动手学深度学习 | Softmax回归+损失函数+图片分类数据集 | 07
Softmax回归
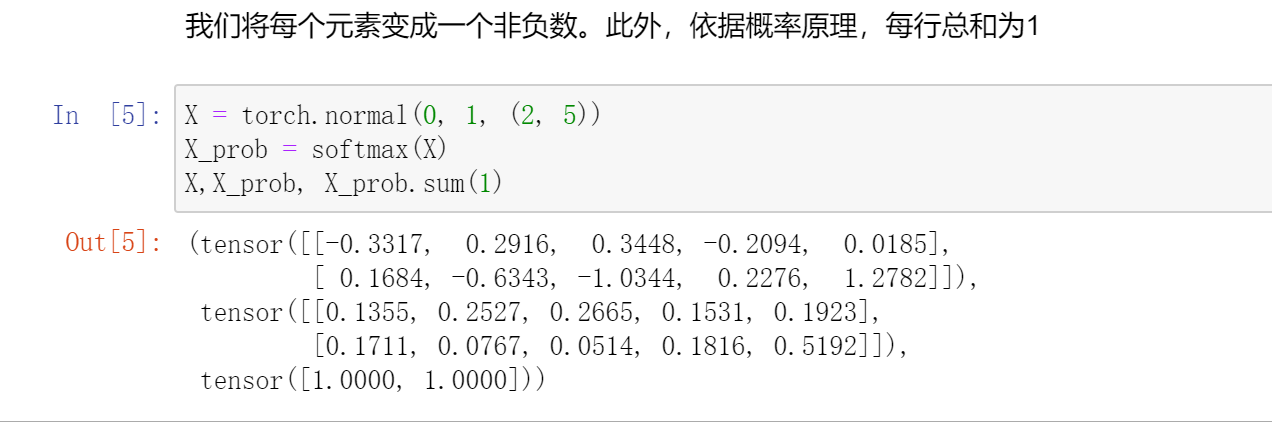
首先简单理解softmax:就是将一个回归值转换成一个概率(也就是把一个实数,定在[0,1.]中)

Softmax回归名字叫做回归,但其实是一个分类问题。(基本是个老师都会重复讲这句话)



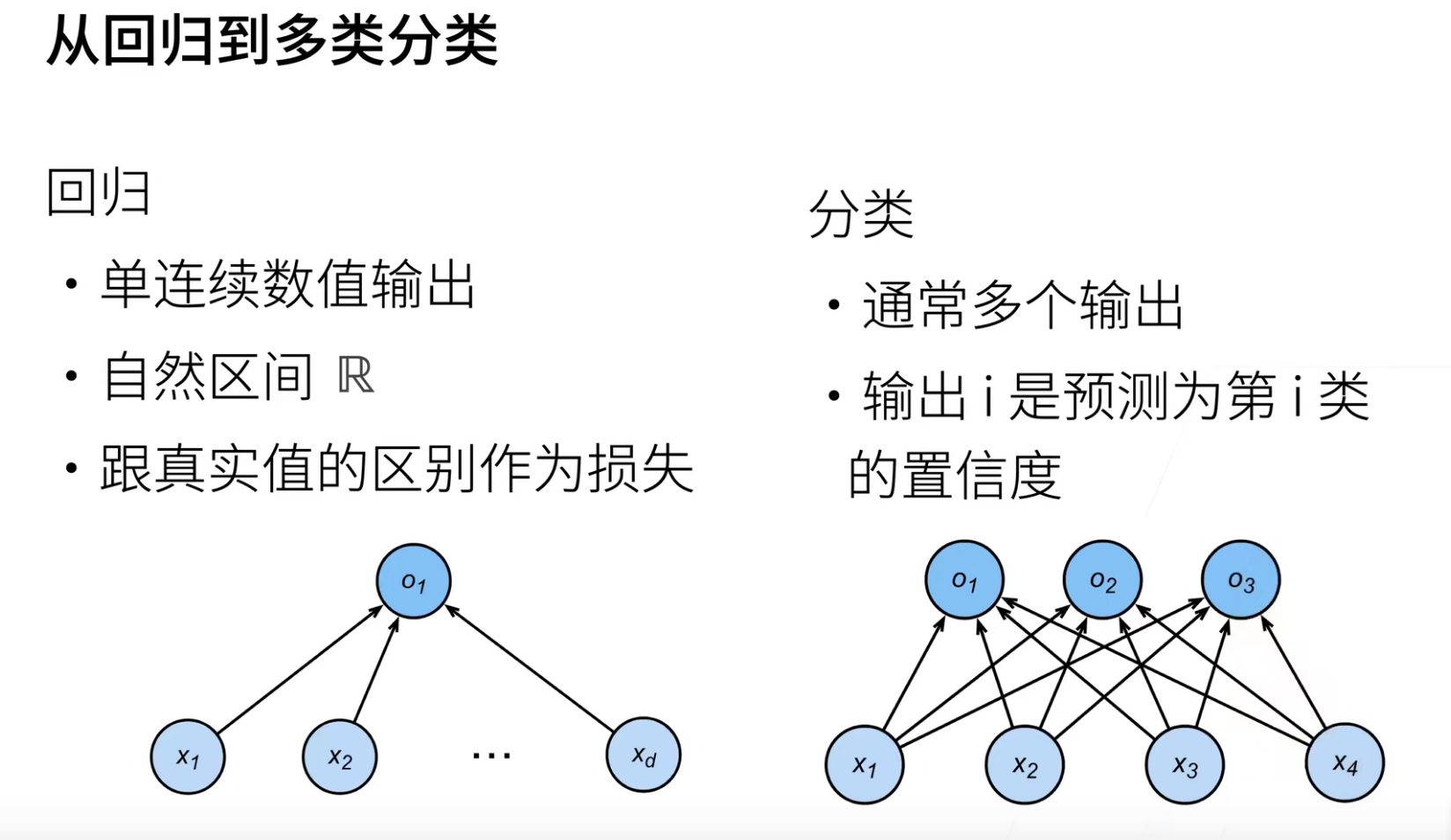
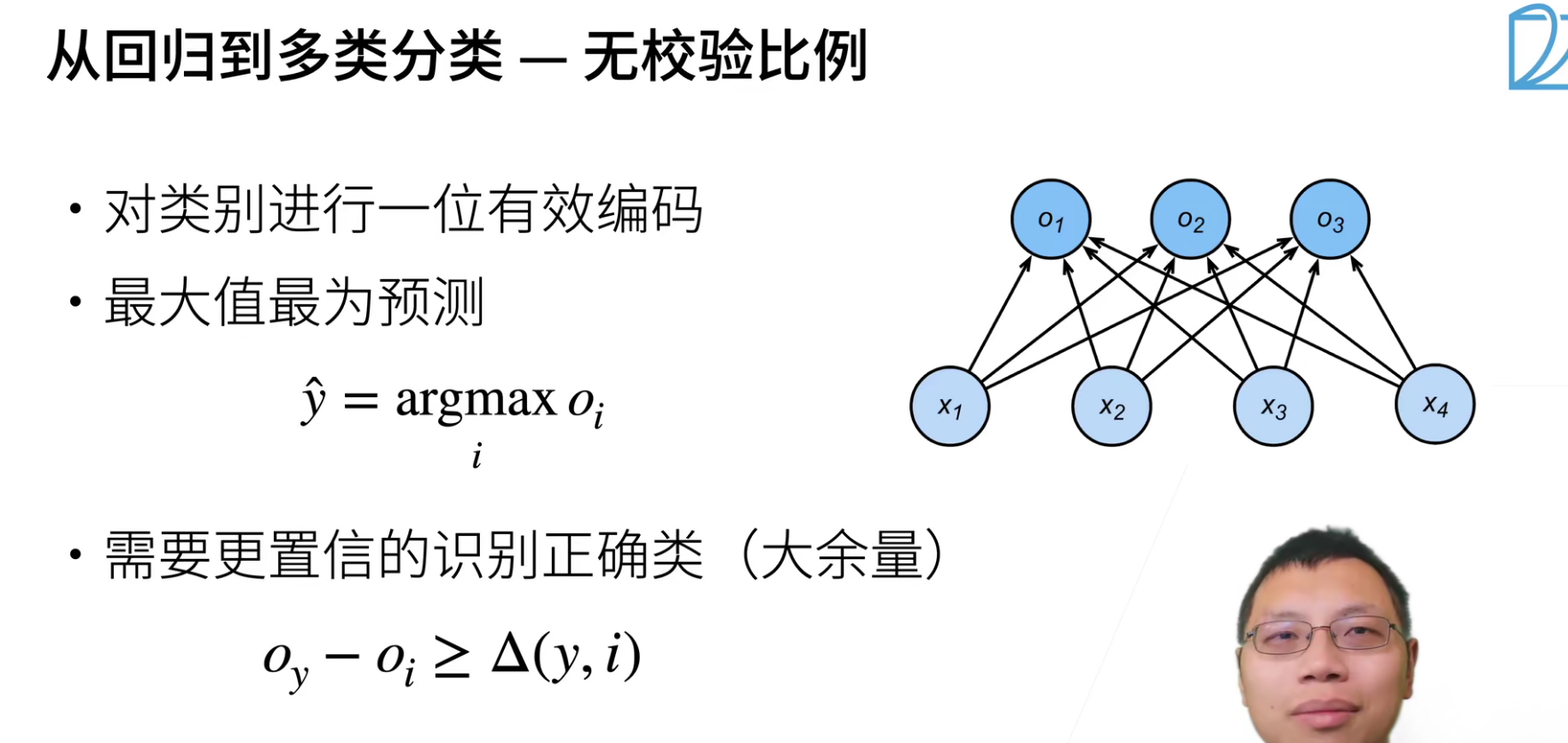
分类和回归的差别就在,回归只有一个输出,而分类是有多个输出。一般是有几个类别多少个输出。
并且分类输出的i是预测为第i类的置信度。
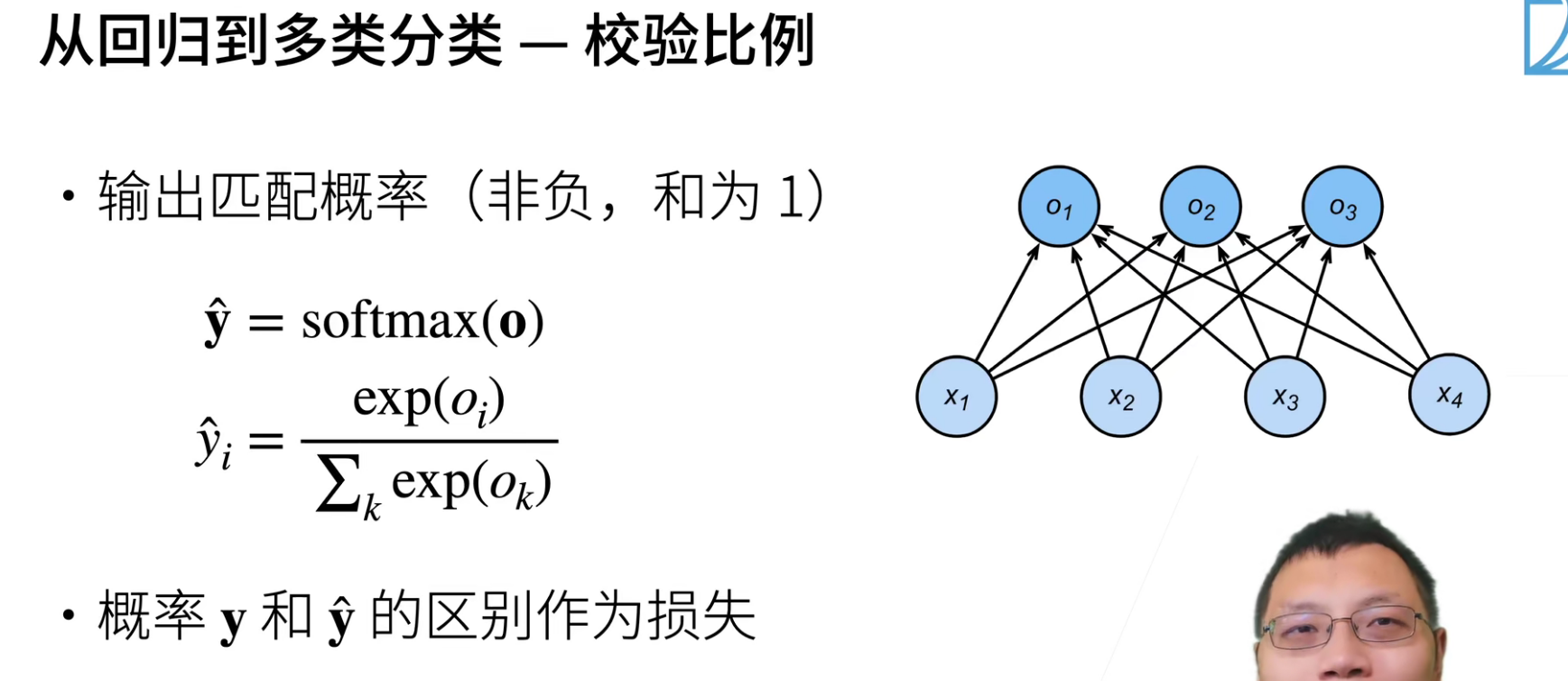
exp()这要要进行指数,是因为指数的好处就是不管什么值,都可以变成非负(概率不能是负数)。


softmax实际上可以理解成也是一个全连接层,得到对应类别的置信度(概率)是需要和之前的输出进行线性组合的。
最后分类问题的损失函数使用交叉熵损失函数(具体推到如果看不懂的话,建议先跳过)

损失函数
loss用来衡量真实值和预测值的差别,是机器学习中一个非常重要的概念。
这里给大家简单介绍3个常用的损失函数。

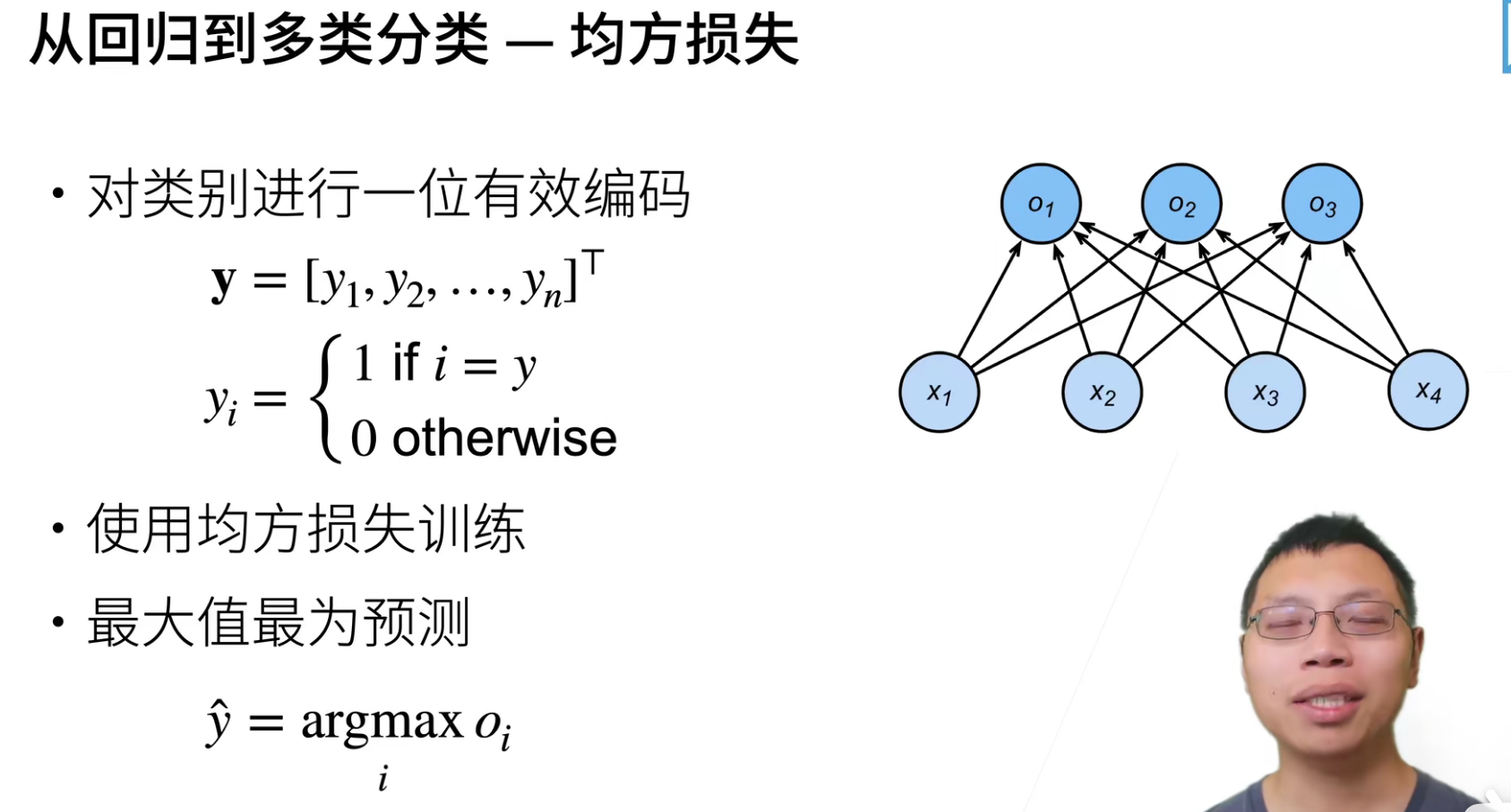
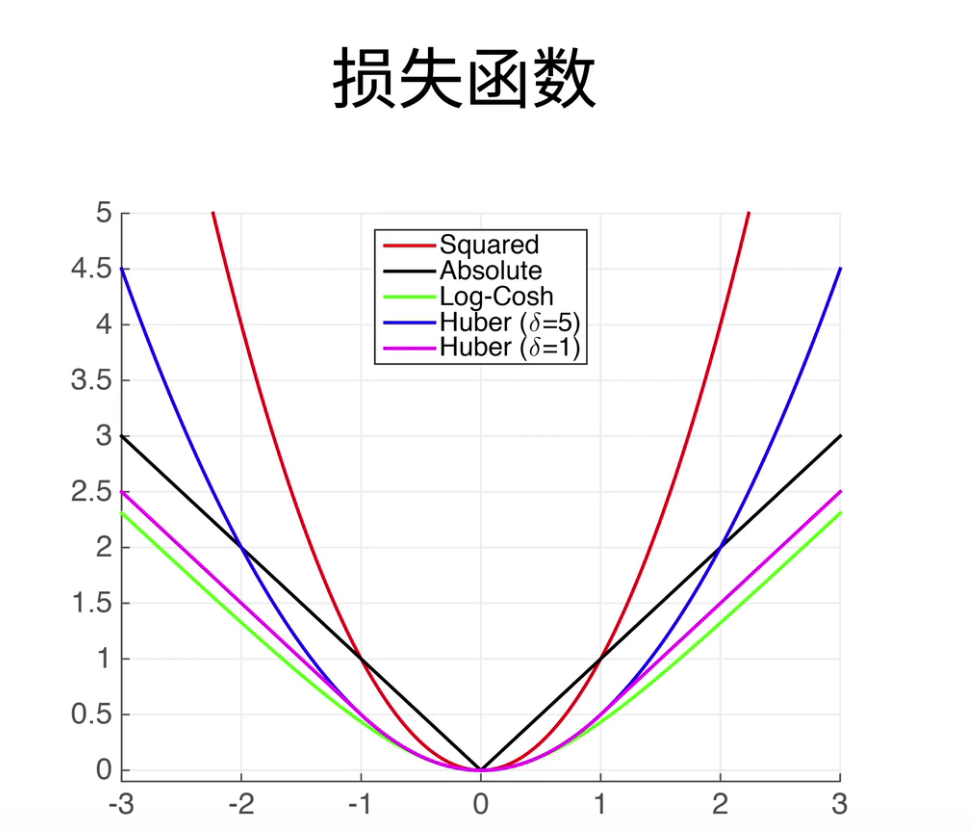
均方损失,也叫做L2 loss。
这里除2是为了方便求导的时候可以和平方的2进行抵消。
上面有3条线,可以可视化这个损失函数的特性。
- 蓝色:当y=0,变换预测值y',它的函数。可以看到它是一个二次函数
- 绿色:它的似然函数,我们并没有要将似然函数,但它确实是统计中一个非常重要的概念,可以看到它的似然函数就是一个高斯分布了。
- 橙色:梯度,我们知道它的梯度就是一个一次函数。
我们更新梯度的时候是根据负梯度方向来更新我们的参数,所以它的导数就决定如何来更新我们的参数,如上图红色箭头。大小要看梯度的值。但是有个不好的地方,就是其实预测值和真实值差的比较远的时候,其实有时候并不想更新那么大。
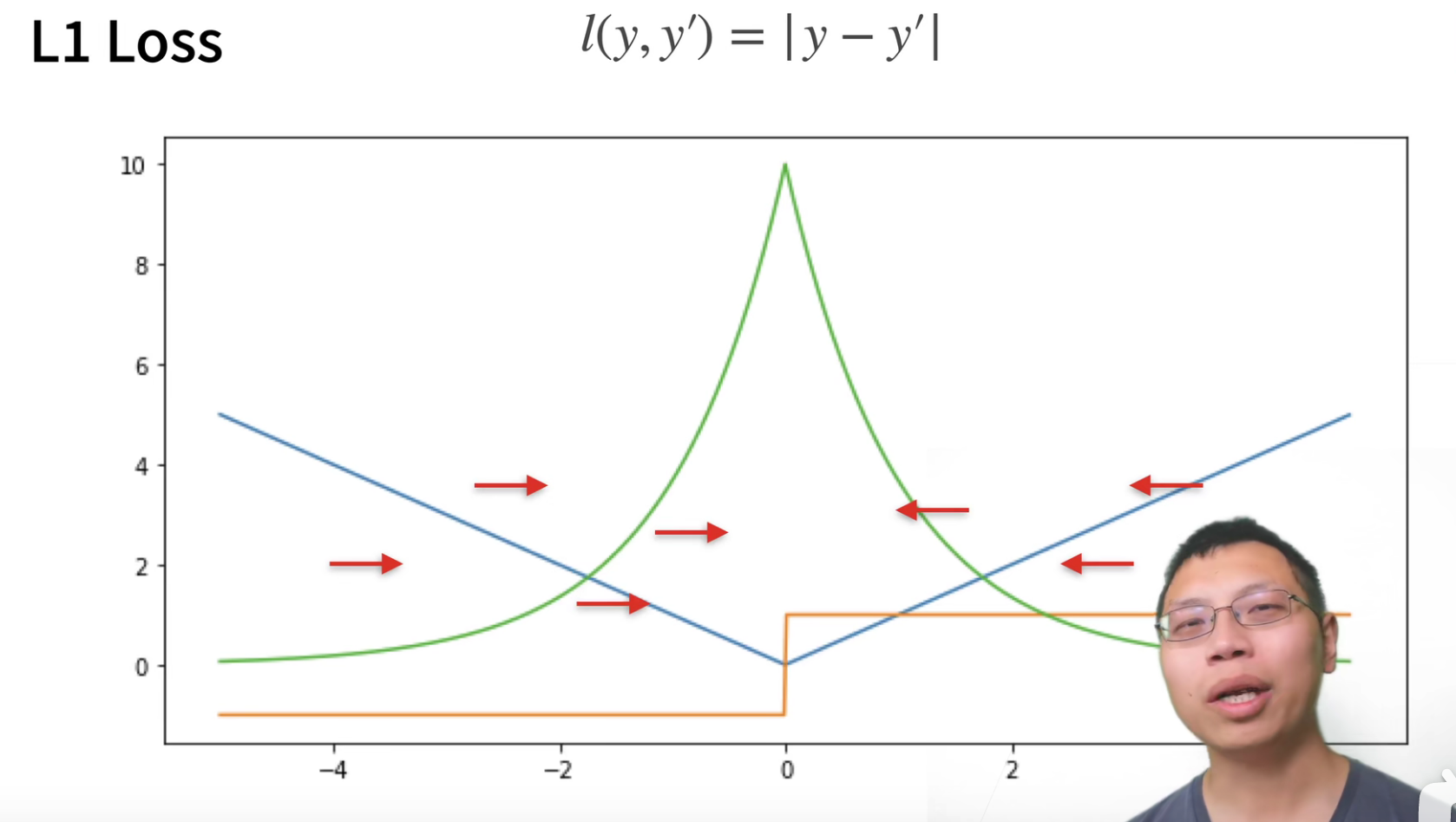
L1 loss,梯度就是一个常数,在-1,1。好处就是不管真实值和预测值相差多大,都可以对参数进行一个稳定的更新,这会带来很多稳定性上的好处。
绝对值函数在0点处是不可导的,所以在0点处会有一个比较剧烈的 变化,也就是当真实值预测值靠的比较近,也就是优化到末期,这里就会变得不那么稳定了。
Huber’s Robuts Loss就将L1 loss 和 L2 loss进行了结合。
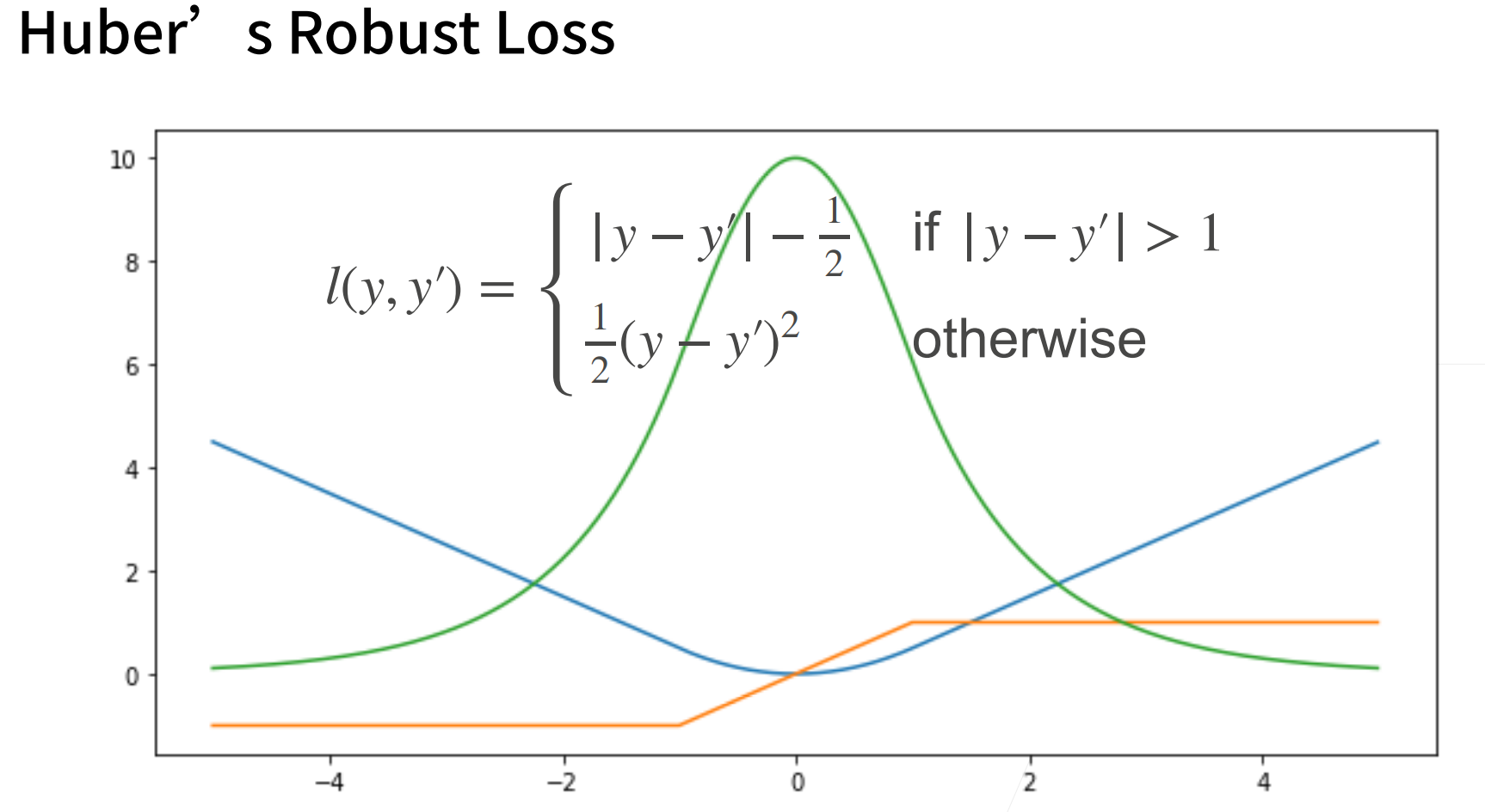
一般看损失函数,都是看其梯度的函数形状,来分析当预测值和真实值相差比较远,还有相差比较近的时候,分别是什么情况。
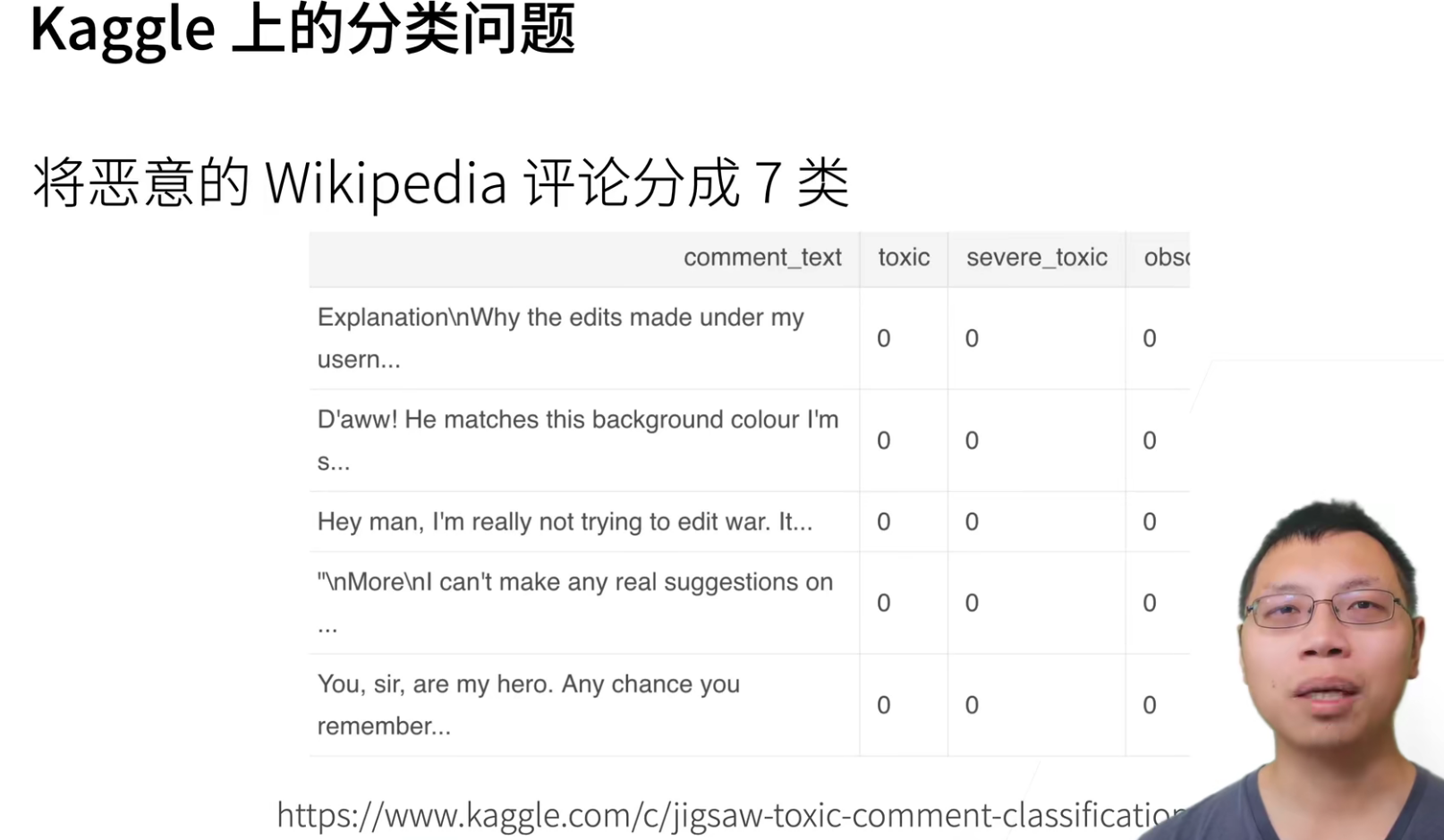
图片分类数据集
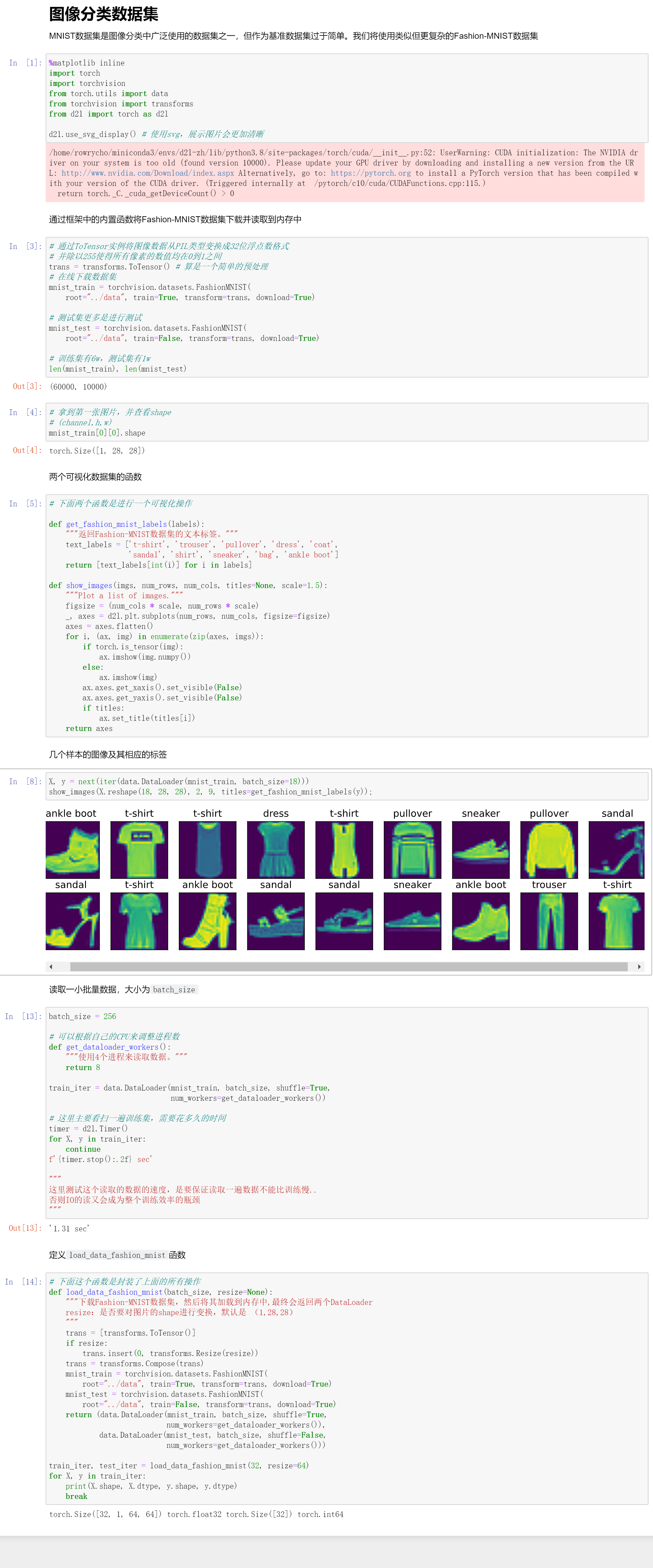
操作总结
def load_data_fashion_mnist(batch_size,resize=None):
# 通过ToTensor实例将图像数据从PIL类型变换成32位浮点数格式
trans = [transforms.ToTensor()]
if resize:
trans.insert(0, transforms.Resize(resize)) # 插入指定的位置
trans = transforms.Compose(trans) # 将多个transform操作进行组合
# 数据数据集
mnist_train = torchvision.datasets.FashionMNIST(root="../data", train=True, transform=trans, download=True)
mnist_test = torchvision.datasets.FashionMNIST(root="../data", train=False, transform=trans, download=True)
# 返回两个DataLoader
return (data.DataLoader(mnist_train, batch_size, shuffle=True,
num_workers=get_dataloader_workers()),
data.DataLoader(mnist_test, batch_size, shuffle=False,
num_workers=get_dataloader_workers()))
Softmax回归从零开始实现
Softmax也要从零开始实现,因为这是一个非常重要的模型,也是后面所有深度学习模型的一个基础。

操作总结
batch_size = 256
train_iter,test_iter = d2l.load_data_fashion_mnist(batch_size) # 加载batch_size的数据
num_inputs = 784
num_outputs = 10
# 这里初始化权重和参数
W = torch.normal(0, 0.01, size=(num_inputs, num_outputs), requires_grad=True)
b = torch.zeros(num_outputs, requires_grad=True) # 对每一个输出都要有一个偏移
# 定义了softmax函数
def softmax(X):
X_exp = torch.exp(X)
partition = X_exp.sum(1, keepdim=True) # 按照水平方向(行)来进行求和
return X_exp / partition # 这里应用了广播机制
# 实现了softmax回归模型
def net(X):
return softmax(torch.matmul(X.reshape((-1, W.shape[0])), W) + b)
# 交叉熵损失函数
def cross_entropy(y_hat, y):
return - torch.log(y_hat[range(len(y_hat)), y])
# 累加器
class Accumulator:
"""在`n`个变量上累加,这是一个累加器"""
def __init__(self, n):
self.data = [0.0] * n
def add(self, *args):
self.data = [a + float(b) for a, b in zip(self.data, args)] # 这是一个累加的过程
def reset(self):
self.data = [0.0] * len(self.data)
def __getitem__(self, idx): # 按照[] 取值
return self.data[idx]
# 计算真实值
def accuracy(y_hat, y):
"""计算预测正确的数量,也就是判断n行中可以预测对几个"""
# 如果存在多行,就只存储每一行的最大值下标
if len(y_hat.shape) > 1 and y_hat.shape[1] > 1:
y_hat = y_hat.argmax(axis=1)
cmp = y_hat.type(y.dtype) == y
# 返回预测正确的数目
return float(cmp.type(y.dtype).sum()) # 布尔类型转换int在求和
# 评估模型在数据集上的准确性
def evaluate_accuracy(net, data_iter):
"""计算在指定数据集上模型的精度,就是看模型在数据迭代器上的精度
net:模型
data_iter:数据迭代器
"""
if isinstance(net, torch.nn.Module): # 如果是使用了torch.nn.Module的模型
net.eval() # 将模型设置为评估模式
metric = Accumulator(2) # 正确预测数、预测总数
for X, y in data_iter:
metric.add(accuracy(net(X), y), y.numel()) # 不断地加入累加器中
return metric[0] / metric[1]
# softmax回归训练
def train_epoch_ch3(net, train_iter, loss, updater):
"""训练模型一个迭代周期(定义见第3章)。"""
if isinstance(net, torch.nn.Module):
net.train() # 开启训练模式,也就是要训练梯度
# [loss,correct_num,total]
metric = Accumulator(3)
for X, y in train_iter:
y_hat = net(X) # softmax回归函数
l = loss(y_hat, y) # 得到loss
if isinstance(updater, torch.optim.Optimizer):
updater.zero_grad()
l.backward()
updater.step()
metric.add(float(l) * len(y), accuracy(y_hat, y),
y.size().numel())
else:
l.sum().backward()
updater(X.shape[0]) # 根据批量大小,反向update一下
metric.add(float(l.sum()), accuracy(y_hat, y), y.numel())
return metric[0] / metric[2], metric[1] / metric[2]
# 训练函数
def train_ch3(net, train_iter, test_iter, loss, num_epochs, updater):
"""训练模型(定义见第3章)。"""
# 画图对象
animator = Animator(xlabel='epoch', xlim=[1, num_epochs], ylim=[0.3, 0.9],
legend=['train loss', 'train acc', 'test acc'])
for epoch in range(num_epochs):
train_metrics = train_epoch_ch3(net, train_iter, loss, updater)
test_acc = evaluate_accuracy(net, test_iter)
animator.add(epoch + 1, train_metrics + (test_acc,))
train_loss, train_acc = train_metrics
assert train_loss < 0.5, train_loss
assert train_acc <= 1 and train_acc > 0.7, train_acc
assert test_acc <= 1 and test_acc > 0.7, test_acc
# 使用SGD来优化模型的loss
lr = 0.1
def updater(batch_size):
return d2l.sgd([W, b], lr, batch_size)
# 训练10个周期
num_epochs = 10
# 这里还封装了一个动态的画图的功能,非常的酷炫(请面向github编程)
train_ch3(net, train_iter, test_iter, cross_entropy, num_epochs, updater)
Softmax回归简洁实现
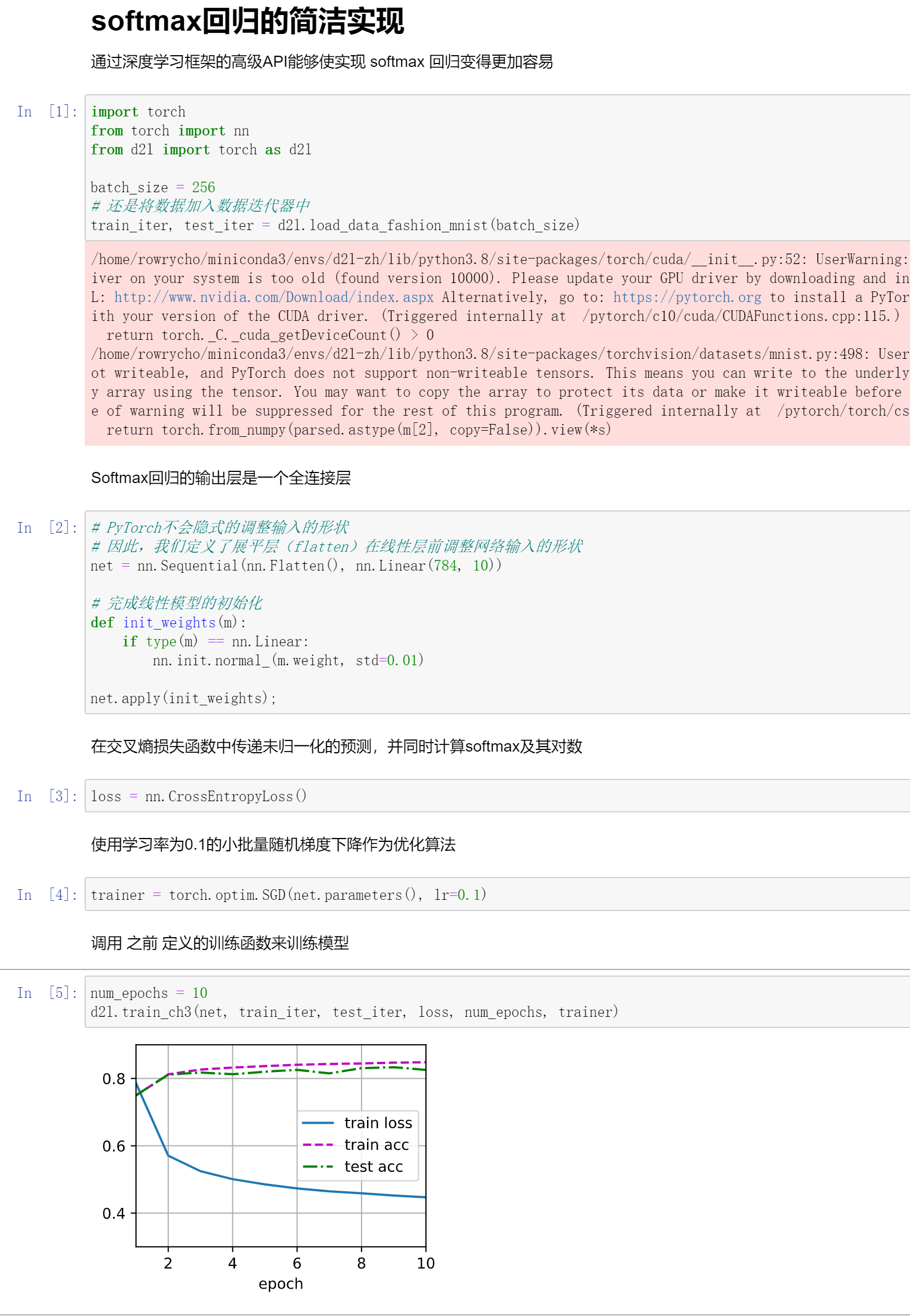
batch_size = 256
# 还是将数据加入数据迭代器中
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size)
# 将模型进行组合
net = nn.Sequential(nn.Flatten(), nn.Linear(784, 10))
# 完成线性模型的初始化
def init_weights(m):
if type(m) == nn.Linear:
nn.init.normal_(m.weight, std=0.01)
net.apply(init_weights);
# 交叉熵损失函数
loss = nn.CrossEntropyLoss()
# SGD
trainer = torch.optim.SGD(net.parameters(), lr=0.1)
# 训练10个epoch
num_epochs = 10
d2l.train_ch3(net, train_iter, test_iter, loss, num_epochs, trainer)
QA
- softmax回归和logistic回归分析是一样的吗?如果不一样的话,那些地方不同?
可以认为logistic回归是softmax回归的一个特例,因为前者的作用就是进行二分类任务,但是二分类任务只要预测一个类别就可以了,另一个类别的概率就是1-other。
softmax是用于多分类的。我们后面基本不会用到二分类,所以课程直接跳过了logistic回归,直接将softmax回归。
- 为什么用交叉熵,不用....等其他基于信息量的度量?
没有特别为什么,一个是交叉熵比较好算。
还有就是其实我们真正关注的就是两个分布的距离,能够得到这个距离就可以了。
- 交叉熵损失函数为什么我们只关心正确类,不关心不正确的类呢?
其实不是我们不关心不正确的类,而是因为one-hot编码就是把不正确类别的概率变成了0,导致我们计算的时候可以忽略掉不正确的类。
- 能对MSE的最大似然估计提一下吗?
没有讲似然函数,是因为这一块是统计中的概念。我们尽量不涉及太多的统计,是因为统计是可以用来解释我们模型的一个工具,反过来讲,后面的深度学习和统计没有太多的关系。所以我们主要讲的是线性代数,因为使用的所有结构是线性代数。
可以大概讲一下,最小化损失就等价于最大化似然函数。似然函数就是有个模型,给定数据的情况下,我的模型(也就是权重)出现的概率有多大?我们要最大化似然函数,也即是找到一个w,是的x出现的概率是最大的,这个也是最合理的解释。
下面这张最大似然函数和损失函数的关系图,也就很好理解了。

我们会稍微讲一点统计的东西,但是不会深入太多。
- batch_size的大小会训练时间的影响是什么?
如果CPU的话,基本是看不出区别的。
batch_size大一点的话,在GPU是可以提高训练的并行度,这样可以节约训练的时间。
当然,不管batch_size怎么取,训练的总体计算量是没有发生变化的。
- 为什么不在accuracy函数中除以len(y)做完呢?
因为最后一个batch可能是不能读满的,所以最好的做法就是Accumulator进行累加,最后在进行相除。
- 在多次迭代之后如果测试进度出现上升后再下降过拟合了吗?可以提前终止吗?
很有可能是过拟合了,其实可以再等等,但如果测试精度是一直下降的话,那很有可能是过拟合。
后面会讲一些策略来尽量避免,比如来微调学习率,当然也可以加入各种各样的正则项。
- cnn网络学习到的到底是什么信息?是纹理还是轮廓还是所有内容的综合,说不清的那种?
其实我们也不好说cnn学到了什么,目前,至少几年前,大家认为cnn是学到的纹理,轮廓cnn其实不那么在意。
- 如果是自己的图片数据集,需要怎么做才能用于训练,怎么根据本地图片训练集和测试机创建迭代器?
这个需要查阅框架的文档,基本都是在本地建立名字为类别的文件夹,然后在对应类别中放入图片,然后告诉框架上层目录即可。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号