《深入浅出Node.js》第3章 异步I/O
@by Ruth92(转载请注明出处)
第3章 异步I/O
-
Node 的基调:异步 I/O、事件驱动、单线程。
-
Node 不再是一个服务器,而是一个可以基于它构建各种高速、可伸缩网络应用的平台。
-
Node 是全方位的,既可以作为服务端去处理客户带来的大量并发请求,也能作为客户端向网络中的各个应用进行并发请求。
-
Web → 网,Node → 网络中灵活的节点
-
事件循环是异步实现的核心,它与浏览器中的执行模型基本保持了一致。Node 正是依靠构建了一套完善的高性能异步 I/O 框架,打破了 JavaScript 在服务器端止步不前的局面。
一、为什么要异步 I/O
-
用户体验
☋ 前端异步的必要性:
- 在浏览器中 JavaScript 在单线程上执行,且与 UI 渲染共用一个线程。即,JavaScript 在执行的时候 UI 渲染和响应是处于停滞状态的。
- 而采用异步请求,如在下载资源期间,JavaScript 和 UI 的执行都不会处于等待状态,页面可以继续响应用户的交互行为。
☊ 后端异步的必要性:
- 前端通过异步可以消除掉 UI 阻塞的现象,但是前端获取资源的速度也取决于后端的响应速度,I/O 很昂贵,因此异步 I/O 是必要的。
-
资源分配
□ 单线程串行依次执行
- 缺点:性能问题,任意一个略慢的任务都会导致后续执行代码被阻塞,如 I/O 的进行会让后续任务等待,这种同步编程模型会导致资源不能被更好地利用。
- 优点:易于表达,符合编程人员按顺序思考的思维方式。
□ 多线程并行完成
- 缺点:(1)创建线程和执行期线程上下文切换的开销较大;(2)在复杂的业务中,多线程编程经常面临锁、状态同步等问题。
- 优点:在多核 CPU 上能够有效提升 CPU 的利用率。
☛ Node 在两者之间给出了解决方案:
(1)利用单线程,远离多线程死锁、状态同步等问题;
(2)利用异步 I/O,当单线程远离阻塞,以更好地使用 CPU。
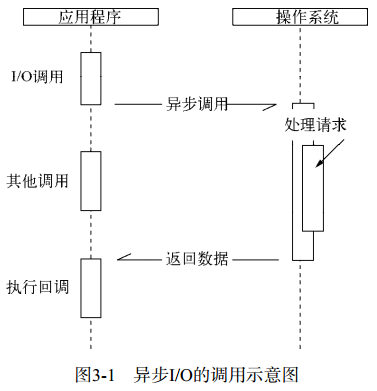
![图3-1 异步I/O的调用示意图]()
二、异步 I/O 的实现现状
-
异步 I/O 与非阻塞 I/O
操作系统内核对于 I/O 只有两种方式:阻塞与非阻塞。
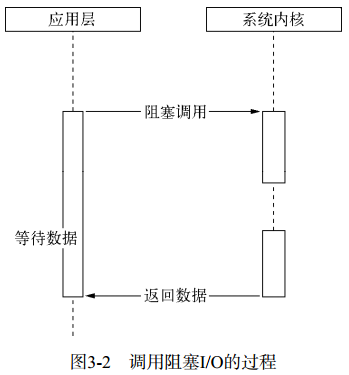
① 阻塞 I/O:调用之后一定等到系统内核层面完成所有操作后,调用才结束。
- 缺点(CPU 等待浪费):造成 CPU 等待 IO,浪费等待时间,且 CPU 的处理能力得不到充分利用;
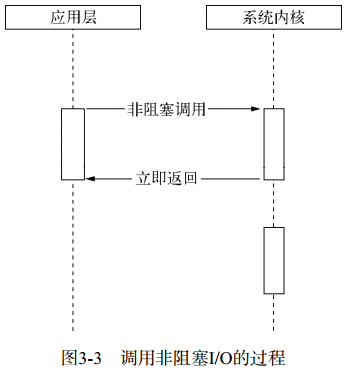
② 非阻塞 I/O:不带数据直接返回,要获取数据,还需要通过文件描述符再次读取。
- 缺点(CPU 资源浪费):1)由于完整的 I/O 并没有完成,立即返回的并不是业务层期望的数据,而仅仅是当前调用的状态。2)然后需要轮询去确认是否完成数据获取,它会让 CPU 处理判断状态,是对 CPU 资源的浪费。
☛ 轮询:在非阻塞 I/O 中,为了获取完整的数据,应用程序需要重复调用 I/O 操作来确认是否完成。这种重复调用判断操作是否完成的技术就叫做轮询。
- 现存的轮询技术:1)read;2)select;3)poll;4)epoll(最佳);5)kqueue
- 轮询技术不够好的原因:对于应用程序而言,仍然只能算是一种同步,因为应用程序仍然需要等待 I/O 完全返回,依旧花费了很多时间来等待。
![图3-2 调用阻塞IO的过程]()
![图3-3 调用非阻塞IO的过程]()
-
理想的非阻塞异步 I/O
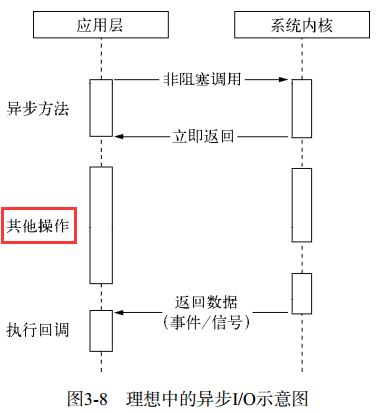
☛ 理想的异步 I/O:在应用程序发起非阻塞调用,无须通过遍历或者事件唤醒等方式轮询,可以直接处理下一个任务,只需在 I/O 完成后通过信号或回调将数据传递给应用程序即可。
![图3-8 理想中的异步IO示意图]()
-
现实的异步 I/O
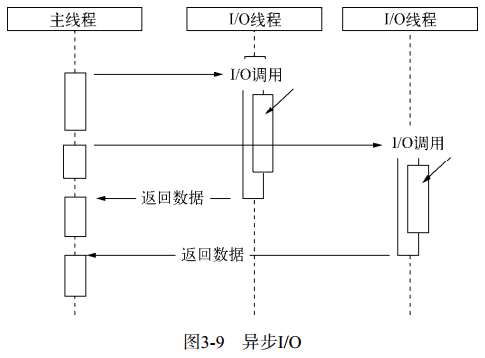
☛ 现实的异步 I/O:(模拟)采用多线程方式,通过让部分线程进行阻塞 I/O 或非阻塞 I/O 加轮询技术来完成数据获取,让一个线程进行计算处理,通过线程之间的通信将 I/O 得到的数据进行传递。
![图3-9 异步IO]()
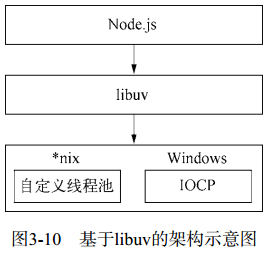
![图3-10 基于libuv的架构示意图]()
注意:我们时常提到 Node 是单线程的,这里的单线程仅仅只是 JavaScript 执行在单线程中罢了。在 Node 中,无论是 *nix 还是 Windows 平台,内部完成 I/O 任务的另有线程池。
三、Node 的异步 I/O
-
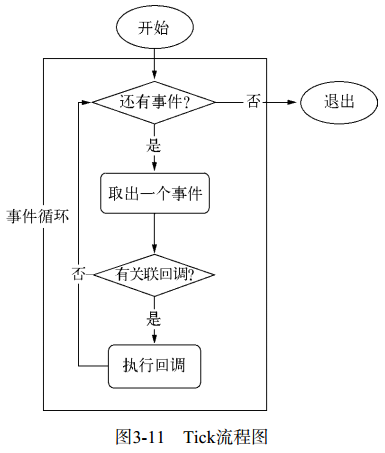
事件循环
事件循环是一个典型的
生产者/消费者模型。异步I/O、网络请求等则是事件的生产者,源源不断为 Node 提供不同类型的事件,这些事件被传递到观察者那里,事件循环则从观察者那里取出事件并处理。![图3-11事件循环(Tick)示意图]()
-
观察者
- 一个观察者可能有多个事件;
- 每个事件都有对应的观察者;
- 观察者对事件进行了分类。
-
请求对象
-
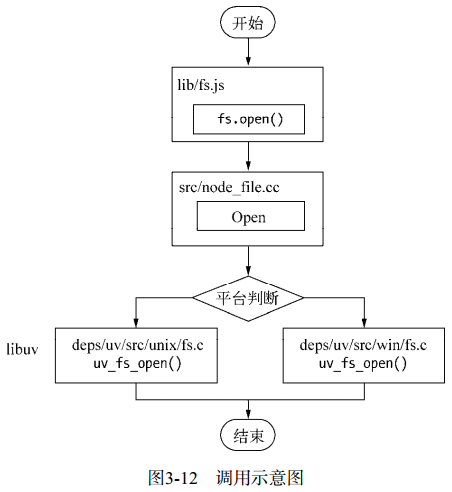
请求对象:从 JavaScript 发起调用到内核执行完 I/O 操作的过渡过程中,存在的一种中间产物。
-
Node 的经典调用方式:从 JavaScript 调用 Node 的核心模块,核心模块调用 C++ 内建模块,内建模块通过 libuv 进行系统调用。
-
请求对象是异步 I/O 过程中的重要中间产物,所有状态都保存在这个对象中,包括送入线程池等待执行 I/O 操作后的回调处理。
![图3-12调用示意图]()
-
-
执行回调
![图3-13 整个异步IO的流程]()
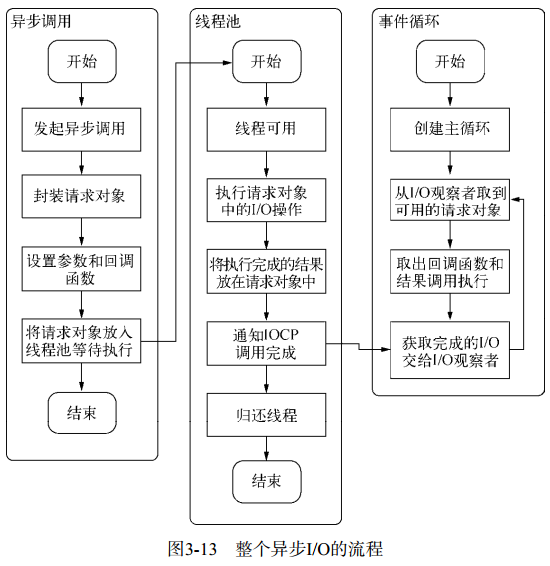
☛ 小结:
构成 Node 异步 I/O 模型的四个基本要素:事件循环、观察者、请求对象、I/O线程池。
除了 JavaScirpt 是单线程外,Node 自身其实是多线程的,只是 I/O 线程使用的 CPU 较少。
注意:除了用户代码无法并行执行外,所有的 I/O (磁盘 I/O 和网络 I/O等)则是可以并行的。
四、非 I/O 的异步 API
-
定时器:
setTimeout()、setInterval()缺点:1)精确度不够;2)需要动用红黑树,创建定时器对象和迭代等操作;3)较为浪费性能。
-
process.nextTich()- 每次调用
process.nextTich()方法,只会将回调函数放入队列中,在下一轮 Tick 时取出执行; - 与定时器相比,较为轻量,更高效。
- 每次调用
-
setImmediate()process.nextTick()中的回调函数执行的优先级要高于setImmediate()- 原因:时间循环对观察者的检查是有先后顺序的,在每一轮循环检查中,idle 观察者(
process.nextTick()) > I/O 观察者 > check 观察者(setImmediate())
- 原因:时间循环对观察者的检查是有先后顺序的,在每一轮循环检查中,idle 观察者(
- 在具体实现上,
process.nextTick()的回调函数保存在一个数组中,setImmediate()的结果保存在链表中; - 在行为上,
process.nextTick()在每轮循环中会将数组中的回调函数全部执行完,setImmediate()在每轮循环中执行链表中的一个回调函数。
五、事件驱动与高性能服务器
☛ 事件驱动的实质:通过主循环加事件触发的方式来运行程序。
☛ Node 高性能的原因:
- Node 通过事件驱动的方式处理请求,无须为每一个请求创建额外的对应线程,可以省掉创建线程和销毁线程的开销;
- 同时操作系统在调度任务时因为线程较少,上下文切换的代价很低。
- 这使得服务器能够有条不紊地处理请求,即使在大量连接的情况下,也不受上下文切换开销的影响。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号