激活函数专辑
激活函数专辑
激活函数(又叫激励函数,后面就全部统称为激活函数)是模型整个结构中的非线性扭曲力,神经网络的每层都会有一个激活函数。
常用的激活函数:Sigmoid函数、tanh函数、Relu函数、Leaky ReLU函数、ELU (Exponential Linear Units) 函数、SoftMax函数、MaxOut函数。
激活函数的作用是什么?
激活函数的主要作用是在神经网络中引入非线性因素。
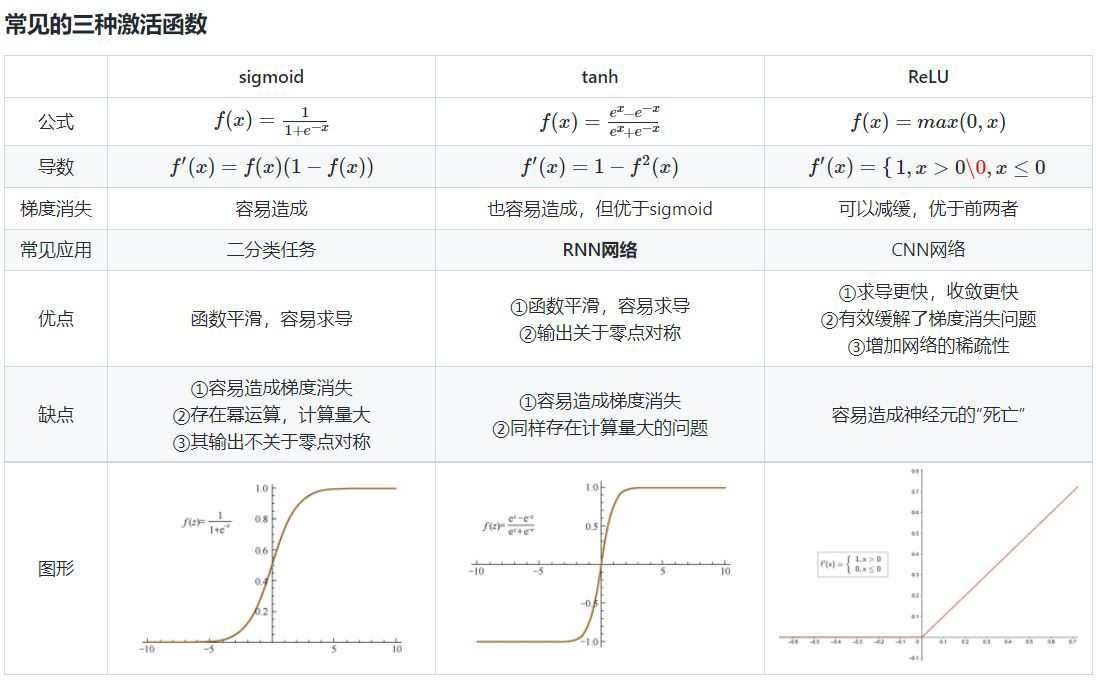
相比于sigmoid函数,tanh激活函数输出关于“零点”对称的好处是什么?
对于sigmoid函数而言,其输出始终为正,这会导致在深度网络训练中模型的收敛速度变慢,因为在反向传播链式求导过程中,权重更新的效率会降低(具体推导可以参考这篇文章)。
此外,sigmoid函数的输出均大于0,作为下层神经元的输入会导致下层输入不是0均值 的,随着网络的加深可能会使得原始数据的分布发生改变。而在深度学习的网络训练中, 经常需要将数据处理成零均值分布的情况,以提高收敛效率,因此tanh函数更加符合这个要求。
sigmoid函数的输出在[0,1]之间,比较适合用于二分类问题。
为什么RNN中常用tanh函数作为激活函数而不是ReLU?
详细分析可以参考这篇文章(https://www.zhihu.com/question/61265076)。下面简单用自己的话总结一下: RNN中将tanh函数作为激活函数本身就存在梯度消失的问题,而ReLU本就是为了克服梯度消失问题而生的,那为什么不能直接(注意:这里说的是直接替代,事实上通过截断优化ReLU仍可以在RNN中取得很好的表现)用ReLU来代替RNN中的tanh来作为激活函数呢?这是因为ReLU的导数只能为0或1,而导数为1的时候在RNN中很容易造成梯度爆炸问题。
为什么会出现梯度爆炸的问题呢?
因为在RNN中,每个神经元在不同的时刻都共享一个参数W(这点与CNN不同,CNN中每一层都使用独立的参数Wi),因此在前向和反向传播中,每个神经元的输出都会作为下一个时刻本神经元的输入,从某种意义上来讲相当于对其参数矩阵W作了连乘,如果W中有其中一个特征值大于1,则多次累乘之后的结果将非常大,自然就产生了梯度爆炸的问题。
那为什么ReLU在CNN中不存在连乘的梯度爆炸问题呢?
因为在CNN中,每一层都有不同的参数Wi,有的特征值大于1,有的小于1,在某种意义上可以理解为抵消了梯度爆炸的可能。
什么是神经元“死亡”?
Relu的输入值为负的时候,输出始终为0,其一阶导数也始终为0,这样会导致神经元不能更新参数,也就是神经元不学习了,这种现象叫做“Dead Neuron”。
如何解决ReLU神经元“死亡”的问题?
①采用Leaky ReLU等激活函数 ②设置较小的学习率进行训练 ③使用momentum优化算法动态调整学习率
Leaky ReLU函数
Leaky ReLU函数是一种专门设计用于解决神经元“死亡”问题的激活函数,出自《Rectified NonlinearitiesImprove Neural Network Acoustic Models (PDF)》一文。

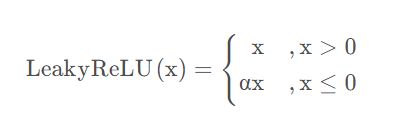
优点:
①神经元不会出现死亡的情况。
②Leaky对于所有的输入,不管是大于等于0还是小于0,神经元不会饱和。
③由于Leaky ReLU线性、非饱和的形式,在SGD中能够快速收敛。
④计算速度要快很多。Leaky ReLU函数只有线性关系,不需要指数计算,不管在前向传播还是反向传播,计算速度都比sigmoid和tanh快。
缺点:
Leaky ReLU函数中的α,需要通过先验知识人工赋值,通常取0.1。
ELU (Exponential Linear Units) 函数
ELU函数也是为解决ReLU存在的问题而提出,出自《Fastand accurate deep network learning by exponential linear units (elus)》一文。
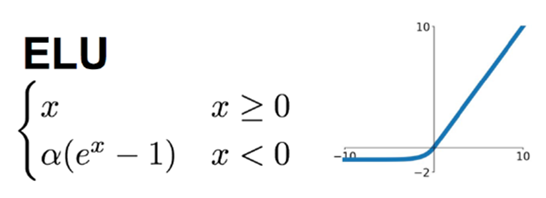
ELU函数的特点:
①没有神经元死亡问题,输出的平均值接近0,以0为中心。
②ELU 通过减少偏置偏移的影响,使正常梯度更接近于单位自然梯度,从而使均值向零加速学习。
③ELU函数在较小的输入下会饱和至负值,从而减少前向传播的变异和信息。
④ELU函数的计算强度更高,它的参数比较多,本质上是在输出结果上又增加了一层。与Leaky ReLU类似,尽管理论上比ReLU要好,但目前在实践中没有充分的证据表明ELU总是比ReLU好。
Softmax函数
Softmax函数是用于多类分类问题的激活函数,在多类分类问题中,超过两个类标签则需要类成员关系。对于长度为K的任意实向量,Softmax函数可以将其压缩为长度为K ,值在[0,1]范围内,并且向量中元素的总和为1的实向量。
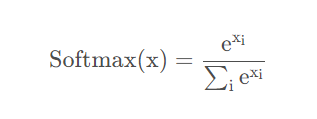
Softmax函数与正常的max函数不同:max函数仅输出最大值,但Softmax函数确保较小的值具有较小的概率,并且不会直接丢弃。Softmax函数的分母结合了原始输出值的所有因子,这意味着Softmax函数获得的各种概率彼此相关。
Softmax函数的特点:
①在零点不可微。
②负输入的梯度为零,这意味着对于该区域的激活,权重不会在反向传播期间更新,因此会产生永不激活的死亡神经元。
MaxOut函数
Maxout函数来源于ICML上的一篇文献《Maxout Networks》,它可以理解为是神经网络中的一层网络,类似于池化层、卷积层一样。我们也可以把Maxout函数看成是网络的激活函数层,我们假设网络某一层的输入特征向量为:x=(x1,x2,...,xd),也就是我们输入是d个神经元。Maxout函数的输出如下:
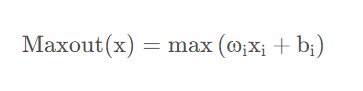
如何选择合适的激活函数?
①通常来说,不能把各种激活函数串起来在一个网络中使用。
②如果使用ReLU,那么一定要小心设置学习率(learning rate),并且要注意不要让网络中出现很多死亡神经元。如果死亡神经元过多的问题不好解决,可以试试Leaky ReLU、PReLU、或者Maxout。
③尽量不要使用sigmoid激活函数,可以试试tanh。
参考文献
深度学习领域最常用的10个激活函数,一文详解数学原理及优缺点26种神经网络激活函数可视化

 浙公网安备 33010602011771号
浙公网安备 33010602011771号