动手学深度学习 | 数据增广 | 35
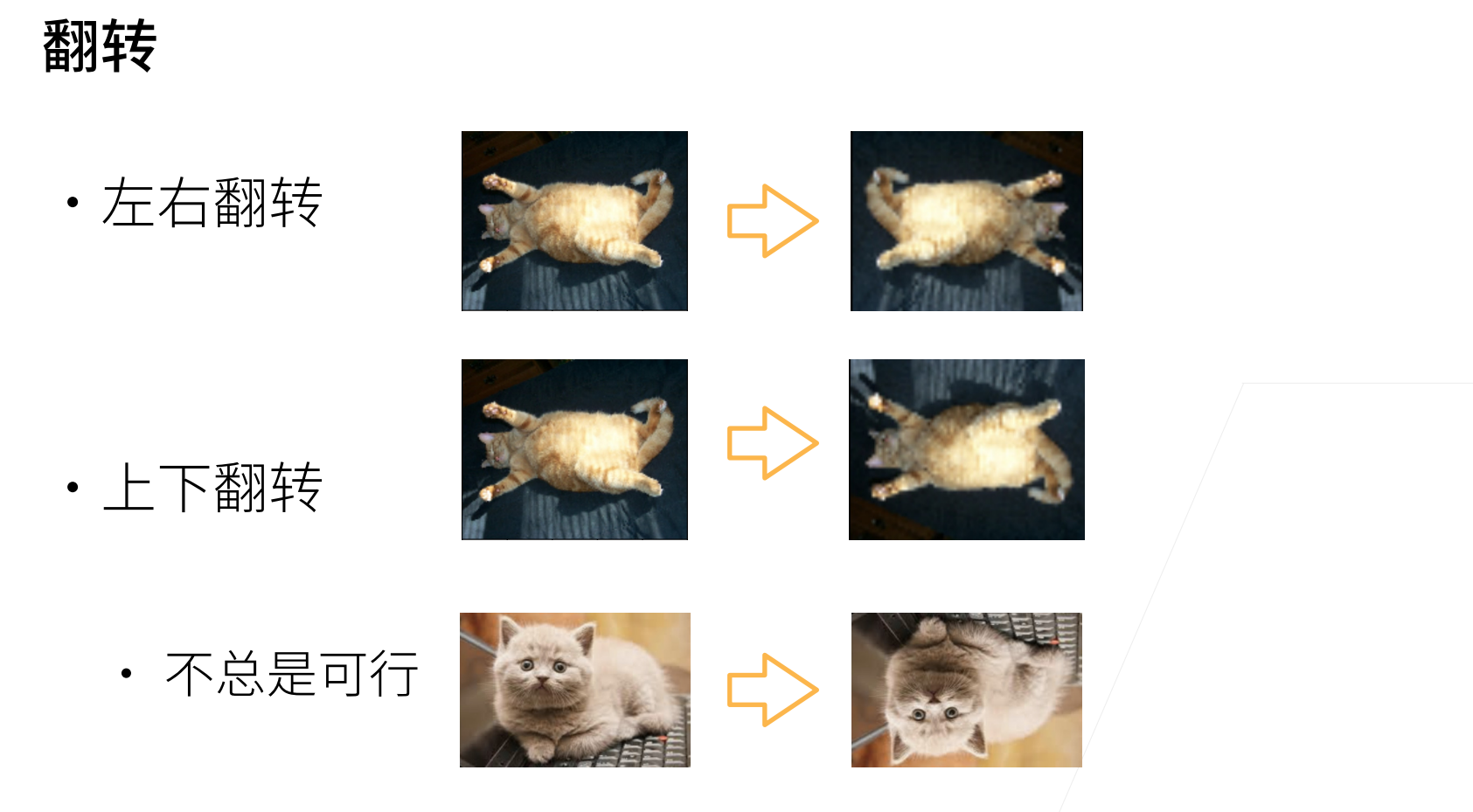
数据增广

数据增广的话就不局限于图片,对文本、语音等都可以进行增广,这里主要是针对图片的技术。







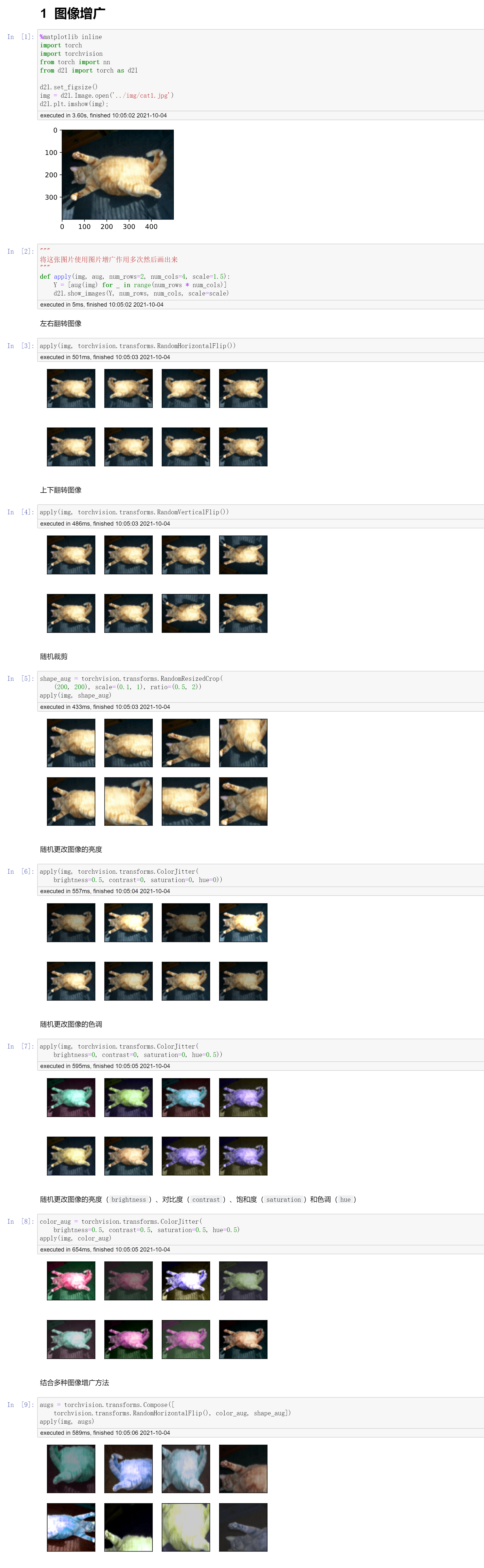
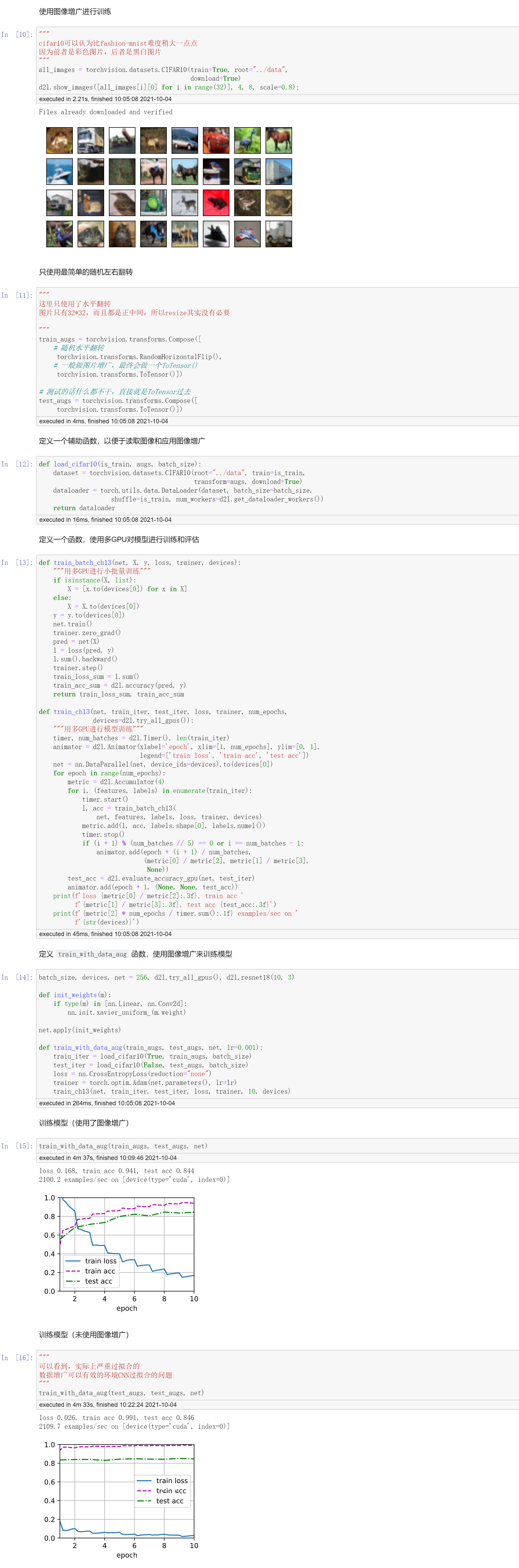
代码
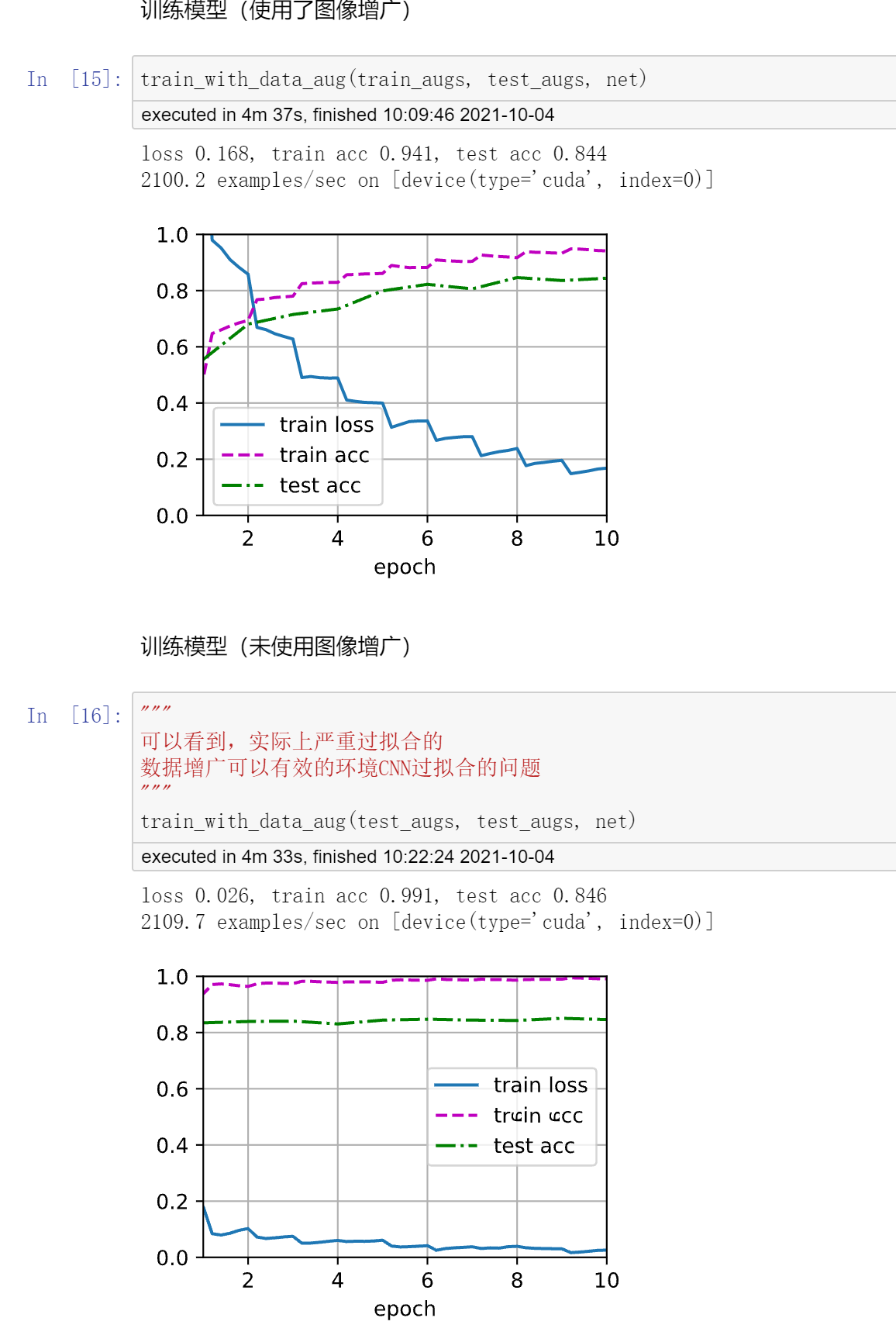
简简单单一个左右翻转的图像增广,就可以有效缓解让cifar10的过拟合情况。
其实不要奇怪,在ImageNet上,如果数据增广做的比较狠的话,经常是可以看到test acc高于train acc的,是因为测试环境不会对图片做数据增广,而训练环境把图片都增广(一堆鬼样子)。
QA
- 理论上,是不是原始样本足够多,就不用做增广了?
是的,但是这样的情况很难发生。
还有图片多,并不代表数据集的多样性好。
还有就是真正应用的时候,其实还有可能会出现更加奇怪的图片。
- num_worker的值是不是根据机器GPU性能而设定?
不是GPU,是CPU...
如果你CPU是双核的,那么num_worker就取2。
虽然我们说深度学习拼的GPU,但是CPU也不能太差,否则数据预处理的时候就会非常的拉跨。(CPU至少要个8核吧)
- 测试一般怎么做增广呢?
测试集一般是不做增广的。
但是如果是输入的一张随机图片,那么就会保留短边,然后按照比例去resize成\(224*224\)。
- 关于cifar10的训练
cifar10的测试精度是可以很高的,可以到95%,大概需要200个epoch。
但是trian acc和test acc之间的gap是不会减少的,一般也很少减少,最终train acc可以达到100%。
- 图片增广后需要人工一张张的确认效果吗?
不用一张张,但是要大致看一下,保证不要太奇怪就行了。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号