
动手学深度学习 | 含并行连结的网络GoogLeNet/Inception V3 | 25
GoogLeNet

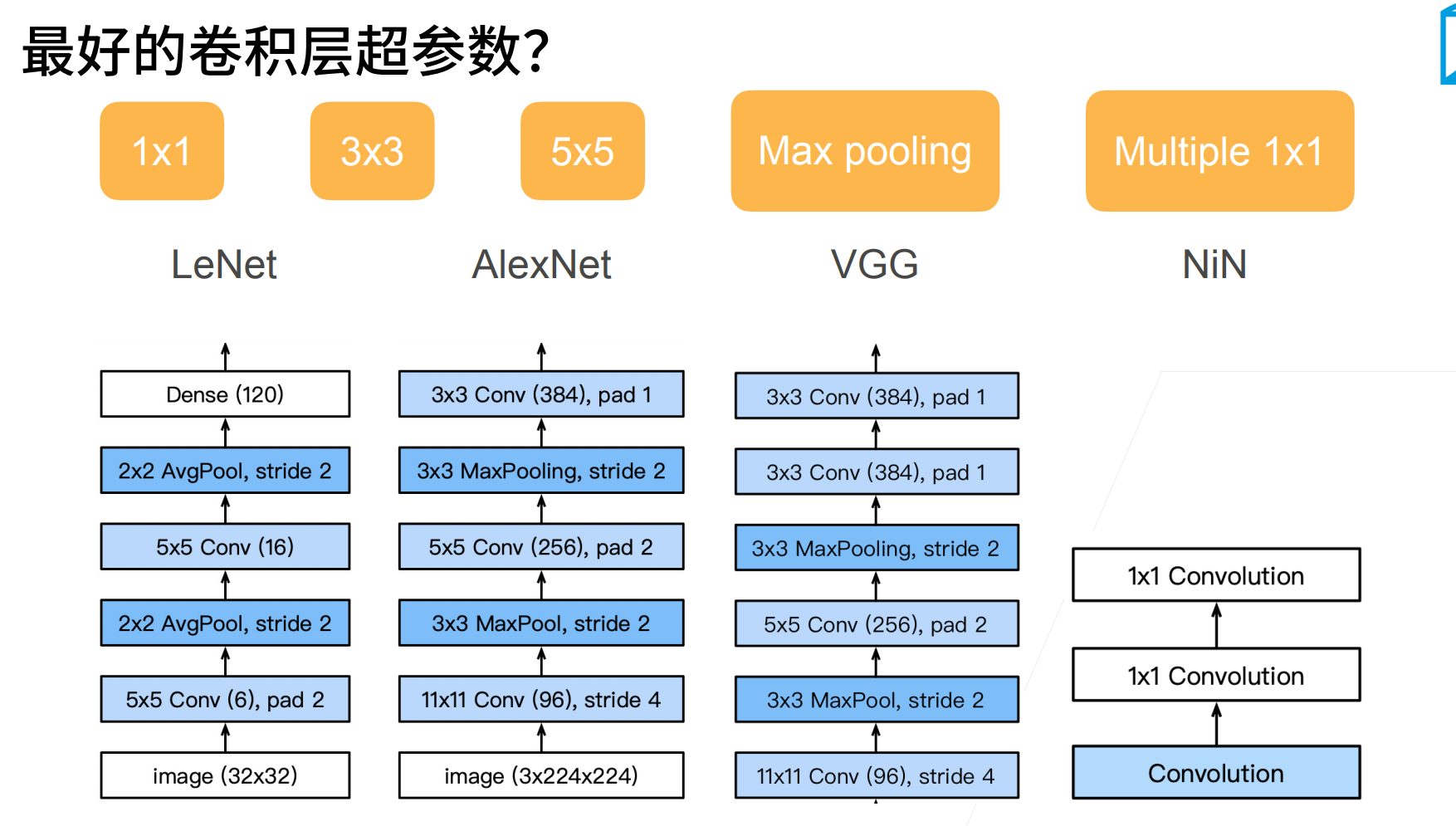
虽然现在NiN基本没有被使用,但是GoogLeNet还是被比较多的使用。
这个网路出来的时候也是吓了大家一跳,就是做到了一个几乎快到100层的卷积层,基本可以认为是第一个超过百层的卷积神经网。虽然不是直接有100层深,但确实卷积个数超过了100。
NiN严重影响了GoogLeNet的设计,所以我们是先讲的NiN。
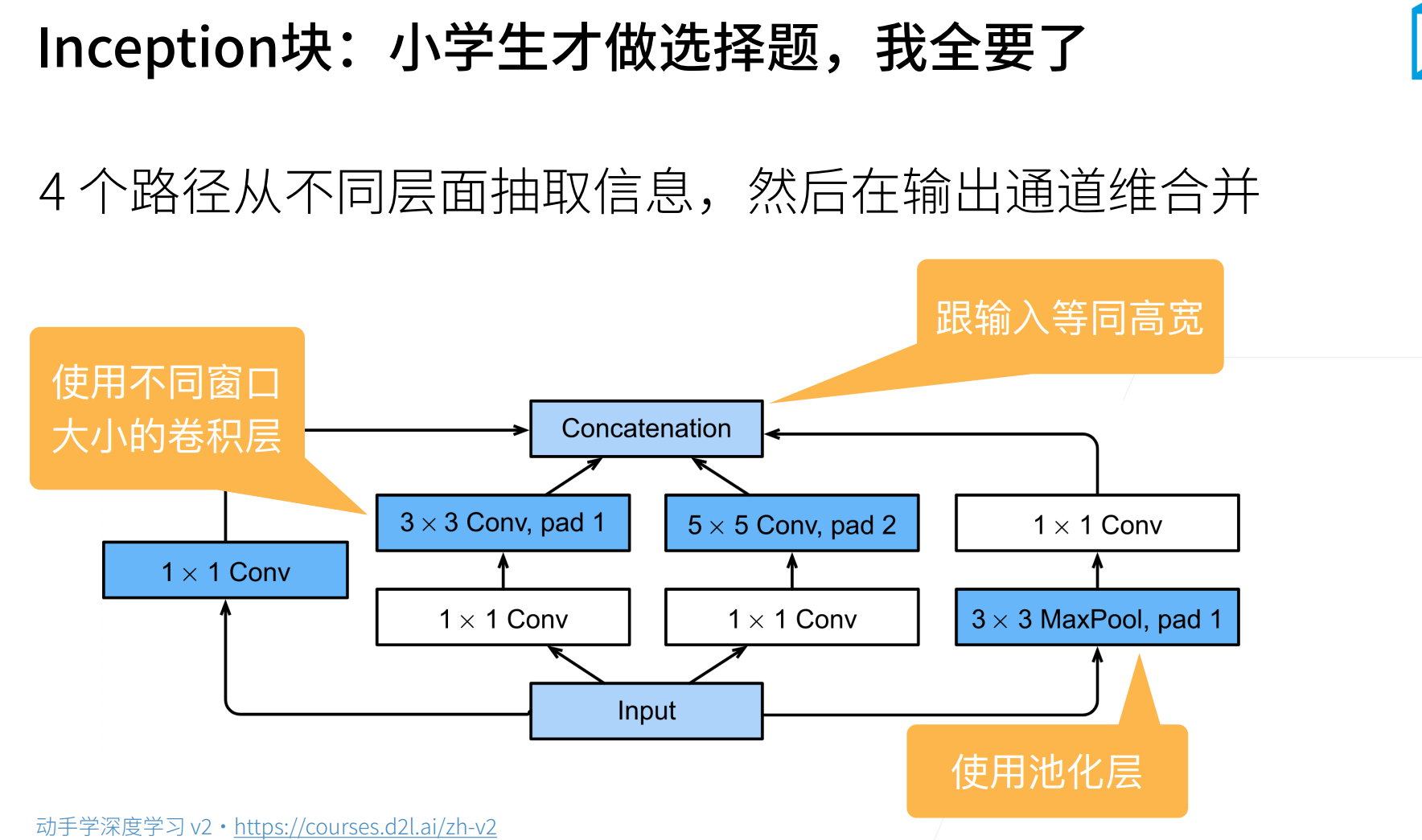
Inception块将input复制了四份,然后进行四路输入。
每路输入的都只改变通道数量,而不该feature_map的高宽,最后将这四路输出进行合并(就是通道的堆叠)
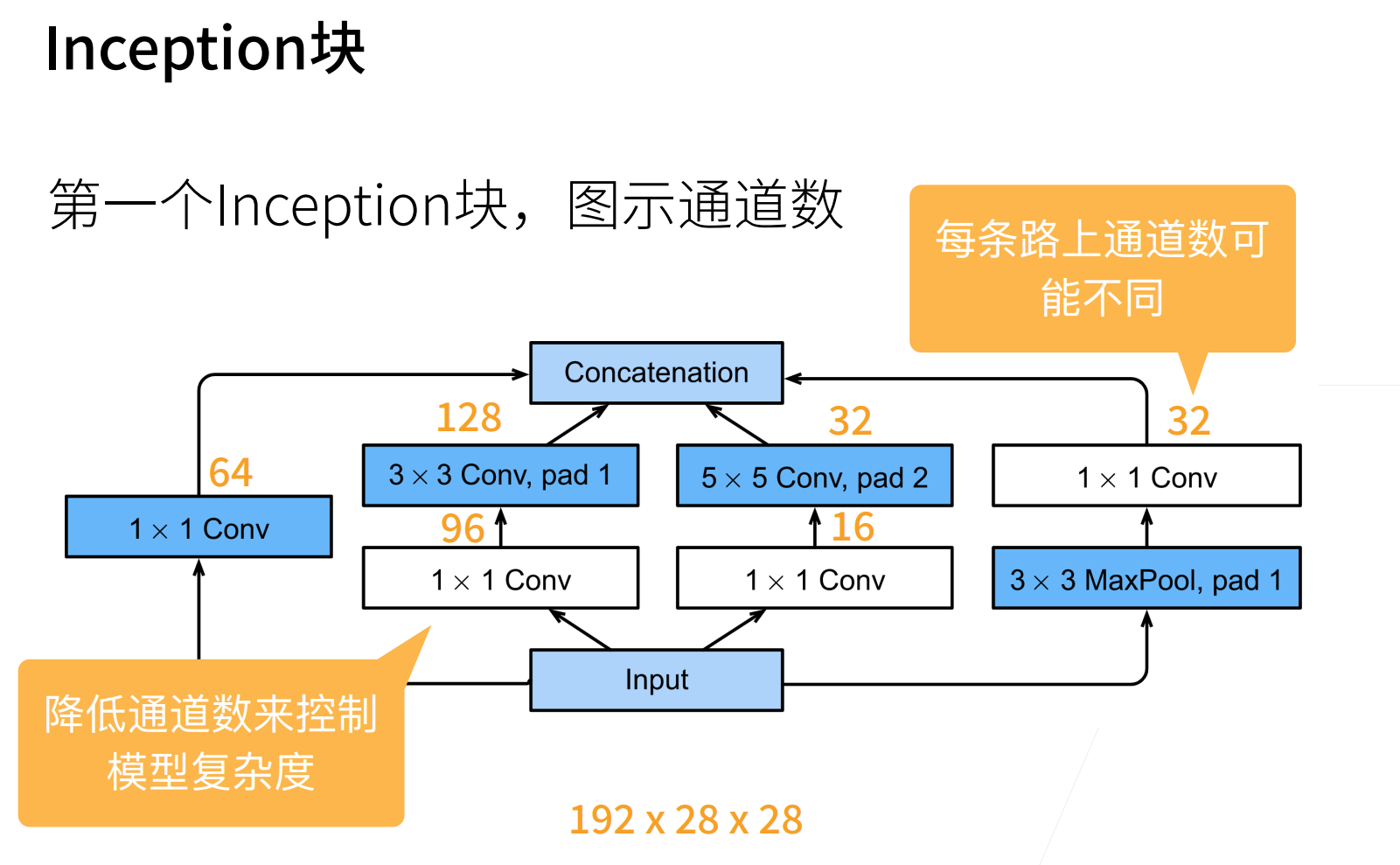
上面标注的数字表示通道数。
但是一个很诡异的事情就是这些数字是怎么来的?作者从来都没有说过这些数字是怎么来的,可能是试出来的吧。
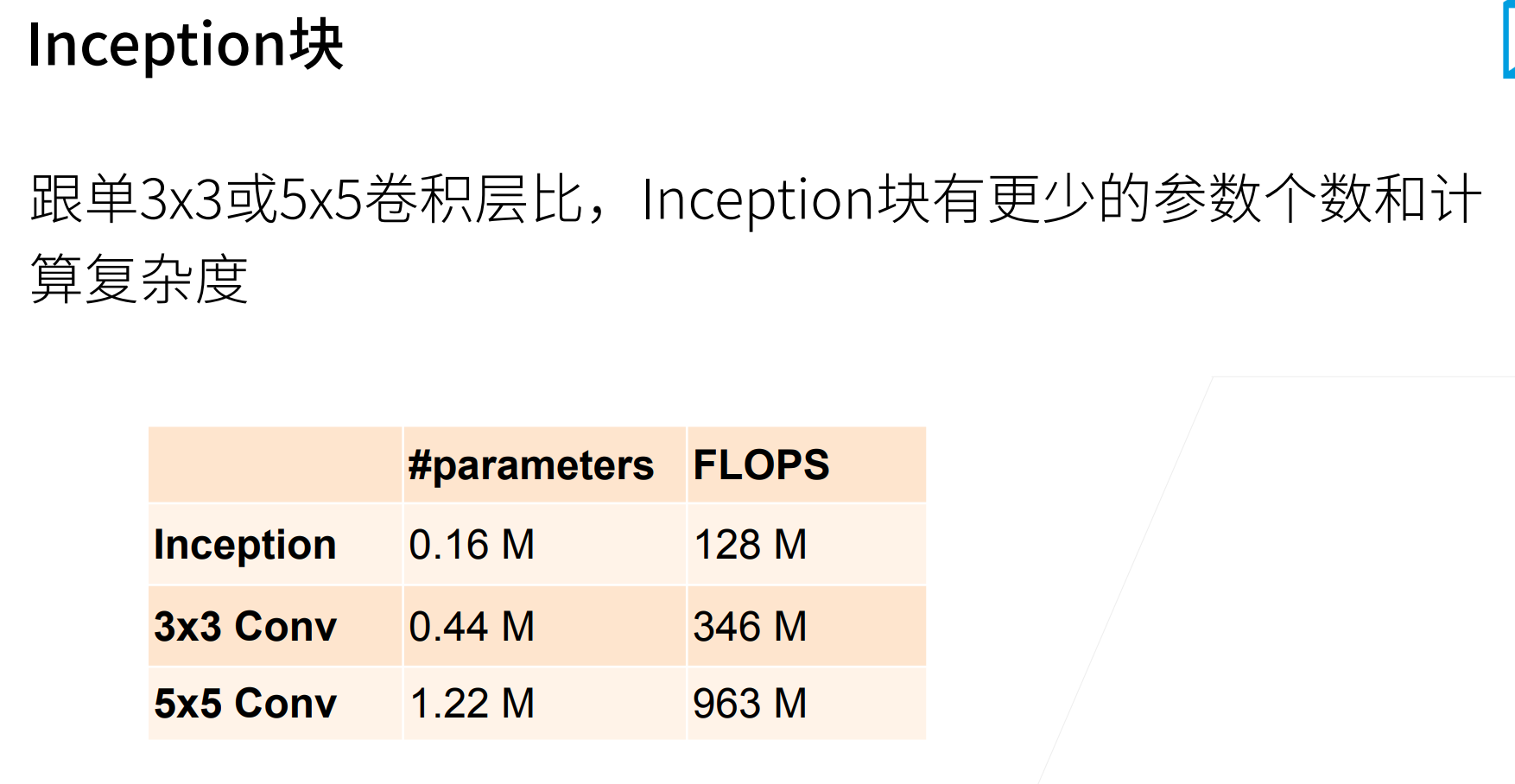
Inception块的参数数量比直接使用\(3*3\)和\(5*5\)的参数数量少了很多,原因就是使用了大量的\(1*1\)卷积来降低通道数量。
计算量也会下降,因为计算量和参数量是成正比的。
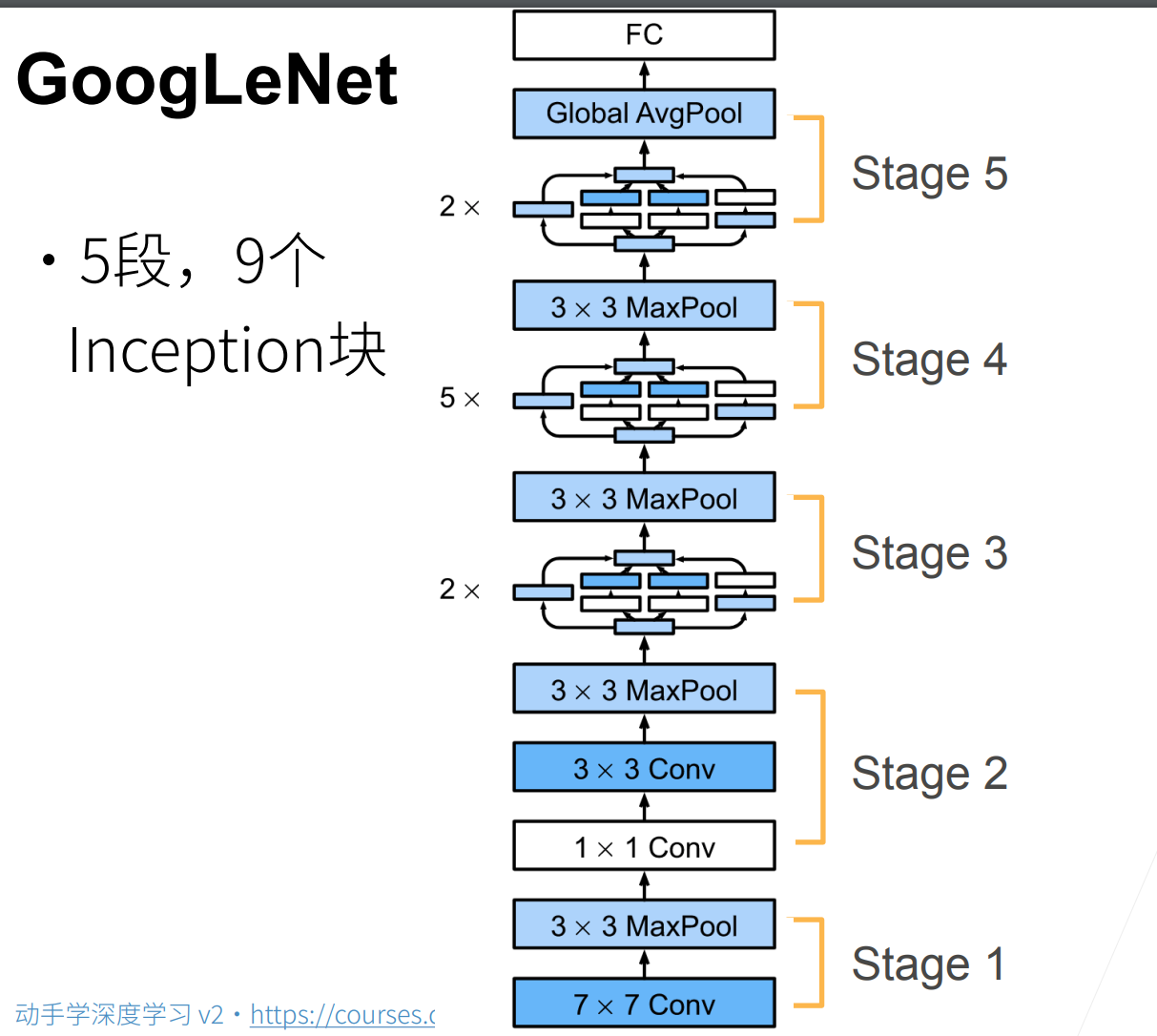
这里所谓stage就是高宽减半一次。
这里GoogLeNet和NiN的不同就是没有强求最后GAP后通道数一定要等于类别数,而是通过一个FC,来进行类别分类。
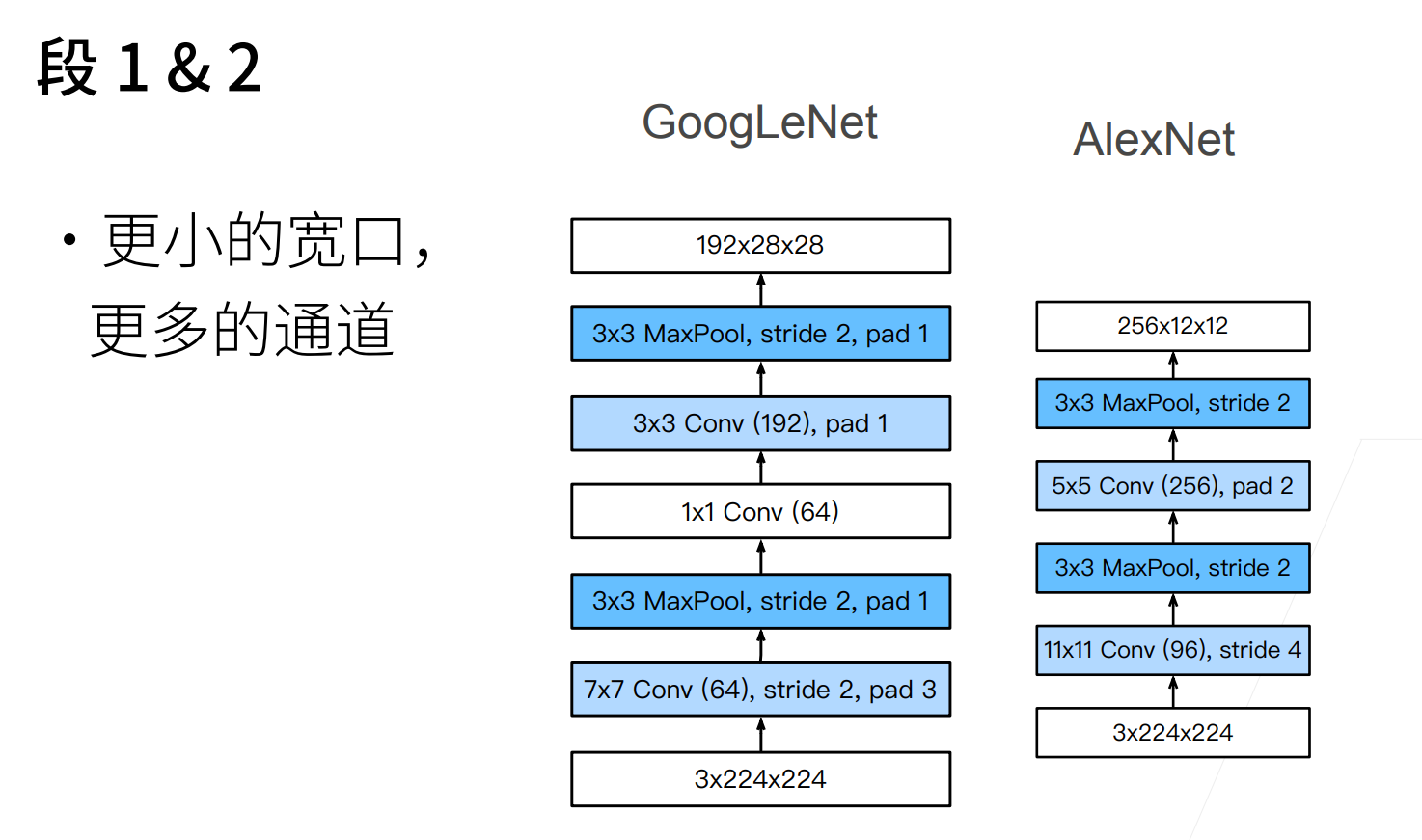
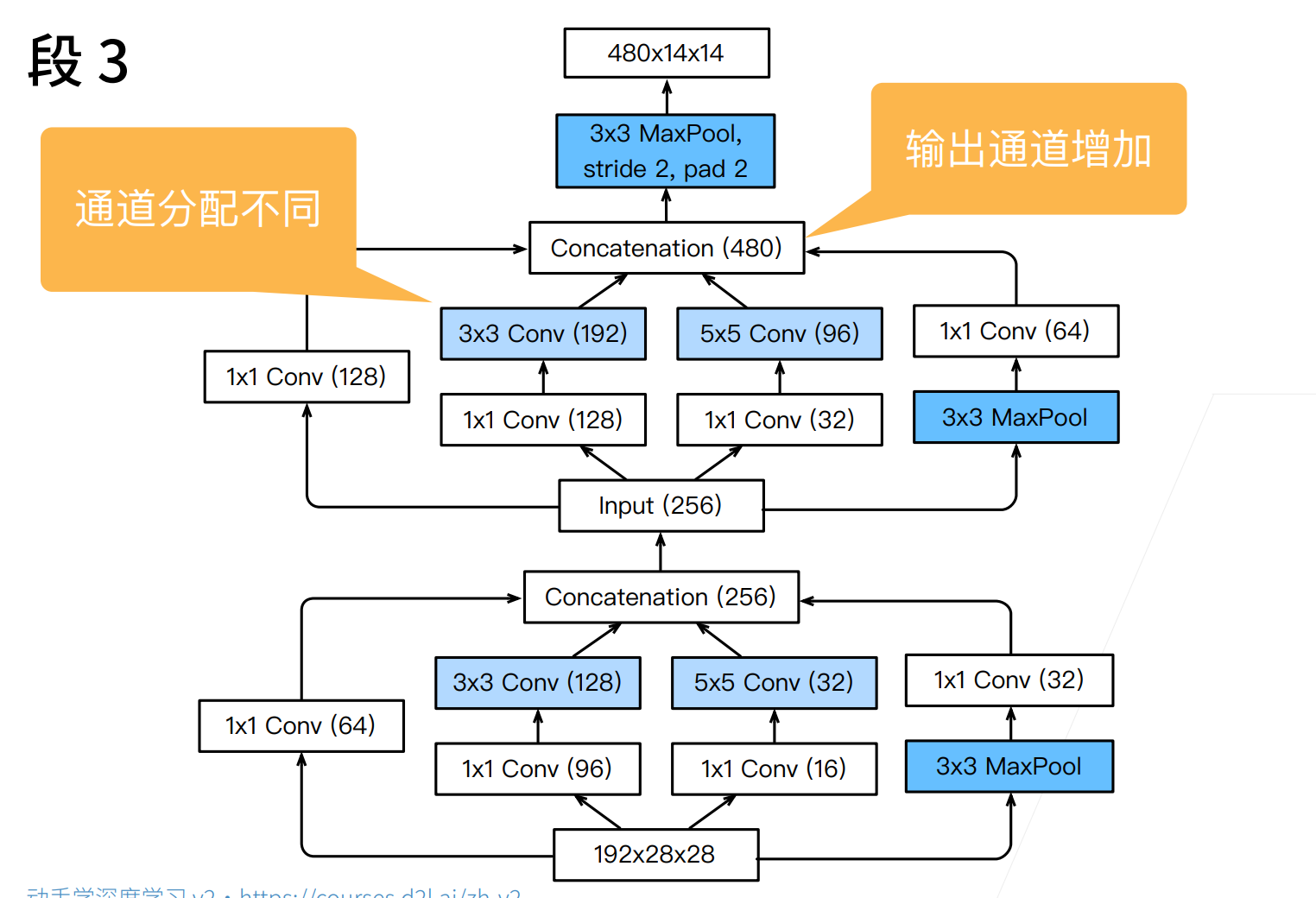
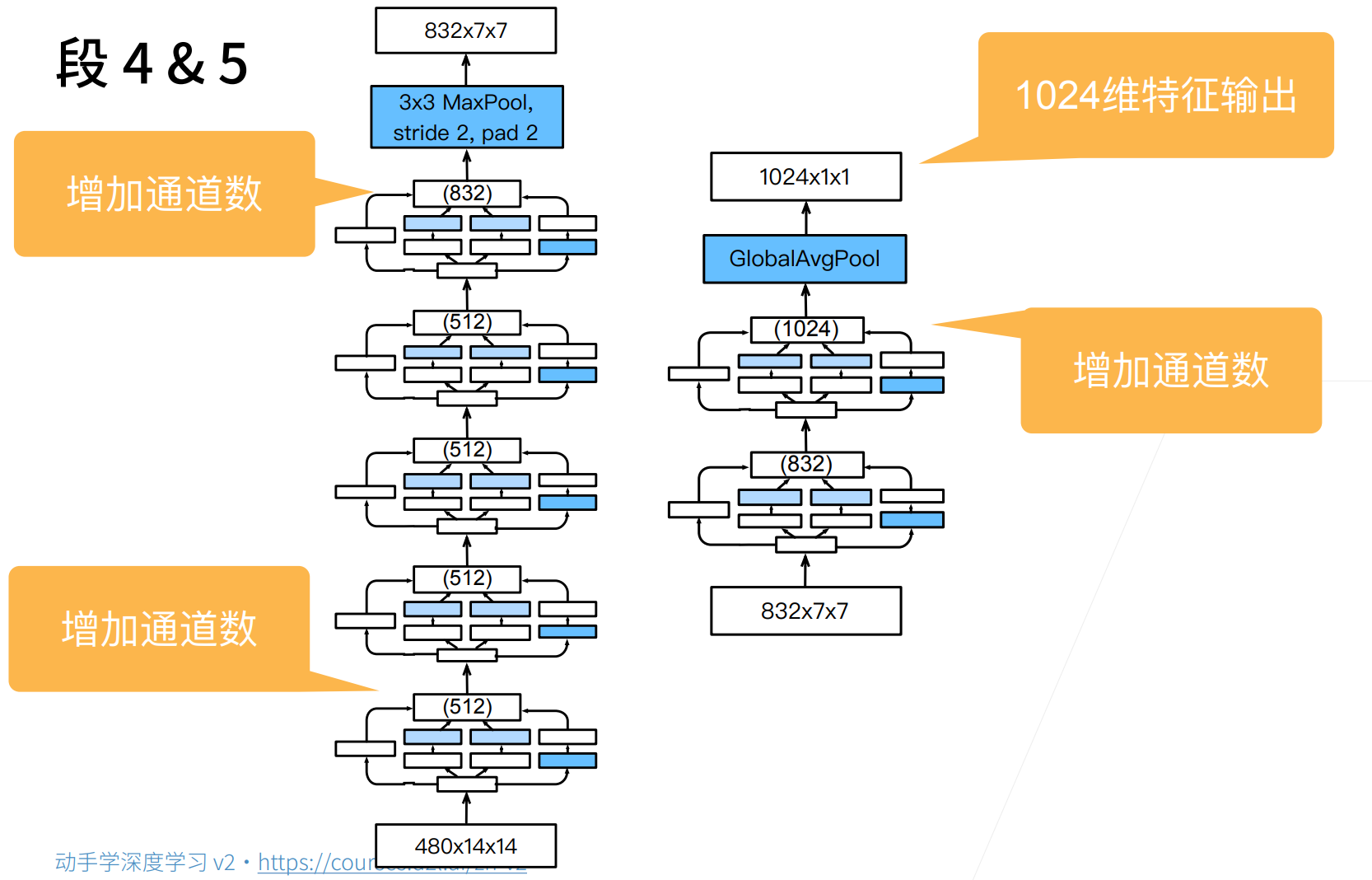
这里832,1024这些玄学数字... Google有钱,可以去暴力枚举参数,他们机器多,算力多。
真的是看了Inception后才是真的相信什么叫做炼丹。

我们前面介绍的V1,但是现在基本不会使用。
V2是在V1的基础上加入了BN层。
V3是在V2的基础上,进行了卷积层内部的修改。
V4在V3的基础上,使用了残差连接。
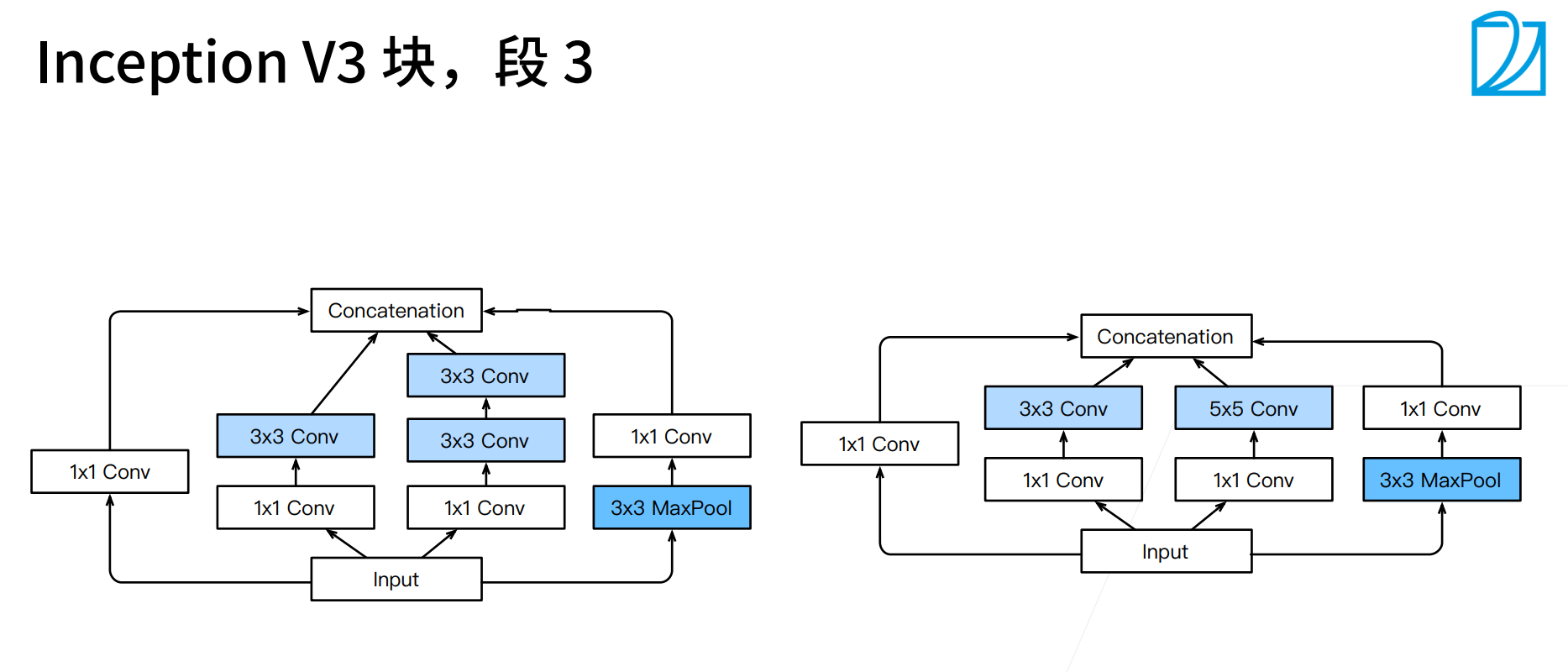
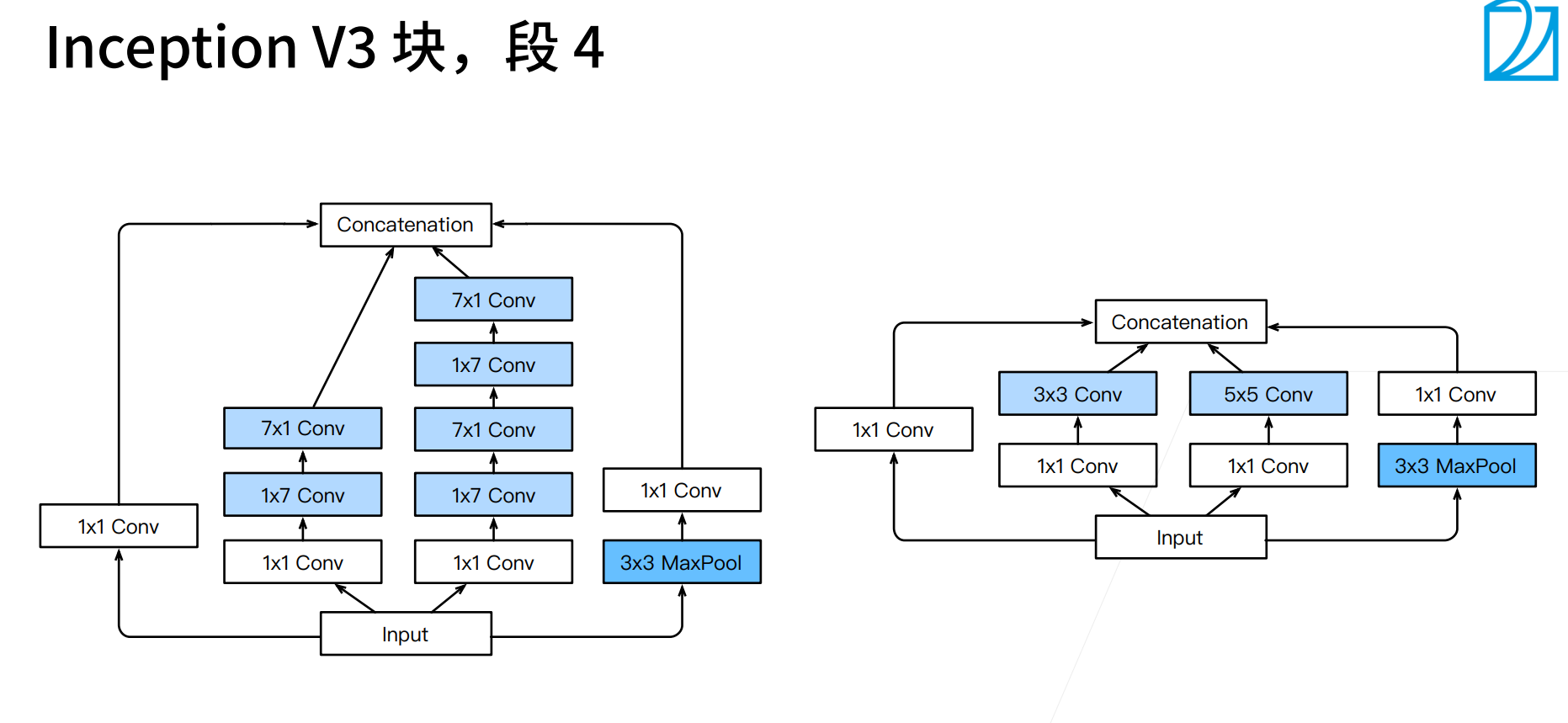
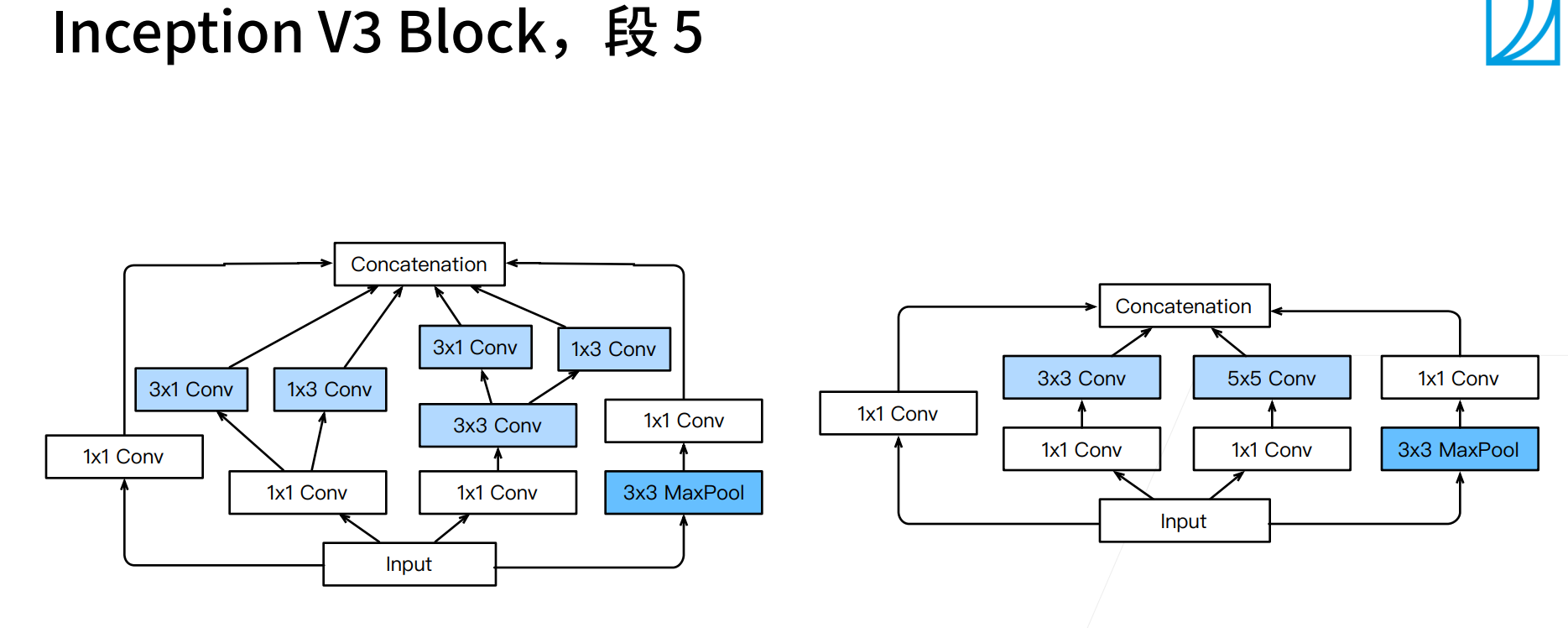
Inception V3真的是... 无法解释,大概这就是有钱人的游戏,google应该是每个都尝试了,选出来了效果最好的那种设计。
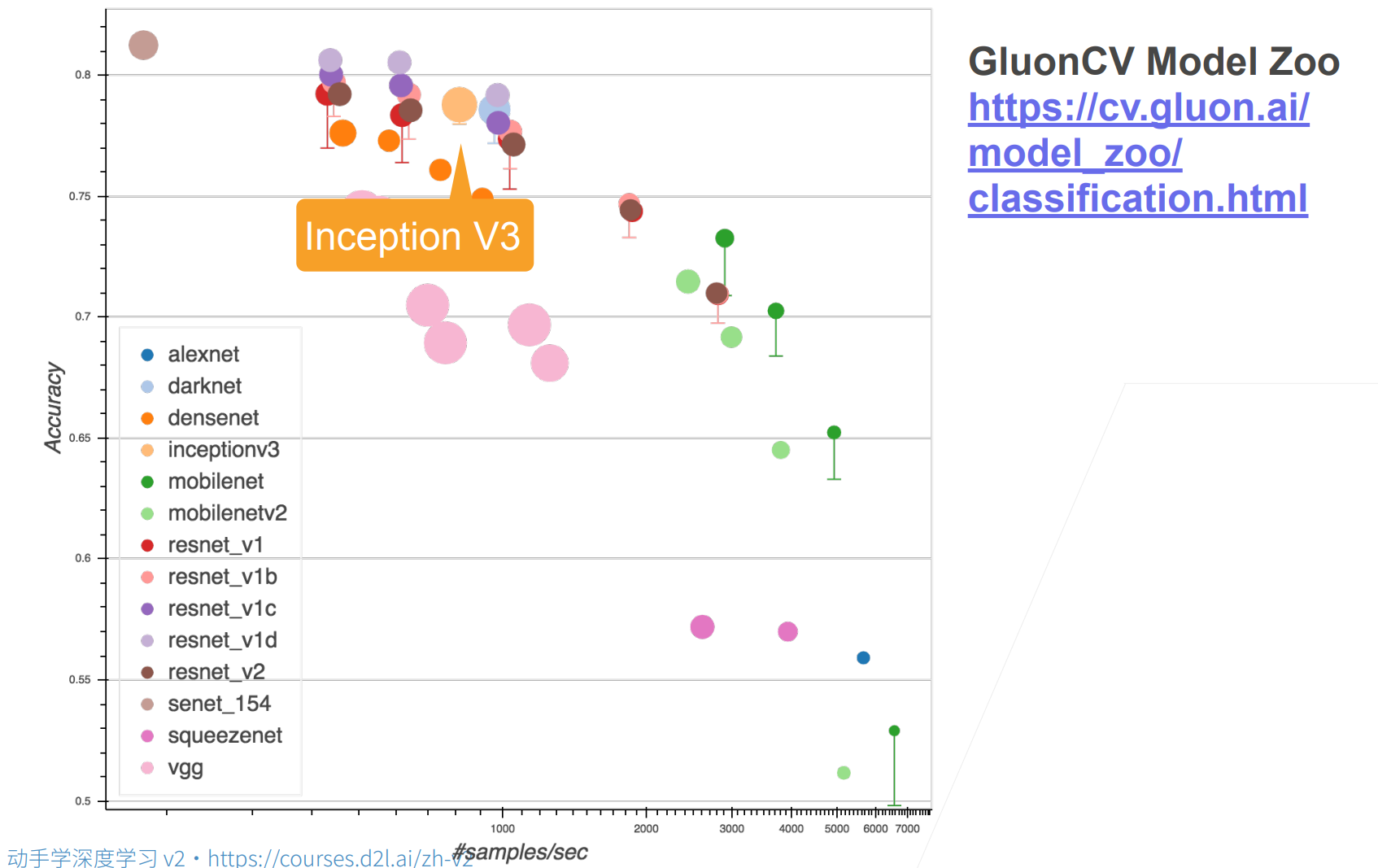
虽然Inception V3非常的诡异,但是表现的效果还是不错!基本完胜VGG。
但是可以看到和其他模型相比,还是没有什么优势。(Inception V3是一个耗费内存较多,运算比较慢,但是精度还算不错的一个网络)

GoogLeNetV3,V4现在还是经常被使用,因为精度上来了。
但是一个很大的问题就是GoogLeNet太复杂了,基本上不像是人能够设计出来的感觉,而且完全不知道是怎么来的,这也是GoogLeNet那么不受欢迎的原因。
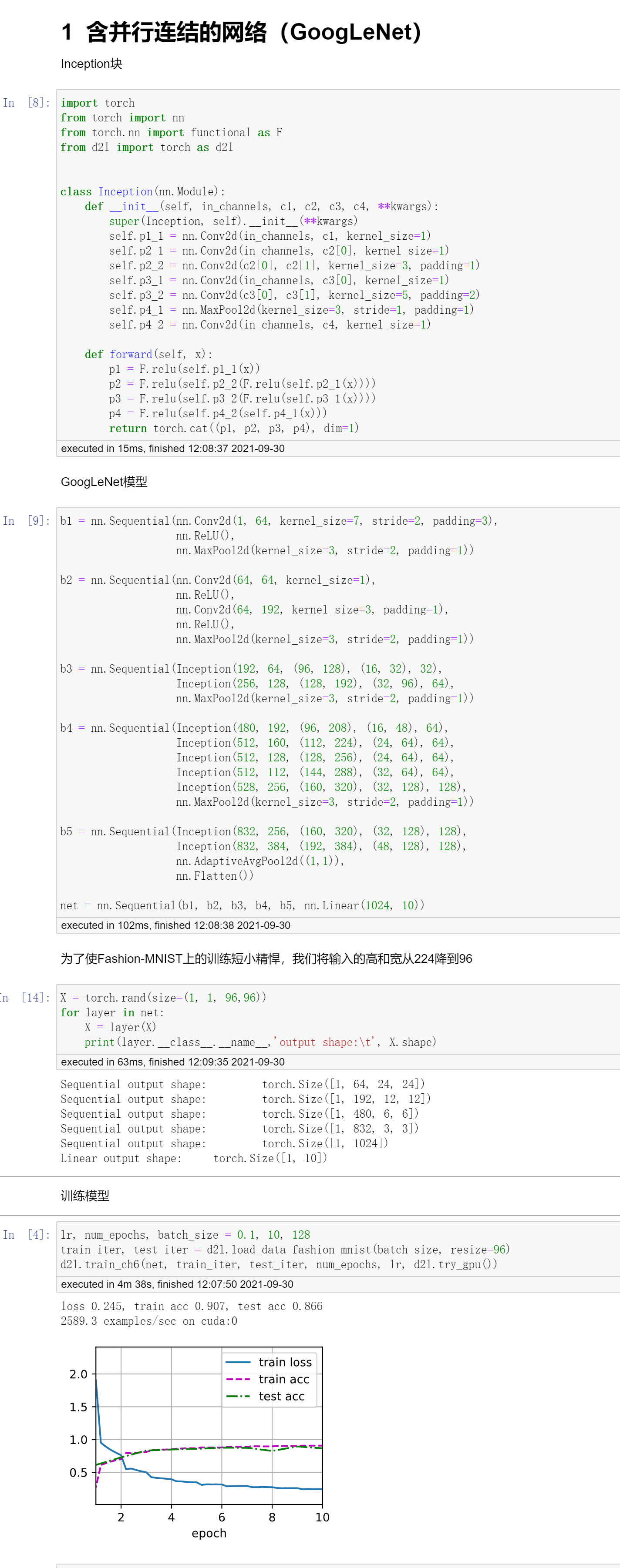
代码实现
GoogLeNet的实现相对来说是比较复杂的...
QA
- Inception中池化层在卷积层前面是不是不太常见?
其实不是的,可以认为\(1*1\)卷积是一个全连接层,这个\(3*3\)的maxpooling还是作用在之前卷积的输出。
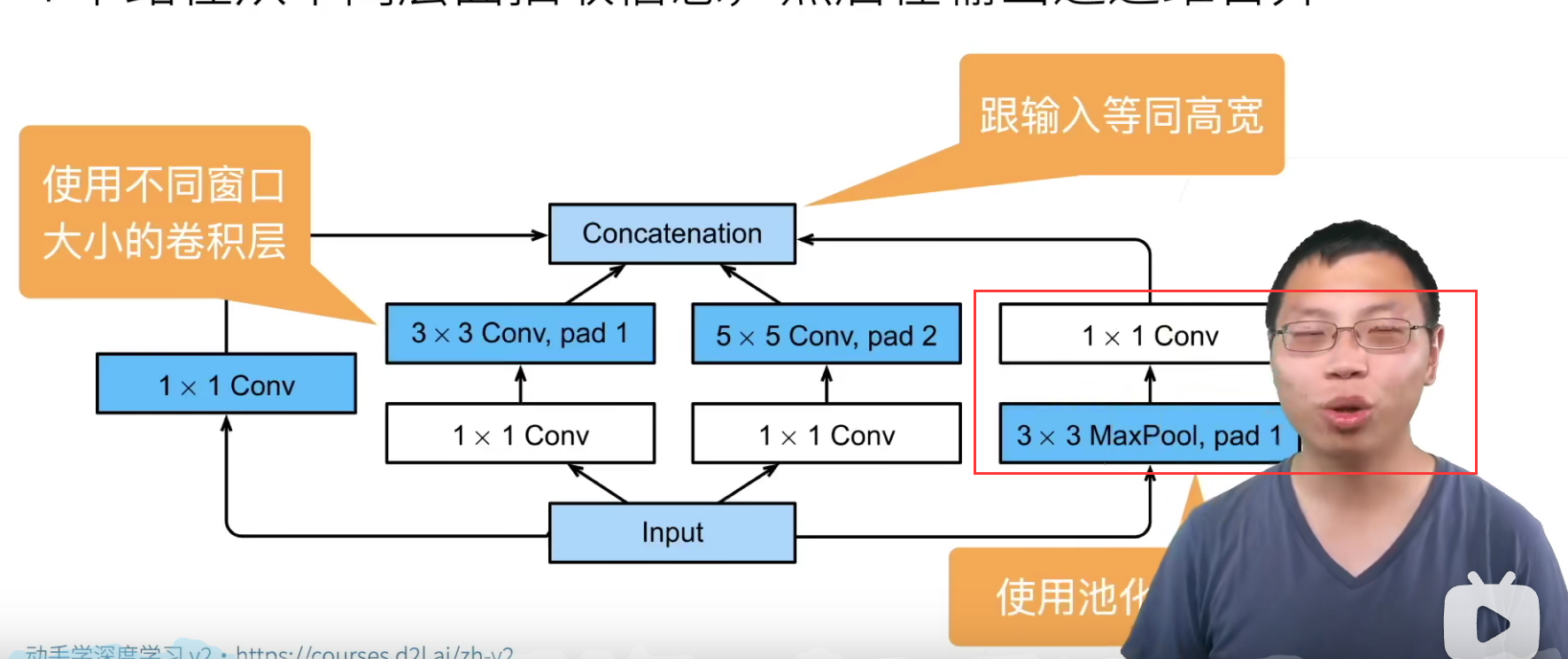
- \(3*3\)和\(5*5\)的卷积核也可以降低通道数,为什么要使用\(1*1\)呢?
\(1*1\)卷积核先给降低通道数,比如将256通道降低为96,然后在交给\(3*3\)和\(5*5\),后面它们要降低或者增加通道数都是可以的,如果不先使用\(1*1\)进行通道数的降低的话,直接输入这个通道数会让计算量非常大。
- 很多超参数都是2的次方,有什么讲究吗?
只是2的次方在计算机中算的会快一些。如果是100,200这种,在GPU上并行起来可能不会那么方便。
- dl中需要修改经典网络的结构吗?
正常做深度学习的时候先不要去改经典的网络,就直接用,除非你的数据真的和别人不一样。
像我们课程中,将VGG的通道数除以4,或者像图片你的输入宽高resize一下,这些简单的变化都是可以的。但是这里建议别的还是不要去调整了。
- 在CNN中目前最强是哪个网络?
就是沐神参与的ResNest,在ImageNet上效果可能不是最好的,但是在迁移学习上效果非常非常的好。
然后这个网络主要的是attention,但是还有使用了很多工作时候积累的trick,这是很多方面作用它的效果才能得到那么好。
- \(3*3\)改成\(1*3\)和\(3*1\)的好处是什么?
好处是可以降低你的计算量,会减少1/3的计算量,这是它的好处;坏处就是可能说他的效果不会有那么好。
- linear,dense,flatten有什么区别?感觉全是卷积。
linear和dense都是全连接,你可以使用linear也可以使用dense,就都是一个东西。
但是flatten不是全连接,flatten就是把一个4-d的tensor变成一个2-d的(batch,tensor),因为全连接的输入必须是一个向量。
- 什么调参?
一般都会先在一个小的数据集上进行...
没有人会直接上大数据集,同时你可以尝试减少图片的尺寸,或者适当减少模型的通道数之类的,先快速得到一个结果,再慢慢进行调整。
- 为什么感觉现在讲的网络通道数越来越多?
因为现在网路设计和很精巧,相比于AlexNet几个大的卷积层和全连接层叠加。
但是对于ImageNet这样大的数据集,其实通道数大概在1024左右也是差不多了,再多的话其实容易overfitting。
但是不是说100w就一定对应1024个通道,这都是实验出来的。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号