动手学深度学习 | PyTorch神经网络基础 | 14
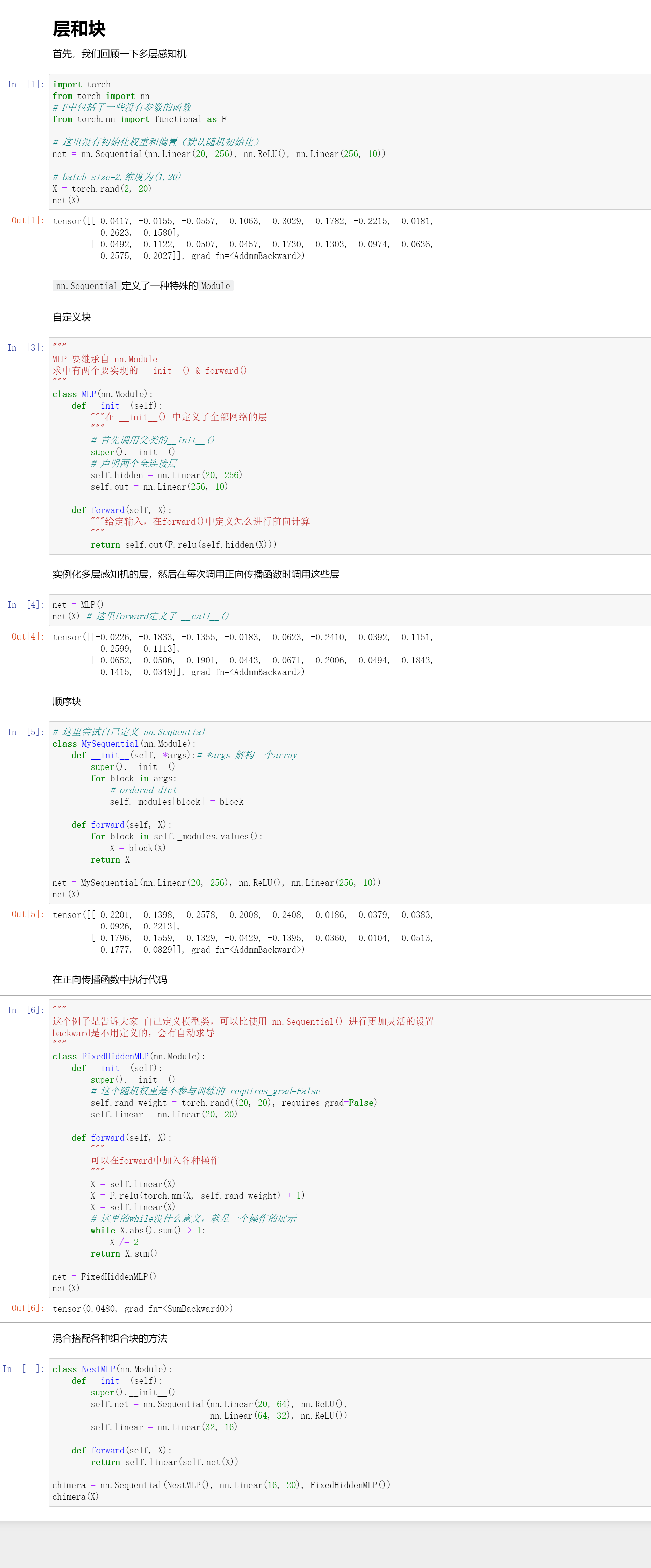
模型构造
这里主要是要继承nn.Module这个类,然后书写其中的__init__() & forward()方法即可。
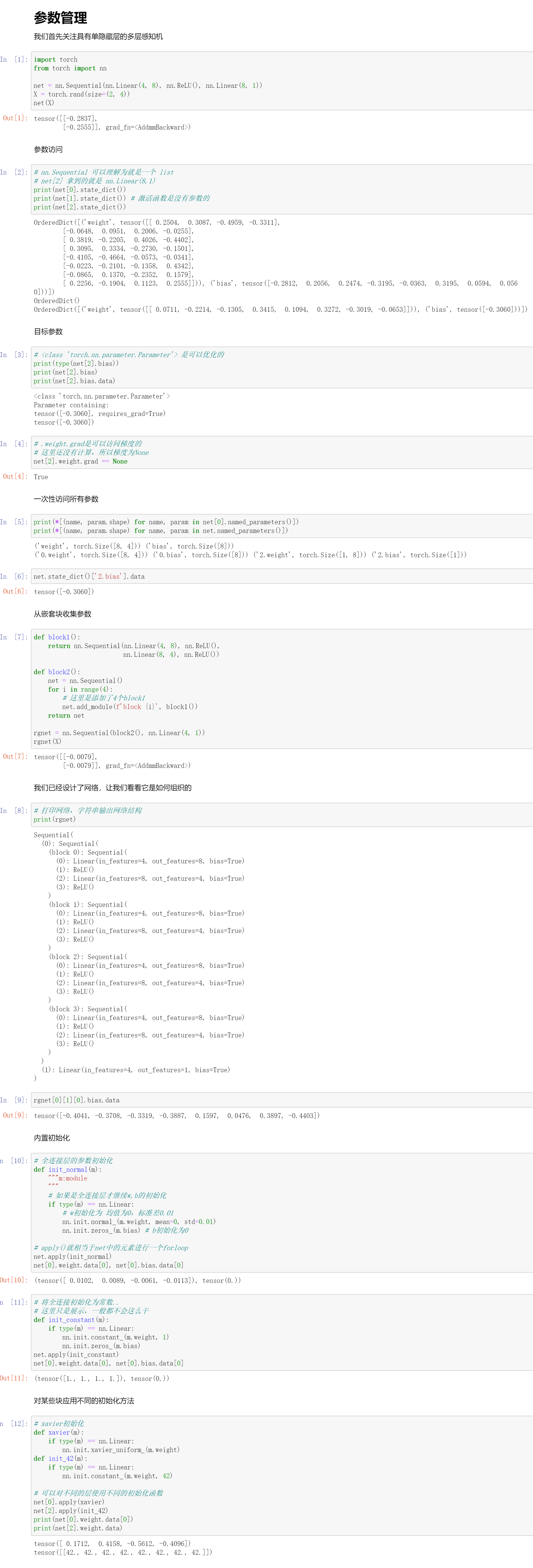
参数管理
假设我们已经定义好我们的模型了,那我们参数应该怎么去访问?

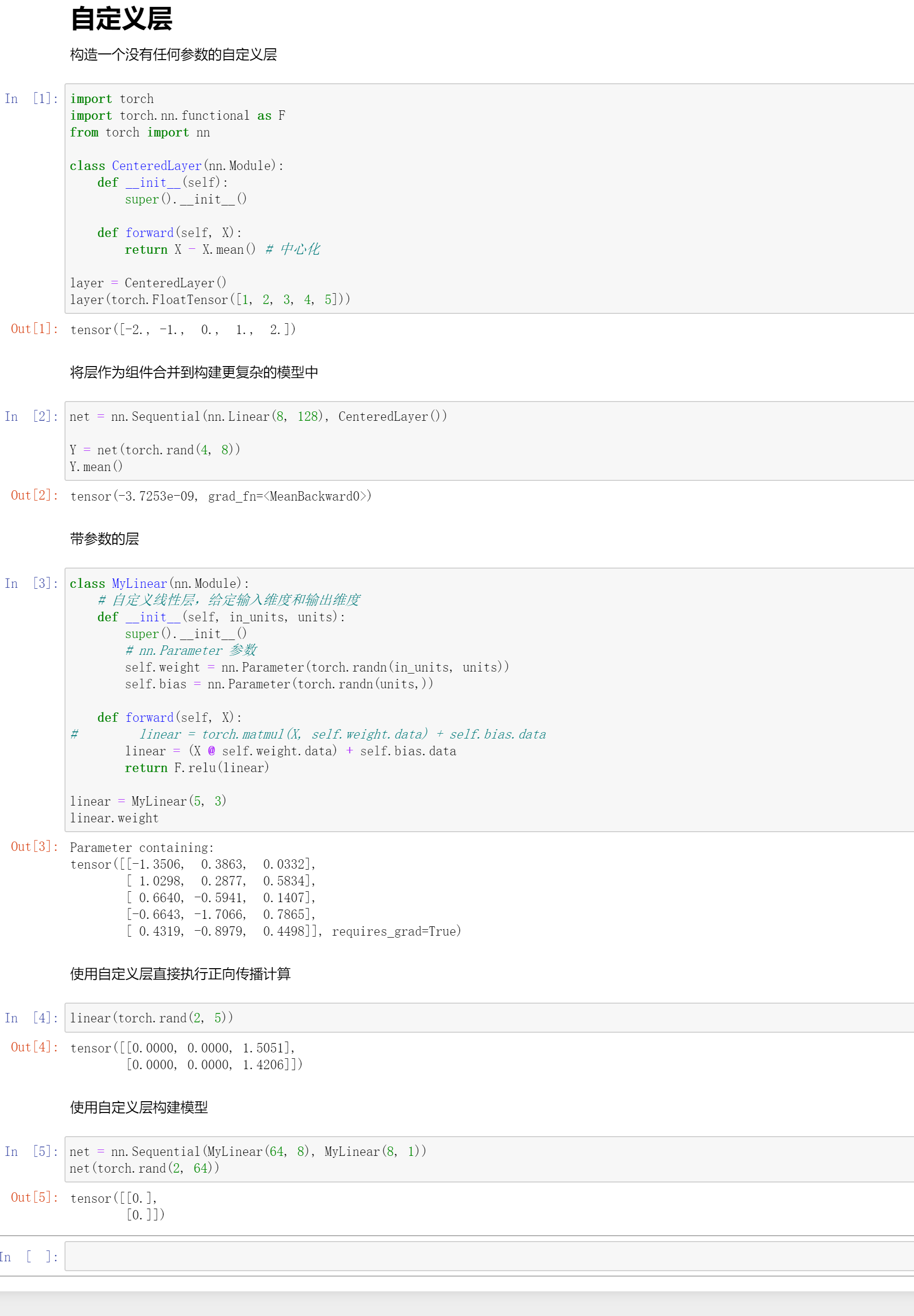
自定义层
自定层其实和自定义网络没有什么区别,因为层也是nn.Module的一个子类。
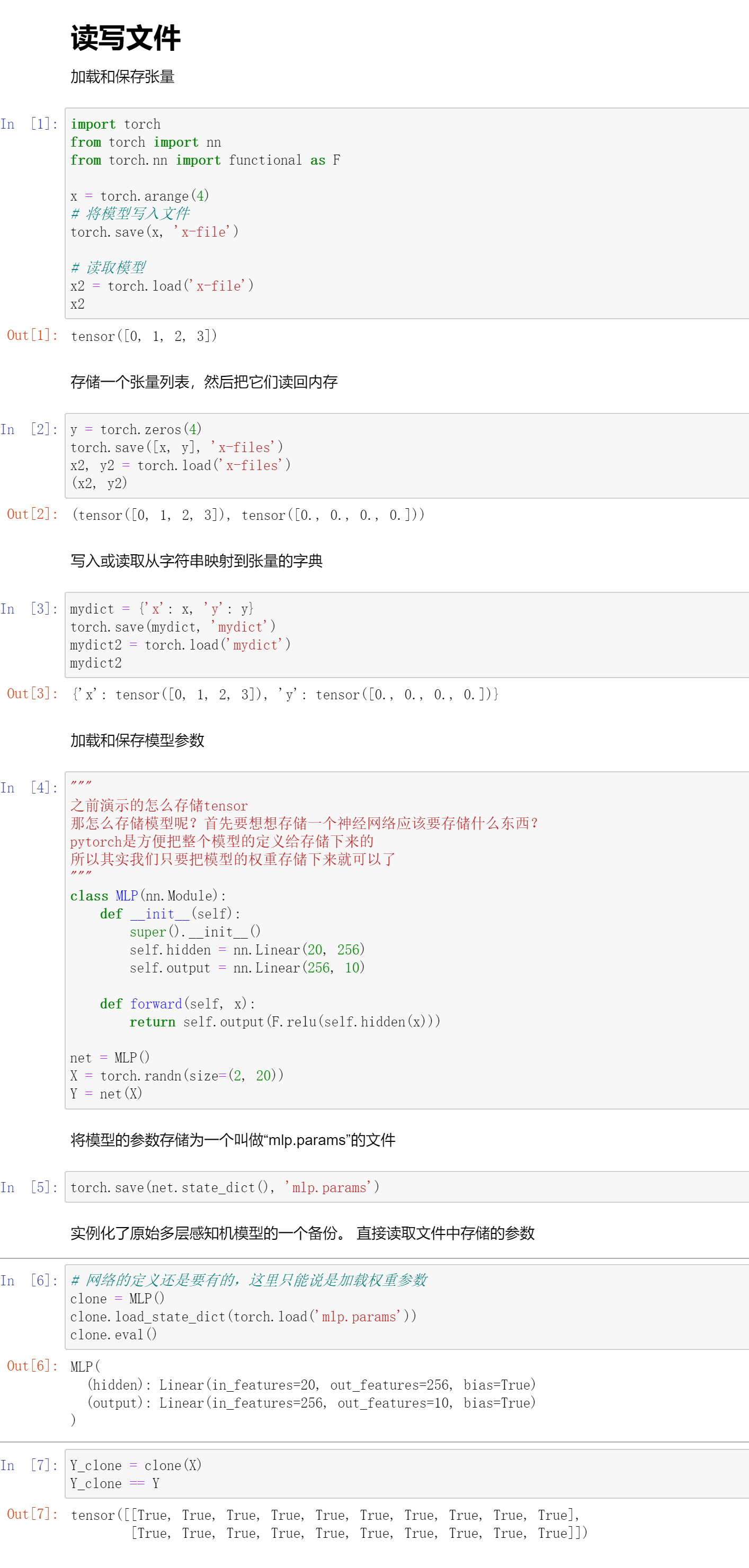
读写文件
读写文件,就是训练的东西怎么存下来,这个也是一个很关键的事情。
QA
- 将字符串转换为one-hot内存爆了怎么办?
这里有两个办法处理
- 一个是使用稀疏矩阵来存储,就不要把那些0都存储下来,这是一个常用的做法
- 如果是对竞赛的话,一个是地址肯定是很多不同的,还有就是简介,那这些其实是可以做提取词处理的。其实最简单的就是先放弃这个维度的特征(当然这样是不好的)关于字符串的处理还是需要一些NLP的知识的。
- MLP层数,以及每一层单元数是怎么设置的?
在之前课程的QA中有过MLP层数设计的经验的分享,其实这个还是要调参的... 就是试出来的好效果。
- 实例化后,不用调用实例方法,就可以
net(X),是因为父类实现了魔方方法吗?
是的,直接括号调用方法是因为父类nn.Module中已经实现了__call__方法。
- kaiming初始化是按什么规则初始化的?
其实这里是没有讲过kaiming初始化的,效果其实和xavier差不多。
其实大家不要太迷信初始化,初始化的主要目的就是就是让模型在一开始迭代的时候不要炸掉。
- 自定义的狐火函数如果是非可导的话auto-grad是否可以求出导数?还是必须先自定义导数?
其实应该说不存在不可导的函数,一般不可导都是在函数的几个离散点,都是可以求的,左导数或者右导数,导数会跳没有关系,一般都是可以导的。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号