Excel & SQL | 数据运算 | 03
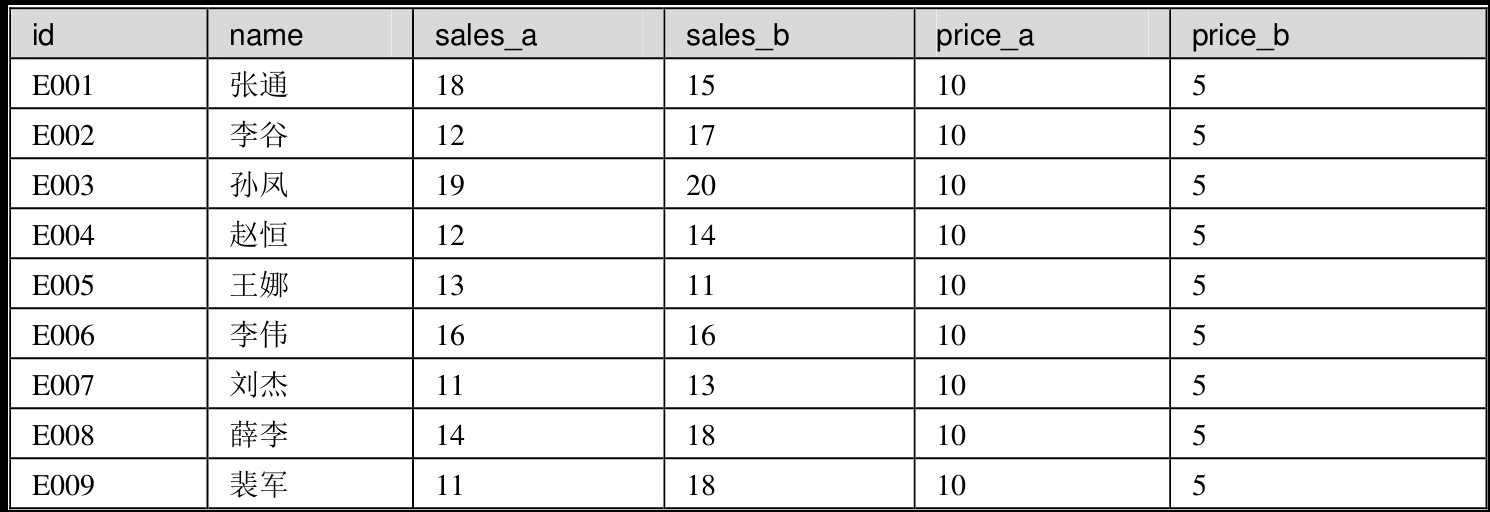
上表存储了id(销售人员ID)、 name (销售人员姓名)、sales_a( a产品销量) 、sales_b ( b产品销量)、price_a ( a产品价格)和price_b ( b产品价格)六个字段。我们把上表中的数据存储在demo数据库的chapter7表中。
算术运算
算术运算就是我们所熟悉的加减乘除运算,是比较常见的、简单的运算。
无论是在Excel中还是SQL中,我们都可以直接对任意两列或多列进行相应的运算。
在SQL中,我们要对某两列或多列进行算术运算时,直接将相应的列名与相应的运算符连接即可。现在需要获取每个销售产品的所有销量,即a产品销量+b产品销量;a产品与b产品的销量差﹔每个销售产品的总销售额,即a产品销量×a产品价格+b产品销量×b产品价格;a产品与b产品的价格倍数;a产品销量的2倍。具体实现代码如下∶
select
id,
(sales_a + sales_b) as all_sales,
(sales_a - sales_b) as sales_a_b,
(sales_a * price_a + sales_b * price_b) as gmv,
(price_a / price_b) as price_a_b,
(sales_a * 2) as 2_sales_a
from chapter7;

在SQL中,加减乘除运算的优先级和数学运算中的优先级是一样的,即先算乘除再算加减。
在算术运算中除了加减乘除,还有整除(div)和求余(%和mod)两种运算。
select 7 div 2 -- 结果为3
select 7 % 2 -- 结果为1
select 7 mod 2 -- 结果为1
这里需要特别说明一下与null相关的运算,如果null参与加减乘除的算术运算,会得到什么结果?
-- 结果都为null
select
1+null,
1-null,
1*null,
1/null;
运行上面的代码,结果为4个null,这是因为null与任何数进行运算,结果都是null,类似于0乘任何数都得0。
比较运算
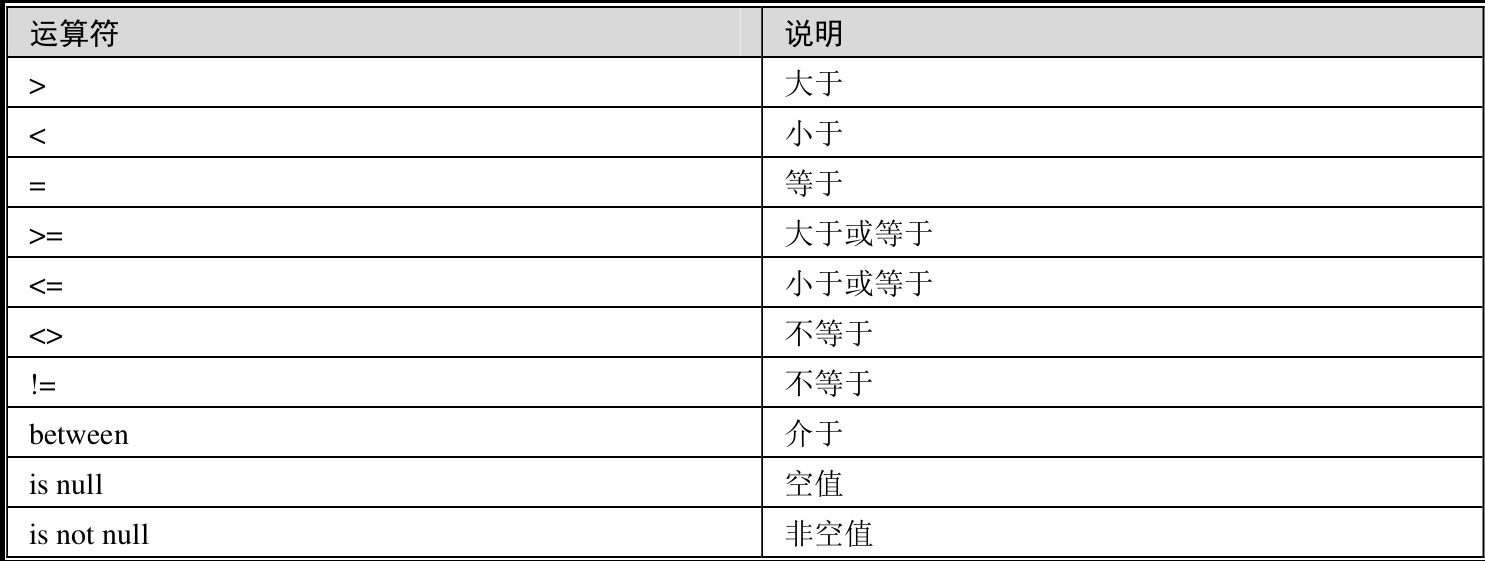
前面的几个运算符读者应该比较了解,后四个运算符可能不太熟悉,这四个运算符只可以在SQL中使用,而不可以在Excel中使用。
在SQL中,要实现比较运算,需要先指明待比较的具体列,然后用比较运算符将不同的列连接起来。
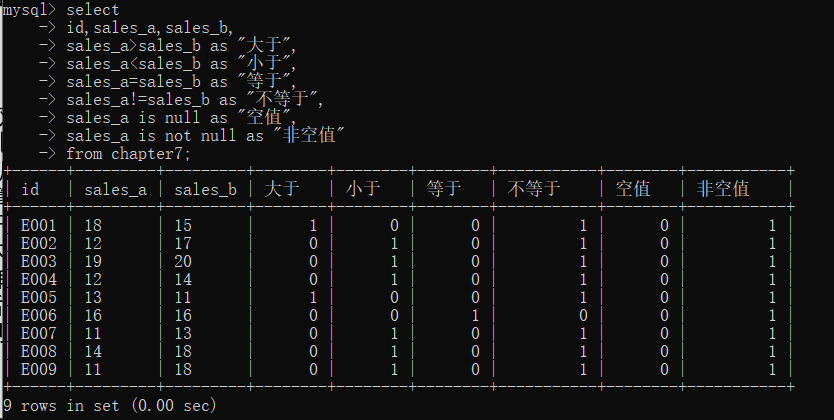
select
id,sales_a,sales_b,
sales_a>sales_b as "大于",
sales_a<sales_b as "小于",
sales_a=sales_b as "等于",
sales_a!=sales_b as "不等于",
sales_a is null as "空值",
sales_a is not null as "非空值"
from chapter7;
在上面的代码中,我们对chapter7表中的sales_a列和sales_b列进行了各种比较运算,最后得到不同的结果,结果展示与Excel有所不同,在Excel中,如果比较结果是正确的,则返回TRUE,否则返回FALSE;而在SQL中如果比较结果是正确的,则返回1,否则返回0。运行上面的代码,具体运行结果如下表所示。
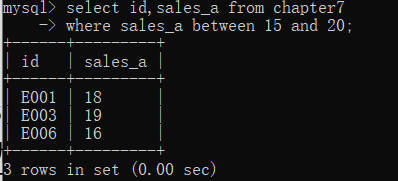
比较运算不仅可以被用于列与列之间的比较,也可以被用于前面讲的条件筛选中,只需在where后面写明具体的比较运算即可。比如,我们要获取a产品的销量为15~20范围内的id列和sales_a列,可以通过如下代码实现∶
select id,sales_a from chapter7
where sales_a between 15 and 20;
如果要获取a产品销量大于15的id列和sales_a列,则可以通过如下代码实现∶
select id,sales_a from chapter7
where sales_a > 15;

逻辑运算
逻辑运算符主要用来连接多个条件,有and、or、not三种。
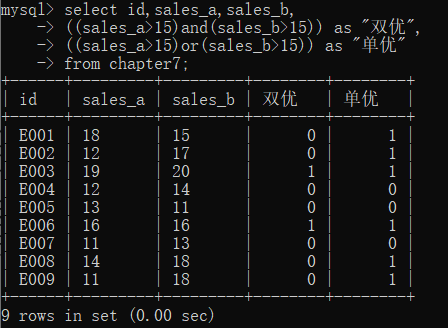
在SQL中实现逻辑运算与在Excel中类似,比如,我们要给每个id加两个标签∶双优和单优。双优的标准是sales_a列和sales_b列均大于15,单优的标准是只要sales_a列和sales_b列中有一列大于15即可。具体实现代码如下:
select id,sales_a,sales_b,
((sales_a>15)and(sales_b>15)) as "双优",
((sales_a>15)or(sales_b>15)) as "单优"
from chapter7;
运行上面的代码,满足双优标准的id会被加上1标签,不满足的被加上O标签,单优也是如此,具体运行结果如下:
数学运算
数学运算就是与数学相关的一些运算,比如三角函数、对数运算等。
求绝对值
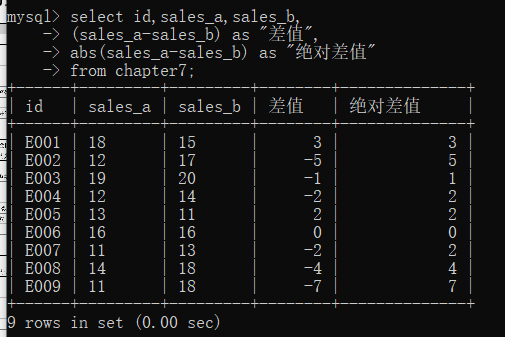
读者应该都知道绝对值是什么意思,求绝对值也是比较常见的一种运算。比如,我们想要求每个id对应的sales_a列和sales_b列的绝对差值,如果直接将这两列做差,得到的结果肯定有正有负,但我们想要求的是绝对差值,所以我们需要对直接做差后的结果求绝对值。具体实现代码如下∶
select id,sales_a,sales_b,
(sales_a-sales_b) as "差值",
abs(sales_a-sales_b) as "绝对差值"
from chapter7;
求最小整数值
有时候,我们会按照某个规则生成某个数对应的整数值,比如,生成不小于x的最小整数值。在SQL中,我们使用的是ceil()函数,具体实现代码如下︰
select ceil(2.9);
求最大整数值
与最小整数值对应的是最大整数值,比如,生成不大于x的最大整数值。在SQL中,我们使用的是floor()函数,具体实现代码如下:
select floor(2.1);
随机数生成
所谓随机数,就是随机产生的数,在SQL中,我们使用rand()函数来生成随机数,rand()函数返回0~1范围内的一个随机浮点数。
直接运行下面的代码,就会得到0~1范围内的一个随机浮点数,每次运行下面的代码,会得到不同的结果∶
select rand();
小数点位数调整
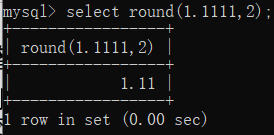
我们平时会经常遇到各种小数,有的小数的小数点位数比较多,我们可以根据自己的需要进行调整。在SQL中,我们使用round()函数来对小数点位数进行调整。具体实现代码如下:
select round(1.1111,2);
如果我们要对一整列的小数点位数进行调整,只需要把1.1111换成对应的列名,把2换成想要保留的小数点位数即可。
如果我们要给每个id对应生成一个随机数,则可以通过如下代码实现︰
select id,rand() as "随机数" from chapter7;
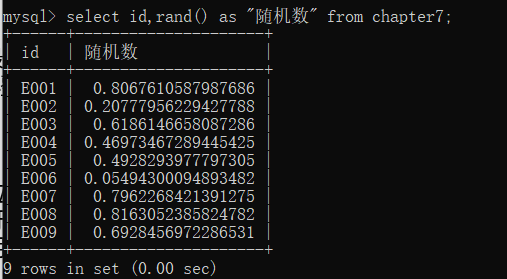
随机数生成还可以用在随机抽样中,比如,我们现在要从9个id中随机抽取出3个,现在每个id都有一个随机数,那么我们只需要把id按照随机数大小进行排序,最后前3行的数据就是我们随机抽样的结果。具体实现代码如下∶
select id,rand() as "随机数" from chapter7
order by rand() limit 3;

正负判断
有时候,我们要判断两个数的大小关系,可以对这两个数进行做差,然后根据差值进行正负判断,通过正负号就可以得到这两个数的大小关系。在SQL中,我们使用sign()函数来进行正负判断。比如,我们要判断每个id对应
的sales_a列和sales_b列的差值的正负,可以通过如下代码实现∶
select id,sales_a,sales_b,
(sales_a-sales_b) as sales_a_b,
sign(sales_a-sales_b) as "正负"
from chapter7;
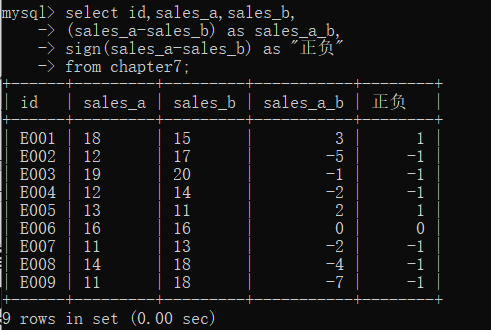
运行上面的代码,就会得到每个id对应的sales_a列和sales_b列的差值,以及差值的正负。如果差值为正,则结果为1;如果差值为负,则结果为-1;如果差值为0,则结果为0。
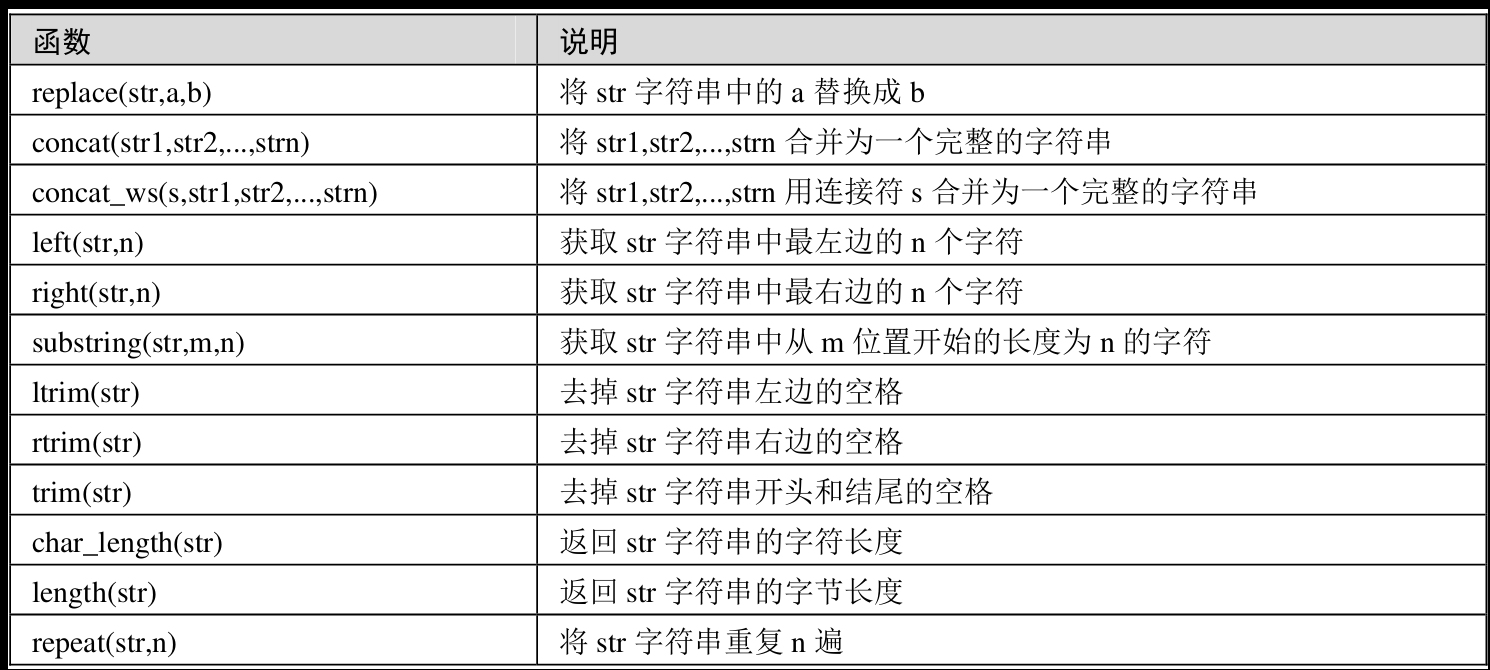
字符串运算
字符串运算也是比较常见的一种运算,字符串运算的函数如下表所示。
字符串替换
有时候,我们需要对一个长字符串中的某个或某些字符进行替换。在SQL中,我们使用的是replace()函数,具体实现代码如下∶
select repalce("AaAaAa","A","a")
运行上面的代码,字符串AaAaAa中的所有A被替换成a,最后得到的结果为aaaaaa。
如果我们要对某一列中的每个值进行替换,比如,把chapter7表中id列的字符E替换成e,具体实现代码如下:
select id,replace(id,"E","e") as repalce_id from chapter7;

字符串合并
字符串合并就是将多个字符串合并成一个字符串,在SQL中,我们使用的是concat()函数。
有的表中姓和名是分为两列存储的,所以我们需要将姓和名合并起来组成姓名,具体实现代码如下︰
select concat("Hello",", ","World!");
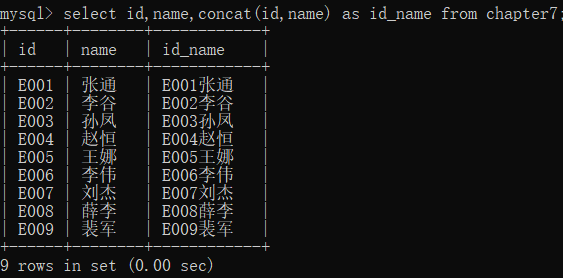
如果将一张表中的两列或多列合并,则直接在concat()函数的括号中指明要合并的列名即可,比如,将chapter7表中的id列和name列合并,具体实现代码如下∶
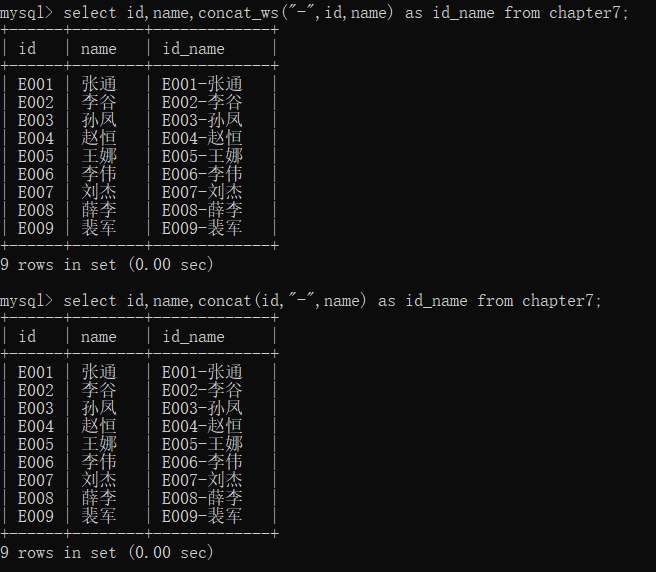
select id,name,concat(id,name) as id_name from chapter7;
有时候,我们想用固定的符号合并不同的字符串或列,这个时候就需要用到另一个函数concat_ws() :
select id,name,concat_ws("-",id,name) as id_name from chapter7;
-- concat()也有同款效果
select id,name,concat(id,"-",name) as id_name from chapter7;
字符串截取
字符串截取就是从一个字符串中截取我们需要的部分字符,主要有左、中、右三种截取方式。
例如,现在有一个字符串2019-10-01 12:30:21,如果我们只想要日期部分,那么可以截取这个字符串的左边部分﹔如果我们只想要时间部分,那么可以截取这个字符串的右边部分;如果我们只想要月份部分,那么就可以截取这个字符串的中间部分。
截取字符串的左边部分使用的是left()函数︰
select left("2019-10-01 12:39:21",10);
上面的代码截取的是字符串左边的10个字符,即2019-10-01。
截取字符串的右边部分使用的是right()函数:
select right("2019-10-01 12:39:21",8);
上面的代码截取的是字符串右边的8个字符,即12:30:21。
截取字符串的中间部分使用的是substring()函数∶
select substring("2019-10-01 12:39:21",6,2);
上面的代码表示从字符串的第6位开始截取,截取长度为2的字符,
即10。
如果要对某一列中的每个字符串进行对应的截取,只需要把上面的日期时间字符串换成对应的列名即可。
字符串匹配
字符串匹配常用在where中,用于筛选满足匹配规则的数据。在SQL中用于字符串匹配的是like , like在英文中除了喜欢的意思,还有长得像的意思。
like有两种匹配符号:%和_。
%用于匹配任意长度的字符,可以是0个,而_用于匹配单个长度的字符。
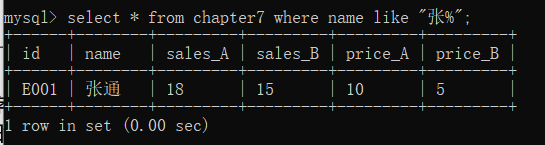
比如,我们要把姓张的同学全部提取出来,假设名字列为name,正常的名字都是先姓后名的,所以想要获取所有姓张的同学,只需要保证第一个字符是张,后面可以是任意长度的字符,具体实现代码如下︰
select * from chapter7 where name like "张%";
再如,我们要把name列中包含凯的名字全部提取出来,只需要保证中间字符是凯,而前面和后面可以是若干个字符,具体实现代码如下:
select * from where name like "%凯%";
又如,我们要获取name列中姓张的,且姓名为两个字的同学,可以通过如下代码实现∶
select * from chapter7 where name like "张_";
上面举的例子都是获取name列中能匹配到的数据,如果我们想要获取匹配不到的数据,只需要把like换成notlike即可。
比如,我们要获取非张姓同学的信息,可以通过如下代码实现︰
select * from chapter7 where name not like "张%";
字符串计数
字符串计数就是统计一个字符串中包含多少个字符。在SQL中,我们使用的是char_length()函数∶
select char_length("sql");
select char_length("我爱学习");
分别运行上面的两行代码,运行第一行代码得到的结果为3,运行第二行代码得到的结果为4。
char_length()函数类似的一个函数是length(),我们来看一下同样的字符串,使用length()函数会得到什么结果∶
select length("sql");
select length("我爱学习");
分别运行上面的两行代码,运行第一行代码得到的结果依旧为3,但是运行第二行代码得到的结果却变成
了12。
我们可以看出,对于“sql”字符串,char_length()和length()函数得到的结果是一样的。而对于“我爱学习”字符串,两个函数得到的结果却是不一样的。这是因为char_length()函数是基于字符计数的,而length()函数是基于字节计数的。
那什么是字符,什么又是字节呢?字符是由字节组成的。英文字母1个字符由1个字节组成;中文1个字符在utf-8编码环境下是由3个字节组成的,在g bk编码环境下是由2个字节组成的。这里是utf-8编码环境,所以使用length()函数对于“我爱学习”字符串进行计数得到的结果为12。
去除字符串空格
有的字符串中会因为各种原因出现空格,但是空格一般不是我们实际想要的数据,空格在一定程度上会导致数据结果出现偏差,比如,空格在字符计数的时候也被算作一个字符。所以我们需要对含有空格的字符串进行去除空格操作,有去除字符串左边的空格、去除字符串右边的空格、去除字符串两边的空格三种方式。具体实现代码如下∶
select
length(" abcdef ") as str_length,
length(ltrim(" abcdef ")) as lstr_length,
length(rtrim(" abcdef ")) as rstr_length,
length(trim(" abcdef ")) as tstr_length;
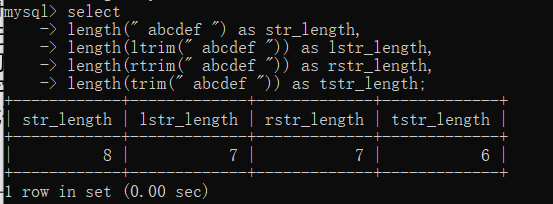
字符串" abcdef”两边各含有1个空格,所以该字符串总长度为8;使用ltrim()函数去掉左边的空格以后字符串长度变为7;使用rtrim()函数去掉右边的空格以后字符串长度也变为7;使trim()函数去掉两边的空格以后,字符串长度变为6。
字符串重复
字符串重复是将同一个字符串重复若干次后合并成一个字符串,在SQL中使用的是repeat()函数。具体实现形式如下∶
select repeat(”sql“,3)
上面的代码表示将字符串Sql重复3次以后合并成一个字符串输出,最后得到的结果为SqlSqlSql.
聚合运算
聚合运算是指将多个值聚合在一起进行某种运算,比如,求和、求平均值等。
count()计数
count(函数是用来对多个非缺失值进行计数的,常用于查看表中某列有多少非空值,比如,我们要查看chapter7表中的id列一共有多少非空值,就可以使用count()函数来实现,具体实现代码如下∶
selct count(id) from chapter7;
运行上面的代码,最后得到的结果为9。
如果我们想要查看chapter7表中一共有多少行,那么只需要把括号中的id换成*即可。读者可能会想,查看表中随便一列有多少行不就知道这张表一共有多少行了吗?多数情况下是可以的,但是如果这一列中有缺失值,那么数据就会变少,因为count()函数是对非缺失值进行计数的。
select count(*) from chapter7;
我们在前面说过,缺失值主要有三种表现形式:null、空格、空值。null和空值是不算入计数的,而空格是算入计数的。
select count(" "); -- 空格算如计数
运行上面的代码,最后得到的结果为1,而运行下面的代码,最后得到的结果为0。
select count(null); -- 空值,null不算计数
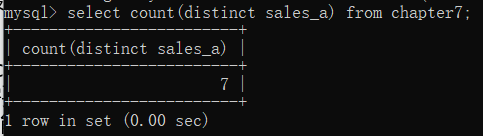
有时候,表中某些列的值可能会重复,如果我们想得到删除重复值后的计数,则可以和前面学过的重复值处理相结合,即count()函数和distinct相结合。比如,我们想查看chapter7表中产品a一共有几种销量水平,即
对sales_a列删除重复值后的计数,具体实现代码如下︰
-- 去除重复值计数
selct count(distinct sales_a) from chapter7;
sum()求和
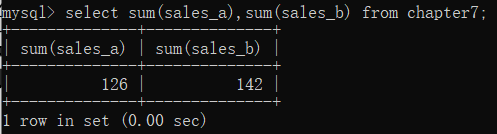
sum()函数主要用于对表中某列的所有值进行求和汇总,比如,我们要分别获取chapter7表中产品a和产品b的总销量,就可以使用sum()函数,具体实现代码如下∶
select sum(sales_a),sum(sales_b) from chapter7;
avg()求平均值
avg()函数主要用于对表中某列的所有值进行求平均值运算,比如,我们要分别获取chapter7表中产品a和产品b的平均销量,就可以使用avg()函数,具体实现代码如下︰
select avg(sales_a),avg(sales_b) from chapter7;
max()求最大值
max()函数主要用于获取表中某列的最大值,比如,我们要分别获
取chapter7表中产品a和产品b的最高销量,就可以使用max()函数,具体实现代码如下︰
select max(sales_a),max(sales_b) from chapter7;
min()求最小值
min()函数与max()函数相对应,用于获取表中某列的最小值,比如,我们要分别获取chapter7表中产品a和产品b的最低销量,就可以使用min()函数,具体实现代码如下∶
select min(sales_a),min(sales_b) from chapter7;
求方差
方差用于反映一组数据的离散程度,即波动程度,方差越大,说明数据波动越厉害,方差的计算公式如下∶

在实际工作中,一组数据的总体是比较难获得的,也就是说,我们看到的数据只是总体数据中的一部分,这个时候的数值个数就是N-1,而不是N。如果分母是N,则表示总体方差﹔如果分母是N-1,则表示样本方差。
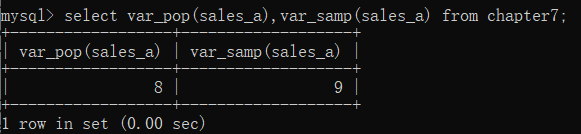
在SQL中,求总体方差,使用的是var_pop()函数﹔求样本方差,使用的是var_samp()函数。具体实现代码如下∶
select var_pop(sales_a),var_samp(sales_a) from chapter7;
求标准差
标准差是方差的开方,也是用于反映数据的离散程度的,读者可能会想,不是已经用方差来反映数据的离散程度了吗,为什么还要用标准差呢?那是因为方差虽然可以反映数据的离散程度,但是不具有实际业务意义。因为标准差与实际数据的单位是一致的,比如,中学生身高的标准差的单位是厘米,而方差是厘米的平方就比较难理解。因为标准差是方差的开方,方差有总体方差和样本方差,所以标准差也有总体标准差和样本标准差。
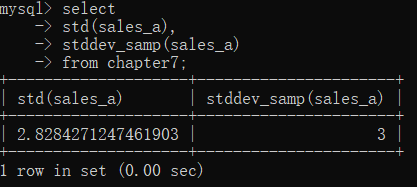
在SQL中,求总体标准差,使用的是std()函数;求样本标准差,使用的是stddev_samp()函数。具体实现代码如下:
select
std(sales_a),
stddev_samp(sales_a)
from chapter7;
聚合函数之间的运算
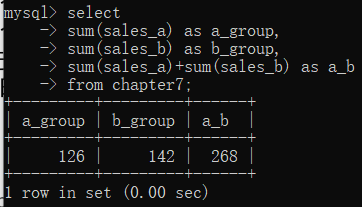
上面讲的聚合函数都是针对某一列进行聚合的,我们平常还有有针对多列进行聚合的需求,比如,我们要获取产品a和产品b的总销量,就需要先对sales_a列进行求和聚合运算,然后对sales_b列进行求和聚合运算,最后把聚合运算后的两个值进行求和聚合运算,就是产品a和产品b的总销量。
select
sum(sales_a) as a_group,
sum(sales_b) as b_group,
sum(sales_a)+sum(sales_b) as a_b
from chapter7;
需要注意的是,我们在对聚合运算后的sales_ a列和sales_ b列进行求和聚合运算时,使用的是sum(sales_ a) +sum(sales b) ,而非a_ group + b_group ,这是因为a_ group和b_ group是聚合运算后结果的别名,而非表中实际存在的列名,如果直接对二者进行求和聚合运算,程序则会报错,提示列名不存在。
小结
算术运算
+ - * / div mod %
SQL可以直接在select中对两列进行结果的计算(运算结果为一个新列)
null和任何数运算,结果都是null
select
id,
(sales_a + sales_b) as all_sales,
(sales_a - sales_b) as sales_a_b,
(sales_a * price_a + sales_b * price_b) as gmv,
(price_a / price_b) as price_a_b,
(sales_a * 2) as 2_sales_a
from chapter7;
比较运算
> < >= <= != <> = between is not null is null
列与列之间的比较
select
id,sales_a,sales_b,
sales_a>sales_b as "大于",
sales_a<sales_b as "小于",
sales_a=sales_b as "等于",
sales_a!=sales_b as "不等于",
sales_a is null as "空值",
sales_a is not null as "非空值"
from chapter7;
where中进行比较
select id,sales_a from chapter7
where sales_a between 15 and 20;
select id,sales_a from chapter7
where sales_a > 15;
逻辑运算
and or not
select id,sales_a,sales_b,
((sales_a>15)and(sales_b>15)) as "双优",
((sales_a>15)or(sales_b>15)) as "单优"
from chapter7;
数学运算
求绝对值 abs()
select id,sales_a,sales_b,
(sales_a-sales_b) as "差值",
abs(sales_a-sales_b) as "绝对差值"
from chapter7;
求最小整数值 ceil()
select ceil(2.9);
求最大整数值 floor()
select floor(2.1);
随机数生成 rand() 生成0~1之间的浮点随机数
select rand();
小数点位数调整 round(浮点数,位数)
select rountd(1.1111,2)
select id,rand() as "随机数" from chapter7;
select id,rand() as "随机数" from chapter7 order by rand() limit 3; # 实现随机选3个id
正负判断
sign()
select id,sales_a,sales_b,
(sales_a-sales_b) as sales_a_b,
sign(sales_a-sales_b) as "正负"
from chapter7;
字符串运算
字符串替换 replace()
select repalce("AaAaAa","A","a")
select id,replace(id,"E","e") as repalce_id from chapter7;
字符串合并 concat() 可以连接多个
select concat("Hello ","World!");
select id,name,concat(id,"-",name) as id_name from chapter7;
字符串截取
left() right() substring()
select left("2019-10-01 12:39:21",10);
select right("2019-10-01 12:39:21",8);
select substring("2019-10-01 12:39:21",6,2);
字符串匹配
like not like
% _
select * from where name like "%凯%";
select * from chapter7 where name not like "张%";
字符串计数
char_length() 基于字符计数
length() 基于字节计数
去除字符串空格
ltrim() rtrim() trim()
字符串重复
select repeat(”sql“,3)
聚合运算
count()
selct count(distinct sales_a) from chapter7;
sum()
select sum(sales_a),sum(sales_b) from chapter7;
avg()
max()
min()
方差 var_pop() var_samp()
select var_pop(sales_a),var_samp(sales_a) from chapter7;
标准差 std() stddev_samp()
select
std(sales_a),
stddev_samp(sales_a)
from chapter7;
聚合函数之间的运算
select
sum(sales_a) as a_group,
sum(sales_b) as b_group,
sum(sales_a)+sum(sales_b) as a_b
from chapter7;

 浙公网安备 33010602011771号
浙公网安备 33010602011771号