动手学深度学习 | 门控制循环单元(GRU)| 56
门控制循环单元 GRU

首先这个GRU是最近几年才提出来的,它是在LSTM之后才提出来的,之所以先讲GRU是因为它相对比较简单一些。LSTM相对复杂,但是其实二者的表现效果差不多,所以实际使用哪个都是可以的。
GRU最主要是知道什么叫做“门控”。

我们之前说过,RNN是处理不了太长的序列的,是因为把所有的信息都放在隐藏状态中,当时间一长,隐藏状态中就累计了太多东西了,对于比较前的信息就不好抽取了。
- 不是每个观察都是同等重要
其实观察一个序列,并不是每个观察值都是同等重要的,第一次出现的猫很重要,但是之后出现的猫就那么重要了,第一次出现的老鼠也很重要。
序列的话,重要的其实就是那几个关键词,关键句子。
-
想只记住相关的观察需要
但是之前RNN并没有机制说要特别关心什么,特别不关心什么。GRU通过门机制,可以控制记住什么,忘记什么。当然后面讲的注意力机制会更加的刻画去关注哪一块,不关注哪一块。
- 能关注的机制(更新门)
更新门,这一个数据比较重要,我需要尽量的用它去更新我的隐藏状态,就是把这个信息尽量的放在隐藏状态中,这样就可以交给后面。
- 能遗忘的机制(重置门)
遗忘门/重置门,要么说输入不重要,或者说隐藏状态中可以忘记一些东西
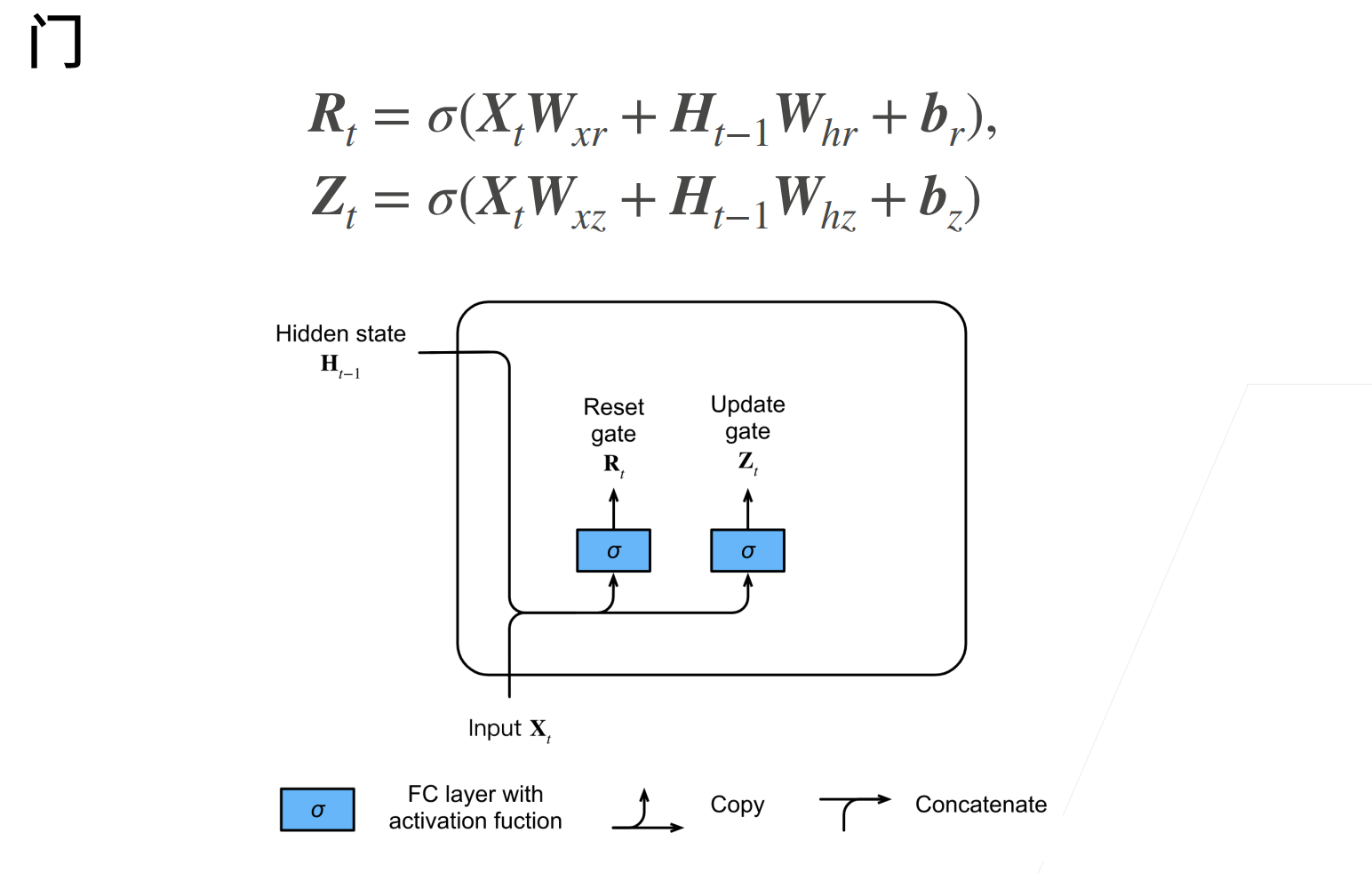
门这个东西这里通过公式和图来给大家解释一下。
\(R_t,Z_t\)都是可以认为是长度和\(H\)一样的一个权重。
和之前的RNN相比,GRU这里有多学了几个权重\(W_{xr},W_{hr},W_{xz},W_{hz}\)。
\(\sigma\)是是sigmoid,用于讲输出收放到\([0,1]\)。
门其实是一个电路中的概念,就是控制这个电流能不能从这里过去,当然这是“软”的,因为范围控制在\([0,1]\)之间。


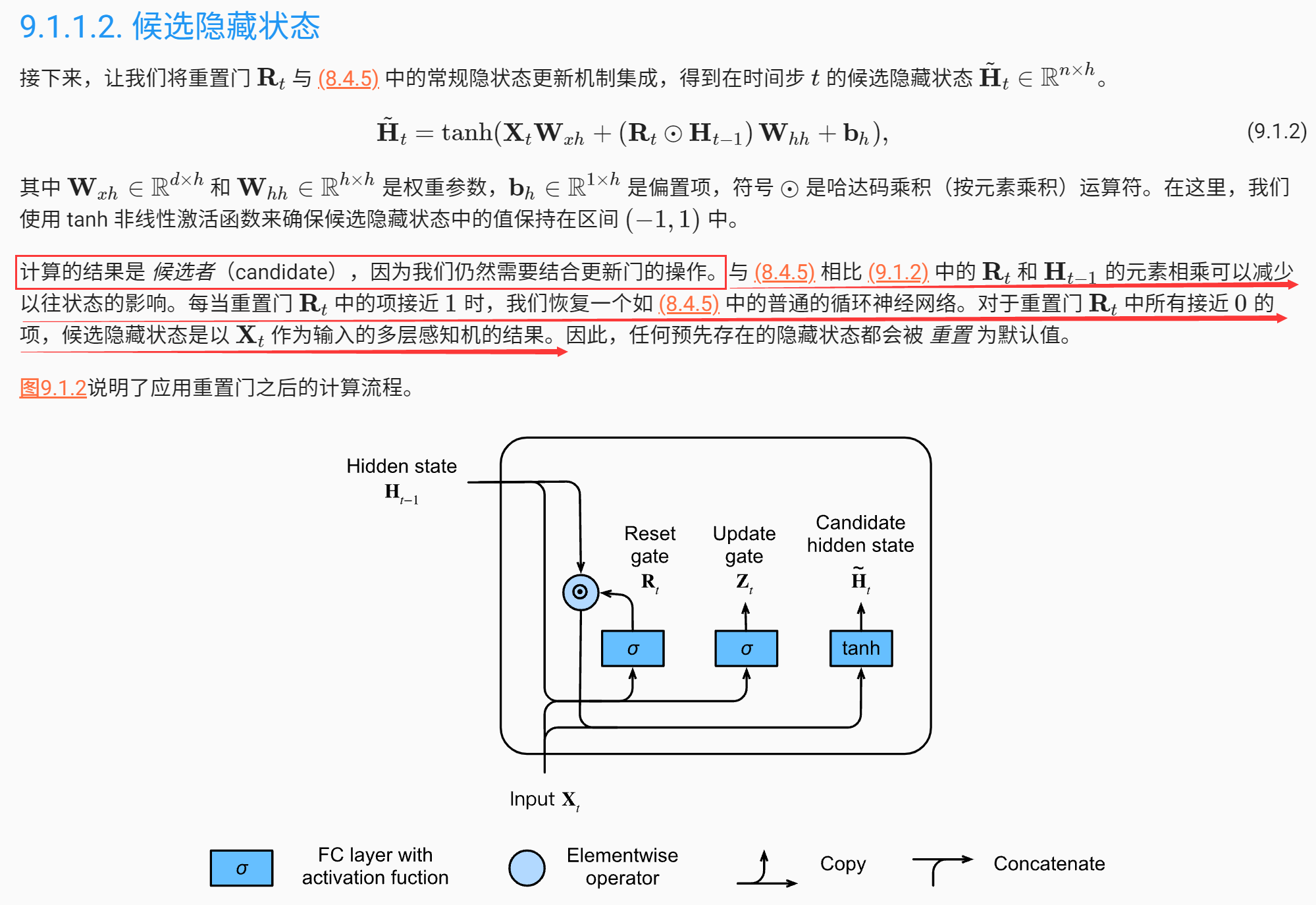
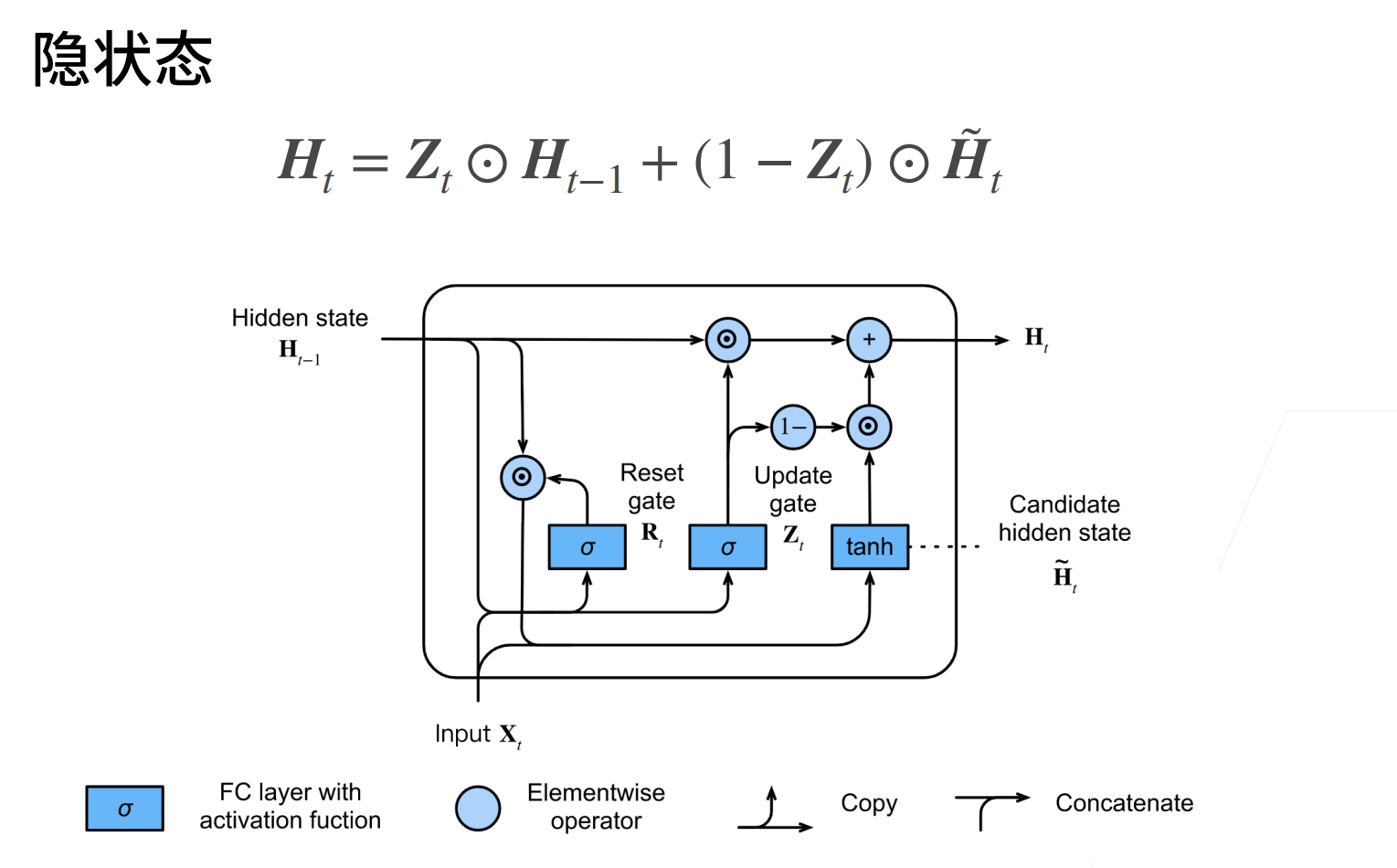

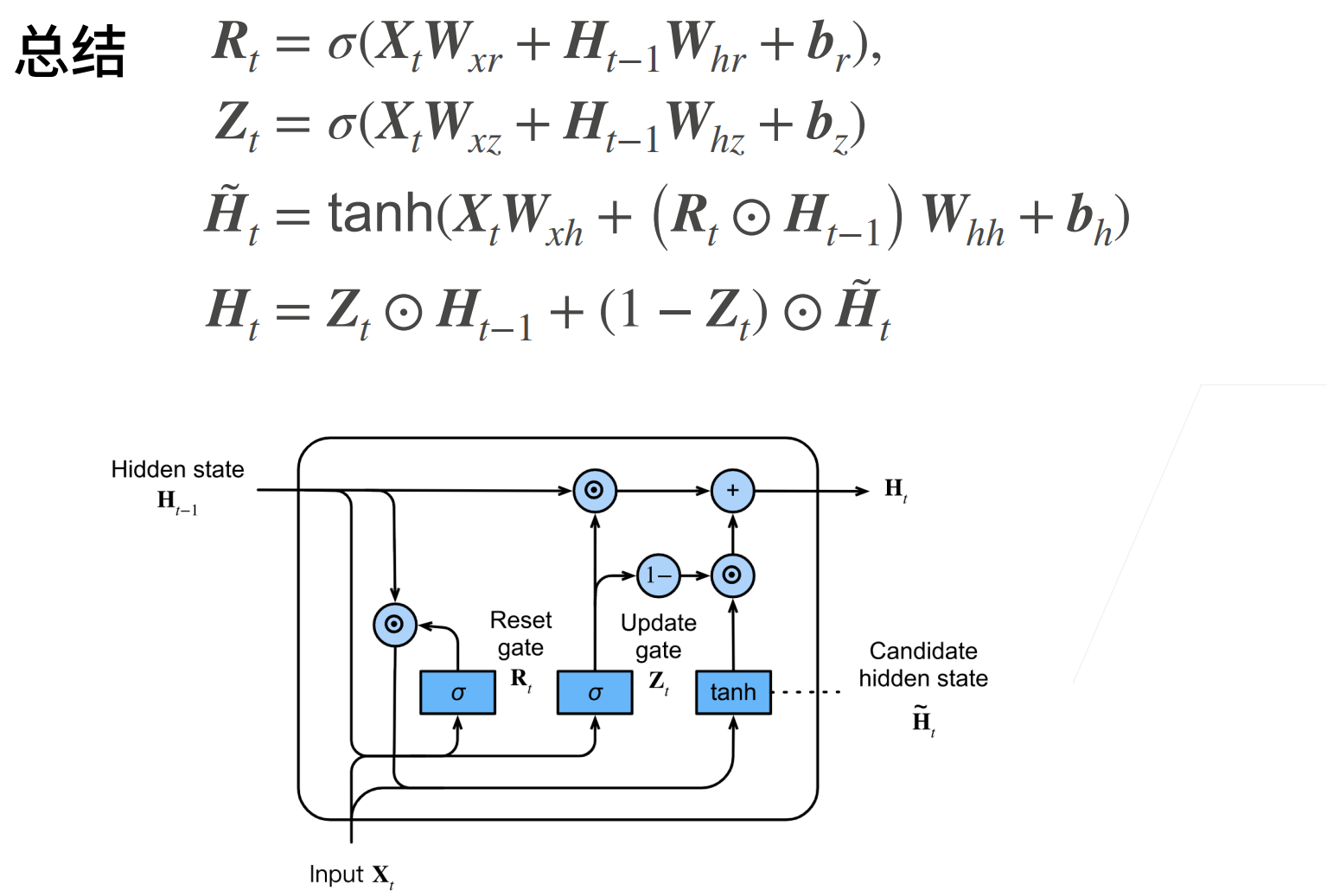

可以看最后的更新门Z,如果Z趋向全1,那么就和原始的RNN没有什么区别,因为\(H_t \approx H_{t-1}\),也就是选择要记住什么新东西,也没有要忘记什么旧东西。
代码
QA
- GRU网络中,R_t和Z_t的网络结构是一样的,为什么就可以自动把R_t选成Reset gate,Z_t选成Update gate?
是的,它们的网络结构是一样的,但是它的参数是可以学习的。
我们这里这样写公式,就是希望它们可以像这样去学习参数。但是模型究竟是不是这么学的呢?这个是不知道的,如果要验证的话,可以进行参数结果的可视化。
- 为什么GRU激活函数使用tanh呢?用relu或其他的激活函数可以吗?
应该是没有问题的,可以尝试一下。
这是使用tanh作为激活函数是因为那个时候relu激活函数还没有出来。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号