应用层(四):Web与基于Web的网络应用
1、Web服务的基本概念
万维网WWW(World Wide Web)简称为Web,它是Internet应用技术发展中的一个重要的里程碑。
Web服务的核心技术是:超文本传送协议(Hyper Text Transfer Protocol,HTTP)、超文本标记语言(Hyper Text Markup Language,HTML),超链接(Hyperlink)与统一资源定位符(Uniform Resource Locator,URL)。
用超文本标记语言创建的网页(web page)存储在Web服务器中;用户通过Web客户浏览器进程在Web服务器中的页面以应答报文的方式发送给客户;浏览器在接收到该页面后对其进行解释,最中将图、文、声并茂的画面呈现给用户。用户也可通过页面中的超链接(hyperllink)功能,方便的访问位于其他Web服务器中的页面,或是其他类型的1网络信息资源。
1.1、主页的概念
主页(home page)是一种特殊的Web页面。通常主页是指包含个人或机构基本信息的页面,用于对个人或机构进行综合性介绍,是访问个人或机构详细信息的入口。主页一般包含以下基本元素。
·文本(text):文字信息
·图像(image):GIF与JPEG图像
·表格(table):类似于Word的字符型表格
·超链接(hyperlink):用于与其他主页的链接。
1.2、URL的基本概念
URL是对Internet资源的位置和访问方法的标识。
标准的URL由协议类型、主机名和路径及文件名三个部分组成。

其中,"http"指出要是用协议的类型,"www.nankai.edu.cn"指出要访问服务器的主机名,"index.html"指出要访问的主页的路径与文件名。除了通过指定Web服务器之外,URL还可以指定其他的协议、服务器与文档。
2、超文本传输协议
2.1、超文本传输协议(HTTP)的基本特点
HTTP是Web浏览器与服务器交换请求与应答报文的通信协议。
2.1.1、无状态协议
HTTP协议在传输层使用的是TCP协议,即使同一个Web浏览器在几秒钟之内两次访问同一个Web服务器,它也必须要分别建立两次TCP连接。
2.1.2、非持续连接(短连接)与持续连接(长连接)
若客户向服务器发出多个服务请求报文,服务器需要对每一个请求报文进行应答,并为每一个应答过程建立一个TCP连接的工作方式称为非连续连接(nonpersistent connection);多个客户与服务器的请求报文与应答报文都可以通过一个TCP连接来完成的工作方式称为持续连接(persistent connection)。
HTTP既可以使用非持续连接,也可以使用持续连接。HTTP1.0默认状态是非持续连接,HTTP1.1默认为持续连接。
2.1.3、非流水线与流水线
持续连接有两种工作方式:非流水线(without pipelining)与流水线(pipelining)。
非流水线方式的特点是:客户端只有在接收到前一个响应时才能发出新的请求,客户端在每访问一个对象时要花费1个RTT时间。这是服务器每发送一个对象之后,要等待下一个请求的到来,连接处于空闲状态,浪费了服务器的资源。
流水线方式的特点是:客户端在没有收到前一个响应时就能够发出新的请求。客户端的请求可以像流水线作业一样,连续的发送到服务器端,服务器端可以连续的发送应答报文。使用流水线方式的客户端访问所有的对象只需花费1个RTT时间。因此,流水线方式可减少TCP连接的空闲耗时间。HTTP1.1默认状态是持续连接的流水线工作方式。
2.2、HTTP报文格式
2.2.1、HTTP报文的基本概念
HTTP是一种使用简单的请求报文与应答报文交互的协议。
2.2.2、HTTP协议请求报文结构
HTTP请求与应答的工作过程:

作为HTTP客户端的Web浏览器向Web服务器发送请求报文。
Web浏览器发送请求报文的意图在于查询一个Web页面的可用性,并从Web服务器中读取该页面。请求报文由4部分组成:请求行(request line)、报头(header)、空白行(blank line)和正文(body)。空白行用CR和LF表示,表示报头部分的结束。
正文部分可以是空着,也可以包含要传送到服务器的数据。
请求报文的发送过程与结构:

请求行是请求报文中的重要组成部分,包括三个字段:方法、URL与HTTP版本。
"方法"用于表示浏览器发送给服务器的操作请求,服务器必须按照这些请求来为客户提供服务。
2.2.3、HTTP应答报文结构

HTTP应答报文结构。应答报文包括三个部分:状态行、报头与正文。其中,状态行又包括HTTP版本、状态码和状态短语三个字段。
HTTP工作原理示意图:

3、超文本标记语言
超文本标记语言(HTML)用于创建网页的语言,Web文档是由HTML元素相互嵌套而成。
Web文档可分为三种类型:静态文档、动态文档与活动文档。
1、静态文档是固定的文档,有服务器创建并保存在服务器。Web客户端只能得到文档的副本。当Web客户端访问静态文档时,文档的一个副本就发送到客户端并显示。
2、动态文档不存在预定义的格式,它是在用户浏览器请求该文档时才有服务器创建;
3、在某些情况下,需要在Web浏览器产生动画图形,或者需要与用户交互的程序,应用程序需要在客户端运行。当用户请求该文档时,服务器就将以二级智能会代码形式的活动文档发送给浏览器。Web浏览器收到该活动文档后,存储并运行该程序。
4、Web浏览器
Web浏览器(browser)的功能是实现客户进程与指定URL的服务器进程的连接,发出请求报文,接收需要浏览的文档,向用户显示网页的内容。
Web浏览器的结构:
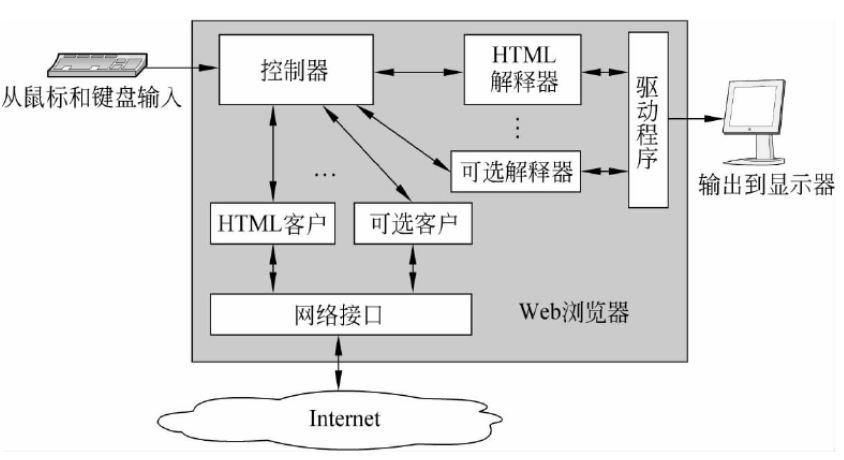
Web浏览器由一组客户、一组解释单元与一个管理他们的控制器组成。控制器是浏览器的核心部件,负责解释鼠标和键盘的输入,并调用其他组件来执行用户指定的操作。
Web工作原理示意图:

当客户从IP地址为190.10.2.16主机的浏览器访问IP地址为212.25.15.180的Web服务器时,HTTP的交互过程为:
报文1~3位客户浏览器进程与Web服务器进程建立TCP连接的三次握手报文;
报文4是浏览器程序向服务器程序发出GET HTTP/1.1命令,请求Web服务器主页。报文5是应答报文。报文6~8是Web服务器程序向客户浏览器程序传输主页的内容。报文9是对传送主页内容的应答报文。
报文10是浏览器程序继续向Web服务器程序发出GET img/test.jpg HTTP1.1命令,请求test.jpg文件。报文12~15是Web服务器向浏览器发送test.jpg文件。
5、搜索引擎
搜索引擎(search engine)是运行在Web上的应用软件系统,以一定的策略在Web系统中搜索和发现信息,对信息进行理解、提取、组织和处理。
搜索引擎可分为两类:目录导航式搜索引擎与网页搜索引擎。
目录导航式搜索引擎又称目录服务,对目录的查询可根据目录类的树状结构,依次点击一层层区查询。主要功能做是编制目录类的树状结构,以及确定检索方法。
5.1、搜索引擎的基本工作原理与结构
当用户在使用搜索引擎时,首先要提交一个或多个"关键字"(或检索词),通过浏览器输入搜索引擎的界面。搜索页引擎返回与"关键字"相关的信息列表,通常包括三个方面内筒:标题、URL、摘要。
5.1.1、搜索引擎的结构
搜索引擎技术起源于传统的全文检索理论。全文检索程序通过扫描一篇文章中的所有词语,并根据检索词在文章中出现的频率和概率,对所有包含这些检索词的文章进行排序,最终给出可以提供给客户的列表。
基于全文搜索的搜索引擎通常包括4个部分:搜索器、索引器、检索器与用户接口。
·搜索器
搜索引擎通过搜索器在Internet上逐个访问Web站点,并建立一个网站的关键字了列表,将搜索器建立关键字列表的过程称为"爬行"。
搜索器要根据一个实现指定的策略确定一个URL列表,这个列表通常是从以前的访问记录中提取的,热门站点和包含新信息的站点。
搜索器访问每个Web站点之后,需要分析与提取新的URL,并将它加入访问列表中。搜索器遍历指定的Web空间,将采集到的网页信息添加到数据库。
搜索策略可以有两种基本类型:一种是从一个起始的URL集出发,顺着这些URL中的超链接,以深度优先或宽度优先,以及启发式循环的发现新的信息。另一种方法是将Web空间按照域名、IP地址划分,每个搜索器负责对一个子域进行遍历搜索。
·索引器
索引器的功能是理解搜索器获取的信息,进行分类并建立索引,存放到索引数据库或目录数据库中。
索引项可分为两种:客观索引项与内容索引项。
用户查询过程只能对索引进行检索,而不是对原始数据进行检索。索引器在建立索引时,需要为每个关键字赋予一个等级值或权重,表示该网页的内容与关键词的符合程度。
当用户输入一个或一组关键词时,搜索器按照等级值由高到低排序,将排序的结果提供给用户。因此,检索结果是否符合用户的需求,取决于索引器确定关键字及权重的策略。
·检索器
检索器的功能是根据用户输入的搜索关键字,在索引库中快速检索出文档。根据用户输入的查询条件,对搜索结果的文档与查询的相关度或等级高的排在前面,将相关度等级低的排在后面。
·用户接口
用户接口用于输入查询要求,显示查询结果,提供用户反馈意见。
用户接口可分为两类:简单接口 与 复杂接口。
简单接口只提供用户输入关键字界面,而复杂用户接口可以对用户输入条件进行限制,如进行简单的与、或、非等逻辑运算,以及相近关系、范围限制,以为提高搜索结果的有效性。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号