python--序列,字符串,列表,元组,字典,集合内存分析
一,什么是序列、
序列是一种数据存储方式,用来存储一系列的数据,在内存(堆内存)中,序列是一块用来存放多个值的连续的内存空间,其存储的值为所指向对象的地址。比如说a = [ 10 , 20 , 30 , 40 ]在内存中实际是按照以下方式存储的。下图中序列存储的是整数对象的地址,而不是整数对象的值。python中常用的序列结构有:字符串,列表,元组,字典,集合
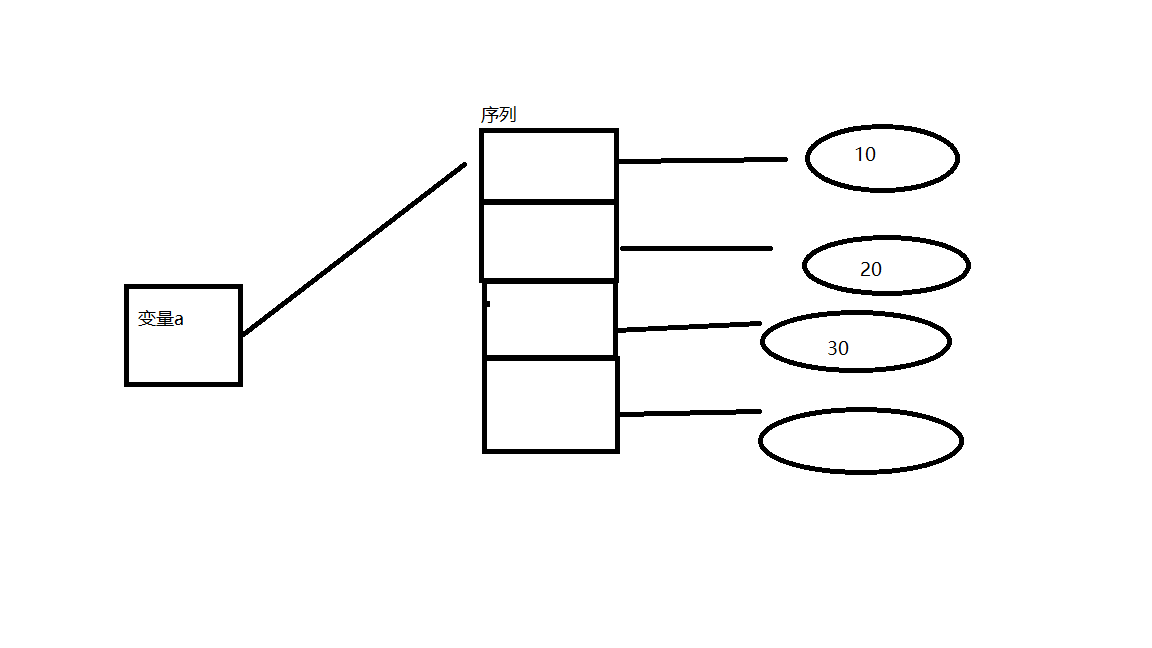
列表:
一,什么是列表?
是一种用来存储任意数目,任意类型的数据集合。
二,列表的底层原理是什么?
参照上图
三,列表的三种创建方式
1.基本语法 [ ] 创建
a = [ 1, 2 , "abc" ]
a = [ ]
2,list()创建:使用list()可以将任何可迭代对象转化为列表
a = list( )
a = list(range(10))
注意:range的语法格式: range([start],end,[step])
start:可选,表示起始数字,默认是0
end:必选,表示结尾数字
step:可选,表示步长,默认是1,可正可负
python3中range()返回的是一个range对象,而不是列表,我们需要通过list()方法将其转换为列表对象
3.推导式生成列表
a = [ x*2 for x in range( 5 ) if x%3==0 ]
第一步:range(5)为,[ 0,1,2,3,4 ]
第二步:每个x分别乘2。[ 0,2,4,6,8 ]
第三步:判断是否为3的倍数。[ 6 ]
四,对列表的操作(添加元素,删除元素,访问元素,切片,排序)
添加元素(5种)
当列表增加和删除元素时,列表会自动进行内存管理,大大减少程序员的负担。但这个特点涉及列表元素的大量移动,效率较低。(当在中间插入或删除元素时,实质上是对数组的拷贝,故而效率较低)除非必要,我们一般只在列表的尾部添加元素或者删除元素,这会大大提高列表的操作效率。
1. append():原地修改列表对象,是真正的在列表尾部添加新的元素,速度最快,推荐使用。
2. +运算符操作:并不是真正的尾部添加元素,而是创建新的列表对象;将原列表的元素和新列表的元素依次复制到新的列表对象中。这样会涉及大量的复制操作,对于操作大量元素不建议使用
3.extend():将目标列表的所有元素添加到本列表的尾部,属于原地操作,不创建新的列表对象
删除元素(3种,其内存原理参照上文insert()方法)
1.del删除:删除列表指定位置的元素()
访问元素(5种)
1.通过索引直接访问元素:可以通过索引直接访问元素,索引的区间在 [ 0 , 列表长度-1]这个范围。超过这个范围会抛出异常。
2.index():可以获取指定元素首次出现的索引位置并返回。语法:index(value , [ start , [ end] ] )。其中,start和end指定了搜索范围.
切片
切片适用于列表,元组,字符串等等(之前讲的烂大街了,不讲了)
注意一点:切片操作时,起始偏移量和终止偏移量不在[0 , 字符串长度-1]这个范围,也不会报错。起始偏移量小于0则会被当作0,终止偏移量大于“长度-1”会被当作-1
排序
sort():修改原列表,不建新列表。默认升序排列,降序reverse=true
sorted():不修改原列表,构建新列表
reverse():修改原列表,反向列表中元素
reversed():不对原列表做任何修改,只是返回一个逆序排列的迭代器对象。需要用list()方法进行处理,也可以用迭代器__next__方法逐个迭代
其他内置函数:
max(a),min(a),sum(a)
列表的拷贝
浅拷贝和深拷贝
元组
列表属于可变序列,可以任意修改列表中的元素。元组属于不可变序列,不能修改元组中的元素。因此,元组没有增加元素,修改元素,删除元素相关的方法。
元组支持如下操作:1.索引访问,2.切片操作,3.连接操作,4.成员关系操作,5.比较运算操作,6.计数:len(),max(),min(),sum()
元组的创建
1.通过()创建元组,小括号可以省略。如果元组只有一个元素,则必须后面加上逗号。这是因为解释器会把(1)解释为整数1,(1,)解释为元组
可以通过生成器对象,转化成列表或者元组。也可以使用生成器对象的__next__()方法进行遍历,或者直接作为迭代器对象进行使用。不管用什么方式使用,元素访问结束后,如果需要重新访问其中的元素,必须重新创建该生成器对象。
元组的访问
元组的元素访问和列表一样,只不过返回的对象仍然是元组
元组的排序
列表关于排序的方法list.sorted()是修改列表对象,元组没有该方法。如果需要对元组进行排序,只能使用内置函数sorted(tupleObj),并生成新的列表对象
元组的总结
1.元组的核心特点是:不可变序列。
2.元组的访问和处理速度比列表快
3.与整数和字符串一样,元组可以作为字典的键,列表则永远不能作为字典的键使用。
字典
字典的创建
1.通过{},dict()来创建字典对象
2.通过zip()创建
3.通过fromkeys创建值为空的字典
字典元素的访问
1,通过[ 键 ]获得“值”。若值不存在,则抛出异常
2,通过get(键)方法获得“值”。推荐使用:优点:指定键不存在,则返回none;也可以设置键不存在时默认返回的对象
3,列出所有的键值对:a.items()
4,列出所有的键:a.keys()
5,列出所有的值:a.values()
6,len():输出键值对的个数
7,检测一个“键”是否在字典中:“键” in a
字典元素的添加,修改,删除
1,给字典新增“键值对”。如果“键”已经存在,则覆盖旧的键值对;如果‘’键“不存在,则新增”键值对“。
4,popitem():随即删除和返回该键值对。字典是”无需可变序列“,因此没有第一个元素,最后一个元素的概念(可以类比想想集合);popitem()弹出随机的项,因为字典并没有”最后的元素“或者其他有关顺序的概。若想一个接一个地移除并处理项,这个方法就非常有效
字典核心底层原理
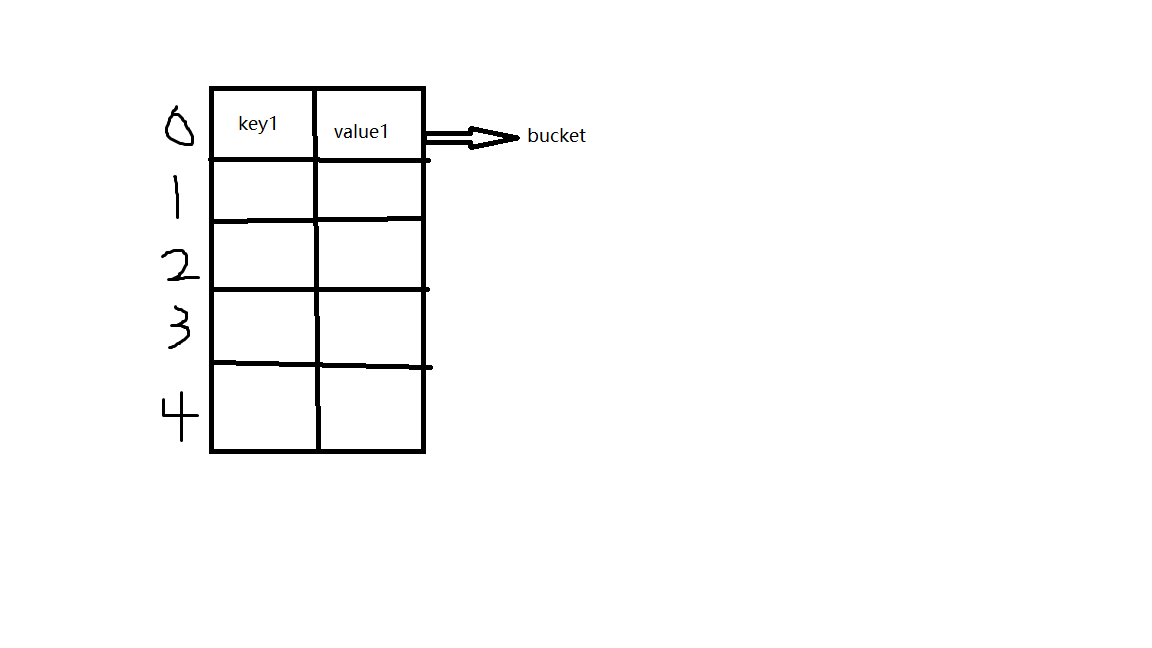
字典对象地核心是散列表。散列表里是一个稀疏数组(总是有空白元素的数组),数组的每个单元叫做bucket。每个bucket由两部分:一个是键对象的引用,一个是值对象的引用。由于所有的bucket结构和大小一致,所以可以通过偏移量来读取指定bucket。
将一个键值对放进字典的底层过程
假设字典对象a创建完成后,数组长度为8:
我们如果要把“name” = “wbh”这个键值对放到对应的字典对象a中,首先第一步需要计算“name”的散列值。python中可以通过hash()来计算。由于数组长度为8,我们可以拿计算出的散列值的最右边3位数字作为偏移量,查看偏移量对应的bucket是否为空。如果为空,则将键值对放进去。如果不为空,则依次取右边3位作为偏移量。当数组被填满至一定程度时,会自动进行扩容。
根据键查找“键值对”的底层过程
当我们调用a.get('name'),时。程序第一步会先计算“name”对象的散列值。和存储的底层流程算法一致,也是依次取散列值的不同位置的数字。假设数组长度为8,我们可以拿计算出的散列值的最右边3位数字作为偏移量。查看偏移量对应的bucket是否为空。如果为空,则返回None。如果不为空,则将这个bucket的键对象计算散列值,和我们的散列值进行比较,如果相等,则将对应的“值对象”返回。如果不相等,则再依次取其他几位数字,重新计算偏移量。依次取完后仍然没有找到,则返回None
集合
集合的创建和删除
集合相关操作

