Excel & SQL | 数据预处理 | 02

上表存储了order_id(订单ID)date (下单日期).value(订单金额)、memberid(会员ID)、age (会员的年龄)、sex(会员的性别)和profession(所在行业信息)七个字段。我们把上表中的数据存储在demo数据库的chapter6表中。
缺失值处理
我们在数据库中存储的数据一般都会由于各种原因存在缺失值,我们需要对这部分数据进行处理。
一般处理方式有两种:
- 缺失值过滤
- 缺失值填充
缺失值过滤
在SQL中,可以通过where进行过滤。
select * from chapter6 where profession!="";
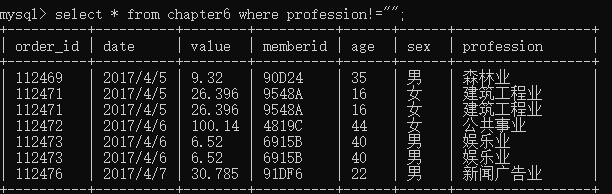
!=表示不等于,""表示空值,缺失值有空格、null和空值三种表现形式,
前两种形式虽然也表示缺失值,但是在对应单元格内是有值的,而后一种空值是没有值的,表示这个单元格什么都没有。
如果缺失值是用空格表示的要过滤缺失值, where后面就需要改成profession != " ";如果缺失值是用null表示的,要过滤掉缺失值, where后面就需要改成profession is not null。
缺失值填充
上面的处理方式把profession列是缺失值的行都过滤掉了,所以这种处理方式会把其他非缺失值的字段过滤掉,而造成数据的浪费。我们可以将profession列中的缺失值填充为其他,而不是直接过滤掉,这就是针对缺失值的第二种处理方式,使用的是coalesce()函数,具体实现代码如下:
select order_id,memberid,coalesce(profession,"其他") from chapter6;

重复值处理
我们在数据库中存储的数据有时候也会存在一些重复值,重复值会影响分析结果,所以我们也需要对这部分数据进行处理。
对重复值的处理,我们一般采取的方式是删除重复值,即只保留重复数据中的一项,其他数据则被删除。
在SQL中,我们可以使用distinct对查询出来的全部结果进行删除重复值的操作,需要注意的是,这里不是针对全表进行删除重复值的操作,而是针对查询出来的全部结果,也就是select distinct后面的具体列进行删除重复值的操作。如果是select distinct * ,则就是针对全表进行删除重复值的操作了。
select distinct * from chapter6;

有时候,我们不需要对全表进行删除重复值的操作,这个时候就可以根据具体需要选择指定列进行删除重复值的操作,比如,我们对chapter6表中的order_id列和memberid列进行删除重复值的操作,具体实现代码如下︰
select distinct order_id,memberid from chapter6;

对重复值进行处理,我们除了可以使用distinct,还可以使用group by。
对想要删除重复值的列进行group by就可以得到删除重复值后的结果。
select order_id,memberid from chapter6 group by order_id,memberid;

运行上面代码,
数据类型转换
一般我们会根据不同的需求,以及不同的场景对数据类型进行转换,转换成我们想要的数据类型。
在SQL中,我们想要更改某一列的数据类型,可以使用cast()和convert()函数。
cast(value as type)
convert(value,type)
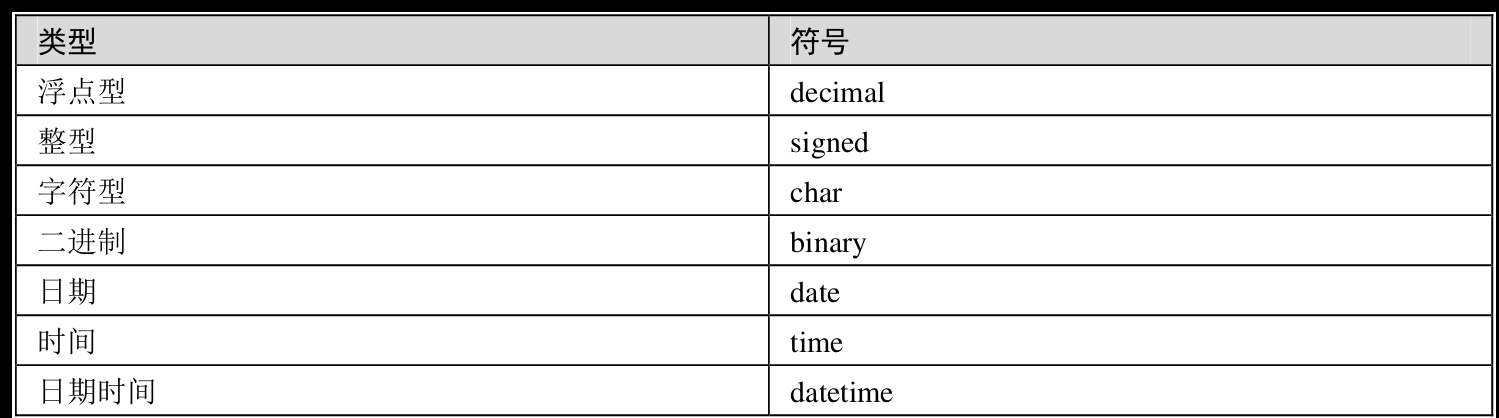
上面两个函数中的type表示某列更改为目标数据后的类型。目标数据类型包括如下表所示几种。
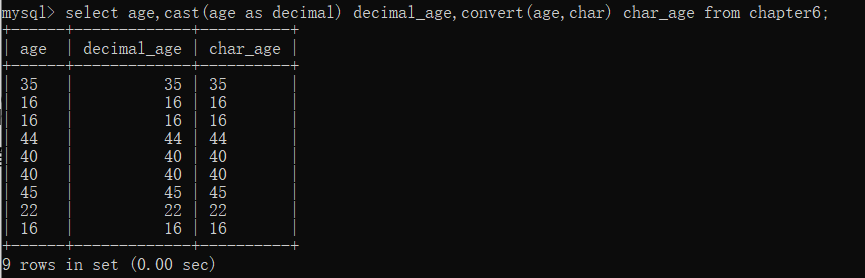
我们将chapter6表中的age列从整型分别转化为浮点型(decimal)和字符型(char)。
select age,cast(age as decimal) decimal_age,convert(age,char) char_age from chapter6;
重命名
—般,公司数据库中存储的表的字段名都是英文形式的,为了让数据更加清晰,我们一般会将英文字段名重命名为中文字段名﹔;或者一个字段并不是表中现有的数据,而是通过表中现有的数据计算生成的,这个时候我们也需要对字段名进行重命名。
在SQL中,可以通过as来实现。as前面为原始字段名,as后面为别名。
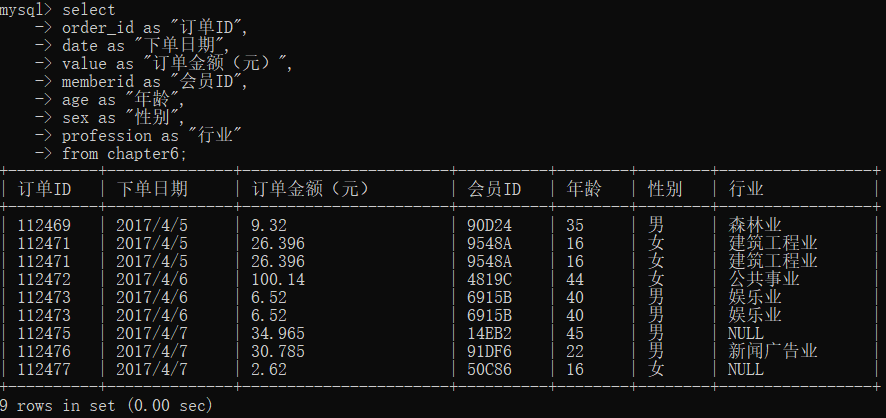
我们将chapter6表中所有英文字段名全部重新命名为中文字段名,具体实现代码如下:
select
order_id as "订单ID",
date as "下单日期",
value as "订单金额(元)",
memberid as "会员ID",
age as "年龄",
sex as "性别",
profession as "行业"
from chapter6;
当然,上面代码中的as是可以省略的,直接以”原始字段名 新字段名“的形式也是可以的,但是为了让代码更加可读,建议不要省略。
小结
缺失值处理
缺失值过滤 where
缺失值可能是 空格 空字符 null
where xx!=""
where xx!=" "
where xx is not null
缺失值填充 coalesce(属性,填充值)
select order_id,memberid,coalesce(profession,"其他") from chapter6;
重复值处理
distinct 对后面查询的列都进行去重
select distinct order_id,memberid from chapter6;
group by 要去重哪个列就对哪个列 group by
select order_id,memberid from chapter6 group by order_id,memberid;
数据类型转换
cast(value as type)
convert(value,type)
select age,cast(age as decimal) decimal_age,convert(age,char) char_age from chapter6;
重命名
as(可以省略 原字段名 新字段名)
select
order_id as "订单ID",
date as "下单日期",
value as "订单金额(元)",
memberid as "会员ID",
age as "年龄",
sex as "性别",
profession as "行业"
from chapter6;

 浙公网安备 33010602011771号
浙公网安备 33010602011771号