
动手学深度学习 | 网络中的网络NiN | 24
NiN
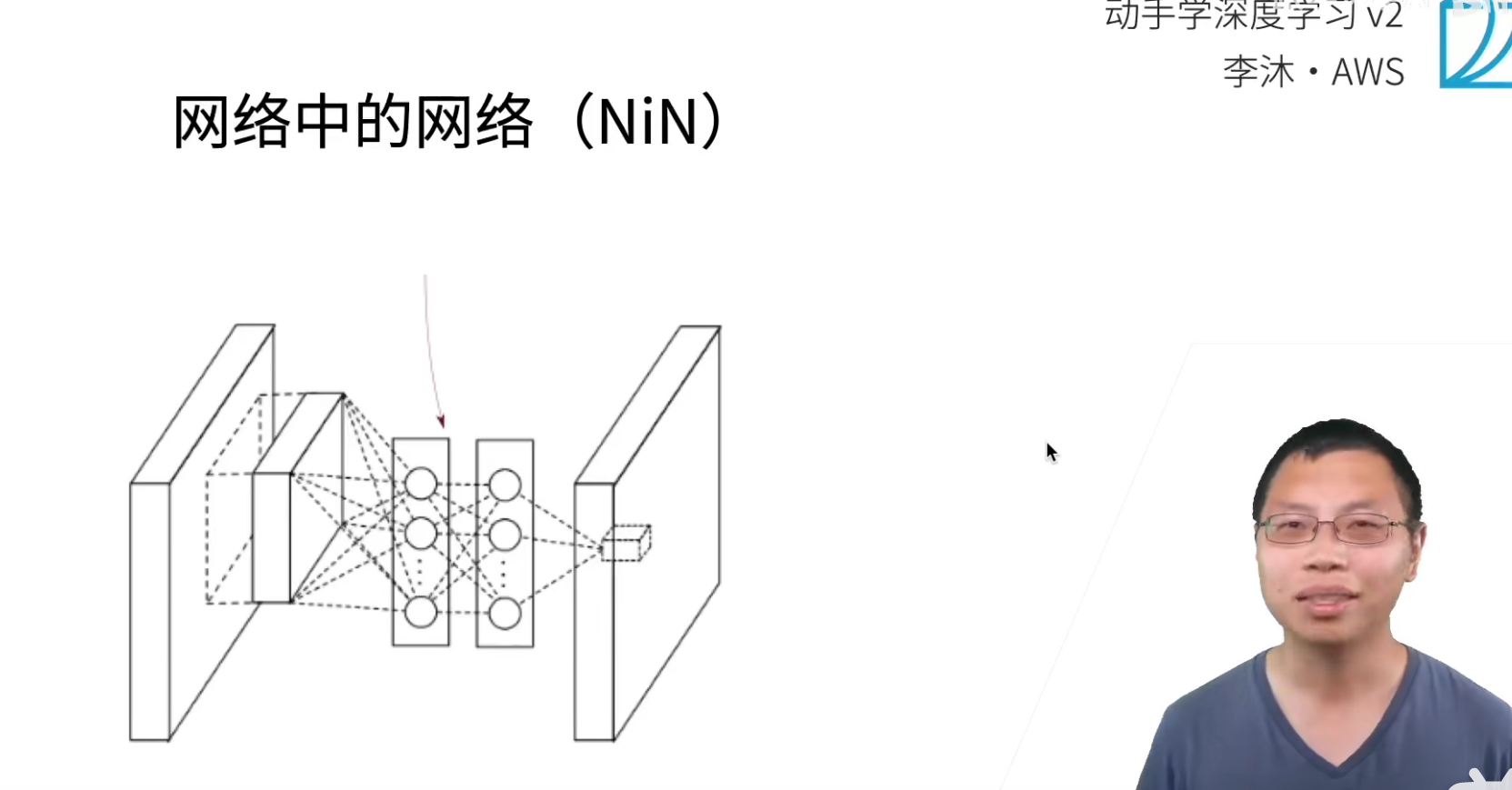
NiN Network in Network,网络中的网络,这个网路现在用的不多,几乎很少被用到,但是它里面提出了比较重要的一些概念,在后面很多网络中都会持续的被用到。

MLP其实是不错的,但是缺点就是参数量实在是太大了!
卷积层的参数相对于MLP会少很多,而且\(1*1\)卷积是可以达到于MLP的相同效果。
参数多会带来很多问题:一个是会占用很多内存,一个是会占用很多的计算带宽,还有一个最重要的事情就是MLP的参数过多,非常容易导致模型的过拟合。
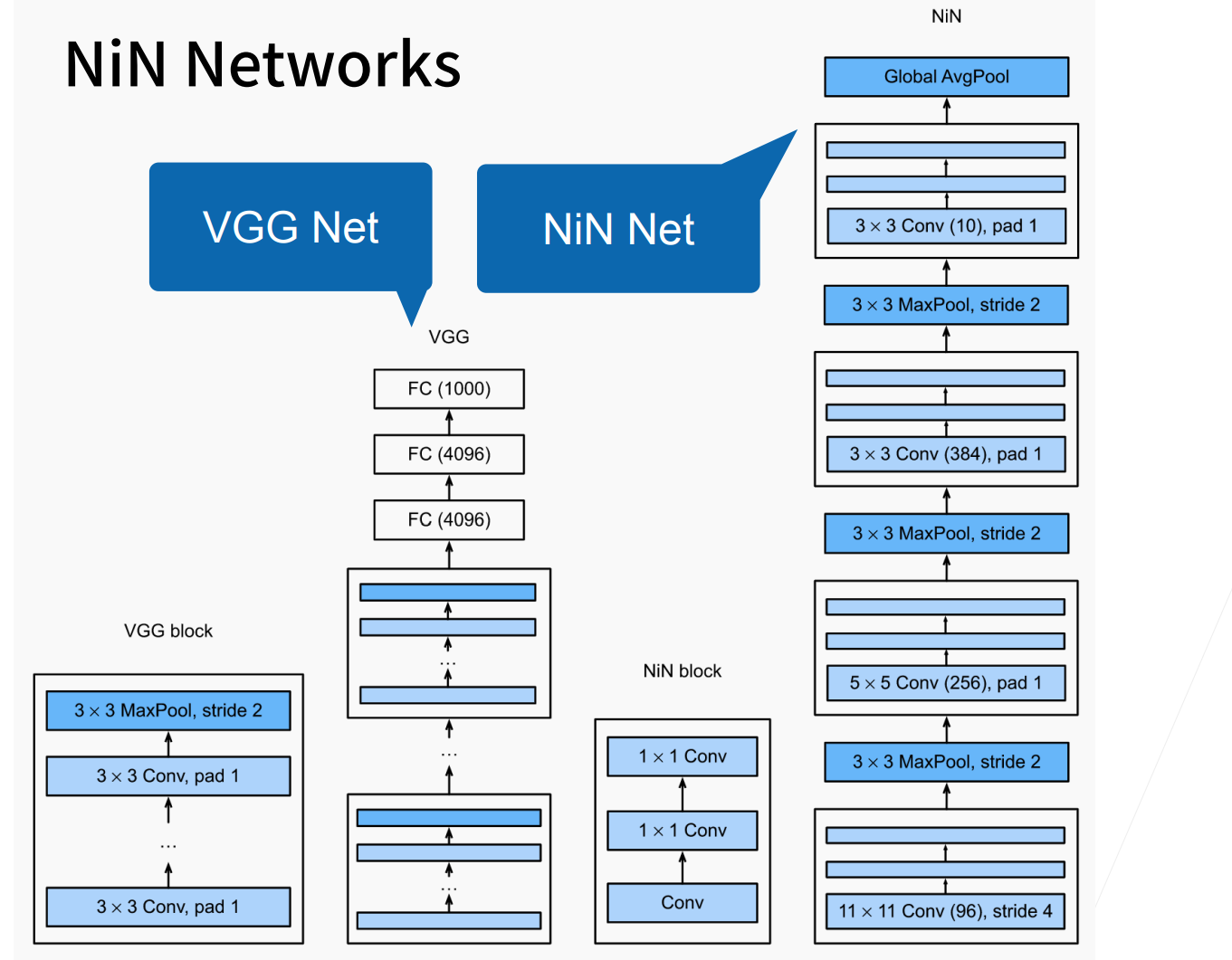
为了避免上述MLP带来的问题,NiN的思想就是完全不要全连接层,而是使用\(1*1\)的卷积来替代。

NiN块,VGG也有VGG块,后面基本卷积神经网都有自己的局部架构。

NiN无全连接层,最后使用一个全局平均池化层得到输出。
所谓的全局池化层,就是池化层的高宽,是等于输入的高宽,就等价对每个通道,把最大值给拿出来。当然一般要分多少类,那么最后的输出通道数就为多少。
NiN是包括最后也不使用MLP,这也是一个非常极端的一个设计。


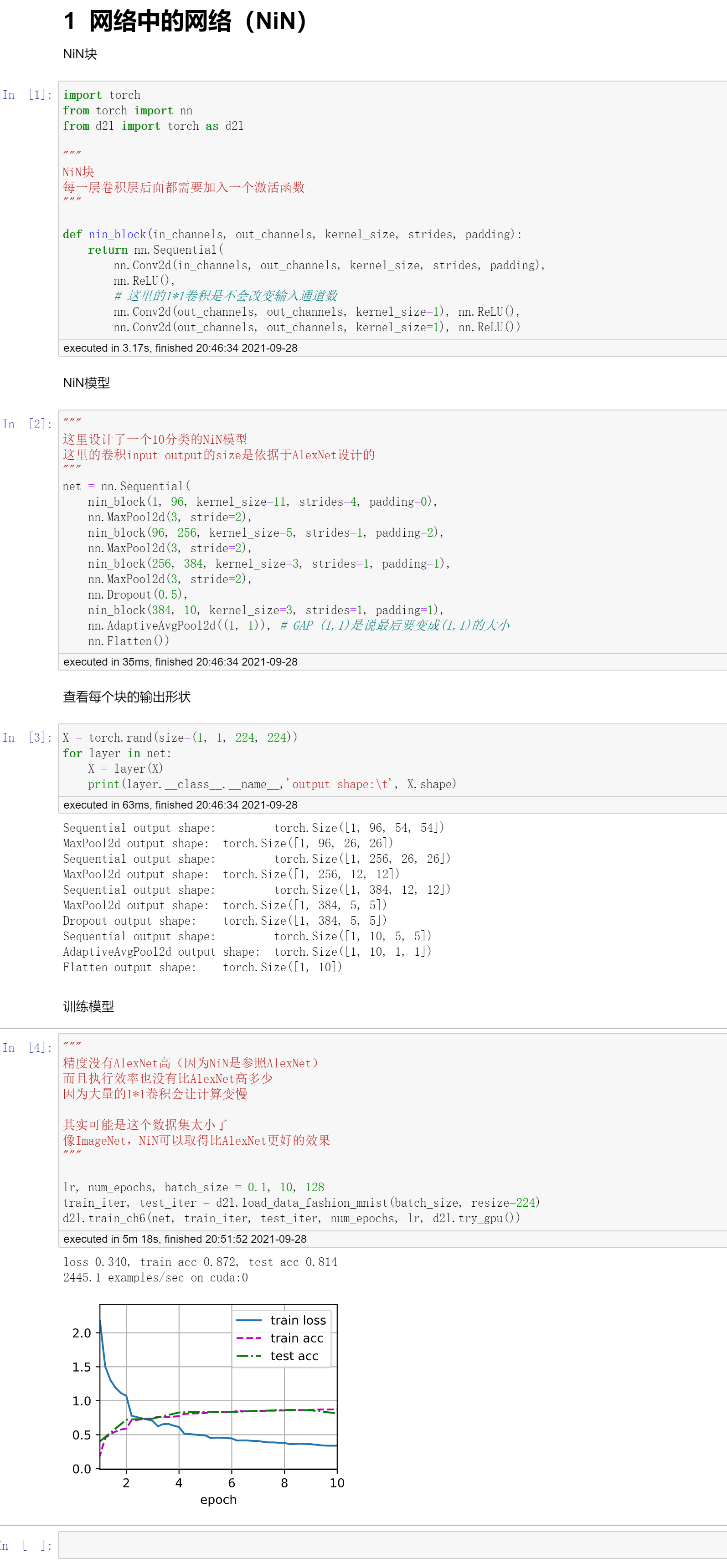
代码
QA
- 为什么这里分类最后没有使用softmax?
不是的,都是有使用softmax的,只不过softmax是写在train函数之中。
softmax是有一个自己的计算公式的(就可以看做是一个模型),然后分类问题使用的交叉熵损失函数。
一个最简洁的softmax模型是包含在Linear中的 net = nn.Sequential(nn.Flatten(),nn.Linear(784,10))
所以GAP不是去替代softmax,而是去替代全连接层。
- GAP的设计是不是很关键?
这个设计思想给后面带来了非常大的影响,后面大家发现这个东西,挺好用的。
GAP是没有学习的参数的,它就是最后把输出压缩成(1,1)。可以理解成GAP的最大作用就是降低了模型的复杂性。使用GAP会大大提高模型的泛化性。
但是GAP的一个缺点就是会让收敛变的很慢,反过来看,之所以AlexNet那些可以收敛的那么快,是因为最后的那两个MLP太厉害了,可以很好的进行数据的拟合。也就是AlexNet和VGG一般epoch=50即可,但是NiN可能epoch=120,这样扫多几次让其收敛。
绝大部分时候,训练久一点不要紧,精度好才是关键。
- 为什么NiN是使用了2个\(1*1\)的卷积,而不是3个?
沐神认为是试出来...

 浙公网安备 33010602011771号
浙公网安备 33010602011771号