《JavaScript Ninja》之正则表达式
正则表达式 是一个拆分字符串并查询相关信息的过程。
练习网站:JS Bin
正则表达式进修
正则表达式通常被称为模式,是一个用简单方式描述或匹配一系列符合某个句法规则的字符串。
创建正则表达式的两种方法:
(1)通过正则表达式字面量(推荐);
var pattern = /test/;
就像字符串是用引号进行界定一样,正则字面量是用 正斜杠 进行界定的。
(2)通过构造 RegExp 对象的实例。
var patter = new RegExp("test");
* 在开发中,如果正则式已知的,则优先选择字面量语法,而构造器方式则是用于在运行时,通过动态构建字符串来构建正则表达式。
正则表达式的3个标志——>这些标志将附加到字面量尾部:
/test/ig,或者作为 RegExp 构造器的第二个字符参数:new RegExp("test","ig"):i:不区分大小写
g:匹配模式中的所有实例
m:允许匹配多个行
术语与操作符
精确匹配:如果一个字符不是特殊字符或操作符,则表示该字符必须在表达式中出现。
/test/:匹配字符串 test
匹配一类字符:匹配一个有限字符集中的某一个字符,可以把字符集放到中括号内,来指定该 字符集(类)操作符。
若想匹配一组有限字符集以外的字符,可以通过在中括号第一个开括号的后面加一个插入符(^)来实现。
字符集的变异操作:制定一个范围。(-)
[abc]:匹配 "a","b","c" 中的任何一个字符
[^abc]:匹配除了 "a","b","c" 以外的任意字符
[a-m]:匹配 "a" 和 "m" 之间的任何一个小写字母
转义:使用反斜杠对任意字符进行转义,让被转义字符作为字符本身进行匹配。(在字符串中使用时,需要对反斜杠进行转义)
\[:匹配 [ 字符
\\:匹配 \ 字符
匹配开始或结束:插入符号(^)表示从字符串的开头进行匹配,美元符号($)表示该模式必须出现在字符串的结尾
这里的插入符号只是 ^ 字符的一个重载,它还可以用于否定一个字符类集。
/^test$/:同时使用^和$,表明指定的模式必须包含整个候选字符串
重复出现:匹配任意数量的相同字符
-
?:在一个字符后面加一个问号,定义为该字符是可选的(可以出现一次或根本不出现)/t?est/:可以匹配 "test" 和 "est" -
+:如果一个字符要出现一次或多次,可以使用加号/t+est/:可以匹配 "test" "ttest" "tttest" -
*:如果一个字符要出现0次或多次,可以使用星号/t*est/:可以匹配 "test" "ttest" "tttest" "est" -
{n}:在字符后面的花括号里指定一个数字来表示重复次数/a{4}/:表示匹配含有连续四个 "a" 字符的字符串 -
{n,m}:在字符后面的花括号里指定两个数字(用逗号隔开),表示重复次数区间/a{4,10}/:表示匹配任何含有连续4个至10个 "a" 字符的字符串 -
{n,}:次数区间的第二个值是可选的(但是要保留逗号),表示一个开区间/a{4,}/:表示匹配任何含有连续4个或多于4个 "a" 字符的字符串
这些重复操作符可以是 贪婪的 或 非贪婪的。默认情况下,它们是 贪婪的:它们匹配所有的字符组合。
在操作符后面加一个问号
?字符(?操作符的一个重载),如a+?,可以让该表达式编程称为 非贪婪的:进行最小限度的匹配。
// 对字符串 "aaa" 进行匹配
/a+/:将匹配所有这三个字符
/a+?/:只匹配一个 a 字符,因为一个 a 字符就可以满足 a+ 术语
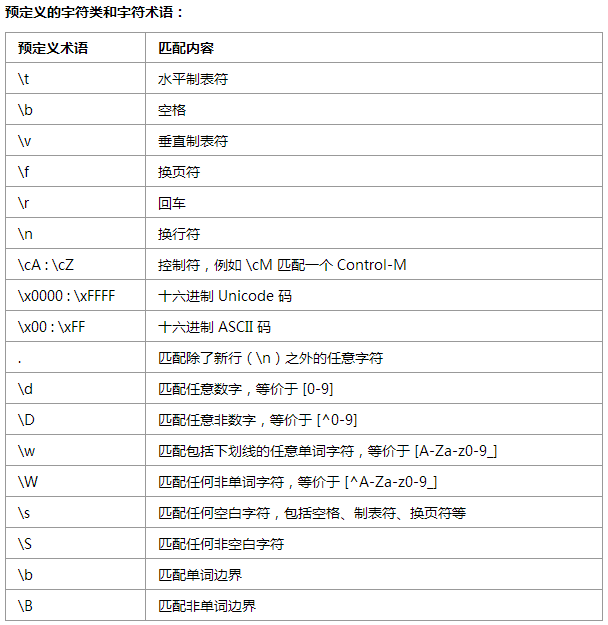
预定义字符类:匹配一些不可能用字面量字符来表示的字符(如像回车这样的控制字符、小数位数或一组空白字符)
分组:如果将操作符应用于一组术语,可以像数学表达式一样在该组上使用小括号
/(ab)+/:匹配一个或多个连续出现的子字符串 "ab"
- 当正则表达式有一部分是用括号进行分组时,它具有双重责任,同时也创建所谓的 捕获。
或操作符(OR):可以用竖线 ( | ) 表示或者的关系。
/a|b/:匹配 "a" 或 "b" 字符
/(ab)+|(cd)+/:匹配出现一次或多次的 "ab" 或 "cd"
反向引用:正则表达式中最复杂的术语是,在正则中所定义的 捕获 的反向引用,将 捕获 作为正则表达式中能够成功匹配术语时的候选字符串。
这种术语表示法是在
反斜杠后面加一个要引用的捕获数量,该数字从1开始,如\1、\2等。
/^([dtn])a\1/:可以任意一个以 "d","t","n" 开头,且后面跟着一个 a 字符,并且再后面跟着的是和第一个捕获相同字符的字符串
不同于 /[dtn]a[dtn]/,a 后面的字符有可能不是 "d" "t" 或 "n" 开头,但这个字符肯定是以触发该匹配的其中一个字符 ("d" "t" 或 "n") 开头。因此,\1 匹配的字符需要在执行的时候才能确定。
编译正则表达式
正则表达式的两个重要阶段:
(1)编译:发生在正则表达式第一次被创建的时候;
(2)执行:发生在我们使用编译过的正则表达式进行字符串匹配的时候。
/*
* 创建编译后正则表达式的两种方式
* 正则表达式在创建之后都处于编译后的状态
*/
var re1 = /test/i; // 通过字面量创建
var re2 = new RegExp("test", "i"); // 通过构造器创建
console.log(re1.toString() == "/test/i"); // true
console.log(re1.test("TesT")); // true
console.log(re2.test("TesT")); // true
console.log(re1.toString() == re2.toString()); // true
console.log(re1 != re2); // true
- 如果将
re1的引用再替换成/test/i字面量,那么同一个正则表达式可能又被编译多次,所以正则表达式只编译一次,并将其保存在一个变量中以供后续使用,这是一个重要的优化过程。
注意:每个正则表达式都有一个独立的对象表示,每次创建正则表达式(也因此被编译),都会为此创建一个新的正则表达式对象。和其他的原始类型不太一样,其结果将永远是独一无二的。
特别重要的一点,用 构造器 创建正则表达式的使用,这种技术允许我们,在运行时通过动态创建的字符串构建和编译一个正则表达式。对于构建大量重用的复杂表达式来说,这是非常有用的。
[例子:]
<div calss="samurai ninja">a</div>
<div class="ninja samurai">b</div>
<div></div>
<span class="samurai ninja ronin">c</span>
<script>
function findClassInElements(className, type) {
var elems = document.getElementsByTagName(type || "*");
/*
* 正则表达式匹配的字符串:
* 要以空字符串或空格开始,
* 而后跟着指定样式名称,
* 并且紧随其后的是一个空白字符或结束字符串
*/
var regex = new RegExp("(^|\\s)" + className + "(\\s|$)");
var results = [];
for (var i = 0, length = elems.length; i < length; i++) {
if (regex.test(elems[i].className)) {
results.push(elems[i]);
}
}
return results;
}
var results1 = findClassInElements("ninja", "div"); // <div class="ninja samurai">b</div>
var results2 = findClassInElements("ninja", "span"); // <span class="samurai ninja ronin">c</span>
var results3 = findClassInElements("ninja"); // <div class="ninja samurai">b</div>
// <span class="samurai ninja ronin">c</span>
console.log(results1.length); // 1
console.log(results2.length); // 1
console.log(results3.length); // 2
</script>
- 在该例子的正则中,要注意
反斜杠(\\)的使用:\\s。创建带有反斜杠字面量正则表达式时,只需要提供一个反斜杠即可。但是,由于我们在字符串中写反斜杠,所以需要双反斜杠进行转义。要明白,我们是用字符串(而不是字面量)来构建正则表达式。
用正则表达式进行捕捉操作
正则表达式的 实用性 表现在捕获已匹配的结果上,这样我们便可以在其中进行处理。
1. 执行简单的捕获 —— match()
-
match()返回的数组的第一个索引的值总是该匹配的完整结果,然后是每个后续捕获结果。 -
记住,捕获是由正则表达式中的小括号所定义。
2. 用全局表达式(/g)进行匹配 —— match() exec()
-
使用
局部正则表达式时,返回的该数组包含了在匹配操作中成功匹配的整个字符串以及其他捕获结果。 -
使用
全局正则表达式时,匹配所有可能的匹配结果,返回的数组包含了全局匹配结果,而不仅仅是第一个匹配结果。
使用 match() 或 exec(),我们总是可以找到想要寻找的精确匹配。
[例子1:]
// 使用 match() 进行全局搜索和局部搜索时的不同
var html = "<div class='test'><b>Hello</b> <i>world!</i></div>";
// 局部正则表达式会返回一个数组,该数组包含了在匹配操作中匹配的整个字符串以及其他捕获结果
var results = html.match(/<(\/?)(\w+)([^>]*?)>/); // 局部正则匹配
console.log(results); // ["<div class='test'>", "", "div", " class='test'"]
console.log(results[0] == "<div class='test'>"); // true
console.log(results[1] == ""); // true
console.log(results[2] == "div"); // true
console.log(results[3] == " class='test'"); // true
// 全局正则表达式返回一个数组,匹配所有可能的匹配结果,而不仅仅是第一个匹配结果
var all = html.match(/<(\/?)(\w+)([^>]*?)>/g); // 全局正则匹配
console.log(all); // ["<div class='test'>", "<b>", "</b>", "<i>", "</i>", "</div>"]
console.log(all[0] == "<div class='test'>"); // true
console.log(all[1] == "<b>"); // true
console.log(all[2] == "</b>"); // true
console.log(all[3] == "<i>"); // true
console.log(all[4] == "</i>"); // true
console.log(all[5] == "</div>"); // true
[例子2:]
// 使用 exec() 方法进行捕获和全局搜索
var html = "<div class='test'><b>Hello</b> <i>world!</i></div>";
var tag = /<(\/?)(\w+)([^>]*?)/g, match;
var num = 0;
while ((match = tag.exec(html)) !== null) {
console.log(match.length); // 4
num++;
}
console.log(num); // 6
3. 捕获的引用
有 两种方法 ,可以引用捕获到的匹配结果:
(1)自身匹配
(2)替换字符串
与反向引用不同,通过调用
replace()方法替换字符串获得捕捉的引用时,使用$1、$2、$3语法表示每个捕获的数字
/*
* 使用反向引用匹配 HTML 标签内容
*/
var html = "<div class='hello'>Hello</b> <i>world!</i>";
var pattern = /<(\w+)([^>]*)>(.*?)<\/\1>/g; // 使用捕获的反向引用
var match = pattern.exec(html); // 在测试字符串上进行匹配
console.log(match); // ["<i>world!</i>", "i", "", "world!"]
console.log(match[0] == "<div class='hello'>Hello</b>"); // false
console.log(match[1] == "b"); // false
console.log(match[2] == " class='hello'"); // false
console.log(match[3] == "Hello"); // false
console.log(match[0] == "<i>world!</i>"); // true
console.log(match[1] == "i"); // true
console.log(match[2] == ""); // true
console.log(match[3] == "world!"); // true
/*
* replace() 方法获得捕捉的引用:使用 $1、$2、$3 语法表示每个捕获的数字
*/
"fontFamily".replace(/([A-Z])/g, "-$1").toLowerCase(); // font-family
4. 没有捕获的分组
小括号的双重责任:(1)进行分组;(2)指定捕获。
-
由于捕获和表达式分组都使用了小括号,所以无法告诉正则表达式处理引擎,哪个小括号是用于分组,以及哪个是用于捕获的。
-
所以会将小括号既视为分组,又视为捕获,由于有时候需要指定一些正则表达式分组,所以会导致捕获的信息比我们预期的还要多。
要让一组括号不进行结果捕获,正则表达式的语法允许我们在开始括号后加一个 ?: 标记,这就是所谓的 被动子表达式。
var pattern = /((?:ninja-)+)sword/;
// 外层小括号 ——> 定义捕获(sword之前的字符串)
// 内层小括号 ——> 针对 + 操作符,对 "ninja-" 文本进行分组
// ?: ——> 只会为外层的括号创建捕获,内层括号被转换为一个被动子表达式
利用函数进行替换
String 对象的 replace 方法:
(1)将正则表达式作为第一个参数,导致在该模式的匹配元素上进行替换。
"ABCDEfg".replace(/[A-Z]/g, "X"); // XXXXXfg,替换所有的大写字母为“X”
(2)(最强大特性)接受一个函数作为替换值,函数的返回值是即将要替换的值。(这样可以在运行时确定该替换的字符串,并掌握大量与匹配有关的信息。)
/*
* 第一个参数:传入完整的字符串
* 第二个参数:捕获结果
*/
function upper(all, letter) {
return letter.toUpperCase();
}
/*
* 函数第一次调用时,传入 "-b" 和 "b"
* 函数第二次调用时,传入 "-w" 和 "w"
*/
"border-bottom-width".replace(/-(\w)/g, upper); // borderBottomWidth
当替换值(第二个参数)是一个函数时,每个匹配都会调用该函数并带有一串参数列表。
- 匹配的完整文本。
- 匹配的捕获,一个捕获对应一个参数。
- 匹配字符在源字符串中的索引。
- 源字符串。
[例子:]
/*
* 让查询字符串转换成另外一个符合我们需求的格式
* 原始字符串:foo=1&foo=2&blah=a&blah=b&foo=3
* 转换成:foo=1,2,3&blah=a,b
*/
function compress(source) {
var keys = {}; // 保存局部键
source.replace(
/([^=&]+)=([^&]*)/g,
function(full, key, value) {
keys[key] = (keys[key] ? keys[key] + "," : "") + value; // 提取键值对信息
/*
* 返回空字符串,因为我们确实不关注源字符串中发生的替换操作
* 我们只需要利用该函数的副作用,而不需要实际替换结果
*/
return "";
}
);
// 收集键的信息
var result = [];
for (var key in keys) {
result.push(key + "=" + keys[key]);
}
// 使用&将结果进行合并
return result.join("&");
}
var origin = "foo=1&foo=2&blah=a&blah=b&foo=3";
compress(origin); // "foo=1,2,3&blah=a,b"
-
一个有趣点:如何使用字符串的
replace()方法来遍历一个字符串,而不是一个实际的搜索替换机制。 -
两个关键点:1)传递一个函数作为替换值参数;2)该函数并不是返回实际的值,而是简单地利用它作为一种搜索手段。
利用这种技巧,我们可以使用
String对象的replace()方法作为字符串搜索机制。搜索结果不仅快速,而且简单、有效。
常用正则表达式
1. 修剪字符串:
// 修剪字符串
function trim(str) {
return (str || "").replace(/^\s+|\s+$/g, "");
}
trim(" #id div.class "); // "#id div.class"
2. 匹配换行符:
// 匹配所有的字符,包括换行符
var html = "<b>Hello</b>\n<i>world!</i>";
// 显示换行符没有被匹配到
console.log(/.*/.exec(html)[0] === "<b>Hello</b>"); // true
// 使用空白符匹配方式匹配所有的元素,为最佳方案
console.log(/[\S\s]*/.exec(html)[0] === "<b>Hello</b>\n<i>world!</i>"); // true
// 用另一种方式匹配所有元素
console.log(/(?:.|\s)*/.exec(html)[0] === "<b>Hello</b>\n<i>world!</i>"); // true
3. Unicode:
// 匹配 Unicode 字符
var text = "\u5FCD\u8005\u30D1\u30EF\u30FC";
var matchAll = /[w\u0080-\uFFFF_-]+/;
text.match(matchAll); // ["忍者パワー"]
4. 转义字符:
// 在 CSS 选择器中匹配转义字符
var pattern = /^((\w+)|(\\.))+$/; // 允许匹配一个单词字符,
// 或一个反斜杠及后面跟随任意字符(甚至是另外一个反斜杠)
// 或者两者都可以匹配
var tests = [
"formUpdate", // true
"form\\.update\\.whatever", // true
"form\\:update", // true
"\\f\\o\\r\\m\\u\\p\\d\\a\\t\\e", // true
"form:update" // false,未能匹配到非单词字符(:)
];
for (var n=0; n<tests.length; n++) {
console.log(pattern.test(tests[n]));
}
参考博文:


 浙公网安备 33010602011771号
浙公网安备 33010602011771号