ORACLE高级SQL之分析函数
首先来看一个例子:
--删除emp表 drop table emp purge; --创建emp表 CREATE TABLE emp ( emp_id NUMBER(6), ename VARCHAR2(45), dept_id NUMBER(4), hire_date DATE, sal NUMBER(8,2) ); --创建emp数据 INSERT INTO emp (emp_id, ename, dept_id, hire_date, sal) VALUES (101, 'Tom', 20, TO_DATE('21-09-1989', 'DD-MM-YYYY'), 2000); INSERT INTO emp (emp_id, ename, dept_id, hire_date, sal) VALUES (102, 'Mike', 20, TO_DATE('13-01-1993', 'DD-MM-YYYY'), 8000); INSERT INTO emp (emp_id, ename, dept_id, hire_date, sal) VALUES (120, 'John', 50, TO_DATE('18-07-1996', 'DD-MM-YYYY'), 1000); INSERT INTO emp (emp_id, ename, dept_id, hire_date, sal) VALUES (121, 'Joy', 50, TO_DATE('10-04-1997', 'DD-MM-YYYY'), 4000); INSERT INTO emp (emp_id, ename, dept_id, hire_date, sal) VALUES (122, 'Rich', 50, TO_DATE('01-05-1995', 'DD-MM-YYYY'), 3000); INSERT INTO emp (emp_id, ename, dept_id, hire_date, sal) VALUES (123, 'Kate', 50, TO_DATE('10-10-1997', 'DD-MM-YYYY'), 5000); INSERT INTO emp (emp_id, ename, dept_id, hire_date, sal) VALUES (124, 'Jess', 50, TO_DATE('16-11-1999', 'DD-MM-YYYY'), 6000); INSERT INTO emp (emp_id, ename, dept_id, hire_date, sal) VALUES (100, 'Stev', 10, TO_DATE('01-01-1990', 'DD-MM-YYYY'), 7000); COMMIT;
查询结果:
SELECT
emp_id,ename,dept_id,hire_date,sal,
SUM(sal) OVER (PARTITION BY dept_id ORDER BY hire_date) sum_sal,
SUM(sal) OVER (PARTITION BY dept_id ) sum_sal2,
SUM(sal) OVER ( ) sum_sal3
FROM emp;

SELECT
emp_id,ename,dept_id,hire_date,sal,
SUM(sal) OVER (PARTITION BY dept_id ORDER BY hire_date) sum_sal1,
SUM(sal) OVER (PARTITION BY dept_id ORDER BY hire_date DESC) sum_sal2, --desc是从下往上累加
SUM(sal) OVER (PARTITION BY dept_id ORDER BY hire_date DESC nulls LAST) sum_sal3,
SUM(sal) OVER (PARTITION BY dept_id ) sum_sal4,
SUM(sal) OVER ( ) sum_sal5
FROM emp;
查询结果:

开窗函数
1、开窗函数之ROWS:
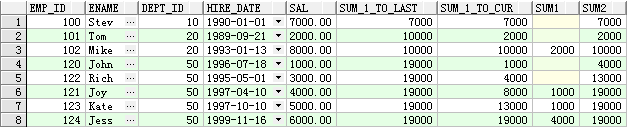
SELECT emp_id,ename,dept_id,hire_date,sal, -- 以下均为首先按dept_id进行分组,其次按照hire_date进行排序,且所有统计不能跨越其所在分区,故不再重复 -- 窗口范围为该分区的第一行到该分区的最后一行,与sum_sal_part等同 SUM(sal) OVER (PARTITION BY dept_id ORDER BY hire_date ROWS BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING) sum_1_to_last, -- 窗口范围为该分区的第一行到本行,与sum_sal_part_order等同 SUM(sal) OVER (PARTITION BY dept_id ORDER BY hire_date ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW) sum_1_to_cur, -- 窗口范围为该分区的第一行到本行前一行,统计的是第一行到本行前一行薪资的累计 SUM(sal) OVER (PARTITION BY dept_id ORDER BY hire_date ROWS BETWEEN UNBOUNDED PRECEDING AND 1/*value_expr*/ PRECEDING) sum_1_to_curbef1, -- 窗口范围为该分区的第一行到本行后一行,统计的是第一行到本行后一行薪资的累计 SUM(sal) OVER (PARTITION BY dept_id ORDER BY hire_date ROWS BETWEEN UNBOUNDED PRECEDING AND 1 FOLLOWING) sum_1_to_curaft1 FROM emp order by dept_id,hire_date;
查询结果:

2、开窗函数之RANGE:
RANGE窗口中只能对NUMBER、DATE起作用。
RANGE窗口中,ORDER BY中只能有一列;但是在ROWS窗口中,ORDER BY中可以有多列。
SELECT emp_id,ename,dept_id,hire_date,sal, -- 后面均为以dept_id分组,再按hire_date排序,且所有统计不能跨分区,由于是逻辑范围,因此PRECEDING和FOLLOWING表达式有符号 -- 窗口范围为该分区的第一行到该分区的最后一行,与sum_sal_part等同,在非条件表达式中等同于ROWS SUM(sal) OVER (PARTITION BY dept_id ORDER BY sal RANGE BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING) sum_1_to_last, -- 窗口范围为该分区的第一行到本行,与sum_sal_part_order等同,在非条件表达式中等同于ROWS SUM(sal) OVER (PARTITION BY dept_id ORDER BY sal RANGE BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW) sum_1_to_cur, -- 窗口范围为该分区内小于(当前行sal - 2500)的所有的薪资累计 SUM(sal) OVER (PARTITION BY dept_id ORDER BY sal RANGE BETWEEN UNBOUNDED PRECEDING AND 2500/*value_expr*/ PRECEDING) sum1, -- 窗口范围为该分区内小于(当前行sal + 2500)的所有薪资累计 SUM(sal) OVER (PARTITION BY dept_id ORDER BY sal RANGE BETWEEN UNBOUNDED PRECEDING AND 2500/*value_expr*/ FOLLOWING) sum2 FROM emp;
查询结果:
3、开窗函数之KEEP
KEEP为聚合函数的特殊关键字。(弄不明白这个函数)
当聚合函数MIN、MAX、SUM、AVG、COUNT、VARIANCE和STDDEV使用KEEP。
当KEEP和DENSE_RANK FIRST/DENSE_RANK LAST 一起使用时,获取一组中排名第一或者排名最后的记录。必须由order by子句来排序。后面也可以接over()分析函数部分。
Min(col2) keep (dense_rank first order by coll)保留按coll排名第一的col2的最小值。
Min(col2) keep (dense_rank first order by co11) over (partition by co 13 )按col3分组保留按coll排名各组第一的col2 的最小值。
SELECT emp_id,ename,dept_id,hire_date,sal,
DENSE_RANK() OVER(PARTITION BY dept_id ORDER BY sal) DENSE_RANK,
MIN(hire_date) KEEP (DENSE_RANK FIRST ORDER BY sal) OVER(PARTITION BY dept_id) min_first,
MIN(hire_date) KEEP (DENSE_RANK LAST ORDER BY sal) OVER(PARTITION BY dept_id) min_last,
MAX(hire_date) KEEP (DENSE_RANK FIRST ORDER BY sal) OVER(PARTITION BY dept_id) max_first,
MAX(hire_date) KEEP (DENSE_RANK LAST ORDER BY sal) OVER(PARTITION BY dept_id) max_last
FROM emp;
查询结果:

函数部分
1、排名函数:ROW_NUMBER、RANK、DENSE_RANK
这三个函数都是根据PARTITION BY后面的字段分组,然后根据ORDER BY后面的字段进行排序后再进行排名
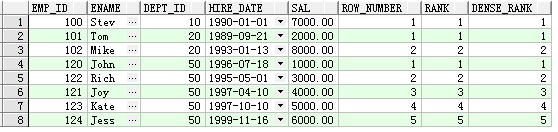
SELECT
emp_id,ename,dept_id,hire_date,sal,
ROW_NUMBER() OVER (PARTITION BY dept_id ORDER BY sal) AS row_number,
RANK() OVER (PARTITION BY dept_id ORDER BY sal) AS rank,
DENSE_RANK() OVER (PARTITION BY dept_id ORDER BY sal) AS dense_rank
FROM emp;
查询结果:
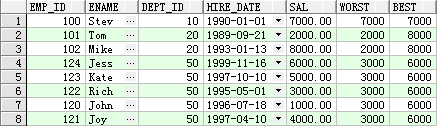
SELECT
emp_id,ename,dept_id,hire_date,sal,
MIN(sal) KEEP (DENSE_RANK FIRST ORDER BY hire_date) OVER (PARTITION BY dept_id) Worst,
MAX(sal) KEEP (DENSE_RANK LAST ORDER BY hire_date) OVER (PARTITION BY dept_id) Best
FROM emp;
查询结果:
2、FIRST_VALUE与LAST_VALUE
FIRST_VALUE 返回一个排序数据集合的第一行,而LAST_VALUE 则返回一个排序数据集合的最后一行。
SELECT
emp_id,ename,dept_id,hire_date,sal,
FIRST_VALUE(ename) OVER(PARTITION BY dept_id ORDER BY sal ) AS fir_val,
FIRST_VALUE(ename) OVER(PARTITION BY dept_id ORDER BY sal DESC) AS fir_val_desc,
LAST_VALUE(ename) OVER(PARTITION BY dept_id ORDER BY sal ) AS last_val,
LAST_VALUE(ename) OVER(PARTITION BY dept_id ORDER BY sal DESC) AS last_val_desc
FROM emp;
查询结果:

3、LAG与LEAD
lag与lead函数是跟偏移量相关的两个分析函数,通过这两个函数可以在一次查询中取出同一字段的前N行的数据(lag)和后N行的数据(lead)作为独立的列,从而更方便地进行进行数据过滤。这种操作可以代替表的自联接,并且LAG和LEAD有更高的效率。
over()表示 lag()与lead()操作的数据都在over()的范围内,它里面可以使用partition by语句(用于分组) order by 语句(用于排序)。partition by a order by b表示以a字段进行分组,再以b字段进行排序,对数据进行查询。
例如:lead(field, num, defaultvalue) field需要查找的字段,num往后查找的num行的数据,defaultvalue没有符合条件的默认值。
SELECT emp_id,ename,dept_id,hire_date,sal, LAG(sal) OVER (ORDER BY hire_date) AS prev_sal1, LEAD(sal) OVER (ORDER BY hire_date) AS next_sal1, LAG(sal, 1, 0) OVER (ORDER BY hire_date) AS prev_sal2, LEAD(sal, 1,0) OVER (ORDER BY hire_date) AS next_sal2, LAG(sal, 1, 0) OVER (partition BY dept_id ORDER BY hire_date) AS prev_sal3, LEAD(sal, 1,0) OVER (partition BY dept_id ORDER BY hire_date) AS next_sal3, LAG(sal, 2, 999) OVER (partition BY dept_id ORDER BY hire_date) AS prev_sal4, LEAD(sal, 2,999) OVER (partition BY dept_id ORDER BY hire_date) AS next_sal4 FROM emp;
查询结果:

案例分析
1、排名论次
环境准备:
drop table emp purge; CREATE TABLE emp ( emp_id NUMBER(6), ename VARCHAR2(45), dept_id NUMBER(4), hire_date DATE, sal NUMBER(8,2) ); --创建emp数据 INSERT INTO emp (emp_id, ename, dept_id, hire_date, sal) VALUES (101, 'Tom', 20, TO_DATE ('21-09-1989', 'DD-MM-YYYY'), 2000); INSERT INTO emp (emp_id, ename, dept_id, hire_date, sal) VALUES (102, 'Mike', 20, TO_DATE ('13-01-1993', 'DD-MM-YYYY'), 8000); INSERT INTO emp (emp_id, ename, dept_id, hire_date, sal) VALUES (120, 'John', 50, TO_DATE ('18-07-1996', 'DD-MM-YYYY'), 1000); INSERT INTO emp (emp_id, ename, dept_id, hire_date, sal) VALUES (121, 'Joy', 50, TO_DATE ('10-04-1997', 'DD-MM-YYYY'), 1000); INSERT INTO emp (emp_id, ename, dept_id, hire_date, sal) VALUES (122, 'Rich', 50, TO_DATE ('01-05-1995', 'DD-MM-YYYY'), 4000); INSERT INTO emp (emp_id, ename, dept_id, hire_date, sal) VALUES (123, 'Kate', 50, TO_DATE ('10-10-1997', 'DD-MM-YYYY'), 4000); INSERT INTO emp (emp_id, ename, dept_id, hire_date, sal) VALUES (124, 'Jess', 50, TO_DATE ('16-11-1999', 'DD-MM-YYYY'), 7000); INSERT INTO emp (emp_id, ename, dept_id, hire_date, sal) VALUES (100, 'Stev', 10, TO_DATE ('01-01-1990', 'DD-MM-YYYY'), 7000); COMMIT;
SQL> select * from emp;
EMP_ID ENAME DEPT_ID HIRE_DATE SAL
------- ----- ------- ----------- ----------
101 Tom 20 1989-09-21 2000.00
102 Mike 20 1993-01-13 8000.00
120 John 50 1996-07-18 1000.00
121 Joy 50 1997-04-10 1000.00
122 Rich 50 1995-05-01 4000.00
123 Kate 50 1997-10-10 4000.00
124 Jess 50 1999-11-16 7000.00
100 Stev 10 1990-01-01 7000.00
用普通语句查询每个部门内收入最低的人:
WITH t as (SELECT dept_id, min(sal) as min_sal FROM emp GROUP BY dept_id) select emp.emp_id, emp.ename, emp.dept_id, emp.hire_date,emp.sal from emp, t where emp.dept_id = t.dept_id and emp.sal = t.min_sal; 查询结果: EMP_ID ENAME DEPT_ID HIRE_DATE SAL ------- ----- ------- ----------- ---------- 101 Tom 20 1989-09-21 2000.00 121 Joy 50 1997-04-10 1000.00 120 John 50 1996-07-18 1000.00 100 Stev 10 1990-01-01 7000.00
用dense_rand分析函数查询每个部门内收入最低的人(效率更高):
SELECT emp_id, ename, dept_id, hire_date,sal FROM (SELECT emp.*, dense_rank() OVER(PARTITION BY dept_id ORDER BY sal ) AS N FROM emp) WHERE N = 1; 查询结果: EMP_ID ENAME DEPT_ID HIRE_DATE SAL ------- ----- ------- ----------- ---------- 100 Stev 10 1990-01-01 7000.00 101 Tom 20 1989-09-21 2000.00 120 John 50 1996-07-18 1000.00 121 Joy 50 1997-04-10 1000.00
2、数据去重
环境准备:
DROP TABLE t purge ; CREATE TABLE t AS SELECT * FROM dba_objects WHERE rownum<=10; UPDATE t SET object_id=rownum; UPDATE t SET object_id=3 WHERE object_id<=3; UPDATE t SET object_id=4 WHERE object_id>=4 AND object_id<=6; COMMIT;
普通的去重写法(随便删除,保留rowid最大的一条):
delete from t where rowid < (select max(rowid) from t t2 where t.object_id = t2.object_id );
数据去重的分析函数写法(保留最新的一条记录):
delete t where rowid in (select rid from (select rowid rid, row_number() over(partition by object_id order by created desc) rn from t) where rn > 1);
日常在处理数据去重的时候,如果数据量太大,可以考虑先把不重复的数据移出到另外一个表中,然后只针对重复数据进行处理。
3、占比应用 ratio_to_report
SELECT
emp_id,ename,dept_id,hire_date,sal,
ratio_to_report(sal) OVER () as pct1l,
ratio_to_report(sal) OVER (partition by dept_id) as pct2
FROM emp;
查询结果:

4、连续值判定
环境准备:
drop table t purge; create table t (id1 int,id2 int ,id3 int); insert into t (id1 ,id2,id3) values (1,45,89); insert into t (id1 ,id2,id3) values (2,45,89); insert into t (id1 ,id2,id3) values (3,45,89); insert into t (id1 ,id2,id3) values (8,45,89); insert into t (id1 ,id2,id3) values (12,45,89); insert into t (id1 ,id2,id3) values (36,45,89); insert into t (id1 ,id2,id3) values (22,45,89); insert into t (id1 ,id2,id3) values (23,45,89); insert into t (id1 ,id2,id3) values (89,45,89); insert into t (id1 ,id2,id3) values (92,45,89); insert into t (id1 ,id2,id3) values (91,45,89); insert into t (id1 ,id2,id3) values (90,45,89); commit; SQL> select * from t; ID1 ID2 ID3 ---- ---- ---- 1 45 89 2 45 89 3 45 89 8 45 89 12 45 89 36 45 89 22 45 89 23 45 89 89 45 89 92 45 89 91 45 89 90 45 89
需要实现的需求:
1、将ID1连续的数据查找出来,效果如下:
ID1 ID2 ID3 ---- ---- ---- 1 45 89 2 45 89 3 45 89 22 45 89 23 45 89 89 45 89 90 45 89 91 45 89 92 45 89
2、要求查出连续数据,并且要算出出最小值和最大值及连续的个数,效果如下:
1 3 3 22 23 2 89 92 4
实现方法:
1、先看如下sql的查询结果,使用分析函数ROW_NUMBER已经把连续的数据找出来了,分成3个组。
SELECT id1, id2, id3, ROW_NUMBER() OVER(ORDER BY id1) - ID1 AS group_id FROM t; ID1 ID2 ID3 GROUP_ID ---- ---- ---- ---------- 1 45 89 0 2 45 89 0 3 45 89 0 8 45 89 -4 12 45 89 -7 22 45 89 -16 23 45 89 -16 36 45 89 -28 89 45 89 -80 90 45 89 -80 91 45 89 -80 92 45 89 -80
2、需求1的实现方法:
select id1, id2, id3 from (select id1, id2, id3, count(*) over(partition by group_id) cnt from (select id1, id2, id3, row_number() over(order by id1) - id1 as group_id from t) ) where cnt > 1 order by id1; 查询结果: ID1 ID2 ID3 ---- ---- ---- 1 45 89 2 45 89 3 45 89 22 45 89 23 45 89 89 45 89 90 45 89 91 45 89 92 45 89
3、需求2的实现方法:
select min(id1), max(id1), count(*) from (select id1, id2, id3, row_number() over(order by id1) - id1 as group_id from t) having count(*) > 1 group by group_id order by 1; 查询结果: MIN(ID1) MAX(ID1) COUNT(*) ---------- ---------- ---------- 1 3 3 22 23 2 89 92 4
5、高频数获取
原始数据查询结果:
SELECT sal,COUNT(*) repeat_num FROM emp GROUP BY sal; 查询结果: SAL REPEAT_NUM ---------- ---------- 1000.00 1 4000.00 4 --4000这个数值出现了4次,出现频率最高 2000.00 1 8000.00 1 7000.00 1
普通写法查找:
select sal from (select sal, count(*) as repeat_num from emp group by sal) t where t.repeat_num = (select max(repeat_num) from (select sal, count(*) as repeat_num from emp group by sal)); 查询结果: SAL ---------- 4000.00
分析函数查找:
select sal from (select sal, rank() over(order by repeat_num desc) rank_repeat_num from (select sal, count(*) repeat_num from emp group by sal) ) where rank_repeat_num = 1; 查询结果: SAL ---------- 4000.00

 浙公网安备 33010602011771号
浙公网安备 33010602011771号