大数据基础 | 学好大数据先攻克linux | 01
Linux虚拟机安装配置
使用VM安装Linux虚拟机
(这里不做赘述)
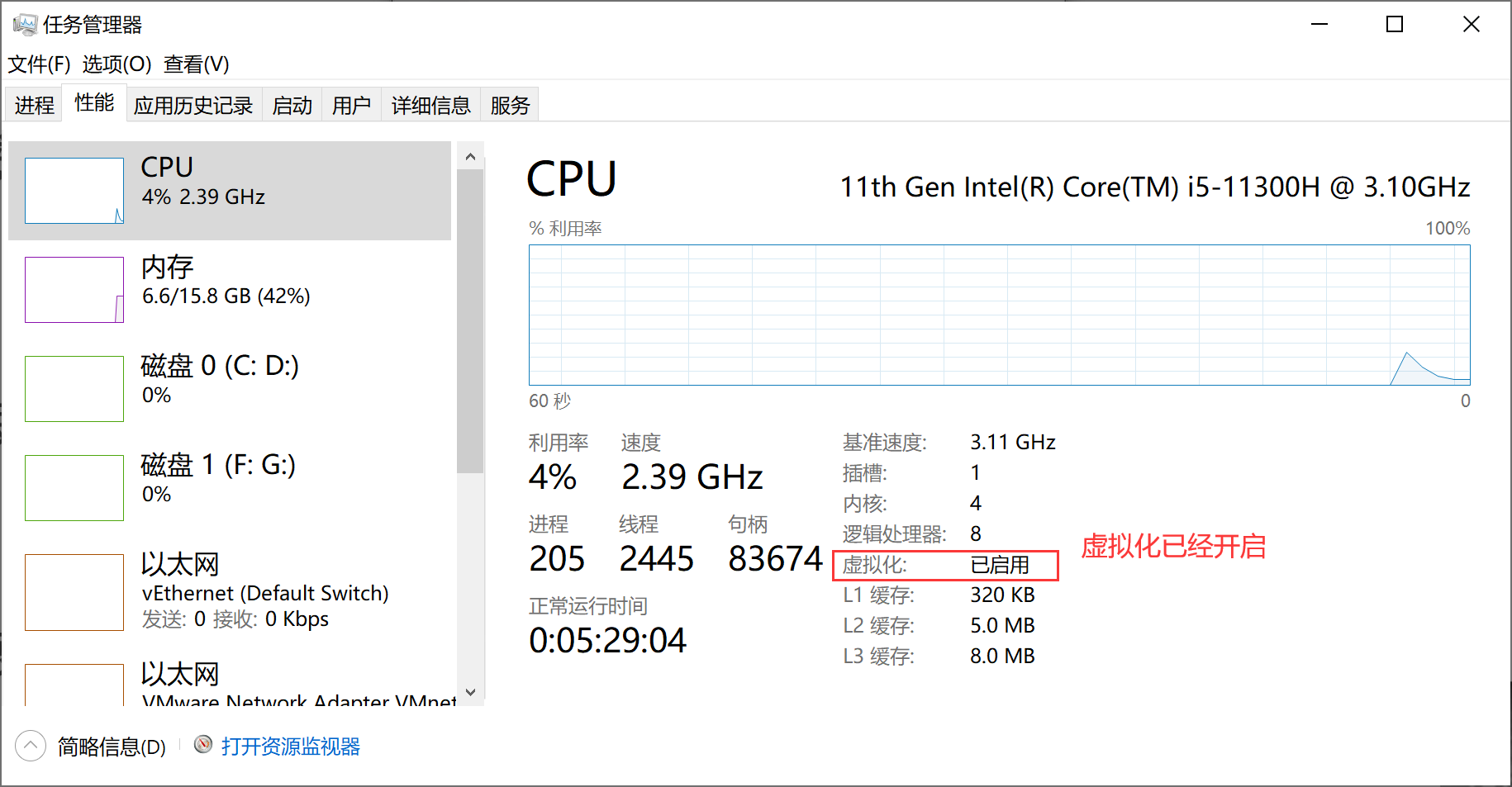
安装VM虚拟机,要先打开电脑虚拟化功能。
检查是否已经打开的方式很简单,打开任务管理器,如下图查看。
使用克隆的方式创建Linux虚拟机
如果每次都是需要重新安装linux,那么步骤是非常繁琐的,这里将学习如果通过克隆的方式创建虚拟机。
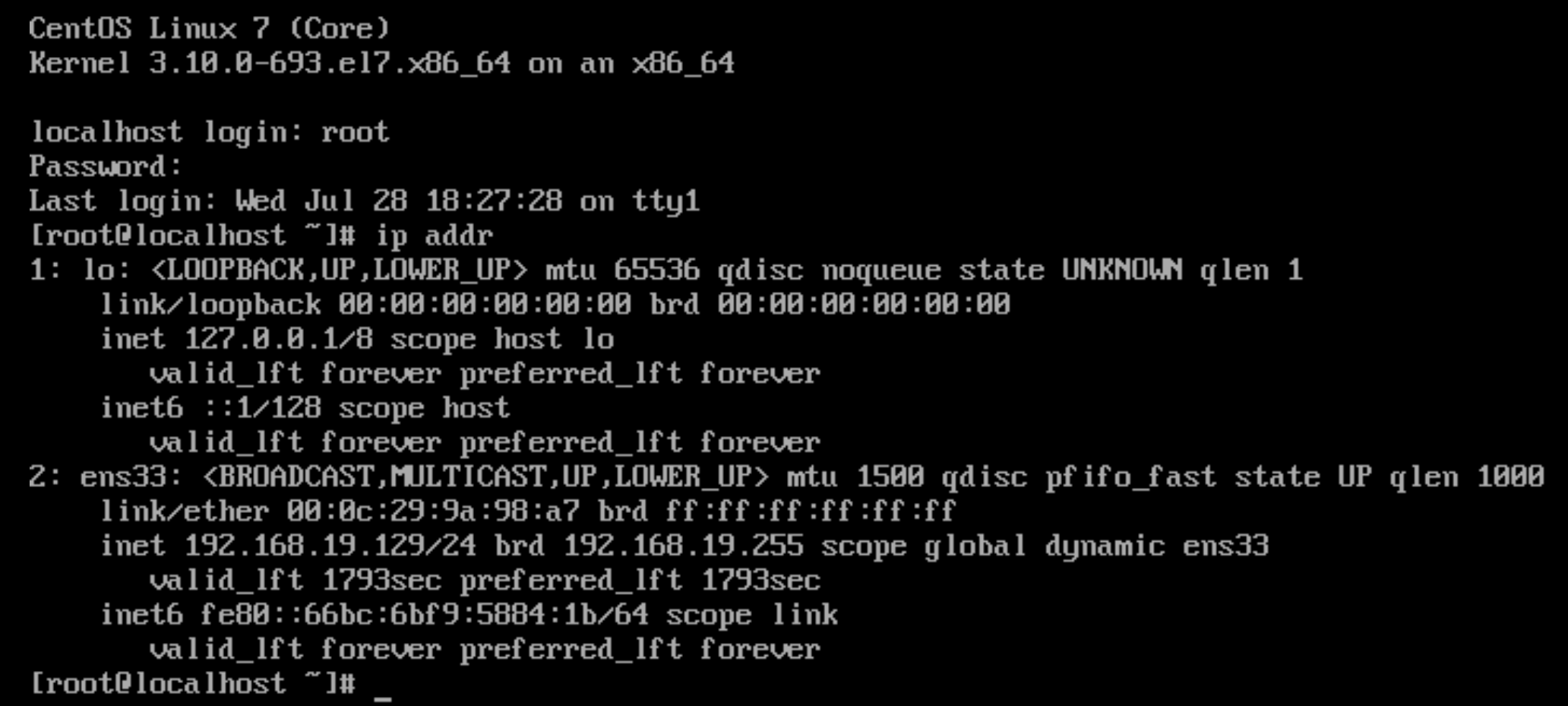
克隆虚拟机后要检查是否可以登录,ip是否能够正常动态分配。
如下图,则表示克隆成功。
Linux极速上手
文件相关命令


- 编辑文件内容
vi hello.txt # 创建hello.txt
i # 编辑模式
# 编辑
esc # 进入命令模式
:wq # 写入退出
cat hello.txt # 查看刚刚写的内容
- 查找字符串
/root # 查找root 回车进行查找
# 按n下一个 N上一个
- 查找某一行内容
:set nu # 设置行号
:10 # 跳转到第10行
- 复制粘贴
# 要复制的行 yy
# p 在当前行的下一行进行粘贴
- 快速删除
# 要删除的行的任意位置 dd
# 删除光标下面的所有行 999 dd
- 快速跳转到文件的首行和末行
G 末尾
gg 首行
文件内容统计相关命令

- wc: 统计字数相关信息
wc -c hello.txt # 只显示Bytes数
wc -l hello.txt # 显示行数
wc -w hello.txt # 显示字数
wc -clw hello.txt # 也可以同时显示
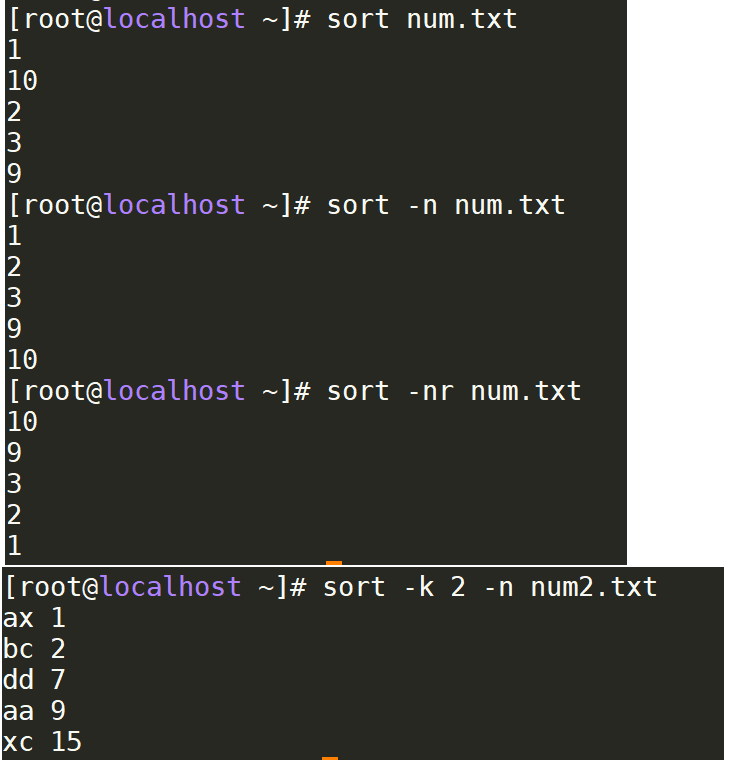
- sort: 排序
sort num.txt # 按照字典序排序
sort -n num.txt # 按照数值排序
sort -nr num.txt # 按照数值排序 倒序
sort -k 2 -n num2.txt # 多列排序 指定关键字列
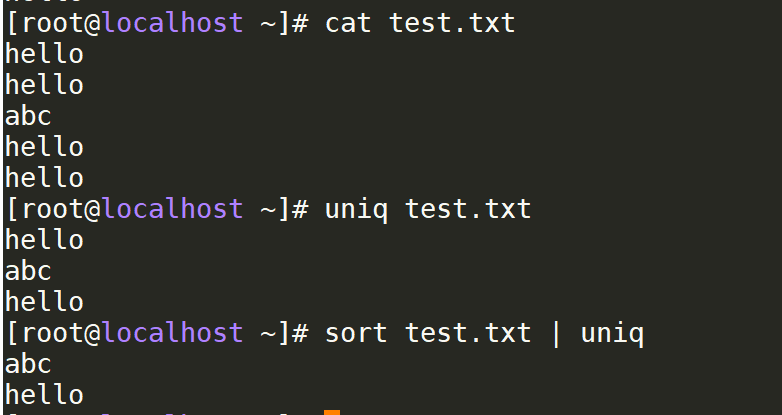
- uniq:检查重复的行列
uniq hello.txt # 去重
uniq -c hello.txt # 去重 并显示重复的次数
uniq -u hello.txt # 返回文件中不重复的行

如果要对上图的内容进行去重的话,需要先进行排序,因为uniq只能对连续行进行去重。
sort test.txt | uniq # 先排序,然后再进行去重
- head:取前N条数据
head num.txt # 前5行数据
sort -nr num.txt | head -3 # 排序后,查看前3条数据
日期相关命令

date # 默认的时间格式
date +"%Y-%m-%d %H:%M:%S" # 除了m,d其余都是大写
date +%s # 获取秒时间戳
date +%s"000" # 获取毫秒时间戳
date --date=”2026-01-01 00:00:00“ +%s # 获取指定时间的时间戳
date --date="1 days ago" # 获取昨天的日期
date --date="2021-03-01 1 days ago" +%d # 查看2021年2月份有多少天
进程相关命令


ps -ef # 显示系统内的所有进程
ps -ef | grep java # 过滤出java的进程
yum install -y net-tools # netstat 默认是没有安装的
netstat -anp # 可以查看端口占用信息



Linux三剑客:grep、sed、awk


grep abc hello.txt # 查找abc
cat hello.txt | grep abc # 查找abc
cat hello.txt | grep ^a # 查找a开头 grep支持正则
cat hello.txt | grep -i abc # 忽略大小写
cat hello.txt | grep -i abc -n # 忽略大小写 并显示行号
ps -ef | grep java | grep -v grep # -v将指定关键字忽略


sed用来自动编辑一个或多个文件,简化对文件的反复操作。
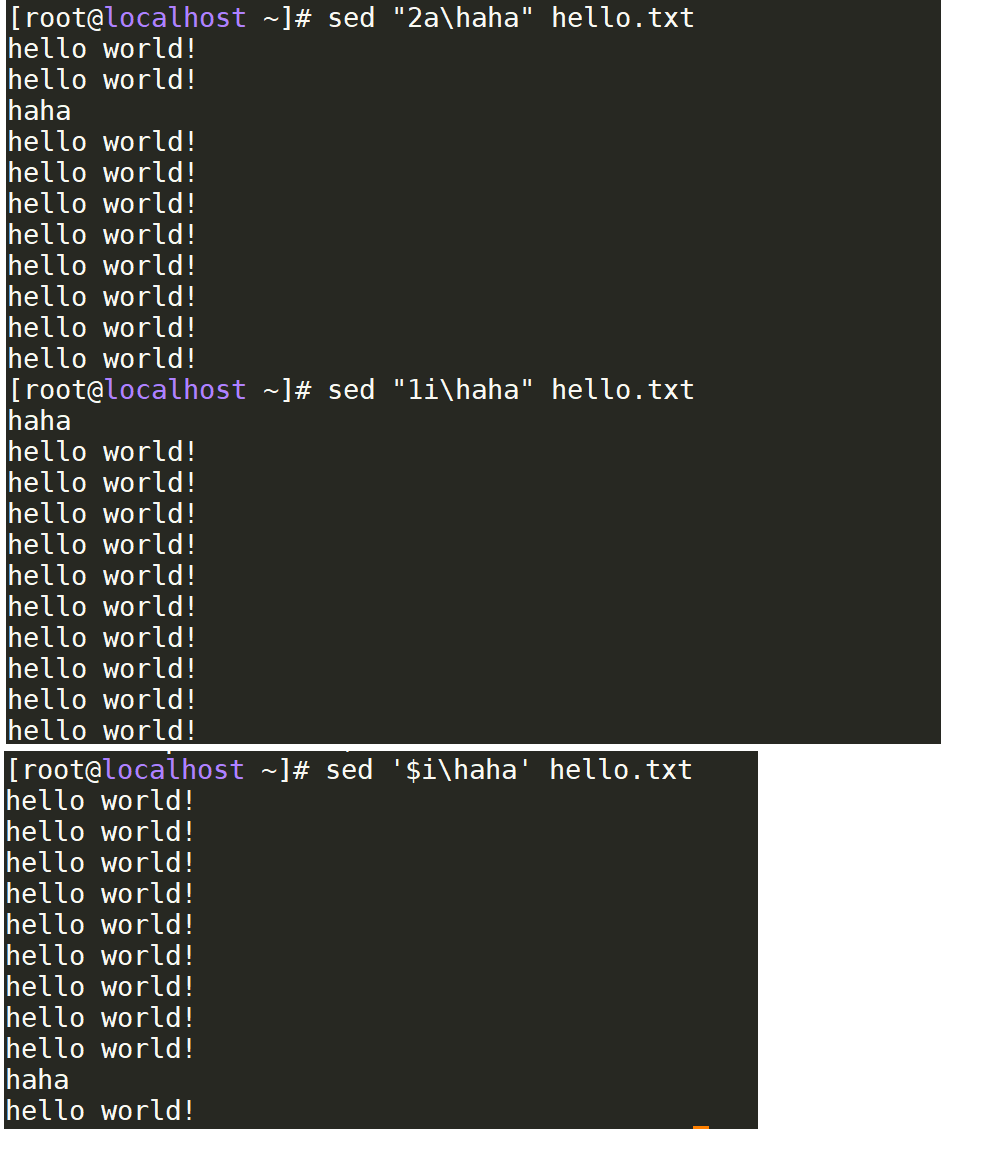
sed "2a\haha" hello.txt # 在hello.txt第2行中追加haha(非文件 是缓冲区)
sed "1i\haha" hello.txt # 第1行前插入haha
sed ''$i\haha' hello.txt # $表示最后一行 最后一行前插入haha
sed '7d' hello.txt # 删除第7行数据
sed '$d' hello.txt # 删除最后一行数据

sed 's/l/a/1' hello.txt # 将l替换为a 第一次出现的
sed 's/l/a/2' hello.txt # 将l替换为a 第二次出现的
sed 's/l/a/g' hello.txt # 将l替换为a 全部替换
sed '2s/l/a/g' hello.txt # 指定第二行 将l替换为a 全部替换
sed -i 's/l/a/g' hello.txt # 将修改结果写入原文件
下面是一个真实的案例,要修改多个配置文件的话
sed -i '61s/127.0.0.1/192.168.182.130/1' redis.conf
awk是一个强大的文本分析工具,相对于grep的查找,sed的编辑,awk在其对数据分析并生成报告时,显得尤为强大,简单来说awk就是把文件逐行的读入,以空白字符为默认分隔符将每行内容切片,切开的部分再进行各种分析处理。
在具体使用awk之前我们还需要掌握awk的一个特性,就是awk在处理文本数据的时候,它会自动给每行中的每个字段分配一个变量
变量从1开始,
$1表示是文本中的第1个数据字段
$2表示是文本中的第2个数据字段
以此类推。
还有一个特殊的 $0 它代表整个文本行的内容
awk '{print $1}' hello.txt # 打印按照空格分隔的第一列
awk '{print $2}' hello.txt # 打印按照空格分隔的第二列
awk -F: '{print $1}' /etc/passwd # 按照:进行分割
awk '/world/{print $1}' hello.txt # 这种写法表示对每次读取到的那一行数据进行匹配,只打印出存在world的行
awk '($1 ~ /world/) {print $1}' hello.txt # 通过$来指定具体是哪一列,需要把具体的对比逻辑放到小括号里面
Linux高级配置

Linux分配身份证号码(ip)
在使用Linux虚拟机的过程中可能会遇到这个问题,当我们重启虚拟机之后,可能会发现使用SecureCRT中配置的信息连不上虚拟机了,我们通过ip addr查看虚拟机的ip信息发现虚拟机的ip地址发生了变化,什么鬼,其实ip发生变化也是正常的,因为现在的ip地址是自动获取的,理论上来说,Linux虚拟机每次重启之后都可能会重新获取到新的ip地址,这样就麻烦了,之前配置好的连接信息又不能用了,怎么解决呢?
如何设置静态ip地址呢?
很简单,打开这个文件,修改里面的一些参数就行了。
sudo vi /etc/sysconfig/network-scripts/ifcfg-ens33
文件的初始内容如下,首先修改BOOTPROTO参数,将之前的dhcp改为static。
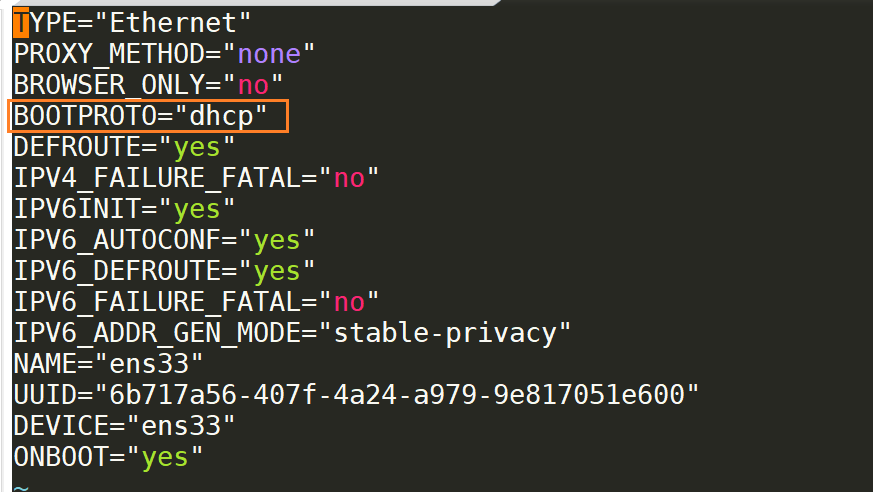
然后在文件末尾增加三行内容。
IPADDR=192.168.19.100
GATEWAY=192.168.19.2
DNS1=192.168.19.2
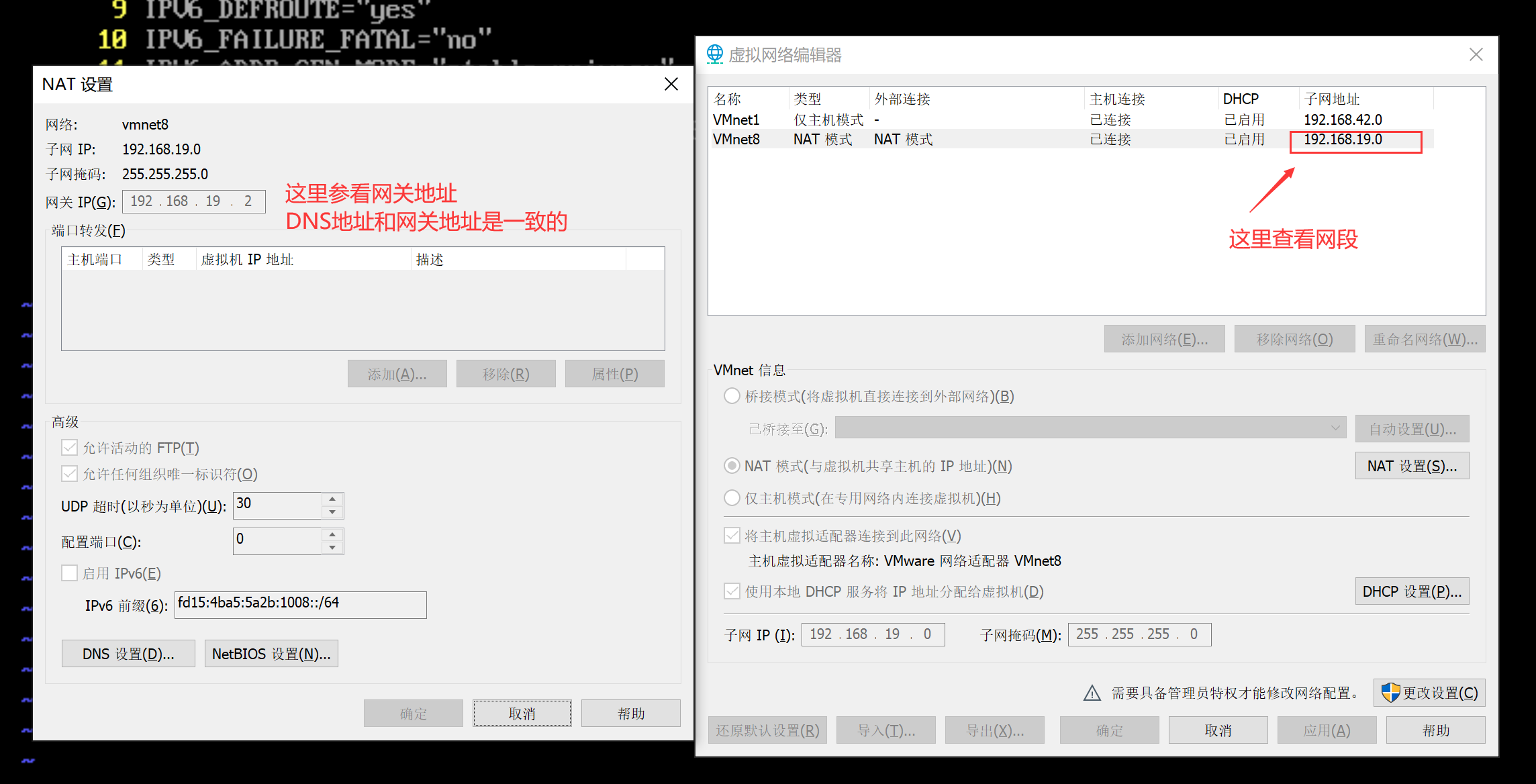
注意:IPADDR的值,192.168.182都是取自虚拟机中虚拟网络编辑器中子网地址的值,最后的100是我自己取的,这个值可以取3~254之间的任意一个数值.
注意:DNS1的值和GATEWAY的值一样即可
修改好以后还有最重要的一步,重启网卡。如果结果显示的是OK,就说明是没有问题的。
service network restart
在这里顺手也把我们之前克隆的第二台机器的ip也修改了,ip设置为192.168.182.101,后面在学习hadoop的时候就需要用到多台机器了。
Linux起名字(hostname)
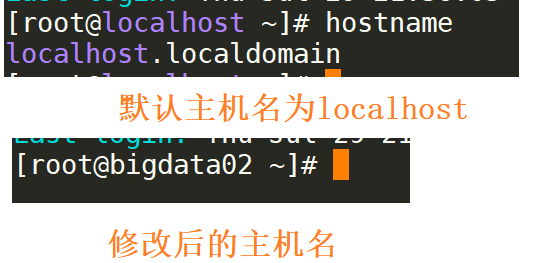
hostname # 查看主机名
hostname bigdata01 # 临时设置主机名 重启失效
vi /etc/hostname # 编辑主机名 永久 重启生效
Linux防火墙
我们在学习阶段,建议关闭防火墙,因为在后面我们会使用到多台机器,如果不关闭防火墙,会遇到机器之间无法通信的场景,比较麻烦,在实际工作中这块工作是由运维负责管理的,我们不需要关注这块。
注意:在实际工作中一般是不需要关闭防火墙的,大家可千万别到时候,上去就把防火墙给关闭了,那样的话针对线上的服务器是有很大安全风险的,我们现在学习阶段是使用的自己本地搭建的虚拟机,不会出现任何安全风险,你们现在遇到的风险都是来源于你们自己。
systemctl stop firewalld # 临时关闭防火墙 重启失效
systemctl status firewalld # 确认当前防火墙状态
systemctl disable firewalld # 永久关闭防火墙 重启生效 推荐

如上图,确认防火墙已经关闭。
Shell编程
什么是shell
shell其实就是用户与linux系统沟通的一个桥梁。
shell编程,最终其实就是要开发一个shell脚本。
第一个shell脚本

shell脚本的第一行内容是: #!/bin/bash
这句话相当于是一个导包语句,将shell的执行环境引入进去了。
注意了,第一行的#号可不是注释,其它行的#号才是注释。
mkdir shell # 创建一个目录,存放脚本
cd shell/
vi hello.sh # 编写shell脚本内容
#!/bin/bash
# first command
echo ’hello world!‘
bash hello.sh # 执行shell脚本
sh hello.sh # 执行shell脚本
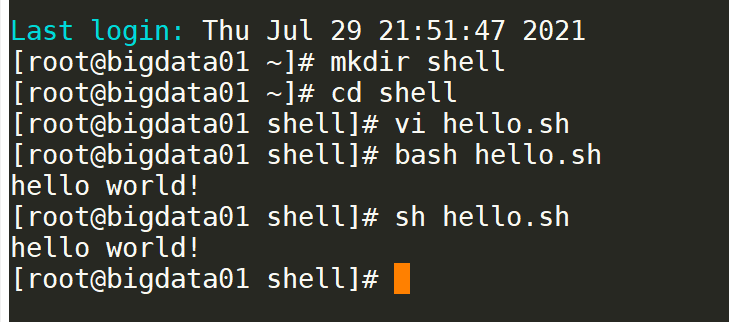
执行shell脚本

bash hello.sh
sh hello.sh
# 先给脚本增加指向权限 再运行脚本
chmod u+x hello.sh
./hello.sh
其实bash和sh在之前对应的是两种类型的shell,不过后来统一了,我们在这也就不区分了,所以在shell脚本中的第一行引入/bin/bash,或者/bin/sh都是一样的,这块大家知道就行了。

如何不要./直接执行本地脚本?
主要原因是这样的,因为在这里我们直接指定的文件名称,前面没有带任何路径信息,那么按照linux的查找规则,它会到PATH这个环境变量中指定的路径里面查找,这个时候PATH环境变量中都有哪些路径呢,我们来看一下。
[root@bigdata01 shell]# echo $PATH
/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/root/bin
所以说到这些路径里面去找肯定是找不到的,那怎么办呢?如果大家在windows中配置过JAVA的PATH环境变量的话就比较容易理解了,在这里我们只需要在PATH中加一个.即可,.表示当前目录,这样在执行的时候会自动到当前目录查找。
下面我们来修改一下这个PATH环境变量,
注意,在这我们先直接修改,后面会详细讲解环境变量的相关内容
打开/etc/profile文件,在最后一行添加export PATH=.:$PATH,保存文件即可。
然后执行source /etc/profile 重新加载环境变量配置文件,这样才会立刻生效。
[root@bigdata01 shell]# echo $PATH
.:/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/root/bin
shell中的变量

- 变量不需要声明,初始化也不需要指定类型
shell就是弱类型语言。
shell的变量和Python很像,不用提前声明,变量也没有类型。
- 变量命名:只能使用数字、字母和下划线,且不能以数字开头
这个变量命名规则和大部分语言一致。
- 变量赋值时通过“=”进行赋值,在变量、等号和值之间不能出现空格!
name=zhangsan
echo $name # zhangsan
echo ${name} # zhangsan
echo $namehaha # 没有该变量
echo ${name}haha # zhangsanhaha 可以实现无缝拼接
变量的分类


本地变量
- 格式: var_name=value
- 在当前shell中的临时变量,对子进程或其他shell无效。
就是本地变量,作用范围只在本进程!
使用命令bash 就可以进入一个子shell,exit可以退出。
关于子进程的查看可以使用pstree


- 格式: exprot var_name=value
- 用于设置临时环境变量,对子shell有效,对其他shell无效
环境变量和作用范围和本地变量的作用范围不一样,环境变量对子进程是有效的。
- 注意:设置永久环境变量,需要添加到配置文件/etc/profile中,然后执行 source /etc/profile 可立刻生效
这里的环境变量和windows中的环境变量意思是一致的。

- $0 $1 $2...
- 格式: xxx.sh abc xyz
- 位置变量相当于java中main中的args参数,可以在shell脚本中动态获取外部参数
这样就可以根据外部传的参数动态执行不同的业务逻辑了,在后面的学习中大家会经常看到位置变量的使用形式。
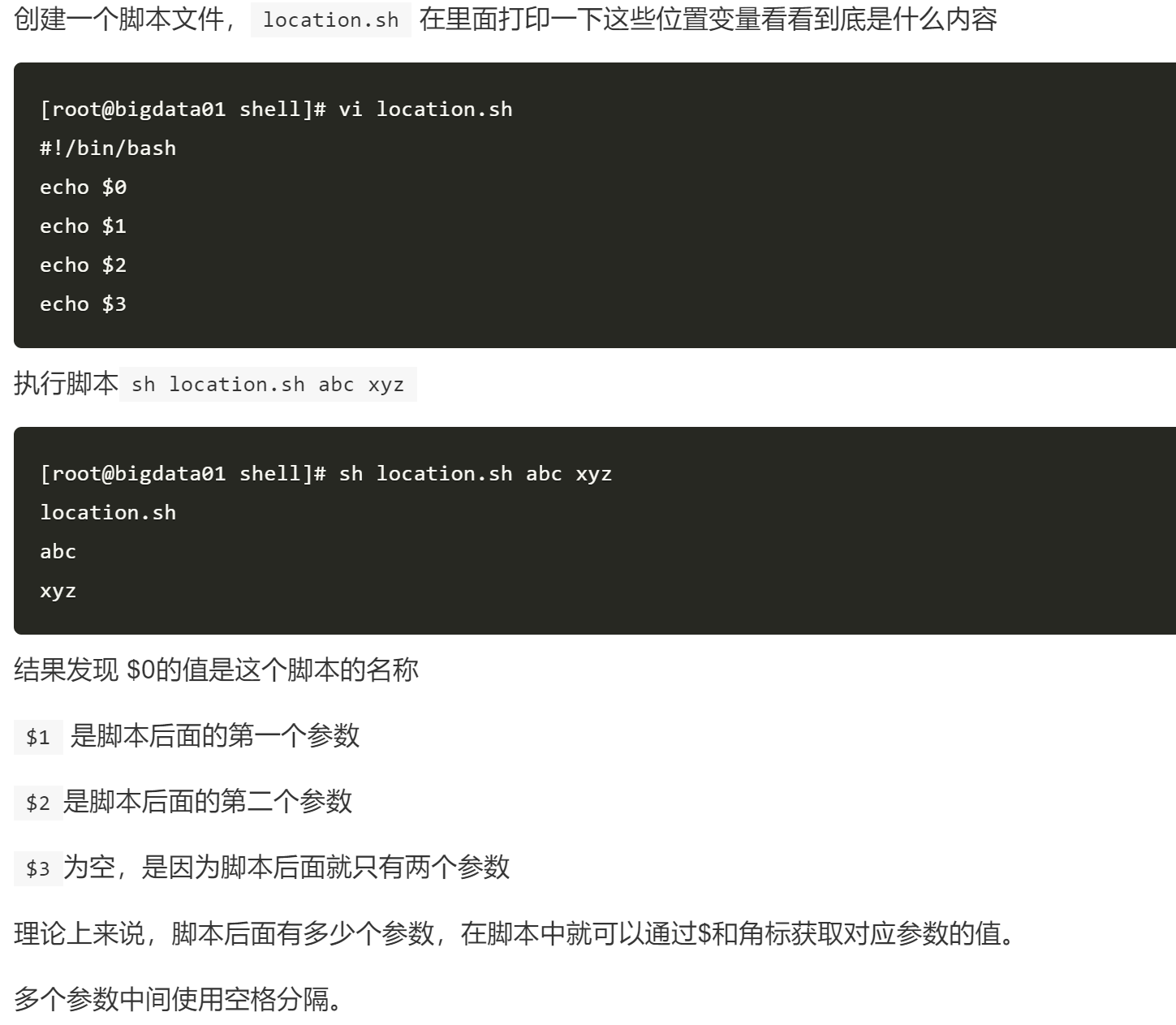
注意:$0打印是脚本名字!

- $?:上一条命令的返回状态码,状态码在0~255之间
如果命令执行成功,这个返回状态码是0,如果失败,则是在1~255之间,不同的状态码代表着不同的错误信息,也就是说,正确的道路只有一条,失败的道路有很多。
ll
echo $? # 0
lk
echo $? # 127
- $#:shell脚本所有参数的个数

这个特殊变量的应用场景是这样的,假设我们的脚本在运行的时候需要从外面动态获取三个参数,那么在执行脚本之前就需要先判断一下脚本后面有没有指定三个参数,如果就指定了1个参数,那这个脚本就没有必要执行了,直接停止就可以了,参数个数都不够,执行是没有意义的。


name=jack
echo '$name' # $name 单引号不解析变量
echo "$name" # jack 双引号解析变量
# 反引号是把“变量命令”执行了 也就是变量本身就是一个命令
name=pwd
`$name` # -bash: /root: Is a directory
echo `$name` # /root
# ``和$()是一样的效果
$($name) # -bash: /root: Is a directory
echo $($name) # /root
shell中的循环和判断
前面我们掌握了shell脚本中单独命令的操作,下面我们就希望能在shell脚本中增加一些逻辑判断,这样就可以解决一些复杂的工作需求了
在这里我们主要学习for循环、while循环和if判断。
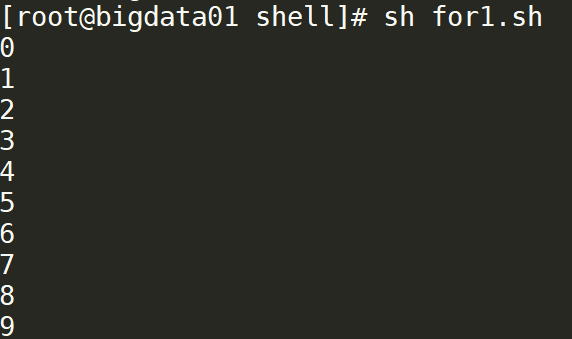
for循环
下图是for循环的两种形式。

#!/bin/bash
for((i=0;i<10;i++))
do
echo $i
done
#!/bin/bash
for i in 1 2 3
do
echo $i
done

while循环


#!/bin/bash
while test 2 -gt 1
do
echo yes
sleep 1 # 休眠一秒
done
while [ 2 -gt 1 ] # -gt前后可以没有空格
do
echo yes
sleep 1
done
while [ "abc" = "abc" ]
do
echo yes
sleep 1
done
if判断
前面我们学习了两个循环的使用,下面来学习一下if这个逻辑判断,有了if,shell脚本才真正有了灵魂
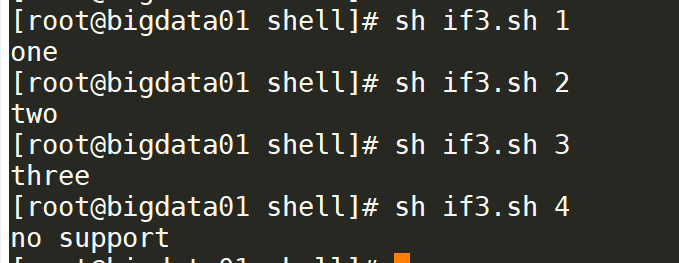
if判断分为三种形式
- 单分支
- 双分支
- 多分支

#!/bin/bash
if [ $# -lt 1 ]
then
echo "not found param"
exit 100
fi
flag=$1
if [ $flag -eq 1 ]
then
echo "one"
fi

#!/bin/bash
if [ $# -lt 1 ]
then
echo "not found param"
exit 100
fi
flag=$1
if [ $flag -eq 1 ]
then
echo "one"
else
echo "not support"
fi

#!/bin/bash
if [ $# -lt 1 ]
then
echo "not found param"
exit 100
fi
flag=$1
if [ $flag -eq 1 ]
then
echo "one"
elif [ $flag -eq 2 ]
then
echo "two"
elif [ $flag -eq 3 ]
then
echo "three"
else
echo "not support"
fi
shell扩展

在执行程序的末尾加上&符号,可以让程序在后台执行。但是关闭shell窗口依然会让后台进程关闭。
如何保证关闭shell窗口而不影响放到后台的shell脚本执行呢?
也很简单,在命令前面加上nohup 即可。
原理就是,默认情况下,当我们关闭shell窗口时,shell窗口会向之前通过它启动的所有shell脚本发送停止信号,当我们加上nohup之后,就会阻断这个停止信号的发送,所以已经放到后台的shell脚本就不会停止了。
此时如果想要停止这个shell脚本的话就只能使用kill了
注意:使用nohup之后,脚本输出的信息默认都会存储到当前目录下的一个nohup.out日志文件中,后期想要排查脚本的执行情况的话就可以看这个日志文件。
下面来看一下什么是标准输出、标准错误输出和重定向
-
标准输出:表示是命令或者程序输出的正常信息 用1表示标准输出 >省略就是1,表示标准输出
-
标准错误输出:表示是命令或者程序输出的错误信息 用2表示标准错误输出
# 重定向标准输出
ll 1>a.txt # 注意 1> 要连接起来
ll 1>>a.txt # 追加重定向
# 重定向标准错误输出
lk 2>b.txt
案例
nohup hello.sh >/dev/null 2>&1 &
# nohup和&:可以让程序一直在后台运行
# /dev/null:是linux中的黑洞,任何数据扔进去都找不到了
# >/dev/null:把标准输出重定向到黑洞中,表示脚本的输出信息不需要存储
# 2>&1 :表示是把标准错误输出重定向到标准输出中
# 最终这条命令的意思就是把脚本放在后台一直运行,并且把脚本的所有输出都扔到黑洞里面
Linux中的定时器crontab
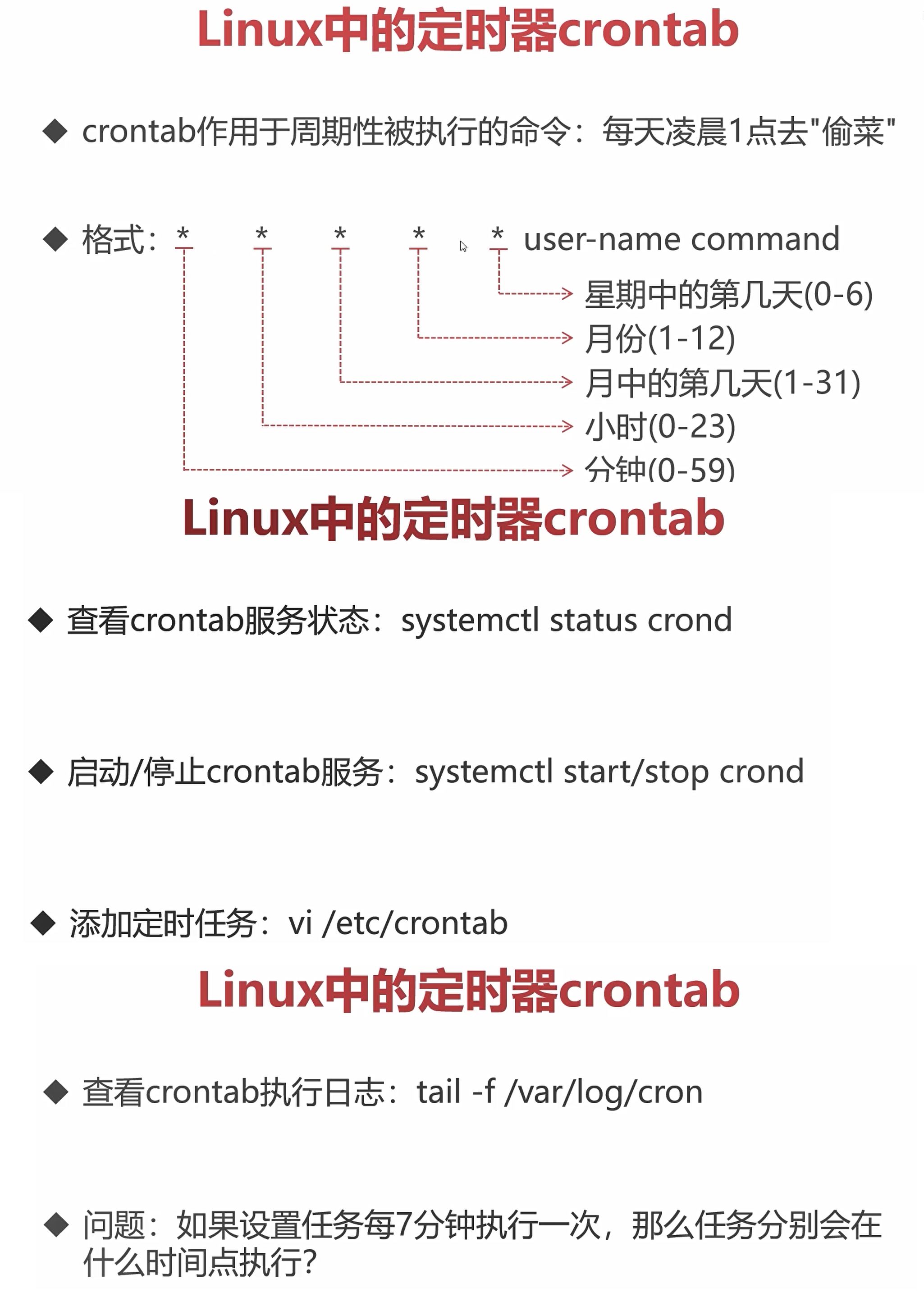
systemctl status crond # 查看crontab服务状态
systemctl start/stop crond # 启动/停止crontab服务
vi /etc/crontab # 添加定时任务(分钟是最小单位)
tail -f xxx # 跟踪文件
编写脚本,定时执行每隔一分钟打印一次当前时间
/root/shell/showTime.sh
#!/bin/bash
showTime=`date +"%Y-%m-%d %H:%M:%S"`
echo $showTime
然后在 /etc/crontab 中写如下命令
* * * * * root sh /root/shell/showTime.sh >> /root/shell/showTime.log
注意: 如果设置每7分钟执行,那么crontab是每个小时的0,7,14,...这样去执行,而不是按照设定时候的时间往后推7分钟。
还有就是这里的间隔时间是7分钟,7分钟无法被60整除,那执行到这个小时的最后一次以后会怎么办呢?它最后会在第56分钟执行一次,再往后的话继续往后面顺延7分钟吗?不是的,下一次执行就是下一个小时的0分开始执行了,所以针对这种除不尽的到下一小时就开始重新计算了,不累计。
在linux上安装JDK
大数据框架基本都是依赖于Java环境的,所以JDK的安装就是最基础的环境配置了。

小结
如果通过克隆的方式创建linux虚拟机?
非常简单...
第一台虚拟机是需要安装的,后面的虚拟机都可以直接克隆第一台机器。
先不要着急配置静态IP,直接先克隆,先使用动态IP分配。
常用的终端
SecureCRT
Xshell
MobaXTerm
vi相关操作
* 编辑文件内容
vi hello.txt # 创建hello.txt
i # 编辑模式
# 编辑
esc # 进入命令模式
:wq # 写入退出
cat hello.txt # 查看刚刚写的内容
* 查找字符串
/root # 查找root 回车进行查找
# 按n下一个 N上一个
* 查找某一行内容
:set nu # 设置行号
:10 # 跳转到第10行
* 复制粘贴
# 要复制的行 yy
# p 在当前行的下一行进行粘贴
* 快速删除
# 要删除的行的任意位置 dd
# 删除光标下面的所有行 999 dd
* 快速跳转到文件的首行和末行
G 末尾
gg 首行
文件内容统计相关操作
* wc: 统计字数相关信息
wc -c hello.txt # 只显示Bytes数
wc -l hello.txt # 显示行数
wc -w hello.txt # 显示字数
wc -clw hello.txt # 也可以同时显示
* sort: 排序
sort num.txt # 按照字典序排序
sort -n num.txt # 按照数值排序
sort -nr num.txt # 按照数值排序 倒序
sort -k 2 -n num2.txt # 多列排序 指定关键字列
* uniq:检查重复的行列
uniq hello.txt # 去重
uniq -c hello.txt # 去重 并显示重复的次数
uniq -u hello.txt # 返回文件中不重复的行
sort test.txt | uniq # 先排序,然后再进行去重
* head:取前N条数据
head num.txt # 前5行数据
sort -nr num.txt | head -3 # 排序后,查看前3条数据
关于日期相关指令
date # 默认的时间格式
date +"%Y-%m-%d %H:%M:%S" # 除了m,d其余都是大写
date +%s # 获取秒时间戳
date +%s"000" # 获取毫秒时间戳
date --date=”2026-01-01 00:00:00“ +%s # 获取指定时间的时间戳
date --date="1 days ago" # 获取昨天的日期
date --date="2021-03-01 1 days ago" +%d # 查看2021年2月份有多少天
进程相关指令
ps -ef # 显示系统内的所有进程
ps -ef | grep java # 过滤出java的进程
yum install -y net-tools # netstat 默认是没有安装的
netstat -anp # 可以查看端口占用信息
top # 动态监控进程
jps # 查看运行的java进程
kill pid # 让进程自杀
kill -9 pid # 动手杀死进程
linux三剑客
* grep
grep abc hello.txt # 查找abc
cat hello.txt | grep abc # 查找abc
cat hello.txt | grep ^a # 查找a开头 grep支持正则
cat hello.txt | grep -i abc # 忽略大小写
cat hello.txt | grep -i abc -n # 忽略大小写 并显示行号
ps -ef | grep java | grep -v grep # -v将指定关键字忽略
* sed
sed "2a\haha" hello.txt # 在hello.txt第2行中追加haha(非文件 是缓冲区)
sed "1i\haha" hello.txt # 第1行前插入haha
sed ''$i\haha' hello.txt # $表示最后一行 最后一行前插入haha
sed '7d' hello.txt # 删除第7行数据
sed '$d' hello.txt # 删除最后一行数据
sed 's/l/a/1' hello.txt # 将l替换为a 第一次出现的
sed 's/l/a/2' hello.txt # 将l替换为a 第二次出现的
sed 's/l/a/g' hello.txt # 将l替换为a 全部替换
sed '2s/l/a/g' hello.txt # 指定第二行 将l替换为a 全部替换
sed -i 's/l/a/g' hello.txt # 将修改结果写入原文件
sed -i '61s/127.0.0.1/192.168.182.130/1' redis.conf
* awk
awk '{print $1}' hello.txt # 打印按照空格分隔的第一列
awk '{print $2}' hello.txt # 打印按照空格分隔的第二列
awk -F: '{print $1}' /etc/passwd # 按照:进行分割
awk '/world/{print $1}' hello.txt # 这种写法表示对每次读取到的那一行数据进行匹配,只打印出存在world的行
awk '($1 ~ /world/) {print $1}' hello.txt # 通过$来指定具体是哪一列,需要把具体的对比逻辑放到小括号里面
如何配置静态ip?
vi etc/sysconfig/network-scripts/ifcfg-ens33
BOOTPROTO="static"
IPADDR=192.168.19.100
GATEWAY=192.168.19.2
DNS1=192.168.19.2
注意:DNS1的值和GATEWAY的值一样即可
service network restart
如何设置主机名?
hostname # 查看主机名
hostname bigdata01 # 临时设置主机名 重启失效
vi /etc/hostname # 编辑主机名 永久 重启生效
如果关闭防火墙?
systemctl stop firewalld # 临时关闭防火墙 重启失效
systemctl status firewalld # 确认当前防火墙状态
systemctl disable firewalld # 永久关闭防火墙 重启生效 推荐
如何执行脚本?
#!/bin/bash
echo 'hello world!'
bash hello.sh
sh hello.sh
chmod u+x hello.sh
./hello.sh
shell的变量
* 变量不需要声明,初始化也不需要指定类型
shell就是弱类型语言。
shell的变量和Python很像,不用提前声明,变量也没有类型。
* 变量命名:只能使用数字、字母和下划线,且不能以数字开头
这个变量命名规则和大部分语言一致。
* 变量赋值时通过“=”进行赋值,**在变量、等号和值之间不能出现空格!**
name=zhangsan
echo $name # zhangsan
echo ${name} # zhangsan
echo $namehaha # 没有该变量
echo ${name}haha # zhangsanhaha 可以实现无缝拼接
shell的变量类型
本地变量
* 格式: var_name=value
* 在当前shell中的临时变量,对子进程或其他shell无效。
就是本地变量,作用范围只在本进程!
环境变量
* 格式: exprot var_name=value
* 用于设置临时环境变量,**对子shell有效,对其他shell无效**
环境变量和作用范围和本地变量的作用范围不一样,环境变量对子进程是有效的。
* 注意:设置永久环境变量,需要添加到配置文件/etc/profile中,然后执行 source /etc/profile 可立刻生效
这里的环境变量和windows中的环境变量意思是一致的。
位置变量
* \$0 \$1 \$2...
* 格式: xxx.sh abc xyz
* 位置变量相当于java中main中的args参数,可以在shell脚本中动态获取外部参数
这样就可以根据外部传的参数动态执行不同的业务逻辑了,在后面的学习中大家会经常看到位置变量的使用形式。
注意:$0 是脚本文件的名字
特殊变量
* \$?:上一条命令的返回状态码,状态码在0~255之间
如果命令执行成功,这个返回状态码是0,如果失败,则是在1~255之间,不同的状态码代表着不同的错误信息,也就是说,正确的道路只有一条,失败的道路有很多。
* \$#:shell脚本所有参数的个数
这个特殊变量的应用场景是这样的,假设我们的脚本在运行的时候需要从外面动态获取三个参数,那么在执行脚本之前就需要先判断一下脚本后面有没有指定三个参数,如果就指定了1个参数,那这个脚本就没有必要执行了,直接停止就可以了,参数个数都不够,执行是没有意义的。
关于子进程
使用命令bash 就可以进入一个子shell,exit可以退出。
关于子进程的查看可以使用pstree
变量和引号的特殊使用
name=jack
echo '$name' # $name 单引号不解析变量
echo "$name" # jack 双引号解析变量
# 反引号是把“变量命令”执行了 也就是变量本身就是一个命令
name=pwd
`$name` # -bash: /root: Is a directory
echo `$name` # /root
# ``和$()是一样的效果
$($name) # -bash: /root: Is a directory
echo $($name) # /root
shell中的变量比较规则
格式:test 表达式 | [ 表达式 ] 注意:[]首位的空格不能少
整型比较: -gt -lt -ge -le -eq -ne
字符串比较: = !=
while test 2 -gt 1
while [ 2 -gt 1 ] # -gt前后可以没有空格
while [ "abc" = "abc" ]
shell后台执行程序
jobs # 查看执行的进程
bg 编号 # 后台执行
fg 编号 # 前台执行
在执行程序的末尾加上&符号,可以让程序在后台执行。但是关闭shell窗口依然会让后台进程关闭。
如何保证关闭shell窗口而不影响放到后台的shell脚本执行呢?
也很简单,在命令前面加上nohup 即可。
原理就是,默认情况下,当我们关闭shell窗口时,shell窗口会向之前通过它启动的所有shell脚本发送停止信号,当我们加上nohup之后,就会阻断这个停止信号的发送,所以已经放到后台的shell脚本就不会停止了。
此时如果想要停止这个shell脚本的话就只能使用kill了
**注意:使用nohup之后,脚本输出的信息默认都会存储到当前目录下的一个nohup.out日志文件中,后期想要排查脚本的执行情况的话就可以看这个日志文件。**
标准输出、 标准错误输出、重定向
* 标准输出:表示是命令或者程序输出的正常信息 用1表示标准输出 >省略就是1,表示标准输出
* 标准错误输出:表示是命令或者程序输出的错误信息 用2表示标准错误输出
# 重定向标准输出
ll 1>a.txt # 注意 1> 要连接起来
ll 1>>a.txt # 追加重定向
# 重定向标准错误输出
lk 2>b.txt
输出&重定向综合案例
nohup hello.sh >/dev/null 2>&1 &
# nohup和&:可以让程序一直在后台运行
# /dev/null:是linux中的黑洞,任何数据扔进去都找不到了
# >/dev/null:把标准输出重定向到黑洞中,表示脚本的输出信息不需要存储
# 2>&1 :表示是把标准错误输出重定向到标准输出中
# 最终这条命令的意思就是把脚本放在后台一直运行,并且把脚本的所有输出都扔到黑洞里面
crontab
systemctl status crond # 查看crontab服务状态
systemctl start/stop crond # 启动/停止crontab服务
vi /etc/crontab # 添加定时任务(分钟是最小单位)
tail -f xxx # 跟踪文件
然后在 /etc/crontab 中写如下命令
* * * * * root sh /root/shell/showTime.sh >> /root/shell/showTime.log
注意: 如果设置每7分钟执行,那么crontab是每个小时的0,7,14,...这样去执行,而不是按照设定时候的时间往后推7分钟。
还有就是这里的间隔时间是7分钟,7分钟无法被60整除,那执行到这个小时的最后一次以后会怎么办呢?它最后会在第56分钟执行一次,再往后的话继续往后面顺延7分钟吗?不是的,下一次执行就是下一个小时的0分开始执行了,所以针对这种除不尽的到下一小时就开始重新计算了,不累计。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号