Python实用工具 | 自主研发-购书比价工具| 01
要爬取的网站
www.dangdang.com
www.jd.com
www.yhd.com
www.taobao.com
课程概要及环境搭建
需求:输入图书的ISBN编码,可以获取多家网上书城的价格,并按照价格排序输出结果。



json知识点学习

JSON:
-
一种轻量级的数据交换格式;通用,跨平台
-
“key -value”的集合;值的有序列表
这是概念性的东西,这里只是简要的提一下,后面写代码的时候会进行详细的概述。
- 类似Python中得dict

上面这张表需要好好掌握住。

Python和Json字符串的相互转换是要学会的。
然后最重要的一点就是从文件中读取Json字符串,将其转换为Python对象,这个在后面爬虫中也是需要被用到的。
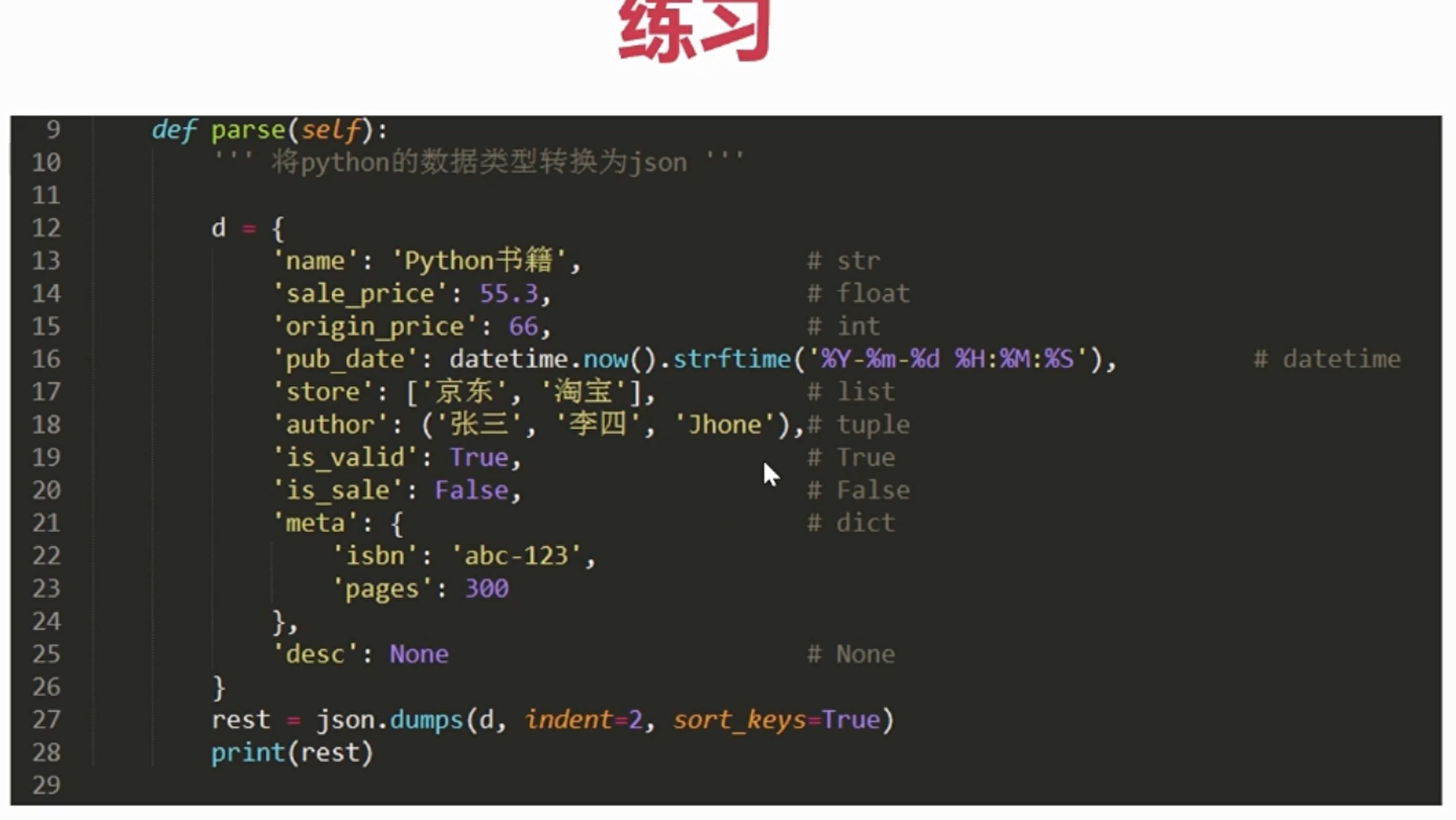
下面是book.json,这是事先准备好json文件数据。
{
"name": "Python书籍",
"origin_price": 66,
"pub_date": "2018-4-14 17:00:00",
"store": ["京东", "淘宝"],
"author": ["张三", "李四", "Jhone"],
"is_valid": true,
"is_sale": false,
"meta": {
"isbn": "abc-123",
"pages": 300
},
"desc": null
}
Json中的key必须是双引号的,不像Python的key,可以单引号也可以双引号。
Json中的key也是唯一的,不能有同名的key。
Python与Json转换API:
-
Python3的标准库 json
-
dumps是将dict转化成str格式,loads是将str转化成dict格式。
-
dump和load也是类似的功能,只是与文件操作结合起来了。
use_json.py
import json
def python_to_json():
"""
将Python对象转换成json字符串 json.dumps()
"""
d = {
'name': 'python书籍',
'price': 62.3,
'is_valid': True
}
res = json.dumps(d,indent=4) # 加上缩进
print("Python转换为Json:", res)
print("类型:", type(res))
def json_to_python():
"""
将json字符串转换为Python对象 json.loads()
"""
data = '''
{
"name": "Python书籍",
"origin_price": 66,
"pub_date": "2018-4-14 17:00:00",
"store": ["京东", "淘宝"],
"author": ["张三", "李四", "Jhone"],
"is_valid": true,
"is_sale": false,
"meta": {
"isbn": "abc-123",
"pages": 300
},
"desc": null
}
'''
res = json.loads(data)
print("Json转换为Python:", res)
print("类型:", type(res))
def json_to_python_from_file():
"""
从文件读取内容,并转换成Python对象
"""
with open("./static/book.json","r",encoding="utf8") as f:
s = f.read() # 读取文件数据
print("Json文件内容:",s)
res = json.loads(s)
print("读取Json文件内容,转换为Python对象:",res)
print("类型:", type(res))
if __name__ == "__main__":
python_to_json()
print("="*20)
json_to_python()
print("="*20)
json_to_python_from_file()
执行结果
Python转换为Json: {
"name": "python\u4e66\u7c4d",
"price": 62.3,
"is_valid": true
}
类型: <class 'str'>
====================
Json转换为Python: {'name': 'Python书籍', 'origin_price': 66, 'pub_date': '2018-4-14 17:00:00', 'store': ['京东', '淘宝'], 'author': ['张三', '李四', 'Jhone'],
'is_valid': True, 'is_sale': False, 'meta': {'isbn': 'abc-123', 'pages': 300}, 'desc': None}
类型: <class 'dict'>
====================
Json文件内容: {
"name": "Python书籍",
"origin_price": 66,
"pub_date": "2018-4-14 17:00:00",
"store": ["京东", "淘宝"],
"author": ["张三", "李四", "Jhone"],
"is_valid": true,
"is_sale": false,
"meta": {
"isbn": "abc-123",
"pages": 300
},
"desc": null
}
读取Json文件内容,转换为Python对象: {'name': 'Python书籍', 'origin_price': 66, 'pub_date': '2018-4-14 17:00:00', 'store': ['京东', '淘宝'], 'author': ['张三',
'李四', 'Jhone'], 'is_valid': True, 'is_sale': False, 'meta': {'isbn': 'abc-123', 'pages': 300}, 'desc': None}
类型: <class 'dict'>
xpath及html基础知识

xPath:一种HTML和XML的查询语言,它能在XML和HTML的树状结构中寻找节点。

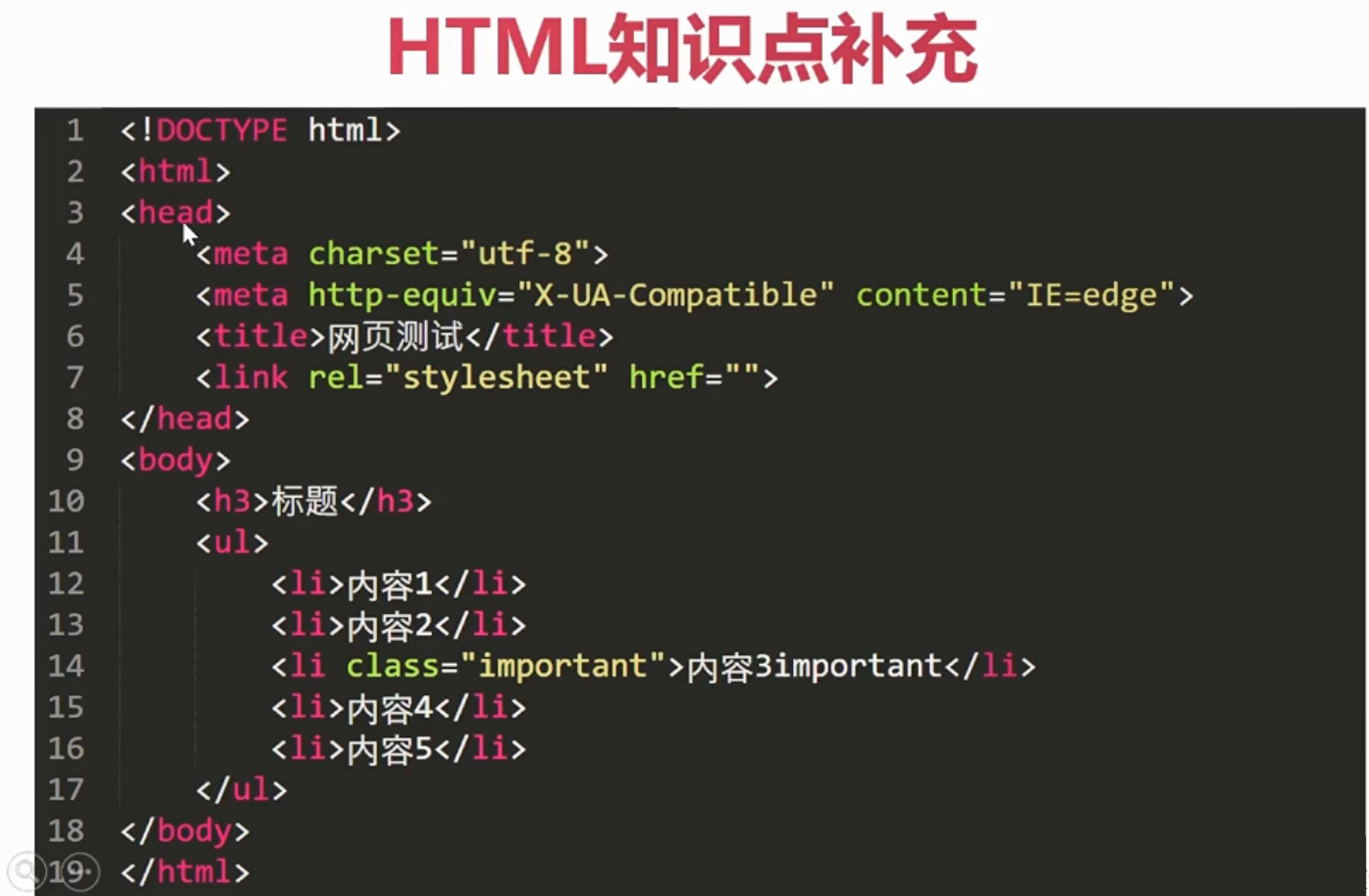
上图是HTML的页面结果。

如上图就是HTML的一个树形结构。
xpath实战

学习的xPath内容重点分为两块:
- 获取文本 //标签1[@属性1=“属性值1”]/标签2[@属性2=“属性值2”]/.../text()
- 获取属性值 //标签1[@属性1=“属性值1”]/标签2[@属性2=“属性值2”]/.../@属性n
什么场景要获取属性值呢?就是获取一个超链接的地址,比如有一个链接,是跳转百度的,那么一定是一个a标签,其中的href这个属性指向的是网站的地址。
xPath中双斜杠和单斜杠的差别:
- 如果是单斜杠开头,就是从文档的根路径开始匹配
- 如果是双斜杠开头,就是从任意的位置匹配
下面就使用xPath匹配下面的HTML文档。
<!DOCTYPE html>
<html>
<head>
<meta charset="utf-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge">
<title>网页测试</title>
<link rel="stylesheet" href="">
</head>
<body>
<h3>标题</h3>
<ul>
<li>内容1</li>
<li>内容2</li>
<li class="important">内容3important</li>
<li>内容4</li>
<li>内容5</li>
</ul>
<div>
内容未知
</div>
<p>
段落内容 from p
</p>
<div id="container">
段落文字
<a href="http://www.baidu.com" title="超链接">跳转到百度首页</a>
<p class="content">
区块内容1
</p>
<p class="content">
区块内容2
</p>
<p class="content">
区块内容3
</p>
<p class="content">
区块内容4
</p>
<p class="content-block">
区块内容5 from block
</p>
<p class="block-content">
区块内容6 末尾内容
</p>
</div>
<p>
最后一段文字
</p>
</body>
</html>
use_xpath_demo.py
from lxml import html
def parse():
"""
将html文件的内容,使用xpath进行提取
"""
with open("static\index.html", "r", encoding="utf8") as f:
s = f.read() # 获取到html字符串
selector = html.fromstring(s) # 解析html文档
print(type(selector)) # <class 'lxml.html.HtmlElement'>
# 解析h3标题
h3 = selector.xpath('/html/body/h3/text()') # 注意 是 / 开头
print("h3:", h3)
# 解析ul下面的内容
ul = selector.xpath("/html/body/ul/li") # 得到的是一个 <class 'lxml.html.HtmlElement'> 的list
print("ul长度:",len(ul)) # 5
for li in ul: # 循环输出其中的内容
print(li.xpath('text()'))
# 解析ul指定的元素值(在元素列表中选择指定的元素)
"""
// 开头就是从根开始找
这里由于只有一个ul 所以找到的结果是唯一的
"""
ul2 = selector.xpath('//ul/li[@class="important"]/text()')
print("ul2:",ul2)
# 解析a标签的内容
a = selector.xpath('//div[@id="container"]/a')
print("a标签的内容:",a[0].xpath('text()'))
print("a标签的网址:",a[0].xpath('@href'))
if __name__ == "__main__":
parse()
执行结果
<class 'lxml.html.HtmlElement'>
h3: ['标题']
ul长度: 5
['内容1']
['内容2']
['内容3important']
['内容4']
['内容5']
ul2: ['内容3important']
a标签的内容: ['跳转到百度首页']
a标签的网址: ['http://www.baidu.com']
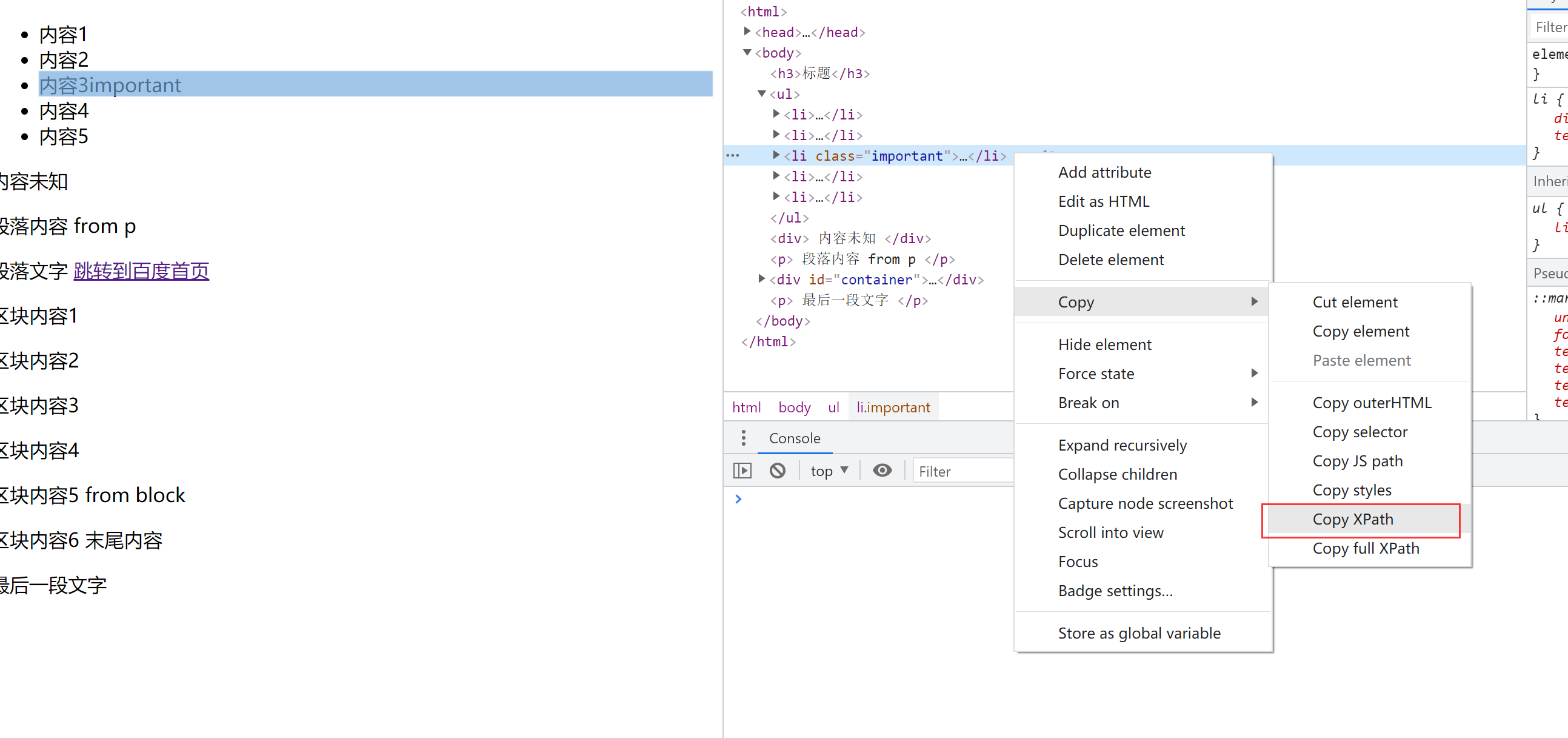
提示:在chrome的检查中可以复制xpath的路径,但是仅供参考..
Requests基础知识

Request库:
-
安装 pip install requests
-
请求和响应 Request & Response
-
POST/GET请求


什么情况下用GET?什么情况下用POST?
一般获取数据,也就是从数据库把信息拉出来的时候,就是使用GET请求,直接通过浏览器就可以访问。
如果要改变数据库的东西,新增、删除、修改,就是要用POST。
Resquets的使用:
-
res = requests.get(url,params={}) # get请求数据
-
res = requests.post(url,params={}) # post请求数据
-
res.text # 获取html文档文本
-
res.json() # 将json响应数据转换为dict
-
res.status_code # HTTP状态码
-
res.encoding # 查看文件的编码
优雅的使用字符串

优雅的使用字符串:
- 使用%格式化字符串
- 使用.format进行高级操作



user_str.py
def format_str():
"""
格式化字符串
"""
name = "张三"
print("欢迎您,%s" % name)
print("您的姓名:%(name)s" % {'name': name})
# 整型 浮点型
num = 12.33
print("您输入的数字是:%.1f" % num) # 12.3
num2 = 54
print("您的编号是:%04d" % num2) # 0054
"""
使用 format() 进行格式化
"""
# 使用位置
print('欢迎您, {0}, {1},---{0}说'.format('张三', '好久不见'))
# 使用名称
d = {
'username': '李四',
'num': 45
}
print('您好,{username}, 您的编号是{num}'.format(**d)) # 字典解包
print('您好,{username}, 您的编号是{num}'.format(username="李四", num=45))
# 格式化元组 第一个表示位置 []表示取下标元素
point = ((1, 2), (3, 4))
print("坐标位置:{0[0]}:{0[1]}".format(point))
# 格式化类
one = User("王五",25)
print(one.show())
class User:
def __init__(self, username, age) -> None:
self.username = username
self.age = age
def show(self):
"""给类进行格式化"""
return "用户名:{self.username},年龄:{self.age}".format(self=self)
if __name__ == "__main__":
format_str()
爬取当当网的数据
import requests
from lxml import html
def spider(sn, book_list=[]):
"""
爬取当当网的数据
params
sn:图书的ibsn
book_list:图书列表
"""
url = "http://search.dangdang.com/?key={sn}&act=input".format(
sn=sn) # format的用法
html_data = requests.get(url)
html_data.encoding = "GB2312"
html_data = html_data.text
# xpath对象
selector = html.fromstring(html_data)
# 找到书本列表(这个就要自己观察网页的结构了!)
# 一般列表是最好爬取的
ul_list = selector.xpath('//div[@id="search_nature_rg"]/ul/li')
print(len(ul_list)) # 打印长度验证是否取到数据
for li in ul_list:
# 标题
title = li.xpath('a/@title')
print("书名:", title[0])
# 购买链接
link = li.xpath('a/@href')
print("购买链接:", link[0])
# 价格
price = li.xpath('p/span[@class="search_now_price"]/text()')
print('价格:', price[0].replace('¥',''))
# 商家
store = li.xpath('p[@class="search_shangjia"]/a/text()')
store = '当当自营' if len(store) == 0 else store[0] # 这个是要自己推断出来的!
print('商家:', store)
if __name__ == "__main__":
sn = '9787115428028'
spider(sn)
爬取京东网的数据
原来京东搜索网址是这个
https://search.jd.com/Search?keyword=9787115428028&enc=utf-8&wq=9787115428028&pvid=31aef6ade5f040eb8962da95e044739f
可以适当删除,下面也不影响搜索结果
https://search.jd.com/Search?keyword=9787115428028
对于京东要登录的这波操作...
关于爬取京东的数据要先登录... 这真的是一个反爬机制阿...
import requests
headers = {
"cookie":"...",
"user-agent": "..."
}
html_data = requests.get(url, headers=headers)
import requests
from lxml import html
def spider(sn,book_list=[]):
"""
爬取京东的图书数据
params
sn: 图书的isbn号
"""
url = "https://search.jd.com/Search?keyword={sn}".format(sn=sn)
# 获取HTML文档
headers = {
"cookie":"...",
"user-agent": "..."
}
html_data = requests.get(url, headers=headers)
html_data.encoding = "utf-8"
html_data = html_data.text
# 获取xpath对象
selector = html.fromstring(html_data)
# 找到列表的集合
ul = selector.xpath('//div[@id="J_goodsList"]/ul/li')
print("列表长度:", len(ul))
# 解析对应的内容
for li in ul:
# 标题
title = li.xpath('div/div[@class="p-name"]/a/em/text()')
print("书名:", title[0])
# 购买链接
link = li.xpath('div/div[@class="p-name"]/a/@href')
print("购买链接:", link[0])
# 价格
price = li.xpath('div/div[@class="p-price"]/strong/i/text()')
print('价格:', price[0])
# 商家
store = li.xpath('div/div[@class="p-shopnum"]/a/@title')
print('商家:', store[0])
if __name__ == "__main__":
sn = '9787115428028'
spider(sn)
爬取1号店的数据
(1号店已经没有了...)
爬取淘宝网的数据
淘宝的数据爬取和其他都不一样,因为它使用json的方式返回的。
淘宝的网站已经更新了,现在是通过js代码来更新商品的...
可以通过爱淘宝来进行搜索..
爬取淘宝网的难度是最大的...
实现购书比价工具
from spider_dangdang import spider as dangdang
from spider_jd import spider as jd
def main(sn):
"""
图书比较工具整合
"""
book_list = []
print("====开始爬取 当当网 数据====")
dangdang(sn, book_list)
print("==== 当当网 数据爬取完成====")
print("====开始爬取 京东 数据====")
jd(sn, book_list)
print("==== 京东 数据爬取完成====")
# 打印所有数据列表
# for book in book_list:
# print(book)
print("===开始排序===")
# 按照价格升序排序
book_list = sorted(book_list, key=lambda x: float(
x["price"]), reverse=True)
for book in book_list:
print(book)
if __name__ == "__main__":
sn = input("请输入ISBN号:").strip()
main(sn)
小结
该工具的需求是什么?
**需求:输入图书的ISBN编码,可以获取多家网上书城的价格,并按照价格排序输出结果。**
什么是Json?
* 一种轻量级的数据交换格式;通用,跨平台
* “key -value”的集合;值的有序列表
这是概念性的东西,这里只是简要的提一下,后面写代码的时候会进行详细的概述。
* 类似Python中得dict
Json中的key必须是双引号的,不像Python的key,可以单引号也可以双引号。
Json中的key也是唯一的,不能有同名的key。
Python-Json类型转换
Python Json
dict object (重点理解!)
list,tuple array
str string
int,float number
True true
False false
None null
Python与Json转换API
dumps是将dict转化成str格式,loads是将str转化成dict格式。
dump和load也是类似的功能,只是与文件操作结合起来了。
Python3的标准库 json
Python如何读取和写入文件?
with open("文件路径","r/w/a",encoding="gbk/utf8") as f:
f.read()/f.write()
什么是xPath?
xPath:一种HTML和XML的查询语言,它能在XML和HTML的树状结构中寻找节点。
xPath的使用
学习的xPath内容重点分为两块:
* 获取文本 //标签1[@属性1=“属性值1”]/标签2[@属性2=“属性值2”]/.../text()
* 获取属性值 //标签1[@属性1=“属性值1”]/标签2[@属性2=“属性值2”]/.../@属性n
什么场景要获取属性值呢?就是获取一个超链接的地址,比如有一个链接,是跳转百度的,那么一定是一个a标签,其中的href这个属性指向的是网站的地址。
xPath中双斜杠和单斜杠的差别:
* 如果是单斜杠开头,就是从文档的根路径开始匹配
* 如果是双斜杠开头,就是从任意的位置匹配
# lxmlc
from lxml import html
selector = html.fromstring(html/xml字符串)
GET & POST
GET请求
可以用浏览器直接访问
请求可以携带参数,但是长度有限制
请求参数直接放在URL后面
POST请求
不能使用浏览器直接访问
对请求参数的长度没有限制
可以用来上传文件等需求
什么情况下用GET?什么情况下用POST?
一般获取数据,也就是从数据库把信息拉出来的时候,就是使用GET请求,直接通过浏览器就可以访问。
如果要改变数据库的东西,新增、删除、修改,就是要用POST。
Requests的使用
res = requests.get(url,params={}) # get请求数据
res = requests.post(url,params={}) # post请求数据
res.text # 获取html文档文本
res.json() # 将json响应数据转换为dict
res.status_code # HTTP状态码
res.encoding # 查看文件的编码
优雅的使用字符串
优雅的使用字符串:
* 使用%格式化字符串
* 使用.format进行高级操作
# %
# 字符串
"欢迎您,%s" % name
"您的姓名:%(name)s" % {'name': name}
# 浮点数 整型
"您输入的数字是:%.1f" % 12.33
"您的编号是:%04d" % 54
# format()
# 使用位置
'欢迎您, {0}, {1},---{0}说'.format('张三', '好久不见')
# 使用名称
'您好,{username}, 您的编号是{num}'.format(**d)
'您好,{username}, 您的编号是{num}'.format(username="李四", num=45)
# 格式化元组 第一个表示位置 []表示取下标元素
point = ((1, 2), (3, 4))
"坐标位置:{0[0]}:{0[1]}".format(point)
# 格式化类
class User:
def __init__(self, username, age) -> None:
self.username = username
self.age = age
def show(self):
"""给类进行格式化"""
return "用户名:{self.username},年龄:
如何理解字典解包?
简单来说,就是把字典的内容变成方法参数中
key1=value1,key2=value2,....
这样的形式
print('您好,{username}, 您的编号是{num}'.format(**d)) # 字典解包
print('您好,{username}, 您的编号是{num}'.format(username="李四",num=45))
爬虫推断!
# 大部分结构是有规律的 但是有特殊的要特殊判断 这个就要靠观察了!
store = li.xpath('p[@class="search_shangjia"]/a/text()')
store = '当当自营' if len(store) == 0 else store[0] # 这个是要自己推断出来的!
一般列表的数据都是 ul
判断是不是要爬取的对象,查看网页的Elements,要确定的话还可以再查看网页的源代码
网址删除
原来京东的网址是这个
https://search.jd.com/Search?keyword=9787115428028&enc=utf-
8&wq=9787115428028&pvid=31aef6ade5f040eb8962da95e044739f
可以适当删除,下面也不影响搜索结果
https://search.jd.com/Search?keyword=9787115428028
关于网页的编码
在网页的源代码中有 charser="..."
然后可以设置
html_data = requests.get(url)
html_data.encoding = "GB2312" # 或者 utf-8
html_data = html_data.text
对于京东要登录的这波操作...
关于爬取京东的数据要先登录... 这真的是一个反爬机制阿...
import requests
headers = {
"cookie":"...",
"user-agent": "..."
}
html_data = requests.get(url, headers=headers)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号