的特性,解决JPEG图像去失真问题。
-
针对于压缩特性,作者考虑了JPEG压缩方案的先验知识,也看到了基于稀疏的双域方法的成功实践[24]。
-
基于此,作者设计了一个单步稀疏推断(One-Step Sparse Inference, 1-SI)模块,作为稀疏编码的前向近似,高效、轻量。
读后感
这篇文章的主要贡献在于:将[24]中的双域法(主要基于稀疏字典学习),推广到了深度学习方法上,从而避免了迭代优化。
至于压缩特性,作者的考虑和[24]应该基本是一样的:特别设计了一个box-constrained loss,若DCT域上的字典生成结果落在了量化间隔外(必须预知量化水平),那么在训练时就会被惩罚,以此逼近更准确的DCT域字典。
故事
-
压缩失真的普遍性:在视觉通信和计算系统中,压缩失真是主要图像失真。有损压缩,例如JPEG和HEVC-MSP,被广泛用于节省带宽和存储。
-
压缩失真简介:有损压缩是对编码对象的不精确的精简近似,因此不可避免地带来失真,比如块效应(blockiness)、振铃(ringing effects)和模糊(blurs)。
-
压缩失真成因简介:这些失真通常是由基于块处理的不连续性、量化丢失高频细节等导致。
-
解决压缩失真的可行性:由于实用的图像压缩方法并非理想(practical image compression methods are not information theoretically optimal),因此得到的码流中仍然是存在冗余的。这就让图像复原成为了可能。此外,压缩失真还具有一些特性可以利用。例如,JPEG压缩会先将图像分为\(8 \times 8\)的块,然后在每个块内执行DCT、根据提前设定的量化水平量化DCT系数。
-
和一般去噪的不同:根据上面的特性不难看出,压缩噪声比一般噪声更难建模,因为其通常是非平稳的(non-stationary)、与信号有关的。
-
前人工作:早期工作[6,22]:基于滤波器,可以滤除一些伪影。数据驱动方法:目的是避免基于经验的、对压缩失真的建模。基于图像稀疏的方法:用于产生锐化的图像,但通常在边缘会有伪影,并且会产生不自然的光滑区域。深度学习方法:鼻祖ARCNN,可惜没有考虑任何压缩特性。还有一些工作,例如快速回归器[14]、稀疏和低秩先验模型[29]、深度系数编码[35]、稀疏展开模型[17]、基于\(l_0\)范数稀疏性的深度网络[34]等。
-
关键启发:本文受到[24]的启发。前人工作要么在DCT域上做,要么在像素域做。然而,只要某个块内一个DCT系数存在量化误差,那么整个块的像素值都会产生误差。另一方面,由于我们去掉了很多高频DCT系数,因此仅仅凭借DCT域是很难恢复高频细节的。因此,[24]就提出了双域模型。博主批注:这其实是频域法和像素域方法各自的特点。实际上,DCT域和像素域是可以互相切换的,你有的冗余我也有。只不过,像素域上对图像的先验更好理解,比如稀疏、对称、自相似等,但频域的先验很难找出来。
-
我们选择DNN的原因:复杂度和实时性是很重要的。传统推导流程,例如稀疏编码,包含大量优化过程。
深度双域法(D3)
首先回顾[24]提出的双域法。博主没做过字典学习和稀疏编码,根据文章猜个大概:
-
假设未压缩图像的像素域块是\(x_i\),量化后的DCT系数是\(y_i\)。
-
首先根据数据库,学习关于DCT域和像素域的两个字典。
-
那么,作者就通过最小化下式(字典已知),学习稀疏系数。
-
该方法需要提前知道量化水平(可推出量化间隔),限制DCT系数在量化间隔内,从而限制解空间。

关键局限:(1)迭代优化;(2)超参数需要主观设置;(3)两个字典是独立学习的。
接下来就是这篇文章的D3工作。
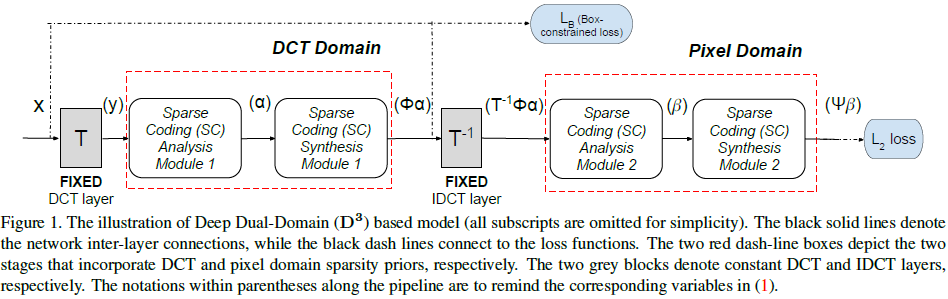
可以看到,框图是一致的,也是先将图像转换到DCT域,然后再转换到图像域。
在转换和反转换后,我们都可以定义一个损失。前者是为了逼近DCT域表示(惩罚落在量化间隔外的表现),后者是为了逼近像素值。
亮点在于:作者借助可学习的LSTA算法(LISTA),将迭代式优化方法替换为了简单的神经网络。原因在于:
-
在[24]中对解空间的限制,可以在训练神经网络时用loss(惩罚)代替。
-
迭代式求解和神经网络对参数的优化,本质是一样的。因此对字典的学习可以用神经网络实现。
具体原理参见3.2-3.3节。
实验略。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号