【商汤实习总结】深度学习模型部署与落地
温故而知新,参考mentor睿昊学长(xhplus)和主管锋伟(forwil)的专栏,记录在商汤实习内容的总结和反思。希望商汤工具人组越来越nb!
什么是模型部署
经过大量的图片进行训练后,一个具有上亿个参数的深度学习模型在测试集上达到的预定的精度,这时候老板们一定催着把这个模型上线/搭载到产品中 进行 验证/售卖。模型部署就是完成深度学习算法产品化的最后一步。一个完美的模型部署工具/引擎,理应完成以下几个功能:
- 跨平台:可跑在任何的硬件上,包括各类cpu/gpu/dsp/asic/fpga...
- 高效能:速度快、占用内存少...
- 保精度:产品精度与训练精度保持一致、损失极少...
- 产品集成:满足产品的各种用法,包括加密、批处理、reshape,甚至授权,可裁剪
- 训练打通:与训练生态打通,最好是训练完成后,简单命令直接导出
理想是美好的,现实往往很惨。理应把模型部署做的很好的源头:pytorch、tensorflow 做得不尽人意,尤其体现在跨平台、高效能和产品集成上。猜测是因为G&F两家的模型部署场景只有云与端,云侧可以用暴力的serving API直接将单模型上线,端侧似乎大家只关心手机,G家草草的搞个tensorflow-lite支持arm/ocl就完事了。
在这方面明显国内的需求场景走的非常靠前:1、国产成熟的深度学习芯片大量覆盖云侧和端侧,端侧需求除手机之外需求同样十分旺盛。2、国内的算法精度/速度要求及其高,普通的单模型流程无法满足。
现在是2020年,可以断言的是,国内随便一家做AI公司的部署系统,必定领先G家和F家好几代,这是贵国产业软件技术领先性上,非常难得的状态。
怎么是多平台模型部署
多平台模型部署指的是将已经训练收敛的模型,经过一系列工具,最终将模型运用在各式各样的计算设备上。市面上所有云端、边缘的人脸特效、人脸验证等功能,都是以此种模式运行,达到高性能、低延时。
商汤的研究课题包括:如何用一套架构支持各式各样的计算设备,如何将算法的前处理和后处理囊括在部署流程中,如何在可编程设备上达到极致的计算性能等等。

怎么研究部署系统
研究模型部署最好的范本绝对是DL框架的老祖宗:caffe。几乎所有的部署系统都深受caffe的影响。caffe提供了一个非常简单的基于net to layer的范式,很好的建模了至少是CNN模型的运行环境。下图展示一个caffe的架构示意图:
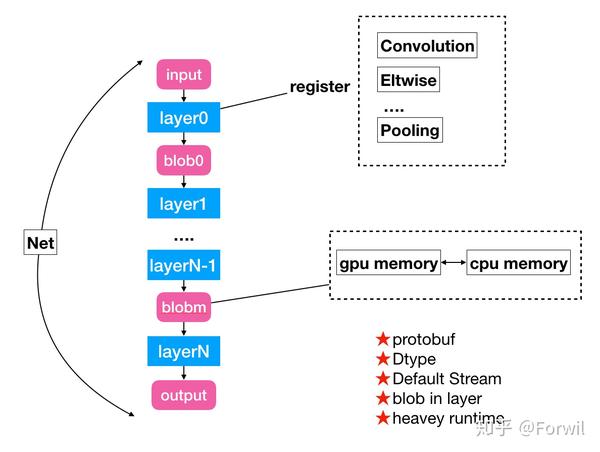
caffe是一个非常简单的执行引擎,在不考虑训练的情况下。最大单位为Net,在Net之上定义了一个Layer Vector,通过从0到n遍历layer,调用layer.forward,即可完成一次前馈。caffe有一些设计被其他框架大量的借鉴,比如基于layer的注册器机制、基于blob的内存管理等等。来自腾讯的ncnn/featherCNN都是基于caffe架构演进过来的(都继承了一些特性,修复了一些问题)。
但caffe的缺点同时也十分明显,给大家留下了非常非常多优化空间,可以说修复这些缺点养活了国内大量的深度学习工程师:
- cuda default stream:caffe里没有进行cuda kernel stream的管理,使得同一张显卡跑两个caffe部署任务效率急剧下降。
- Dtype:caffe里创建网络的数值类型是通过模板参数传入了,由于深度学习的低精度、低比特并不仅仅是改变编程语言里的数值类型这么简单,导致至少在很长一段时间里,caffe甚至都极难支持fp16部署。
- protobuf:caffe极度依赖一个中心化的protobuf定义,这带来了几个问题,一是protobuf的代码size不小,在极端追求库体积情况下成为累赘。另一个是中心化的protobuf使得注册一个新的layer及其不模块化,很容易造成版本冲突。
- blob in layer:caffe的设计中,卷积的weight是隐藏在layer的参数中的,这样的设计明显不如将卷积的weight作为第二个/第三个常量tensor输入来的简洁和一致。
- heavey runtime:caffe没有解耦 模型结构定义 与 layer kernel实现 两者,使得caffe和protobuf格式深深的绑定在了一起。在深度学习不断发展,硬件不断变多,网络格式日新月异的同时,all-in-one-runtime的方式制约了许多新feature的引入和更深的优化。compiler-runtime分离的方式被验证是一种更合理的方案。
尽管如此,caffe依然是一个非常伟大的框架,任何在校生只要能把caffe吃透,对于其对深度学习的理解,大规模c++项目的认知将会上一个台阶。
什么是深度学习芯片
深度学习芯片是一个并未界定严谨的概念。
狭义上,深度学习芯片指“针对深度学习设计的,可高效执行深度学习算法的芯片”,一般指ASIC和FPGA。其叫法五花八门,根据不同厂商的风格,有不同的特定称呼,如DPU,NPU,TPU等等。
从广义上,DSP、CPU和GPU也可以称之为深度学习芯片,因为深度学习算法也可以极其高效的运行在这些设备上面:DSP往往拥有超长的指令集(VLIW),提供位宽特别大,峰值算力不错的SIMD(单指令多数据流)指令支持。CPU中的ARM/X86同样也为深度学习应用提供了长度128~256~512不等的fp32/fp16/int8计算。至于GPU,深度学习扛把子Nvidia的GPU就不同提了,移动端的GPU同样提供丰富的矩阵算力,以fp16为主要支持的精度。

Hi3559A 提供了4种不同类型的深度学习执行方案
以最为典型的海思家族的Hi3559A SOC为例,就集结了四种典型的处理器类型。神奇的是,这四种处理器都可以执行深度学习模型,是不是很吃惊?所以如果听到有人说“我这个算法可以跑在3559A”上,那你可得问清楚了是跑在哪个处理器,因为四种处理器的编程难度、算力可不相同。
| 芯片 | 算力 | 编程方法级别 |
|---|---|---|
| ARM A73/A53 | 28.8 + 19.2 Gops(fp32) | ARM neon:vmla |
| Mali G71 | 约 22.16 Gops (fp16) | opencl 1.1/1.2/2.0 |
| DSP:4 x cadence vp6 | 4 x 350 Gops (int8) | VP6 VLIW instruction |
| NPU:2 x nnie11 | 2 x 1.7 Tops (int8) | HI_MPI_SVP_NNIE API |
部署框架如何支持一款新的深度学习硬件
我们可以找到非常方便的部署软件库:
- ARM:市面上支持arm上部署神经网络的库很多:ncnn,tnn,mnn,tengine,featherCNN,tvm
- DSP:tensilica官方提供运行库XNNC(Xtensa Neural Network Compiler)看文档有点麻烦,但跑起来应该没问题。就是需要封装到HI_SVP的DSP RPC接口中。
- NNIE:nnie的文档十分完善,mapper一下直接量化部署全搞定!
“针对每个平台单独转换,执行的话,以后换新算法、新模型咋办?以后如果又来一个新平台,你是不是还得再写一遍代码。”
——思考一种软件架构,可以灵活的接入不同的新硬件,并且快速适配新模型:
定义一个标准接口(或者说基类),然后针对每个平台写一个适配(子类)。实操上,可以使用工厂模式或者动态库加载的方式,注册到环境中。这样就可以不用改动上层的前处理和后处理封装,将神经网络的执行过程完全隐藏在标准接口内了。几个基础函数如下:
1 nn_handle * NN_Init(char * model_file); // 通过模型文件创建句柄 2 void NN_Prepare(nn_handle * hdl); // 执行一的内存空间申请等事项 3 nn_tensor * NN_GetTensor(nn_handle * hdl, char * tensor_name); // 获取输入输出Tensor 用于取数据(或者塞数据) 4 void NN_SetTensor(nn_handle * hdl, char * tensor_name, nn_tensor * tensor); // 将数据送回网络(一般是输入) 5 void NN_Forward(nn_handle * hdl): // 数据准备完毕,开始推理 6 void NN_Destroy(nn_handle * hdl); // 模型执行结束,销毁句柄
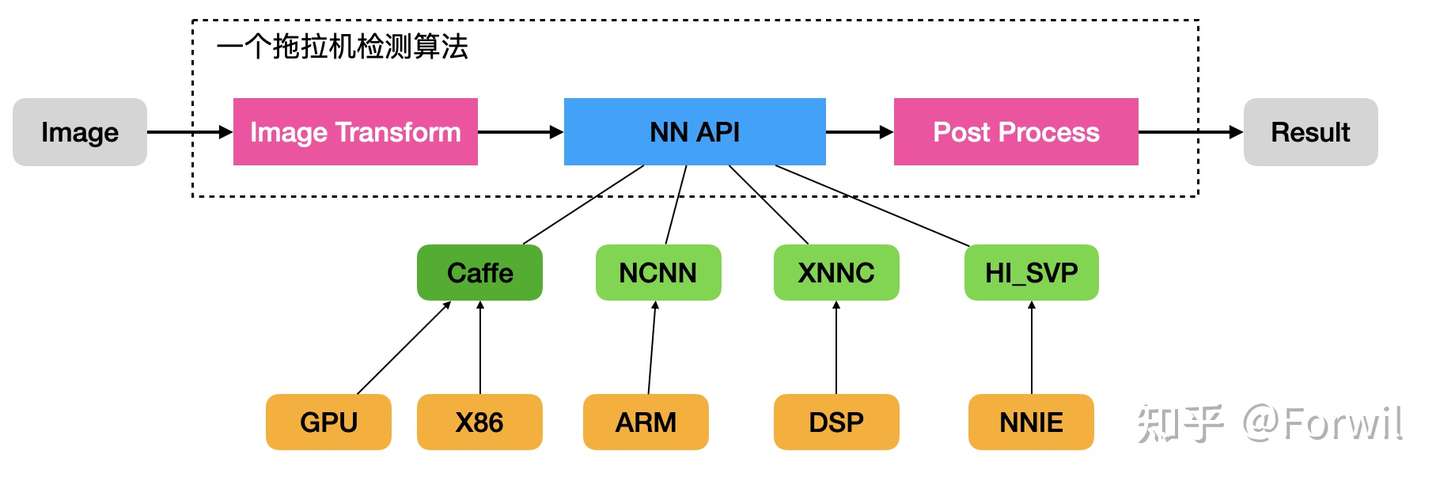
一个简单版本的多平台模型部署框架
除此之外,我们还发现另外一堆严重的问题:
- DSP和NNIE都只支持量化INT8/INT32数据输入/输出,之前Caffe和NCNN则都是fp32。数据类型无法统一。
- NNIE不支持在运行时使用caffe模型进行初始化,需要转换到专用格式,这种格式只能在x86上进行。
- DSP的模型已经直接编译成二进制固件了,需要非常复杂的DSP重启操作才能使用。
- 刨掉Shufflenet不说,NNIE和DSP在Resnet18上因为将数值转化成了INT8,都出现了不同程度的掉精度。
Reference
部署:深度学习落地的最后“N”公里

 浙公网安备 33010602011771号
浙公网安备 33010602011771号