中英文词频统计(MATLAB)
中英文词频统计(MATLAB)
1. 英文词频统计
英文词频统计很简单,只需借助split断句,再统计即可。
完整MATLAB代码:
function wordcount
%思路:中文词频统计涉及到对“词语”的判断,需要导入词典或编写判断规则,很复杂。
%最简单的办法是直接统计英文词频,并由空格直接划分词语。然后再翻译即可得到中文词频。
%从官方网站上下载的pdf,转成reportfulltext.txt,存到workspace进行操作 全文共25003个字符。
clc;
clear;
report=fileread('reportfulltext.txt'); %读入全文
report=regexprep(report,'\W',' '); %不是字符的,都转换为空格。主要是去除标点符号
report=lower(report); %变成小写
words=regexp(report,' ','split')'; %根据空格分隔为单词cell
%至此每个单词都拿出来了
rank = tabulate(words); %rank是三列向量,包括名称,出现次数和百分比
ans=sortrows(rank,-2); %只根据第二列进行排序 -2表示降序
xlswrite('results',ans);%输出为excel文件
end
2. 中文词频统计
中文词频统计相对复杂一些。关键在于:
-
使用合适的语料库
-
从长到短,匹配词语。比如句中出现了“计算机”三字词,我们应该将三个字视为一个词,而不能把“计算”当做一个词。
function wordcountchinese
clc;
clear;
report=fileread('reportchinese.txt'); %读入中文报告,事先已放在工作区
%% dictionary.mat是一个我事先准备好的列向量
%其中dict是14636*1的字典列向量,从网上下载的官方语料库转换得到的
load dictionary.mat;
Maxlen=max(cellfun(@length,dict)); %最大词长,结果是10
%% 按标点初步分词
cut='[\,\。\、\;\:\!\?\“\”\‘\’\(\)\《\》\<\>\……\·]'; %标点符号的正则表达式
F=regexp(report,cut,'split')'; %转置,变成3131*1的列向量
% 此时,待分析的句集F和词典都已就绪
%% 算法原理
% 首先判断是否为有效句:句长是否大于0。小于0的不操作,相当于跳过
% 若是有效句,计算句长和最大词长Maxlen的最小值maxlen。待选字串长度不能大于该长度
% 从maxlen长度开始,取出待选字串
% 匹配,成功就输出,标记。若成功,平移maxlen个单位;若不成功,平移1个单位
% 选出下一个待选字串再匹配,重复操作,直到移动到句长以外
% 如果上一个长度匹配成功,那么就不用再匹配了,该句跳过;如果meet==0,重复上一步操作
% 长度maxlen减到1,也要匹配,因为词库中有一个字的词;maxlen==0是终止信号。
%% 最大匹配法进一步分词
sentence=[]; %是粗分后F中的每一个元素
word=[];
words={};
k=1;
for i=1:length(F) %遍历F
sentence=cell2mat(F(i,1)); %把cell转换成字符串
sentence_len=length(sentence); %求出句长
meet=0; %更新初始状态
if(sentence_len>0) %有效句
maxlen=min(Maxlen,sentence_len);
while(maxlen>0)
start=1;
while((start+maxlen)<=sentence_len) %索引不能移动到句子外面
word=sentence(start:start+maxlen);
if(ismember(word,dict))%如果匹配成功
meet=1;
words(k)=cellstr(word);
k=k+1;
start=start+maxlen; %移动maxlen个单位再匹配
else
start=start+1; %移动一个单位再匹配
end
end
%已经移动到句子外面了
if(meet==0)
maxlen=maxlen-1;
else
break;
end
end
end
%无效句,句长为0,不处理,直接跳过
end
%% 排序处理
rank = tabulate(words); %rank是三列向量,包括名称,出现次数和百分比
ANS=sortrows(rank,-2); %只根据第二列进行排序 -2表示降序
xlswrite('resultschinese',ANS(1:50,1:3));%输出为excel文件 由于词语将近1777个,因此只输出前100个
end
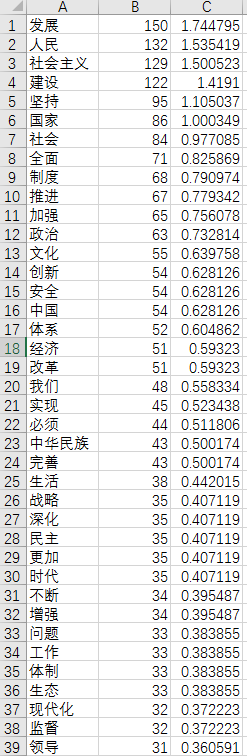
十九大中文版报告统计结果:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号