动手学深度学习 | 微调 | 36
微调 fine tune

沐神:微调绝对是深度学习中一个非常重要的技术!整个深度学习为什么能够work,就是因为有微调。迁移学习(transfer learning)


在ImageNet上训练的模型,其实是可以为我所用的。


微调的核心思想就是在源数据集上(通常是比较大的数据集)训练的模型,我们可把做特征提取的那一块拿来重新用一用,当然输出层是不能重用的(因为输出类别标号的都不一样)
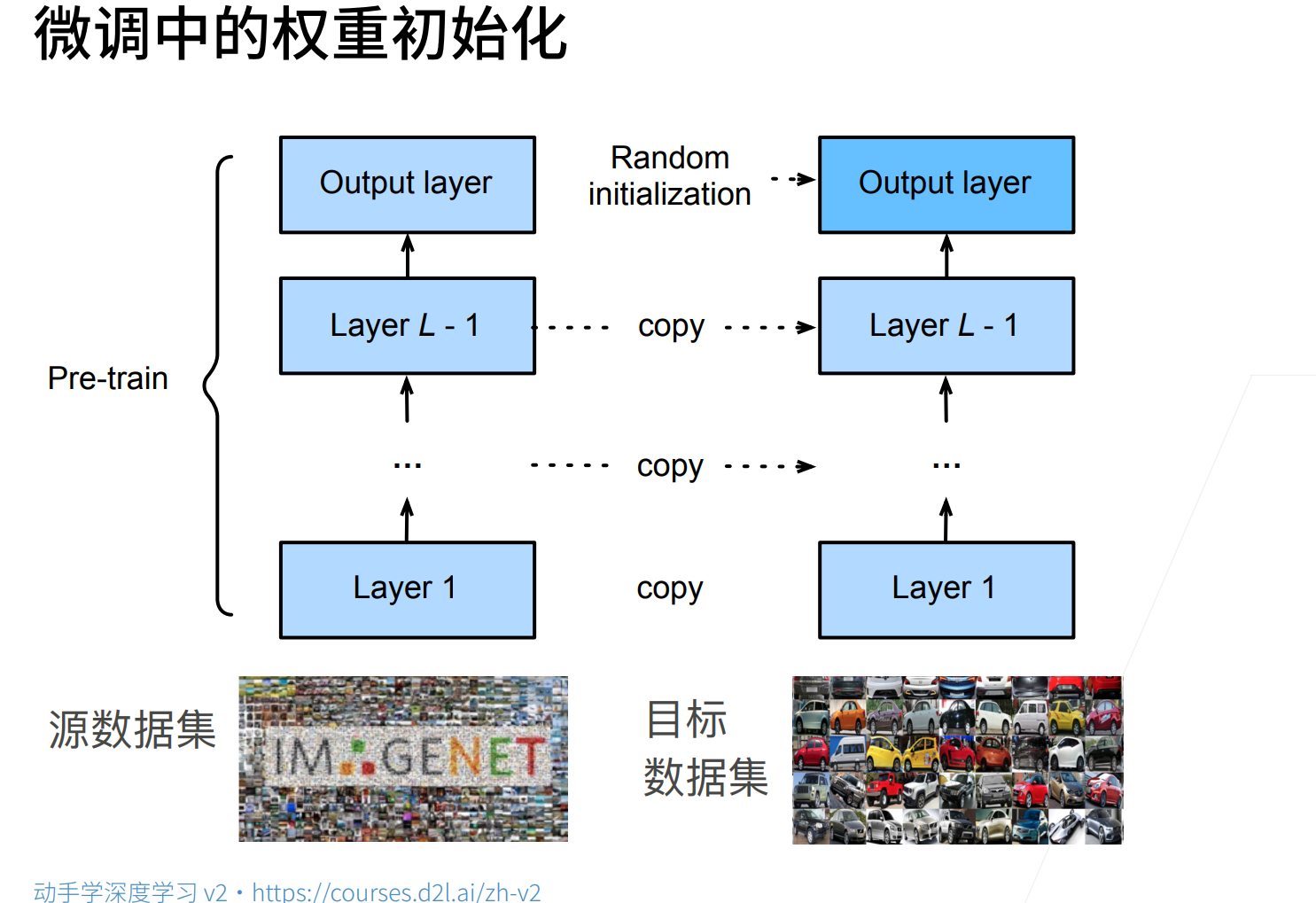
pre-train 预训练模型。
新建模型,就是模仿pre-train模型构造层,然后直接将参数(在源数据集上训练好的参数)拿过来,最后的的输出层参数随机初始化(因为最后的输出层是不能重用的)
上面的输出层是训练的比较快的,然后下面的层(因为一开始学习的就比较好,直接复制过来的肯定好),然后就微调(就是对下面层的参数进行细微调整)



我们可以认为越到后面的层,跟输出的标号越相关,越底层,提取的特征越基础(基础特征是基本不用改变的),那么可以固定底部的一些层的参数,不参与更新(可以认为是更强的正则)。

深度学习在工业界迅速应用就是因为有微调。有很好的pre-train模型,拿过来在自己数据集上跑一下,就可以得到一个很好的效果。
代码

可以看到,确实在pre-trian上进行微调效果要比重新在训练好的多。
QA
- 微调这部分意味着前面层的网络进行特征提取是通用的吗?
是的,可以认为网络越底层是越通用的,这部分的特征是基本不需要改变的。
- 假设有A,B两个数据集,都很大,A是imagenet,B是医学图片。如果我要识别癌症,那是用pre-trained A的现成模型然后再加上B进行fine tune效果好,还是直接用B从头进行train比较好?
你可以试试... 直观来说可能从头训练效果会好,但是要测试过才知道结果。
建议还是找相近的任务,然后使用相近任务的pre-train。如果源数据集和目标数据集差异很大,那么模型迁移的效果有可能会很差。
- fine tuning是不是就是transfer training?两者有什么不同?
其实可以认为就是一个东西,只不过搞dl这帮人就是喜欢重新起名字。
- imagenet比较简单的话,能从那些地方获取一些更好的可用于微调的模型?
一般公司都会把自己在大数据上train的模型当作财产,有时候比数据还重要。学术界imagenet是挺好的,公司话你可能要自己去找一找。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号