
人脸识别智能小程序 | Tensorflow挑战Cifar-10图像分类任务 | 04
TF挑战cifar10

cifar100有两类标签,一个是大类标签,一个是小类标签,也就是一个是粗粒度标签,一个是细粒度标签,

上面的代码是解析cifar10的,前面已经讲解过,这里不再赘述。

使用 tf.train.string_input_producer 的方式来对打包好的TFRecord文件进行读取。
将所有的训练样本存放在 train.tfrecord,将所有的测试样本存放在 test.tfrecord。

TF训练框架搭建:
- Data
首先是数据的读取和数据的打包。
- Net
网络的搭建,这里采用slim来搭建网络结构,因为slim是对tf更加高层的封装,可以写更加简洁的代码。
- Loss
Loss本身就是网络的一部分,这个会采用softmaxLoss来进行Loss定义。
另外还会定义正则化的Loss。
- Summary
Summary完成了训练过程中日志的记录。
- Session
Session完成了构造出网络结构后,如果对计算图中的结点进行计算,会通过Session在后端完成整个网络的BP。并通过Feed给网络数据,Fetch获得输出的张量。


训练代码,也就是baseline版本,要如何进行优化呢?上面提供了几个参考思路。
- 更多的数据增强策略,比如:mixup等
通过数据增强的策略,来丰富样本量,进而提高模型对更多样本的泛化能力。
- 更好的主干网络,比如:SENet等
有VGG,ResNet这样的主干网络,当然,SENet比ResNet的性能更好,可以实验哪个主干网络实验出来的效果更好。
- 更好的标签策略,比如:Soft-label策略
cifar10的标签就是从0到9十个标签,这里可以采用soft-label的策略,比如有些物体既像飞机又像汽车,那么就可以采用软的策略,来对标签进行预处理。
- 更好的loss设计,比如:采用分类+回归smooth-l1 loss等
另外可以采用更好的loss,这里采用交叉熵损失来完成图像分类的任务,另外大家也可以考虑结合回归的loss,来进行一个多个loss的约束。
- 不同的优化器、参数初始化方法等

Cifar10数据读取与数据增强
文件项目的目录结构如上图
- data: 存放数据 这里是打包好的TFRecord
- logdirs:存放log日志信息
- model:存放训练好的模型
readcifar10.py
import tensorflow as tf
def read(batchsize=64, type=1, no_aug_data=1):
"""
读取TFRecord的脚本
params
batchsize:批大小 默认64
type: test or train 表示从test中读数据还是从train中读数据 0表示train 1表示test
no_aug_data: 是否进行数据增强 1 or 0
"""
reader = tf.TFRecordReader()
"""
搭建模型的时候每训练一定的次数,或每训练一个epoch的时候,这时候会从test文件进行一次测试
"""
if type == 0: # train
file_list = ["data/train.tfrecord"]
if type == 1: # test
file_list = ["data/test.tfrecord"]
filename_queue = tf.train.string_input_producer(
file_list, num_epochs=None, shuffle=True
)
_, serialized_example = reader.read(filename_queue)
batch = tf.train.shuffle_batch([serialized_example], batchsize, capacity=batchsize * 10,
min_after_dequeue=batchsize * 5)
#
feature = {'image': tf.FixedLenFeature([], tf.string),
'label': tf.FixedLenFeature([], tf.int64)}
features = tf.parse_example(batch, features=feature)
images = features["image"]
img_batch = tf.decode_raw(images, tf.uint8)
img_batch = tf.cast(img_batch, tf.float32)
img_batch = tf.reshape(img_batch, [batchsize, 32, 32, 3])
"""
这里对train的数据进行数据增强
数据增强只对train数据
"""
if type == 0 and no_aug_data == 1:
# 随机裁剪
distorted_image = tf.random_crop(img_batch,
[batchsize, 28, 28, 3])
# 随机对比度
distorted_image = tf.image.random_contrast(distorted_image,
lower=0.8,
upper=1.2)
# 随机色调
distorted_image = tf.image.random_hue(distorted_image,
max_delta=0.2)
# 随机饱和度
distorted_image = tf.image.random_saturation(distorted_image,
lower=0.8,
upper=1.2)
# 对处理过的图像进行取值范围的约束
img_batch = tf.clip_by_value(distorted_image, 0, 255)
# 最后将图像resize回[32,32]
img_batch = tf.image.resize_images(img_batch, [32, 32])
label_batch = tf.cast(features['label'], tf.int64)
# [-1,1] 将图片归一化
img_batch = tf.cast(img_batch, tf.float32) / 128.0 - 1.0
return img_batch, label_batch
TensorFlow+Slim网络结构搭建
def model(image, keep_prob=0.8, is_training=True):
"""
在model中我们会定义网络结构
params
image: 输入的图片
return 概率分布值 10 dim vector
"""
# batchnorm的参数
batch_norm_params = {
"is_training": is_training, # train:True test:False
"epsilon": 1e-5, # 这个值是防止batchnorm在归一化的时候除0
"decay": 0.997, # 衰减系数
'scale': True,
'updates_collections': tf.GraphKeys.UPDATE_OPS
}
"""
定义优化器
用 slim.arg_scope()为目标函数设置默认参数.
下面两个with,完成卷积默认参数的初始化和pooling层默认参数的初始化
一个with就是一个参数域 网络可以使用通过的参数
"""
with slim.arg_scope(
[slim.conv2d], # 这里是给 slim.conv2d 规定过了后面的参数
weights_initializer=slim.variance_scaling_initializer(), # 方差尺度不变来进行初始化
activation_fn=tf.nn.relu, # 默认激活函数为relu 在卷积之后加入激活函数
weights_regularizer=slim.l2_regularizer(
0.0001), # 权值的正则化约束 正则项权值为0.0001
normalizer_fn=slim.batch_norm, # 在卷积机后加入 BatchNorm
normalizer_params=batch_norm_params):
with slim.arg_scope([slim.max_pool2d], padding="SAME"): # 给 slim.max_pool2d 规定参数
"""
接下来利用卷积层、池化层、全连接层搭建一个cifar10用于图像分类的全连接网
"""
# 输入image 学习32个卷积核(channel) 卷积核大小 [3,3] 卷积层命名 conv1
net = slim.conv2d(image, 32, [3, 3], scope='conv1')
# 输入net 学习32个卷积核 卷积核大小 [3,3] 卷积层命名 conv2
net = slim.conv2d(net, 32, [3, 3], scope='conv2')
# 输入net 池化核大小[3,3] stride=2(进行两倍下采样)
net = slim.max_pool2d(net, [3, 3], stride=2, scope='pool1')
"""
===========
上面 conv+conv+maxpool 算是一个基本单元,后面基本就是使用这样的基本单元进行堆叠
==========
"""
# 每次经过pooling之后 卷积层channel的数量应该翻倍
net = slim.conv2d(net, 64, [3, 3], scope='conv3')
net = slim.conv2d(net, 64, [3, 3], scope='conv4')
net = slim.max_pool2d(net, [3, 3], stride=2, scope='pool2')
net = slim.conv2d(net, 128, [3, 3], scope='conv5')
net = slim.conv2d(net, 128, [3, 3], scope='conv6')
net = slim.max_pool2d(net, [3, 3], stride=2, scope='pool3')
# 经过8倍下采样之后 在加入一个卷积层
net = slim.conv2d(net, 256, [3, 3], scope='conv7')
"""
特征图维度 (n,h,w,c)
对 h,w 进行均值的求解 得到 (n,1,1,c) 因为 reduce_mean 就是降维求平均
"""
net = tf.reduce_mean(net, axis=[1, 2]) # nhwc--n11c
"""
slim.flatten 将输入扁平化但保留batch_size,假设第一维是batch。
将 (n,1,1,c) 转为 (n,c)
"""
net = slim.flatten(net)
# 全连接层 这里还不着急分类 (1,1024)可以作为从图像中提取出来的特征
net = slim.fully_connected(net, 1024)
"""
全连接层的参数太多 要加入dropout层 来进行正则化
keep_prob 概率值 定义了我们对当前神经元选择的概率
在训练和测试的时候,这个概率要取不同的值 训练的时候要取<1 测试的时候要=1
"""
slim.dropout(net, keep_prob)
# 输出为10 对应了10个分类类别
net = slim.fully_connected(net, 10)
return net # 10 dim vec
这里的模型设计基本是沿用了VGG的设计思路,采用了\(3*3\)的小卷积核,每次pooling后对channel的数量进行翻倍,并且在全连接层后面加入了dropout层。另外在经过8倍下采样后采用了一个average pooling层,进行一个全图的池化,最后输出一个10维的概率分布值。
Loss、Optimal、Learning Rate、BN等定义
Loss层定义
def loss(logits, label):
"""
loss使用交叉熵损失函数
param
logits: 预测出来的概率分布值
label: 实际的label
return 分类的loss
"""
# 对label进行one-hot编码 定义one-hot长度为10
one_hot_label = slim.one_hot_encoding(label, 10)
# 使用交叉熵损失函数 并传入 预测值 和 one-hot label
slim.losses.softmax_cross_entropy(logits, one_hot_label)
"""
在前面 slim.arg_scope 中定义了weights_regularizer=slim.l2_regularizer(0.0001)
通过 tf.GraphKeys.REGULARIZATION_LOSSES 可以拿到这些loss正则化的集合
"""
reg_set = tf.get_collection(tf.GraphKeys.REGULARIZATION_LOSSES)
# 将这些正则化loss进行相加 计算出总体的l2_loss
l2_loss = tf.add_n(reg_set)
# 将 l2_loss添加到loss中
slim.losses.add_loss(l2_loss)
totalloss = slim.losses.get_total_loss()
# 这里为了后面做日志,这里把l2_loss也传出
return totalloss, l2_loss
Train部分代码编写
初代Train代码
import os
import tensorflow as tf
import readcifar10
from tqdm import tqdm
slim = tf.contrib.slim
slim = tf.contrib.slim
def model(image, keep_prob=0.8, is_training=True):
"""
在model中我们会定义网络结构
params
image: 输入的图片
return 概率分布值 10 dim vector
"""
# batchnorm的参数
batch_norm_params = {
"is_training": is_training, # train:True test:False
"epsilon": 1e-5, # 这个值是防止batchnorm在归一化的时候除0
"decay": 0.997, # 衰减系数
'scale': True,
'updates_collections': tf.GraphKeys.UPDATE_OPS
}
"""
定义优化器
用 slim.arg_scope()为目标函数设置默认参数.
下面两个with,完成卷积默认参数的初始化和pooling层默认参数的初始化
一个with就是一个参数域 网络可以使用通过的参数
"""
with slim.arg_scope(
[slim.conv2d], # 这里是给 slim.conv2d 规定过了后面的参数
weights_initializer=slim.variance_scaling_initializer(), # 方差尺度不变来进行初始化
activation_fn=tf.nn.relu, # 默认激活函数为relu 在卷积之后加入激活函数
weights_regularizer=slim.l2_regularizer(
0.0001), # 权值的正则化约束 正则项权值为0.0001
normalizer_fn=slim.batch_norm, # 在卷积机后加入 BatchNorm
normalizer_params=batch_norm_params):
with slim.arg_scope([slim.max_pool2d], padding="SAME"): # 给 slim.max_pool2d 规定参数
"""
接下来利用卷积层、池化层、全连接层搭建一个cifar10用于图像分类的全连接网
"""
# 输入image 学习32个卷积核(channel) 卷积核大小 [3,3] 卷积层命名 conv1
net = slim.conv2d(image, 32, [3, 3], scope='conv1')
# 输入net 学习32个卷积核 卷积核大小 [3,3] 卷积层命名 conv2
net = slim.conv2d(net, 32, [3, 3], scope='conv2')
# 输入net 池化核大小[3,3] stride=2(进行两倍下采样)
net = slim.max_pool2d(net, [3, 3], stride=2, scope='pool1')
"""
===========
上面 conv+conv+maxpool 算是一个基本单元,后面基本就是使用这样的基本单元进行堆叠
==========
"""
# 每次经过pooling之后 卷积层channel的数量应该翻倍
net = slim.conv2d(net, 64, [3, 3], scope='conv3')
net = slim.conv2d(net, 64, [3, 3], scope='conv4')
net = slim.max_pool2d(net, [3, 3], stride=2, scope='pool2')
net = slim.conv2d(net, 128, [3, 3], scope='conv5')
net = slim.conv2d(net, 128, [3, 3], scope='conv6')
net = slim.max_pool2d(net, [3, 3], stride=2, scope='pool3')
# 经过8倍下采样之后 在加入一个卷积层
net = slim.conv2d(net, 256, [3, 3], scope='conv7')
"""
特征图维度 (n,h,w,c)
对 h,w 进行均值的求解 得到 (n,1,1,c) 因为 reduce_mean 就是降维求平均
"""
net = tf.reduce_mean(net, axis=[1, 2]) # nhwc--n11c
"""
slim.flatten 将输入扁平化但保留batch_size,假设第一维是batch。
将 (n,1,1,c) 转为 (n,c)
"""
net = slim.flatten(net)
# 全连接层 这里还不着急分类 (1,1024)可以作为从图像中提取出来的特征
net = slim.fully_connected(net, 1024)
"""
全连接层的参数太多 要加入dropout层 来进行正则化
keep_prob 概率值 定义了我们对当前神经元选择的概率
在训练和测试的时候,这个概率要取不同的值 训练的时候要取<1 测试的时候要=1
"""
slim.dropout(net, keep_prob)
# 输出为10 对应了10个分类类别
net = slim.fully_connected(net, 10)
return net # 10 dim vec
def loss(logits, label):
"""
loss使用交叉熵损失函数
param
logits: 预测出来的概率分布值
label: 实际的label
return 分类的loss
"""
# 对label进行one-hot编码 定义one-hot长度为10
one_hot_label = slim.one_hot_encoding(label, 10)
# 使用交叉熵损失函数 并传入 预测值 和 one-hot label
slim.losses.softmax_cross_entropy(logits, one_hot_label)
"""
在前面 slim.arg_scope 中定义了weights_regularizer=slim.l2_regularizer(0.0001)
通过 tf.GraphKeys.REGULARIZATION_LOSSES 可以拿到这些loss正则化的集合
"""
reg_set = tf.get_collection(tf.GraphKeys.REGULARIZATION_LOSSES)
# 将这些正则化loss进行相加 计算出总体的l2_loss
l2_loss = tf.add_n(reg_set)
# 将 l2_loss添加到loss中
slim.losses.add_loss(l2_loss)
totalloss = slim.losses.get_total_loss()
# 这里为了后面做日志,这里把l2_loss也传出
return totalloss, l2_loss
def func_optimal(batchsize, loss_val):
"""
定义优化器
"""
global_step = tf.Variable(0, trainable=False)
# 通过指数衰减的形式来定义学习率
lr = tf.train.exponential_decay(0.01,
global_step,
decay_steps=50000 // batchsize,
decay_rate=0.95,
staircase=False)
update_ops = tf.get_collection(tf.GraphKeys.UPDATE_OPS)
with tf.control_dependencies(update_ops):
op = tf.train.AdamOptimizer(lr).minimize(loss_val, global_step)
"""
global_step 可以得到当前的迭代次数
op sess.run()执行op可以完成对网络参数的调节
lr 返回 便于log信息的记录
"""
return global_step, op, lr
def train():
batchsize = 64
floder_log = 'logdirs'
floder_model = 'model'
if not os.path.exists(floder_log):
os.mkdir(floder_log)
if not os.path.exists(floder_model):
os.mkdir(floder_model)
# data
tr_im, tr_label = readcifar10.read(batchsize, 0, 1)
te_im, te_label = readcifar10.read(batchsize, 1, 0)
# net
"""
tf.placeholder 此函数可以理解为形参,用于定义过程,在执行的时候再赋具体的值
训练数据 [None,32,32,3] None是考虑到batch_size是可以变化的
"""
input_data = tf.placeholder(tf.float32, shape=[None, 32, 32, 3],
name='input_data')
input_label = tf.placeholder(tf.int64, shape=[None],
name='input_label')
"""
keep_prob dropout的概率值
训练过程 keep_prob 也就是dropout的概率值 为0.5 或小于1的值
"""
keep_prob = tf.placeholder(tf.float32, shape=None,
name='keep_prob')
is_training = tf.placeholder(tf.bool, shape=None,
name='is_training')
logits = model(
input_data, keep_prob=keep_prob, is_training=is_training)
# loss
"""
损失函数 传入预测的结果和真实的标签
"""
total_loss, l2_loss = loss(logits, input_label)
# accurancy
"""
tf.argmax 获取最大值的索引
[n,10] axis=1 计算的是10维这个维度最大值对应的索引值
"""
pred_max = tf.argmax(logits, 1)
# 判断最大值索引和 label是否相等
correct = tf.equal(pred_max, input_label)
accurancy = tf.reduce_mean(tf.cast(correct, tf.float32))
# op
global_step, op, lr = func_optimal(batchsize, total_loss)
with tf.Session() as sess:
# 初始化参数 包括了局部变量和全局变量
sess.run(tf.group(tf.global_variables_initializer(),
tf.local_variables_initializer()))
# 启动文件队列写入的线程
tf.train.start_queue_runners(sess=sess,
coord=tf.train.Coordinator())
epoch_val = 10
# 读取文件队列中的数据,完成对网络的训练
for i in tqdm(range(50000 * epoch_val)):
train_im_batch, train_label_batch = \
sess.run([tr_im, tr_label])
feed_dict = {
input_data: train_im_batch,
input_label: train_label_batch,
keep_prob: 0.8,
is_training: True
}
# 注意 这里得到这这些值 都是一个batch_size的
_, global_step_val, \
lr_val, \
total_loss_val, \
accurancy_val = sess.run([op,
global_step,
lr,
total_loss,
accurancy],
feed_dict=feed_dict)
# 每隔一百次打印一次
if i % 20 == 0:
print("\n{},{},{},{}".format(global_step_val,
lr_val,
total_loss_val,
accurancy_val))
return
if __name__ == '__main__':
train()
Test部分代码编写
在完成一部分train,可以进行test
import os
import tensorflow as tf
import readcifar10
from tqdm import tqdm
slim = tf.contrib.slim
slim = tf.contrib.slim
def model(image, keep_prob=0.8, is_training=True):
"""
在model中我们会定义网络结构
params
image: 输入的图片
return 概率分布值 10 dim vector
"""
# batchnorm的参数
batch_norm_params = {
"is_training": is_training, # train:True test:False
"epsilon": 1e-5, # 这个值是防止batchnorm在归一化的时候除0
"decay": 0.997, # 衰减系数
'scale': True,
'updates_collections': tf.GraphKeys.UPDATE_OPS
}
"""
定义优化器
用 slim.arg_scope()为目标函数设置默认参数.
下面两个with,完成卷积默认参数的初始化和pooling层默认参数的初始化
一个with就是一个参数域 网络可以使用通过的参数
"""
with slim.arg_scope(
[slim.conv2d], # 这里是给 slim.conv2d 规定过了后面的参数
weights_initializer=slim.variance_scaling_initializer(), # 方差尺度不变来进行初始化
activation_fn=tf.nn.relu, # 默认激活函数为relu 在卷积之后加入激活函数
weights_regularizer=slim.l2_regularizer(
0.0001), # 权值的正则化约束 正则项权值为0.0001
normalizer_fn=slim.batch_norm, # 在卷积机后加入 BatchNorm
normalizer_params=batch_norm_params):
with slim.arg_scope([slim.max_pool2d], padding="SAME"): # 给 slim.max_pool2d 规定参数
"""
接下来利用卷积层、池化层、全连接层搭建一个cifar10用于图像分类的全连接网
"""
# 输入image 学习32个卷积核(channel) 卷积核大小 [3,3] 卷积层命名 conv1
net = slim.conv2d(image, 32, [3, 3], scope='conv1')
# 输入net 学习32个卷积核 卷积核大小 [3,3] 卷积层命名 conv2
net = slim.conv2d(net, 32, [3, 3], scope='conv2')
# 输入net 池化核大小[3,3] stride=2(进行两倍下采样)
net = slim.max_pool2d(net, [3, 3], stride=2, scope='pool1')
"""
===========
上面 conv+conv+maxpool 算是一个基本单元,后面基本就是使用这样的基本单元进行堆叠
==========
"""
# 每次经过pooling之后 卷积层channel的数量应该翻倍
net = slim.conv2d(net, 64, [3, 3], scope='conv3')
net = slim.conv2d(net, 64, [3, 3], scope='conv4')
net = slim.max_pool2d(net, [3, 3], stride=2, scope='pool2')
net = slim.conv2d(net, 128, [3, 3], scope='conv5')
net = slim.conv2d(net, 128, [3, 3], scope='conv6')
net = slim.max_pool2d(net, [3, 3], stride=2, scope='pool3')
# 经过8倍下采样之后 在加入一个卷积层
net = slim.conv2d(net, 256, [3, 3], scope='conv7')
"""
特征图维度 (n,h,w,c)
对 h,w 进行均值的求解 得到 (n,1,1,c) 因为 reduce_mean 就是降维求平均
"""
net = tf.reduce_mean(net, axis=[1, 2]) # nhwc--n11c
"""
slim.flatten 将输入扁平化但保留batch_size,假设第一维是batch。
将 (n,1,1,c) 转为 (n,c)
"""
net = slim.flatten(net)
# 全连接层 这里还不着急分类 (1,1024)可以作为从图像中提取出来的特征
net = slim.fully_connected(net, 1024)
"""
全连接层的参数太多 要加入dropout层 来进行正则化
keep_prob 概率值 定义了我们对当前神经元选择的概率
在训练和测试的时候,这个概率要取不同的值 训练的时候要取<1 测试的时候要=1
"""
slim.dropout(net, keep_prob)
# 输出为10 对应了10个分类类别
net = slim.fully_connected(net, 10)
return net # 10 dim vec
def loss(logits, label):
"""
loss使用交叉熵损失函数
param
logits: 预测出来的概率分布值
label: 实际的label
return 分类的loss
"""
# 对label进行one-hot编码 定义one-hot长度为10
one_hot_label = slim.one_hot_encoding(label, 10)
# 使用交叉熵损失函数 并传入 预测值 和 one-hot label
slim.losses.softmax_cross_entropy(logits, one_hot_label)
"""
在前面 slim.arg_scope 中定义了weights_regularizer=slim.l2_regularizer(0.0001)
通过 tf.GraphKeys.REGULARIZATION_LOSSES 可以拿到这些loss正则化的集合
"""
reg_set = tf.get_collection(tf.GraphKeys.REGULARIZATION_LOSSES)
# 将这些正则化loss进行相加 计算出总体的l2_loss
l2_loss = tf.add_n(reg_set)
# 将 l2_loss添加到loss中
slim.losses.add_loss(l2_loss)
totalloss = slim.losses.get_total_loss()
# 这里为了后面做日志,这里把l2_loss也传出
return totalloss, l2_loss
def func_optimal(batchsize, loss_val):
"""
定义优化器
"""
global_step = tf.Variable(0, trainable=False)
# 通过指数衰减的形式来定义学习率
lr = tf.train.exponential_decay(0.01,
global_step,
decay_steps=50000 // batchsize,
decay_rate=0.95,
staircase=False)
update_ops = tf.get_collection(tf.GraphKeys.UPDATE_OPS)
with tf.control_dependencies(update_ops):
op = tf.train.AdamOptimizer(lr).minimize(loss_val, global_step)
"""
global_step 可以得到当前的迭代次数
op sess.run()执行op可以完成对网络参数的调节
lr 返回 便于log信息的记录
"""
return global_step, op, lr
def train():
batchsize = 64
floder_log = 'logdirs'
floder_model = 'model'
if not os.path.exists(floder_log):
os.mkdir(floder_log)
if not os.path.exists(floder_model):
os.mkdir(floder_model)
# data
tr_im, tr_label = readcifar10.read(batchsize, 0, 1)
te_im, te_label = readcifar10.read(batchsize, 1, 0)
# net
"""
tf.placeholder 此函数可以理解为形参,用于定义过程,在执行的时候再赋具体的值
训练数据 [None,32,32,3] None是考虑到batch_size是可以变化的
"""
input_data = tf.placeholder(tf.float32, shape=[None, 32, 32, 3],
name='input_data')
input_label = tf.placeholder(tf.int64, shape=[None],
name='input_label')
"""
keep_prob dropout的概率值
训练过程 keep_prob 也就是dropout的概率值 为0.5 或小于1的值
"""
keep_prob = tf.placeholder(tf.float32, shape=None,
name='keep_prob')
is_training = tf.placeholder(tf.bool, shape=None,
name='is_training')
logits = model(
input_data, keep_prob=keep_prob, is_training=is_training)
# loss
"""
损失函数 传入预测的结果和真实的标签
"""
total_loss, l2_loss = loss(logits, input_label)
# accurancy
"""
tf.argmax 获取最大值的索引
[n,10] axis=1 计算的是10维这个维度最大值对应的索引值
"""
pred_max = tf.argmax(logits, 1)
# 判断最大值索引和 label是否相等
correct = tf.equal(pred_max, input_label)
accurancy = tf.reduce_mean(tf.cast(correct, tf.float32))
# op
global_step, op, lr = func_optimal(batchsize, total_loss)
with tf.Session() as sess:
# 初始化参数 包括了局部变量和全局变量
sess.run(tf.group(tf.global_variables_initializer(),
tf.local_variables_initializer()))
# 启动文件队列写入的线程
tf.train.start_queue_runners(sess=sess,
coord=tf.train.Coordinator())
epoch_val = 10
# 读取文件队列中的数据,完成对网络的训练
for i in tqdm(range(50000 * epoch_val)): # 这里这个数量我还是没有理解
train_im_batch, train_label_batch = \
sess.run([tr_im, tr_label])
feed_dict = {
input_data: train_im_batch,
input_label: train_label_batch,
keep_prob: 0.8,
is_training: True
}
# 注意 这里得到这这些值 都是一个batch_size的
_, global_step_val, \
lr_val, \
total_loss_val, \
accurancy_val = sess.run([op,
global_step,
lr,
total_loss,
accurancy],
feed_dict=feed_dict)
# 每隔一百次打印一次
if i % 100 == 0:
print("\n[trian]:{},{},{},{}".format(global_step_val,
lr_val,
total_loss_val,
accurancy_val))
# 隔一段时间进行测试
if i % (50000 // batchsize) == 0:
test_loss = 0
test_acc = 0
for ii in range(10000//batchsize):
test_im_batch, test_label_batch = \
sess.run([te_im, te_label])
feed_dict = {
input_data: test_im_batch,
input_label: test_label_batch,
keep_prob: 1.0,
is_training: False
}
total_loss_val, global_step_val, \
accurancy_val = sess.run([total_loss,global_step,
accurancy],
feed_dict=feed_dict)
test_loss += total_loss_val
test_acc += accurancy_val
print('[test]:', test_loss * batchsize / 10000,
test_acc* batchsize / 10000)
return
if __name__ == '__main__':
train()
Tensorboard+tf.summary
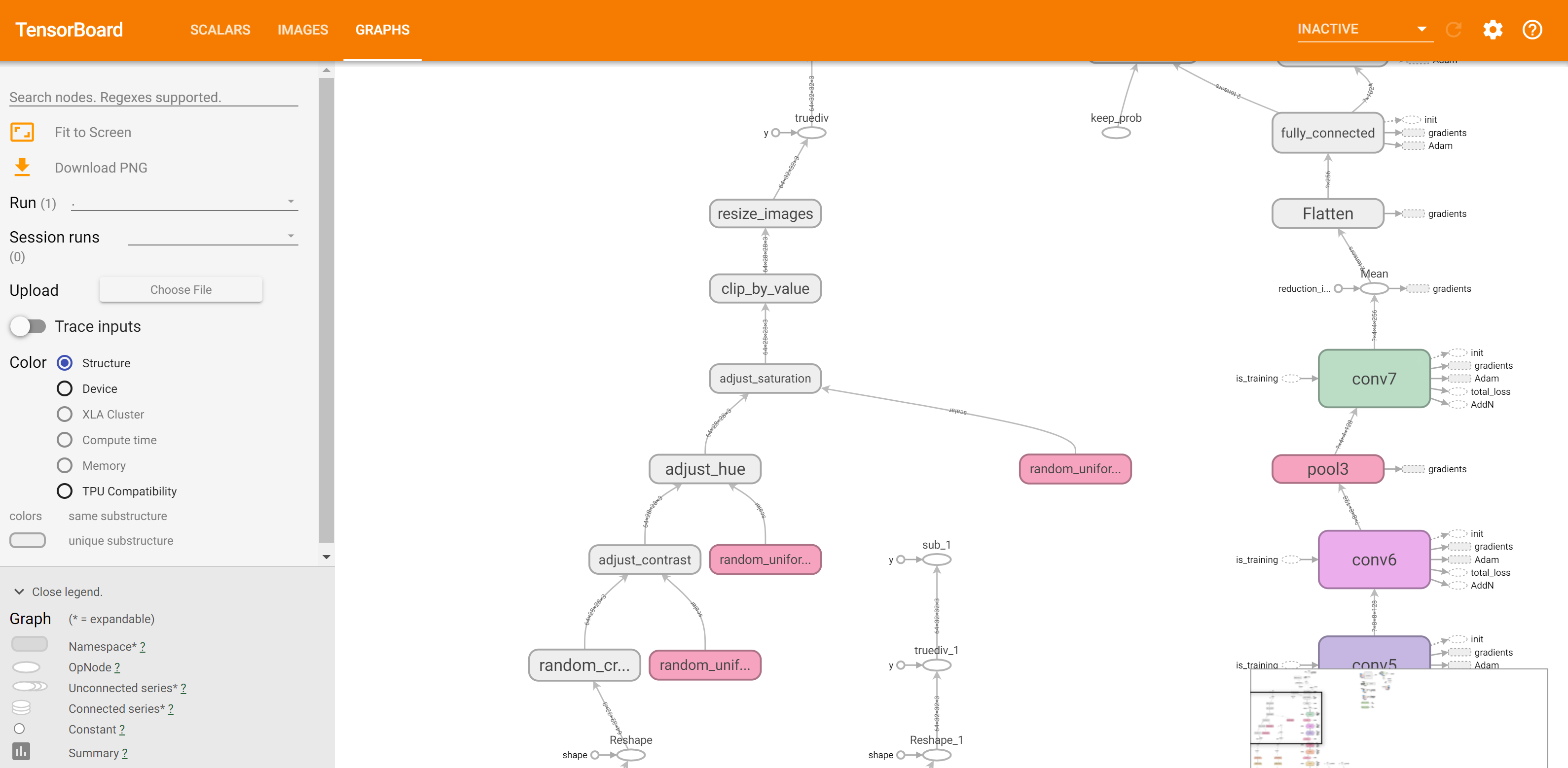
因为查看训练的消息只能在控制台查看,所以这里要记录日志信息。
训练好会输出日志,如下图。

如何查看该日志呢?在终端输入以下命令
tensorboard --logdir=logdirs
import os
import tensorflow as tf
import readcifar10
from tqdm import tqdm
slim = tf.contrib.slim
slim = tf.contrib.slim
def model(image, keep_prob=0.8, is_training=True):
"""
在model中我们会定义网络结构
params
image: 输入的图片
return 概率分布值 10 dim vector
"""
# batchnorm的参数
batch_norm_params = {
"is_training": is_training, # train:True test:False
"epsilon": 1e-5, # 这个值是防止batchnorm在归一化的时候除0
"decay": 0.997, # 衰减系数
'scale': True,
'updates_collections': tf.GraphKeys.UPDATE_OPS
}
"""
定义优化器
用 slim.arg_scope()为目标函数设置默认参数.
下面两个with,完成卷积默认参数的初始化和pooling层默认参数的初始化
一个with就是一个参数域 网络可以使用通过的参数
"""
with slim.arg_scope(
[slim.conv2d], # 这里是给 slim.conv2d 规定过了后面的参数
weights_initializer=slim.variance_scaling_initializer(), # 方差尺度不变来进行初始化
activation_fn=tf.nn.relu, # 默认激活函数为relu 在卷积之后加入激活函数
weights_regularizer=slim.l2_regularizer(
0.0001), # 权值的正则化约束 正则项权值为0.0001
normalizer_fn=slim.batch_norm, # 在卷积机后加入 BatchNorm
normalizer_params=batch_norm_params):
with slim.arg_scope([slim.max_pool2d], padding="SAME"): # 给 slim.max_pool2d 规定参数
"""
接下来利用卷积层、池化层、全连接层搭建一个cifar10用于图像分类的全连接网
"""
# 输入image 学习32个卷积核(channel) 卷积核大小 [3,3] 卷积层命名 conv1
net = slim.conv2d(image, 32, [3, 3], scope='conv1')
# 输入net 学习32个卷积核 卷积核大小 [3,3] 卷积层命名 conv2
net = slim.conv2d(net, 32, [3, 3], scope='conv2')
# 输入net 池化核大小[3,3] stride=2(进行两倍下采样)
net = slim.max_pool2d(net, [3, 3], stride=2, scope='pool1')
"""
===========
上面 conv+conv+maxpool 算是一个基本单元,后面基本就是使用这样的基本单元进行堆叠
==========
"""
# 每次经过pooling之后 卷积层channel的数量应该翻倍
net = slim.conv2d(net, 64, [3, 3], scope='conv3')
net = slim.conv2d(net, 64, [3, 3], scope='conv4')
net = slim.max_pool2d(net, [3, 3], stride=2, scope='pool2')
net = slim.conv2d(net, 128, [3, 3], scope='conv5')
net = slim.conv2d(net, 128, [3, 3], scope='conv6')
net = slim.max_pool2d(net, [3, 3], stride=2, scope='pool3')
# 经过8倍下采样之后 在加入一个卷积层
net = slim.conv2d(net, 256, [3, 3], scope='conv7')
"""
特征图维度 (n,h,w,c)
对 h,w 进行均值的求解 得到 (n,1,1,c) 因为 reduce_mean 就是降维求平均
"""
net = tf.reduce_mean(net, axis=[1, 2]) # nhwc--n11c
"""
slim.flatten 将输入扁平化但保留batch_size,假设第一维是batch。
将 (n,1,1,c) 转为 (n,c)
"""
net = slim.flatten(net)
# 全连接层 这里还不着急分类 (1,1024)可以作为从图像中提取出来的特征
net = slim.fully_connected(net, 1024)
"""
全连接层的参数太多 要加入dropout层 来进行正则化
keep_prob 概率值 定义了我们对当前神经元选择的概率
在训练和测试的时候,这个概率要取不同的值 训练的时候要取<1 测试的时候要=1
"""
slim.dropout(net, keep_prob)
# 输出为10 对应了10个分类类别
net = slim.fully_connected(net, 10)
return net # 10 dim vec
def loss(logits, label):
"""
loss使用交叉熵损失函数
param
logits: 预测出来的概率分布值
label: 实际的label
return 分类的loss
"""
# 对label进行one-hot编码 定义one-hot长度为10
one_hot_label = slim.one_hot_encoding(label, 10)
# 使用交叉熵损失函数 并传入 预测值 和 one-hot label
slim.losses.softmax_cross_entropy(logits, one_hot_label)
"""
在前面 slim.arg_scope 中定义了weights_regularizer=slim.l2_regularizer(0.0001)
通过 tf.GraphKeys.REGULARIZATION_LOSSES 可以拿到这些loss正则化的集合
"""
reg_set = tf.get_collection(tf.GraphKeys.REGULARIZATION_LOSSES)
# 将这些正则化loss进行相加 计算出总体的l2_loss
l2_loss = tf.add_n(reg_set)
# 将 l2_loss添加到loss中
slim.losses.add_loss(l2_loss)
totalloss = slim.losses.get_total_loss()
# 这里为了后面做日志,这里把l2_loss也传出
return totalloss, l2_loss
def func_optimal(batchsize, loss_val):
"""
定义优化器
"""
global_step = tf.Variable(0, trainable=False)
# 通过指数衰减的形式来定义学习率
lr = tf.train.exponential_decay(0.01,
global_step,
decay_steps=50000 // batchsize,
decay_rate=0.95,
staircase=False)
update_ops = tf.get_collection(tf.GraphKeys.UPDATE_OPS)
with tf.control_dependencies(update_ops):
op = tf.train.AdamOptimizer(lr).minimize(loss_val, global_step)
"""
global_step 可以得到当前的迭代次数
op sess.run()执行op可以完成对网络参数的调节
lr 返回 便于log信息的记录
"""
return global_step, op, lr
def train():
batchsize = 64
floder_log = 'logdirs'
floder_model = 'model'
if not os.path.exists(floder_log):
os.mkdir(floder_log)
if not os.path.exists(floder_model):
os.mkdir(floder_model)
# 存放train和test的日志信息
tr_summary = set()
te_summary = set()
# data
tr_im, tr_label = readcifar10.read(batchsize, 0, 1)
te_im, te_label = readcifar10.read(batchsize, 1, 0)
# net
"""
tf.placeholder 此函数可以理解为形参,用于定义过程,在执行的时候再赋具体的值
训练数据 [None,32,32,3] None是考虑到batch_size是可以变化的
"""
input_data = tf.placeholder(tf.float32, shape=[None, 32, 32, 3],
name='input_data')
input_label = tf.placeholder(tf.int64, shape=[None],
name='input_label')
"""
keep_prob dropout的概率值
训练过程 keep_prob 也就是dropout的概率值 为0.5 或小于1的值
"""
keep_prob = tf.placeholder(tf.float32, shape=None,
name='keep_prob')
is_training = tf.placeholder(tf.bool, shape=None,
name='is_training')
logits = model(
input_data, keep_prob=keep_prob, is_training=is_training)
# loss
"""
损失函数 传入预测的结果和真实的标签
"""
total_loss, l2_loss = loss(logits, input_label)
# 记录loss
tr_summary.add(tf.summary.scalar('train total loss', total_loss))
tr_summary.add(tf.summary.scalar('test l2_loss', l2_loss))
te_summary.add(tf.summary.scalar('train total loss', total_loss))
te_summary.add(tf.summary.scalar('test l2_loss', l2_loss))
# accurancy
"""
tf.argmax 获取最大值的索引
[n,10] axis=1 计算的是10维这个维度最大值对应的索引值
"""
pred_max = tf.argmax(logits, 1)
# 判断最大值索引和 label是否相等
correct = tf.equal(pred_max, input_label)
accurancy = tf.reduce_mean(tf.cast(correct, tf.float32))
tr_summary.add(tf.summary.scalar('train accurancy', accurancy))
te_summary.add(tf.summary.scalar('test accurancy', accurancy))
# op
global_step, op, lr = func_optimal(batchsize, total_loss)
tr_summary.add(tf.summary.scalar('train lr', lr))
te_summary.add(tf.summary.scalar('test lr', lr))
# 图片数据是归一化过的 这里要处理回来
tr_summary.add(tf.summary.image('train image', input_data * 128 + 128))
te_summary.add(tf.summary.image('test image', input_data * 128 + 128))
with tf.Session() as sess:
# 初始化参数 包括了局部变量和全局变量
sess.run(tf.group(tf.global_variables_initializer(),
tf.local_variables_initializer()))
# 启动文件队列写入的线程
tf.train.start_queue_runners(sess=sess,
coord=tf.train.Coordinator())
epoch_val = 10
# 将日志进行合并
tr_summary_op = tf.summary.merge(list(tr_summary))
te_summary_op = tf.summary.merge(list(te_summary))
summary_writer = tf.summary.FileWriter(floder_log, sess.graph)
# 读取文件队列中的数据,完成对网络的训练
for i in tqdm(range(50000 * epoch_val)): # 这里这个数量我还是没有理解
train_im_batch, train_label_batch = \
sess.run([tr_im, tr_label])
feed_dict = {
input_data: train_im_batch,
input_label: train_label_batch,
keep_prob: 0.8,
is_training: True
}
# 注意 这里得到这这些值 都是一个batch_size的
_, global_step_val, \
lr_val, \
total_loss_val, \
accurancy_val, tr_summary_str = sess.run([op,
global_step,
lr,
total_loss,
accurancy, tr_summary_op],
feed_dict=feed_dict)
summary_writer.add_summary(tr_summary_str, global_step_val)
# 每隔一百次打印一次
if i % 100 == 0:
print("\n[trian]:{},{},{},{}".format(global_step_val,
lr_val,
total_loss_val,
accurancy_val))
# 隔一段时间进行测试
if i % (50000 // batchsize) == 0:
test_loss = 0
test_acc = 0
for ii in range(10000//batchsize):
test_im_batch, test_label_batch = \
sess.run([te_im, te_label])
feed_dict = {
input_data: test_im_batch,
input_label: test_label_batch,
keep_prob: 1.0,
is_training: False
}
total_loss_val, global_step_val, \
accurancy_val, te_summary_str = sess.run([total_loss,global_step,
accurancy, te_summary_op],
feed_dict=feed_dict)
summary_writer.add_summary(te_summary_str, global_step_val)
test_loss += total_loss_val
test_acc += accurancy_val
print('[test]:', test_loss * batchsize / 10000,
test_acc * batchsize / 10000)
return
if __name__ == '__main__':
train()
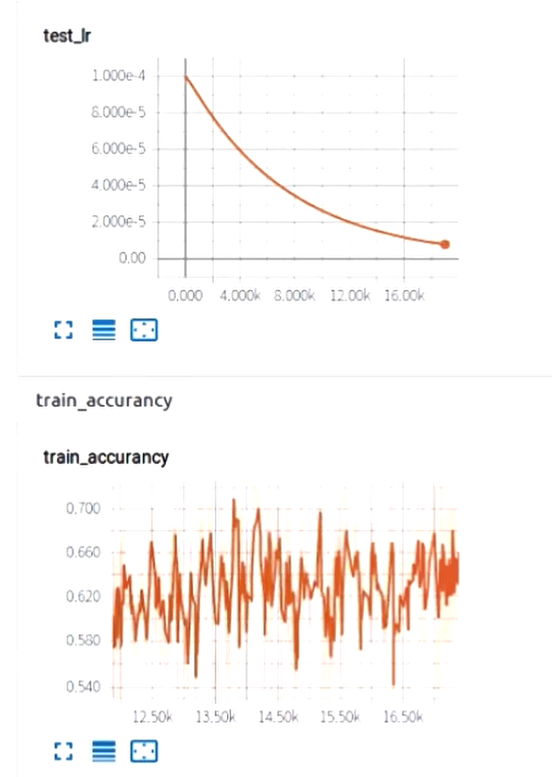
观察loss,确实是在收敛,但是准确率的震荡还是比较大的。
那么处理的思路有:
- 减小学习率或加大学习率衰减的值
修改优化器
模型恢复和模型存储
上面的程序没有加入模型存储的代码。
保存的模型代码结果如下
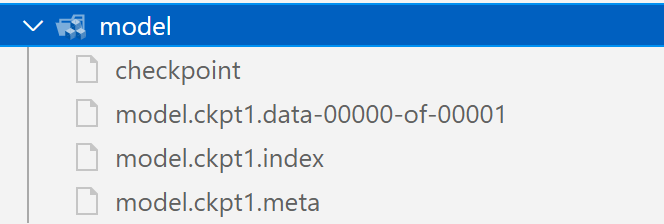
对于tf的model,就是包含了以下几个部分:
- checkpoint: 指向最新的模型
- .meta: 定义了graph的结构
- .data:存放了网络中具体参数的值
- .index: 完成对data和meta的索引
import os
import tensorflow as tf
import readcifar10
from tqdm import tqdm
slim = tf.contrib.slim
slim = tf.contrib.slim
def model(image, keep_prob=0.8, is_training=True):
"""
在model中我们会定义网络结构
params
image: 输入的图片
return 概率分布值 10 dim vector
"""
# batchnorm的参数
batch_norm_params = {
"is_training": is_training, # train:True test:False
"epsilon": 1e-5, # 这个值是防止batchnorm在归一化的时候除0
"decay": 0.997, # 衰减系数
'scale': True,
'updates_collections': tf.GraphKeys.UPDATE_OPS
}
"""
定义优化器
用 slim.arg_scope()为目标函数设置默认参数.
下面两个with,完成卷积默认参数的初始化和pooling层默认参数的初始化
一个with就是一个参数域 网络可以使用通过的参数
"""
with slim.arg_scope(
[slim.conv2d], # 这里是给 slim.conv2d 规定过了后面的参数
weights_initializer=slim.variance_scaling_initializer(), # 方差尺度不变来进行初始化
activation_fn=tf.nn.relu, # 默认激活函数为relu 在卷积之后加入激活函数
weights_regularizer=slim.l2_regularizer(
0.0001), # 权值的正则化约束 正则项权值为0.0001
normalizer_fn=slim.batch_norm, # 在卷积机后加入 BatchNorm
normalizer_params=batch_norm_params):
with slim.arg_scope([slim.max_pool2d], padding="SAME"): # 给 slim.max_pool2d 规定参数
"""
接下来利用卷积层、池化层、全连接层搭建一个cifar10用于图像分类的全连接网
"""
# 输入image 学习32个卷积核(channel) 卷积核大小 [3,3] 卷积层命名 conv1
net = slim.conv2d(image, 32, [3, 3], scope='conv1')
# 输入net 学习32个卷积核 卷积核大小 [3,3] 卷积层命名 conv2
net = slim.conv2d(net, 32, [3, 3], scope='conv2')
# 输入net 池化核大小[3,3] stride=2(进行两倍下采样)
net = slim.max_pool2d(net, [3, 3], stride=2, scope='pool1')
"""
===========
上面 conv+conv+maxpool 算是一个基本单元,后面基本就是使用这样的基本单元进行堆叠
==========
"""
# 每次经过pooling之后 卷积层channel的数量应该翻倍
net = slim.conv2d(net, 64, [3, 3], scope='conv3')
net = slim.conv2d(net, 64, [3, 3], scope='conv4')
net = slim.max_pool2d(net, [3, 3], stride=2, scope='pool2')
net = slim.conv2d(net, 128, [3, 3], scope='conv5')
net = slim.conv2d(net, 128, [3, 3], scope='conv6')
net = slim.max_pool2d(net, [3, 3], stride=2, scope='pool3')
# 经过8倍下采样之后 在加入一个卷积层
net = slim.conv2d(net, 256, [3, 3], scope='conv7')
"""
特征图维度 (n,h,w,c)
对 h,w 进行均值的求解 得到 (n,1,1,c) 因为 reduce_mean 就是降维求平均
"""
net = tf.reduce_mean(net, axis=[1, 2]) # nhwc--n11c
"""
slim.flatten 将输入扁平化但保留batch_size,假设第一维是batch。
将 (n,1,1,c) 转为 (n,c)
"""
net = slim.flatten(net)
# 全连接层 这里还不着急分类 (1,1024)可以作为从图像中提取出来的特征
net = slim.fully_connected(net, 1024)
"""
全连接层的参数太多 要加入dropout层 来进行正则化
keep_prob 概率值 定义了我们对当前神经元选择的概率
在训练和测试的时候,这个概率要取不同的值 训练的时候要取<1 测试的时候要=1
"""
slim.dropout(net, keep_prob)
# 输出为10 对应了10个分类类别
net = slim.fully_connected(net, 10)
return net # 10 dim vec
def loss(logits, label):
"""
loss使用交叉熵损失函数
param
logits: 预测出来的概率分布值
label: 实际的label
return 分类的loss
"""
# 对label进行one-hot编码 定义one-hot长度为10
one_hot_label = slim.one_hot_encoding(label, 10)
# 使用交叉熵损失函数 并传入 预测值 和 one-hot label
slim.losses.softmax_cross_entropy(logits, one_hot_label)
"""
在前面 slim.arg_scope 中定义了weights_regularizer=slim.l2_regularizer(0.0001)
通过 tf.GraphKeys.REGULARIZATION_LOSSES 可以拿到这些loss正则化的集合
"""
reg_set = tf.get_collection(tf.GraphKeys.REGULARIZATION_LOSSES)
# 将这些正则化loss进行相加 计算出总体的l2_loss
l2_loss = tf.add_n(reg_set)
# 将 l2_loss添加到loss中
slim.losses.add_loss(l2_loss)
totalloss = slim.losses.get_total_loss()
# 这里为了后面做日志,这里把l2_loss也传出
return totalloss, l2_loss
def func_optimal(batchsize, loss_val):
"""
定义优化器
"""
global_step = tf.Variable(0, trainable=False)
# 通过指数衰减的形式来定义学习率
lr = tf.train.exponential_decay(0.01,
global_step,
decay_steps=50000 // batchsize,
decay_rate=0.95,
staircase=False)
update_ops = tf.get_collection(tf.GraphKeys.UPDATE_OPS)
with tf.control_dependencies(update_ops):
op = tf.train.AdamOptimizer(lr).minimize(loss_val, global_step)
"""
global_step 可以得到当前的迭代次数
op sess.run()执行op可以完成对网络参数的调节
lr 返回 便于log信息的记录
"""
return global_step, op, lr
def train():
batchsize = 64
floder_log = 'logdirs'
floder_model = 'model'
if not os.path.exists(floder_log):
os.mkdir(floder_log)
if not os.path.exists(floder_model):
os.mkdir(floder_model)
# 存放train和test的日志信息
tr_summary = set()
te_summary = set()
# data
tr_im, tr_label = readcifar10.read(batchsize, 0, 1)
te_im, te_label = readcifar10.read(batchsize, 1, 0)
# net
"""
tf.placeholder 此函数可以理解为形参,用于定义过程,在执行的时候再赋具体的值
训练数据 [None,32,32,3] None是考虑到batch_size是可以变化的
"""
input_data = tf.placeholder(tf.float32, shape=[None, 32, 32, 3],
name='input_data')
input_label = tf.placeholder(tf.int64, shape=[None],
name='input_label')
"""
keep_prob dropout的概率值
训练过程 keep_prob 也就是dropout的概率值 为0.5 或小于1的值
"""
keep_prob = tf.placeholder(tf.float32, shape=None,
name='keep_prob')
is_training = tf.placeholder(tf.bool, shape=None,
name='is_training')
logits = model(
input_data, keep_prob=keep_prob, is_training=is_training)
# loss
"""
损失函数 传入预测的结果和真实的标签
"""
total_loss, l2_loss = loss(logits, input_label)
# 记录loss
tr_summary.add(tf.summary.scalar('train total loss', total_loss))
tr_summary.add(tf.summary.scalar('test l2_loss', l2_loss))
te_summary.add(tf.summary.scalar('train total loss', total_loss))
te_summary.add(tf.summary.scalar('test l2_loss', l2_loss))
# accurancy
"""
tf.argmax 获取最大值的索引
[n,10] axis=1 计算的是10维这个维度最大值对应的索引值
"""
pred_max = tf.argmax(logits, 1)
# 判断最大值索引和 label是否相等
correct = tf.equal(pred_max, input_label)
accurancy = tf.reduce_mean(tf.cast(correct, tf.float32))
tr_summary.add(tf.summary.scalar('train accurancy', accurancy))
te_summary.add(tf.summary.scalar('test accurancy', accurancy))
# op
global_step, op, lr = func_optimal(batchsize, total_loss)
tr_summary.add(tf.summary.scalar('train lr', lr))
te_summary.add(tf.summary.scalar('test lr', lr))
# 图片数据是归一化过的 这里要处理回来
tr_summary.add(tf.summary.image('train image', input_data * 128 + 128))
te_summary.add(tf.summary.image('test image', input_data * 128 + 128))
with tf.Session() as sess:
# 初始化参数 包括了局部变量和全局变量
sess.run(tf.group(tf.global_variables_initializer(),
tf.local_variables_initializer()))
# 启动文件队列写入的线程
tf.train.start_queue_runners(sess=sess,
coord=tf.train.Coordinator())
saver = tf.train.Saver(tf.global_variables(), max_to_keep=5)
ckpt = tf.train.latest_checkpoint(floder_model)
if ckpt:
saver.restore(sess, ckpt)
epoch_val = 10
# 将日志进行合并
tr_summary_op = tf.summary.merge(list(tr_summary))
te_summary_op = tf.summary.merge(list(te_summary))
summary_writer = tf.summary.FileWriter(floder_log, sess.graph)
# 读取文件队列中的数据,完成对网络的训练
for i in tqdm(range(50000 * epoch_val)): # 这里这个数量我还是没有理解
train_im_batch, train_label_batch = \
sess.run([tr_im, tr_label])
feed_dict = {
input_data: train_im_batch,
input_label: train_label_batch,
keep_prob: 0.8,
is_training: True
}
# 注意 这里得到这这些值 都是一个batch_size的
_, global_step_val, \
lr_val, \
total_loss_val, \
accurancy_val, tr_summary_str = sess.run([op,
global_step,
lr,
total_loss,
accurancy, tr_summary_op],
feed_dict=feed_dict)
summary_writer.add_summary(tr_summary_str, global_step_val)
# 每隔一百次打印一次
if i % 100 == 0:
print("\n[trian]:{},{},{},{}".format(global_step_val,
lr_val,
total_loss_val,
accurancy_val))
# 隔一段时间进行测试
if i % (50000 // batchsize) == 0:
test_loss = 0
test_acc = 0
for ii in range(10000//batchsize):
test_im_batch, test_label_batch = \
sess.run([te_im, te_label])
feed_dict = {
input_data: test_im_batch,
input_label: test_label_batch,
keep_prob: 1.0,
is_training: False
}
total_loss_val, global_step_val, \
accurancy_val, te_summary_str = sess.run([total_loss,global_step,
accurancy, te_summary_op],
feed_dict=feed_dict)
summary_writer.add_summary(te_summary_str, global_step_val)
test_loss += total_loss_val
test_acc += accurancy_val
print('[test]:', test_loss * batchsize / 10000,
test_acc * batchsize / 10000)
if i % 1000 == 0:
saver.save(sess, "{}/model.ckpt{}".format(floder_model, str(global_step_val)))
if __name__ == '__main__':
train()
网络结构优化—resnet模型
上面就是一个完整的网络结构了,如果要对模型进行优化,通常需要修改哪几个地方?
-
一个就是修改网络结构,这里也称之为主干网络结构,上面是非常简单的串联的网络结构,这里可以使用resnet来这种跳连的结构来进行替代。
-
还有就是可以修改学习率参数,以及学习率衰减的策略,针对不同的策略,观察对网络性能的影响。
-
加入更多数据增强的方法,采用不同的优化器来进行模型的训练。
resnet.py
import tensorflow as tf
slim = tf.contrib.slim
def resnet_blockneck(net, numout, down, stride, is_training):
"""
resnet的基本单元
params
net: 输入的特征图
numout: 输出channel的数量
down:在resnet中1*1卷积核下采样的倍率
stride:下采样步长
is_training: batchnorm的参数
"""
batch_norm_params = {
'is_training': is_training,
'decay': 0.997,
'epsilon': 1e-5,
'scale': True,
'updates_collections': tf.GraphKeys.UPDATE_OPS,
}
# 下面定义了卷积层的作用域
with slim.arg_scope(
[slim.conv2d],
weights_regularizer=slim.l2_regularizer(0.0001),
weights_initializer=slim.variance_scaling_initializer(),
activation_fn=tf.nn.relu,
normalizer_fn=slim.batch_norm,
normalizer_params=batch_norm_params):
with slim.arg_scope([slim.batch_norm], **batch_norm_params):
with slim.arg_scope([slim.conv2d, slim.max_pool2d], padding='SAME') as arg_sc:
"""
对于resnet,首先要将输入的特征图进行备份
"""
shortcut = net
"""
并且对备份过之后的特征图需要进行卷积和池化的判断
主要就是判断channel的数量是否相等 如果不相等就要使用1*1的卷积核进行卷积
如果是stride=2那么就进行下采样 保证特征图的大小也是一样的
"""
if numout != net.get_shape().as_list()[-1]:
shortcut = slim.conv2d(net, numout, [1, 1])
if stride != 1:
shortcut = slim.max_pool2d(shortcut, [3, 3],
stride=stride)
"""
先是使用1*1卷积核对channel数量进行下降
才经过3*3的卷积
最后通过1*1的卷积还原到想要输出的channel的数量
"""
net = slim.conv2d(net, numout // down, [1, 1])
net = slim.conv2d(net, numout // down, [3, 3])
net = slim.conv2d(net, numout, [1, 1])
if stride != 1:
net = slim.max_pool2d(net, [3, 3], stride=stride)
# 跳连结构
net = net + shortcut
return net
def model_resnet(net, keep_prob=0.5, is_training = True):
with slim.arg_scope([slim.conv2d, slim.max_pool2d], padding='SAME') as arg_sc:
"""
输入图像的时候,还是会使用标准卷积
"""
net = slim.conv2d(net, 64, [3, 3], activation_fn=tf.nn.relu)
net = slim.conv2d(net, 64, [3, 3], activation_fn=tf.nn.relu)
"""
在网络结构中 对resnet基本单元进行了堆叠
每次经过下采样 会对channel进行进行翻倍处理
这里就是把之前的卷积单元替换成了resnet单元 其他都是一样的
"""
net = resnet_blockneck(net, 128, 4, 2, is_training)
net = resnet_blockneck(net, 128, 4, 1, is_training)
net = resnet_blockneck(net, 256, 4, 2, is_training)
net = resnet_blockneck(net, 256, 4, 1, is_training)
net = resnet_blockneck(net, 512, 4, 2, is_training)
net = resnet_blockneck(net, 512, 4, 1, is_training)
net = tf.reduce_mean(net, [1, 2])
net = slim.flatten(net)
net = slim.fully_connected(net, 1024, activation_fn=tf.nn.relu, scope='fc1')
net = slim.dropout(net, keep_prob, scope='dropout1')
net = slim.fully_connected(net, 10, activation_fn=None, scope='fc2')
return net
train_resnet.py
import tensorflow as tf
import readcifar10
import os
import resnet
from tqdm import tqdm
slim = tf.contrib.slim
def loss(logits, label):
one_hot_label = slim.one_hot_encoding(label, 10)
slim.losses.softmax_cross_entropy(logits, one_hot_label)
reg_set = tf.get_collection(tf.GraphKeys.REGULARIZATION_LOSSES)
l2_loss = tf.add_n(reg_set)
slim.losses.add_loss(l2_loss)
totalloss = slim.losses.get_total_loss()
return totalloss, l2_loss
def func_optimal(batchsize, loss_val):
global_step = tf.Variable(0, trainable=False)
lr = tf.train.exponential_decay(0.01,
global_step,
decay_steps= 50000// batchsize,
decay_rate= 0.95,
staircase=False)
update_ops = tf.get_collection(tf.GraphKeys.UPDATE_OPS)
with tf.control_dependencies(update_ops):
op = tf.train.AdamOptimizer(lr).minimize(loss_val, global_step)
return global_step, op, lr
def train():
batchsize = 64
floder_log = 'logdirs-resnet'
floder_model = 'model-resnet'
if not os.path.exists(floder_log):
os.mkdir(floder_log)
if not os.path.exists(floder_model):
os.mkdir(floder_model)
tr_summary = set()
te_summary = set()
##data
tr_im, tr_label = readcifar10.read(batchsize, 0, 1)
te_im, te_label = readcifar10.read(batchsize, 1, 0)
##net
input_data = tf.placeholder(tf.float32, shape=[None, 32, 32, 3],
name='input_data')
input_label = tf.placeholder(tf.int64, shape=[None],
name='input_label')
keep_prob = tf.placeholder(tf.float32, shape=None,
name='keep_prob')
is_training = tf.placeholder(tf.bool, shape=None,
name='is_training')
logits = resnet.model_resnet(input_data, keep_prob=keep_prob, is_training=is_training)
##loss
total_loss, l2_loss = loss(logits, input_label)
tr_summary.add(tf.summary.scalar('train total loss', total_loss))
tr_summary.add(tf.summary.scalar('test l2_loss', l2_loss))
te_summary.add(tf.summary.scalar('train total loss', total_loss))
te_summary.add(tf.summary.scalar('test l2_loss', l2_loss))
##accurancy
pred_max = tf.argmax(logits, 1)
correct = tf.equal(pred_max, input_label)
accurancy = tf.reduce_mean(tf.cast(correct, tf.float32))
tr_summary.add(tf.summary.scalar('train accurancy', accurancy))
te_summary.add(tf.summary.scalar('test accurancy', accurancy))
##op
global_step, op, lr = func_optimal(batchsize, total_loss)
tr_summary.add(tf.summary.scalar('train lr', lr))
te_summary.add(tf.summary.scalar('test lr', lr))
tr_summary.add(tf.summary.image('train image', input_data * 128 + 128))
te_summary.add(tf.summary.image('test image', input_data * 128 + 128))
with tf.Session() as sess:
sess.run(tf.group(tf.global_variables_initializer(),
tf.local_variables_initializer()))
tf.train.start_queue_runners(sess=sess,
coord=tf.train.Coordinator())
saver = tf.train.Saver(tf.global_variables(), max_to_keep=5)
ckpt = tf.train.latest_checkpoint(floder_model)
if ckpt:
saver.restore(sess, ckpt)
epoch_val = 100
tr_summary_op = tf.summary.merge(list(tr_summary))
te_summary_op = tf.summary.merge(list(te_summary))
summary_writer = tf.summary.FileWriter(floder_log, sess.graph)
for i in tqdm(range(50000 * epoch_val)):
train_im_batch, train_label_batch = \
sess.run([tr_im, tr_label])
feed_dict = {
input_data:train_im_batch,
input_label:train_label_batch,
keep_prob:0.8,
is_training:True
}
_, global_step_val, \
lr_val, \
total_loss_val, \
accurancy_val, tr_summary_str = sess.run([op,
global_step,
lr,
total_loss,
accurancy, tr_summary_op],
feed_dict=feed_dict)
summary_writer.add_summary(tr_summary_str, global_step_val)
if i % 100 == 0:
print("{},{},{},{}".format(global_step_val,
lr_val, total_loss_val,
accurancy_val))
if i % (50000 // batchsize) == 0:
test_loss = 0
test_acc = 0
for ii in range(10000//batchsize):
test_im_batch, test_label_batch = \
sess.run([te_im, te_label])
feed_dict = {
input_data: test_im_batch,
input_label: test_label_batch,
keep_prob: 1.0,
is_training: False
}
total_loss_val, global_step_val, \
accurancy_val, te_summary_str = sess.run([total_loss,global_step,
accurancy, te_summary_op],
feed_dict=feed_dict)
summary_writer.add_summary(te_summary_str, global_step_val)
test_loss += total_loss_val
test_acc += accurancy_val
print('test:', test_loss * batchsize / 10000,
test_acc* batchsize / 10000)
if i % 1000 == 0:
saver.save(sess, "{}/model.ckpt{}".format(floder_model, str(global_step_val)))
return
if __name__ == '__main__':
train()
TF官方版本训练Cifar10分类任务
上面所有的步骤,在官方给出的源码中,其实都已经实现了!
要避免重复造轮子,可以对找官方给出的参考代码进行修改。
https://github.com/tensorflow/models/tree/master/research/slim
好好读读人家的README,会有巨大的收获!

小结
TF训练框架搭建:
* Data
首先是数据的读取和数据的打包。
* Net
网络的搭建,这里采用slim来搭建网络结构,因为slim是对tf更加高层的封装,可以写更加简洁的代码。
* Loss
Loss本身就是网络的一部分,这个会采用softmaxLoss来进行Loss定义。
另外还会定义正则化的Loss。
* Summary
Summary完成了训练过程中日志的记录。
* Session
Session完成了构造出网络结构后,如果对计算图中的结点进行计算,会通过Session在后端完成整个网络的BP。并通过Feed给网络数据,Fetch获得输出的张量。
有哪些优化模型效果的思路?
训练代码,也就是baseline版本,要如何进行优化呢?上面提供了几个参考思路。
* 更多的数据增强策略,比如:mixup等=
通过数据增强的策略,来丰富样本量,进而提高模型对更多样本的泛化能力。
* 更好的主干网络,比如:SENet等
有VGG,ResNet这样的主干网络,当然,SENet比ResNet的性能更好,可以实验哪个主干网络实验出来的效果更好。
* 更好的标签策略,比如:Soft-label策略
cifar10的标签就是从0到9十个标签,这里可以采用soft-label的策略,比如有些物体既像飞机又像汽车,那么就可以采用软的策略,来对标签进行预处理。
* 更好的loss设计,比如:采用分类+回归smooth-l1 loss等
另外可以采用更好的loss,这里采用交叉熵损失来完成图像分类的任务,另外大家也可以考虑结合回归的loss,来进行一个多个loss的约束。
* 不同的优化器、参数初始化方法等

 浙公网安备 33010602011771号
浙公网安备 33010602011771号