


机器学习九-聚类
1 聚类
聚类是无监督学习,聚类试图将样本划分为若干个不想交的子集,每个子集称为簇。常见的无监督学习除了聚类还有密度估计、异常检测等。
聚类既可以寻找数据内在分布结构,也可以作为分类任务的前驱。
2 性能度量
聚类性能度量即聚类“有效性指标”(validity index),聚类希望的结果是“簇间相似度低”而 “簇内相似度”高。
聚类的性能度量大致分两类:
外部性能指标:聚类结果和某个reference model比较
内部性能指标:直接考察聚类结果
对数据集![]() ,通过聚类簇划分C={C1,C2,…Ck},参考模型C*={ C1*,C2*,…Ck*
}。令λ与λ*表示簇标记向量。将样本两两配对:
,通过聚类簇划分C={C1,C2,…Ck},参考模型C*={ C1*,C2*,…Ck*
}。令λ与λ*表示簇标记向量。将样本两两配对:
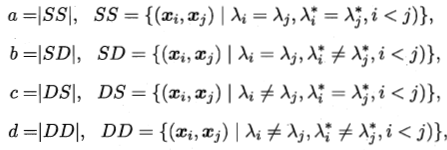
其中a+b+c+d = m(m-1)/2,常用的聚类性能外部指标:


上述性能度量值域[0,1],越大越好
考虑聚类簇划分C={C1,C2,…Ck},定义
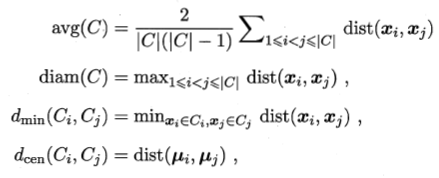
dist()计算样本间距离,μ代表簇中心点,avg(C)代表簇C的平均距离,diam(C)对应簇C的最远距离,dmin(ci,cj)对应簇Ci和Cj最近样本距离,dcen(Ci,Cj)对应簇Ci和Cj中心距离
常用聚类性能度量内部指标:

DBI越小越好,DI越大越好
3 距离计算
函数dist()基本性质:
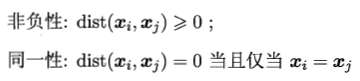
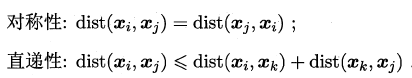
对于有序属性,常用的是闵可夫斯基距离
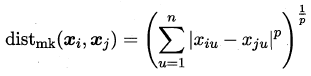
p=2 是欧氏距离
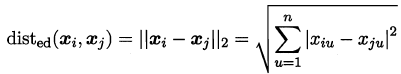
p=1时候曼哈顿距离:
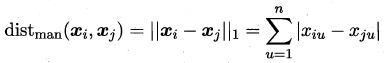
属性:我们将属性分为连续属性和离散属性。前者在定义域上取值无数,后者取值有限个。在距离计算时,属性上是否定义了序很重要。连续属性和离散属性对于有序属性在计算距离的时候的性质较为相似,例如{1,2,3}和[1,3];然而{飞机,火车,轮船}这样无序属性无法直接计算距离,对于无序属性可采用VDM距离,mu,a,i表示第i个样本簇在属性U上取值为a的样本数。k为样本簇数,则属性u上的两个离散值a,b的VDM距离:
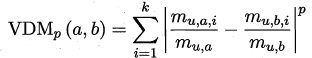
混合属性,假设有nc个有序属性,n-nc个无序属性,则:
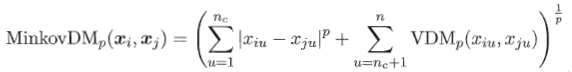
如果属性重要性不同,可使用“加权距离”:
![]()
4 原型聚类
此类算法假设聚类结构能通过一组原型刻画,通常先对算法进行初始化,然后进行迭代更新。常用的原型聚类算法如下:
(1)k均值算法
根据样本集D={x1,x2,…xm}所得簇划分C={C1,C2…CK}最小化平方误差
![]()
其中,![]() 是Ci的均值向量
是Ci的均值向量
直观来看,k均值反映了样本的紧密程度,E越小簇内相似度越高。最小化该式是一个NP难题,因此k均值算法采用了贪心策略,通过迭代优化近似求解。

(2)学习向量量化
假设数据样本带有类别标记,学习过程利用样本信息辅助聚类。
LVQ的目标是学得一组n维原型向量{p1,p2…pq}代表一个聚类。

其中最关键的是第6-10行更新原型向量。对于样本xj,如果与最近的原型向量pi*标记相同,则令pi*向xj方向靠拢,新的原型向量为
![]()
p’与xj的距离为
![]()
学习率![]() ,则原型向量更新后更靠近xj,同理,如果pi*与xj标记不同,则更新后远离xj.
,则原型向量更新后更靠近xj,同理,如果pi*与xj标记不同,则更新后远离xj.
(3)高斯混合聚类
它与k均值、LVQ刻画聚类结构不同,高斯混合聚类采用概率模型表达原型。
对n维样本空间![]() 中的随机向量x,若x服从高斯分布,其概率密度函数为
中的随机向量x,若x服从高斯分布,其概率密度函数为
![]()
其中u是n维均值向量,![]() 是n * n的协方差矩阵,将概率密度函数记为
是n * n的协方差矩阵,将概率密度函数记为![]() .
.
定义高斯混合分布
![]()
该分布由k个混合成分组成,每个混合成分对应一个搞死分布,其中μi与
![]() 是第i个混合成分的参数,
是第i个混合成分的参数,![]() 为相应的“混合系数”,
为相应的“混合系数”,![]()



