python高级应用程序设计任务
一、主题式网络爬虫设计方案(15分)
1.主题式网络爬虫名称
58招聘网站爬虫
2.主题式网络爬虫爬取的内容与数据特征分析
2.主题式网络爬虫爬取的内容与数据特征分析
爬取58同城上面发布的职位信息,分析不同城市,不同岗位的学历要求
3.主题式网络爬虫设计方案概述(包括实现思路与技术难点)
3.主题式网络爬虫设计方案概述(包括实现思路与技术难点)
爬取58招聘当中不同城市不同岗位所需各种学历人才数的通过分析其网页特征来使用python代码切换不同的城市页面,再通过BeautifulSoup库获取其网页标签内的内容来爬取我们所需要的数据,之后保存进csv表格内,再通过提取出不同城市不同岗位所需各种学历人才数进行绘制柱状图。
技术难点:58招聘的内容较多,在分析其网页结构可能会比普通的求职网站要来得复杂一些,并且注意识别其中一些广告内容。
二、主题页面的结构特征分析(15分)
1.主题页面的结构特征
58招聘网站中的城市与网页地址中的头两个字母有关,通过使用不同的城市中文拼音简写来实现切换不同的城市页面

三、网络爬虫程序设计(60分)
爬虫程序主体要包括以下各部分,要附源代码及较详细注释,并在每部分程序后面提供输出结果的截图。
爬虫程序主体要包括以下各部分,要附源代码及较详细注释,并在每部分程序后面提供输出结果的截图。
import matplotlib.pyplot as plt import requests import csv import pandas as pd from bs4 import BeautifulSoup #数据响应 def getHTMLText(): url = 'https://%s.58.com/ruanjiangong/?PGTID=0d202408-0012-321e-c0b2-77ddf4e60b9f&ClickID=1' %cityname try: r=requests.get(url,timeout=30) r.raise_for_status() r.encoding=r.apparent_encoding return r.text except: return'产生异常' #数据爬取 def get_data(): html = getHTMLText() soup = BeautifulSoup(html, 'html.parser') csv_file = open('D:\\pachong.csv', 'a', newline='') writer = csv.writer(csv_file) writer.writerow(['城市', '学历', '经验', '职位']) chengshi=soup.select('#filterArea > ul > li.select > a')[0].text for li in soup.find_all('li', class_='job_item clearfix'): try: xueli = li.find('span', class_="xueli") jingyan = li.find('span', class_='jingyan') job = li.find('span', class_='cate') writer.writerow([ chengshi,xueli.text, jingyan.text, job.text]) except OSError: pass continue print("保存成功") #绘制组合柱状图 def picture(): df = pd.read_csv(r'D:\pachong.csv', encoding="gbk") #爬取泉州地区各个学历聘取人数 qz1 = df[df['城市'].str.contains("全泉州")] a1 = qz1.loc[qz1["学历"] == "大专"]["学历"].count() a2 = qz1.loc[qz1["学历"] == "本科"]["学历"].count() a3 = qz1.loc[qz1["学历"] == "不限"]["学历"].count() # 爬取厦门地区各个学历聘取人数 xm1 = df[df['城市'].str.contains("全厦门")] b1 = xm1.loc[xm1["学历"] == "大专"]["学历"].count() b2 = xm1.loc[xm1["学历"] == "本科"]["学历"].count() b3 = xm1.loc[xm1["学历"] == "不限"]["学历"].count() # 爬取福州地区各个学历聘取人数 fz1 = df[df['城市'].str.contains("全福州")] c1 = fz1.loc[fz1["学历"] == "大专"]["学历"].count() c2 = fz1.loc[fz1["学历"] == "本科"]["学历"].count() c3 = fz1.loc[fz1["学历"] == "不限"]["学历"].count() # 爬取杭州地区各个学历聘取人数 hz1 = df[df['城市'].str.contains("全杭州")] d1 = hz1.loc[hz1["学历"] == "大专"]["学历"].count() d2 = hz1.loc[hz1["学历"] == "本科"]["学历"].count() d3 = hz1.loc[hz1["学历"] == "不限"]["学历"].count() # 爬取上海地区各个学历聘取人数 sh1 = df[df['城市'].str.contains("全上海")] e1 = sh1.loc[sh1["学历"] == "大专"]["学历"].count() e2 = sh1.loc[sh1["学历"] == "本科"]["学历"].count() e3 = sh1.loc[sh1["学历"] == "不限"]["学历"].count() # 爬取北京地区各个学历聘取人数 bj1 = df[df['城市'].str.contains("全北京")] f1 = bj1.loc[bj1["学历"] == "大专"]["学历"].count() f2 = bj1.loc[bj1["学历"] == "本科"]["学历"].count() f3 = bj1.loc[bj1["学历"] == "不限"]["学历"].count() plt.rcParams['font.sans-serif'] = ['SimHei'] plt.rcParams['font.family'] = 'sans-serif' plt.figure(figsize=(10,6)) citys=['泉州','厦门','福州','杭州','上海','北京'] #招聘城市 dazhuang=[a1,b1,c1,d1,e1,f1] #大专招聘人数 benke=[a2,b2,c2,d2,e2,f2] #本科招聘人数 buxian=[a3,b3,c3,d3,e3,f3] #不限招聘人数 x=list(range(len(dazhuang))) total_width,n=0.8,3#设置间距 width=total_width/n #在偏移间距位置绘制柱状图1 for i in range(len(x)): x[i]-=width plt.bar(x,dazhuang,width=width,label='大专',fc='teal') #设置数字标签 for a,b in zip(x,dazhuang): plt.text(a,b,b,ha='center',va='bottom',fontsize=10) #在偏移间距位置绘制柱状图2 for i in range(len(x)): x[i]+=width plt.bar(x,benke,width=width,label='本科',tick_label=citys,fc='darkorange') for a,b in zip(x,benke): plt.text(a,b,b,ha='center',va='bottom',fontsize=10) #在偏移间距位置绘制柱状图3 for i in range(len(x)): x[i]+=width plt.bar(x,buxian,width=width,label='不限',fc='lightcoral') for a,b in zip(x,buxian): plt.text(a,b,b,ha='center',va='bottom',fontsize=10) plt.show() if __name__ == '__main__': all_city=['qz','xm','fz','hz','sh','bj'] for cityname in all_city: getHTMLText() get_data() picture()


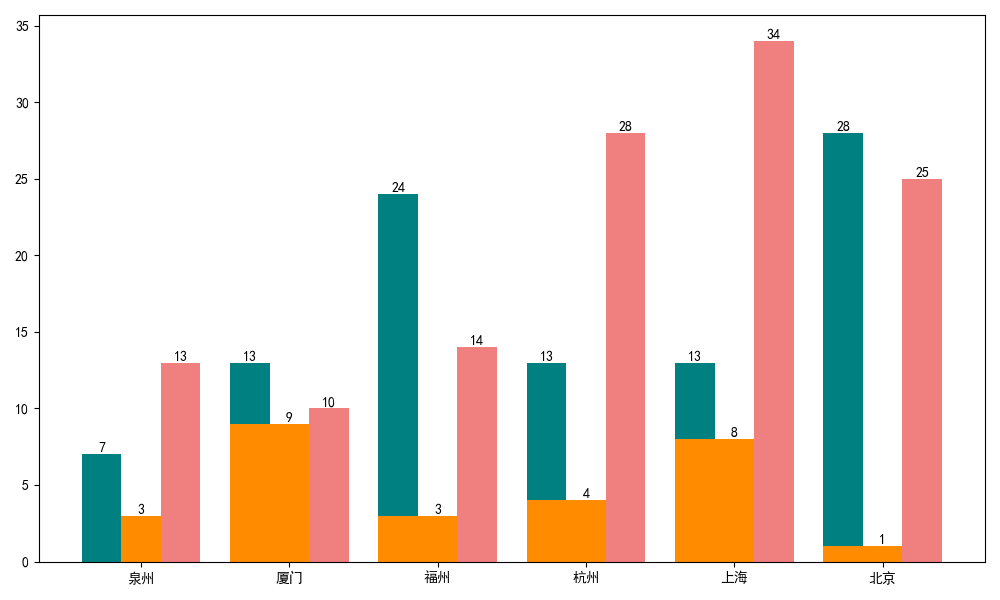
1.数据爬取
def get_data(): html = getHTMLText() soup = BeautifulSoup(html, 'html.parser') csv_file = open('D:\\pachong.csv', 'a', newline='') writer = csv.writer(csv_file) writer.writerow(['城市', '学历', '经验', '职位']) chengshi=soup.select('#filterArea > ul > li.select > a')[0].text for li in soup.find_all('li', class_='job_item clearfix'): try: xueli = li.find('span', class_="xueli") jingyan = li.find('span', class_='jingyan') job = li.find('span', class_='cate') writer.writerow([ chengshi,xueli.text, jingyan.text, job.text]) except OSError: pass continue print("保存成功")
2.数据响应
def getHTMLText(): url = 'https://%s.58.com/ruanjiangong/?PGTID=0d202408-0012-321e-c0b2-77ddf4e60b9f&ClickID=1' %cityname try: r=requests.get(url,timeout=30) r.raise_for_status() r.encoding=r.apparent_encoding return r.text except: return'产生异常'
四、结论(10分)
1.经过对主题数据的分析与可视化,可以得到哪些结论?
1.经过对主题数据的分析与可视化,可以得到哪些结论?
爬虫可以让我们以更快速度获取我们想知道的招聘信息,并且更为精准全面。
2.对本次程序设计任务完成的情况做一个简单的小结。
2.对本次程序设计任务完成的情况做一个简单的小结。
通过此次的设计任务,让我充分感受到python的魅力,虽然过程较为艰辛,但在成功爬取的那一刻,令我对自己感到十分的骄傲,也进一步增强了我对爬虫技术的兴趣。我相信,在未来会更加深入地研究这项技术。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号