
WordCount优化
github地址:
https://github.com/Hoyifei/SQ-T-Homework-WordCount-Advanced
psp表格:
|
PSP2.1 |
PSP阶段 |
预估耗时(分钟) |
实际耗时(分钟) |
|
Planning |
计划 |
20 |
30 |
|
· Estimate |
· 估计这个任务需要多少时间 |
10 |
20 |
|
Development |
开发 |
400 |
480 |
|
· Analysis |
· 需求分析 (包括学习新技术) |
60 |
80 |
|
· Design Spec |
· 生成设计文档 |
20 |
40 |
|
· Design Review |
· 设计复审 (和同事审核设计文档) |
30 |
40 |
|
· Coding Standard |
· 代码规范 (为目前的开发制定合适的规范) |
10 |
10 |
|
· Design |
· 具体设计 |
60 |
60 |
|
· Coding |
· 具体编码 |
500 |
480 |
|
· Code Review |
· 代码复审 |
60 |
90 |
|
· Test |
· 测试(自我测试,修改代码,提交修改) |
200 |
220 |
|
Reporting |
报告 |
100 |
120 |
|
· Test Report |
· 测试报告 |
50 |
60 |
|
· Size Measurement |
· 计算工作量 |
20 |
20 |
|
· Postmortem & Process Improvement Plan |
· 事后总结, 并提出过程改进计划 |
30 |
30 |
|
|
合计 |
1570 |
1780 |
本次我负责的代码在src/com/wordcount/Main.java和WordCounter.java
在Main函数中 我主要对参数进行了判断处理:
如果少于一个,报错退出
当多余一个时,给出警告并提示将忽略其他参数
当处理的文件扩展名并非txt时,给出警告,但仍然执行
之后通过调用Splitter对文件进行分词统计并实现回调函数将结果输入统计模块
从统计模块获取结果并输入到result.txt,若发生错误,则给出警告并将结果输出到控制台
使用接口:
WordSplitterCallback
WordSplitter:constructor split()
Trie:curWordAppendChar() curWordEnd()
sortWords() getWord()
TrieNode: getCount()
接口具体实现:
使用正则表达式判断输入的文件是否以.txt 结尾
WordSplitterCallback:在构造函数中建立一个Trie,之后在回调函数中调用相应的操作
从Trie的排序结果中获取最多前100,转换成string的形式,组织成word-Count pair数组
代码如下:


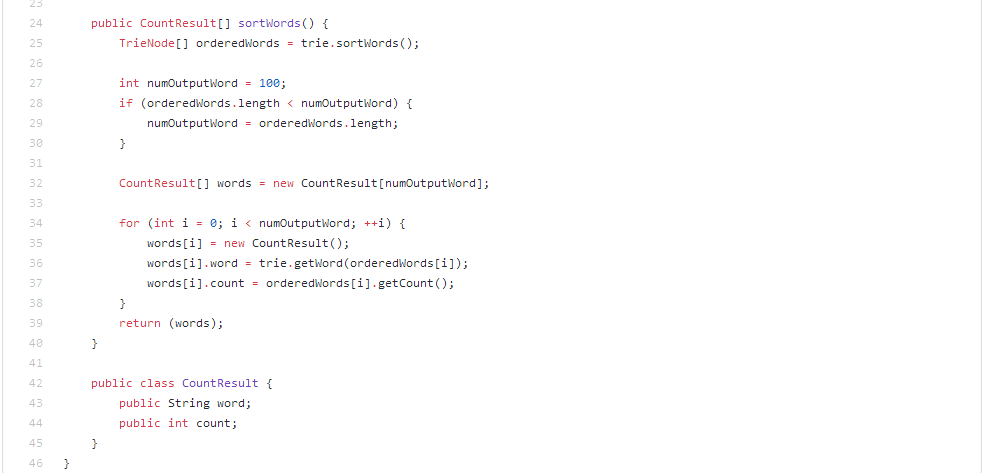
测试用例:
本模块依赖于Trie和WordSplitter模块,因此没有进行单独测试
对于运行参数的处理进行了手工运行的测试 ,对程序整体的测试包含5个手工编写文件(case1-case5)以及15个·随机生成的较大的文件(case6-case20)
其中五个手工编写的文件如下:
case1:普通的英语文章,用于测试基本功能

case2:有大量词频相同的词语,用于测试词频相同时的排序结果
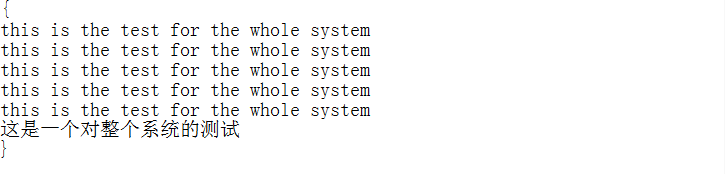
case3:有词频相同的单词和含有数字的单词

case4:这是一个空文件。。。
case5:有非法字符出现,单词末的连接符和连续的连接符等情况

其余15个随机生成的较大文件在此不一一列举
最终测试结果如下:
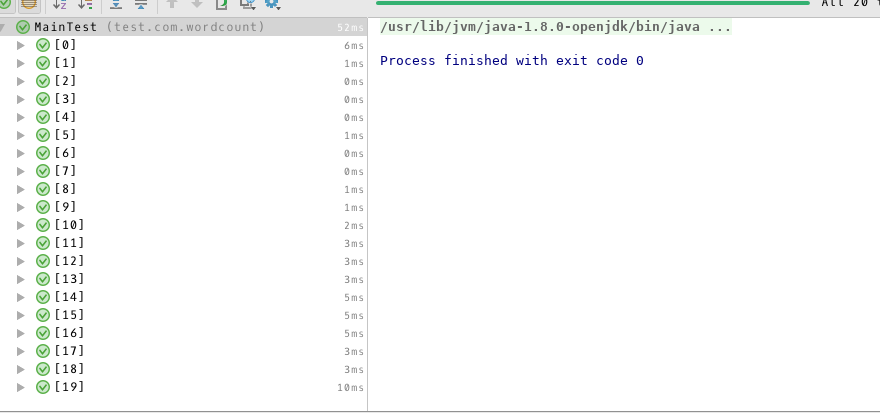
测试评价:
所有的测试案例都通过了测试,被测模块质量水平较高。
开发规范说明:
我选取的是谷歌java编程风格指南中的规则
通过对我代码的评审,我发现大部分的代码符合规范,主要不符合的有:
在类内连续的成员之间(字段,构造函数,方法,嵌套类,静态初始化块,实例初始化块)需使用空格
大括号与if, else, for, do, while语句一起使用,即使只有一条语句(或是空),也应该把大括号写上
参考文献:https://blog.csdn.net/zen99t/article/details/50763231
静态代码扫描:
扫描工具:Checkstyle
扫描截图:
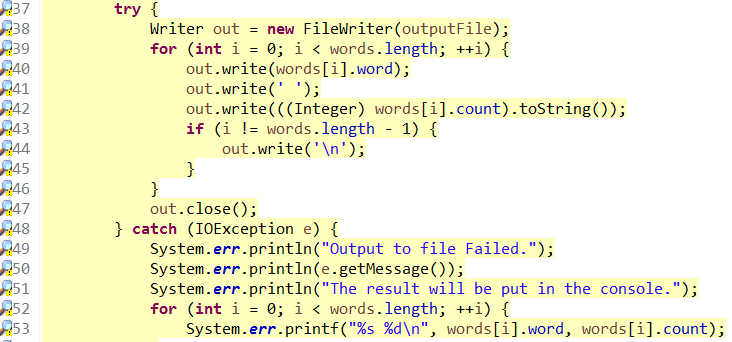
安装静态检查插件后,编码过程中IDE实时给出了提示,因此最终没有统计数据,但是代码基本符合代码规范
性能测试:
我们进行了性能测试,具体结果参见组员高阳的博客,这里不再赘述。
高阳博客链接:http://www.cnblogs.com/dilidiligy/
小组小结:
本次软件测试结果还算让人满意,软件测试也是软件质量的重要保证。

