
第一次个人编程作业
第一次个人编程作业
写在最初
最终赶在deadline之前完成了,给自己鼓个掌~
在这里要感谢@breezerf 哥哥,不厌其烦地教我(不然我可能都做不出来。在这里要郑重向你道个歉,对不起,浪费你很多时间,下次还敢
第一眼看到题目时候,发现竟无从下手,经过一天查阅资料后才发现应该是NLP文本相似度问题,一开始打算用c++完成,研究两天后未果,是我太naive了。听取breezerf哥哥的意见后,选用python。
随后连肝两天,初步掌握python的用法,就直接上手了。很无奈,这知识不进脑子啊(头秃
PATR 1 GitHub
GitHub 仓库链接🔗:GitHub
PART 2 计算模块接口的设计与实现过程
算法流程
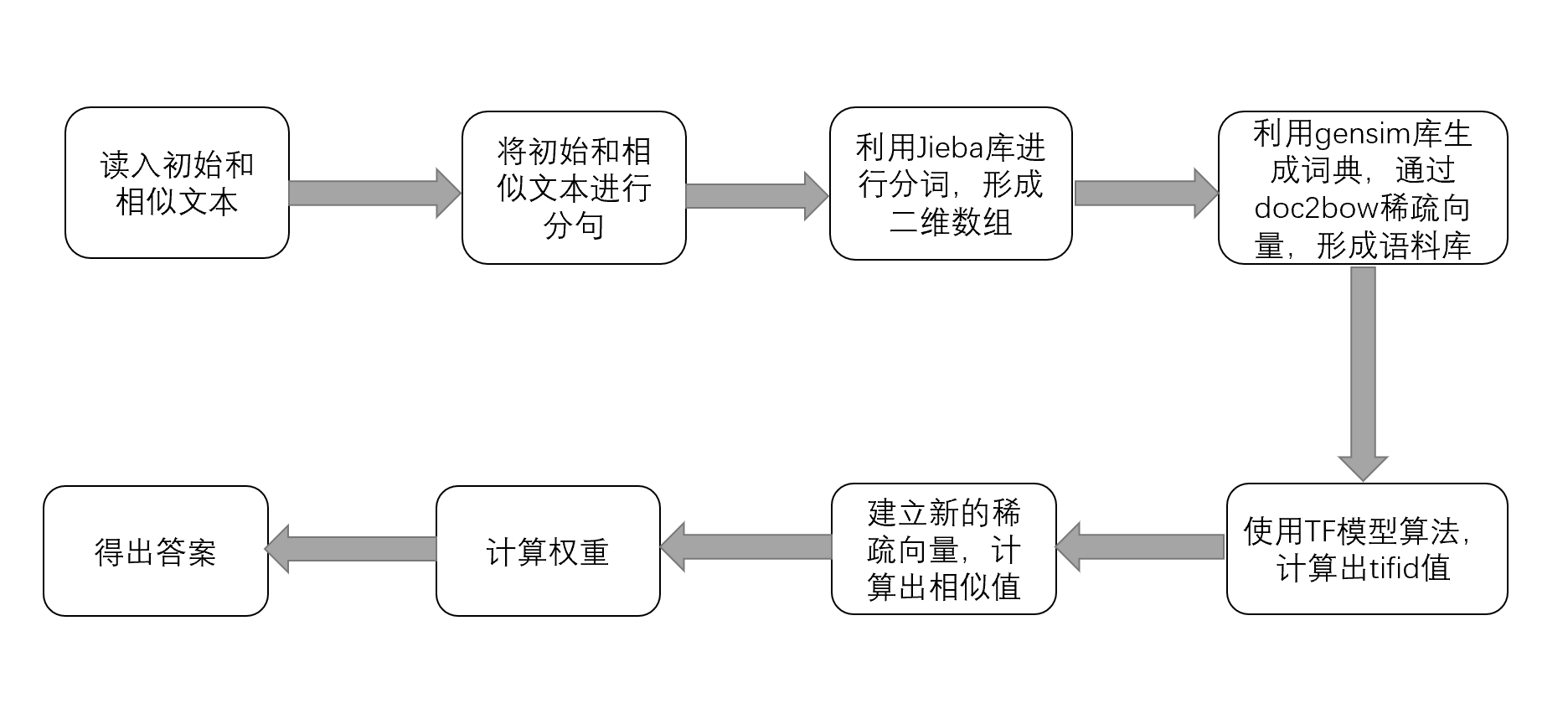
主要思想:利用gensim建立语料库和TF-IDF模型计算出相似值
TF-IDF 模型:TF-IDF是一种统计方法,用以评估一字词对于一个文件集或一个语料库中的其中一份文件的重要程度。字词的重要性随着它在文件中出现的次数成正比增加,但同时会随着它在语料库中出现的频率成反比下降。
词频(TF):表示词条(关键字)在文本中出现的频率。
TF=在某一类中词出现的次数/该类中所有词条数目
逆向文件频率 (IDF) :某一特定词语的IDF,可以由总文件数目除以包含该词语的文件的数目,再将得到的商取对数得到。
IDF=log[语料库的文档总数/(包含词条的文档数+1)]
TF - IDF = 词频(TF)*逆向文件频率(IDF)
主要参考文献:
算法思想
1.读入文件
根据题目要求,分别从命令行参数给出论文原文的文件的绝对路径以及抄袭版论文的文件的绝对路径,调用函数read_txt(),read_add_txt()分别读入初始文件和相似文件
# 读入初始文件
def Read_txt(command):
file = open(command, 'r', encoding='UTF-8')
origin_file = file.read()
file.close()
origin = Split_sentence(origin_file) # 初始文件分句
return origin
# 读入相似文件
def Read_add_txt(command):
file = open(command, 'r', encoding='UTF-8')
origin_add_file = file.read()
file.close()
origin_add = Split_sentence(origin_add_file) # 相似文件分句
return origin_add
# sys.argv[1] 论文原文的文件的绝对路径
# sys.argv[2] 抄袭版论文的文件的绝对路径
# sys.argv[3] 输出的答案文件的绝对路径
# 读入初始文件
command = sys.argv[1]
origin_txt = Read_txt(command)
# 读入相似文件
command = sys.argv[2]
origin_add_txt = Read_add_txt(command)
2.数据字符处理模块
根据utf-8的字符编码方式,中文字符的范围在“\u4e00-\u9fa5"之间,调用函数Split_sentence(),根据范围过滤出中文字符,然后以中文逗号为分隔符,将文章分成一句句话
# 将文章进行拆分成句子
def Split_sentence(file_txt):
head = '\u4e00'
tail = '\u9fa5'
word = ""
sentence_list = [] # 保存拆分的句子
for each in range(len(file_txt)):
if head <= file_txt[each] <= tail: # 中文编码范围
word += file_txt[each]
elif file_txt[each] == ",": # 以逗号分句
sentence_list.append(word)
word = ""
else:
continue
if word != '':
sentence_list.append(word)
word = ''
return sentence_list
3.文本分词处理
利用Jieba库将拆分完的句子近一步拆分成词组,形成一个二维数组
# 利用jieba.luct进行分词 保存在list列表中
ori_list = [[word for word in jieba.lcut(sentence)] for sentence in origin_txt]
ori_add_list = [[word for word in jieba.lcut(sentence)] for sentence in origin_add_txt]
4.计算相似度
采用基于gensim库的TF-IDF算法来实现余弦相似度,通过Similiarity()函数计算出每句话的相似度,根据权重求出整篇文章相似度
def Similiarity():
# 生成词典
dictionary = corpora.Dictionary(ori_list)
# 通过doc2bow稀疏向量生成语料库
corpus = [dictionary.doc2bow(word) for word in ori_list]
# 通过TF模型算法,计算出tf值
tf = models.TfidfModel(corpus)
# 通过token2id得到特征数(字典里面的键的个数)
num_features = len(dictionary.token2id.keys())
# 计算稀疏矩阵相似度,建立索引
index = similarities.MatrixSimilarity(tf[corpus], num_features=num_features)
# 每句长度-单个变量
word_size = 0
size = 0
sim = 0
for word in range(len(ori_add_list)):
# 新的稀疏向量
new_vector = dictionary.doc2bow(ori_add_list[word])
# 算出相似度
sim_list = index[tf[new_vector]]
# 选出最大相似度
sim = max(sim_list)
# 加入相似度列表
sim_value.append(sim)
# 相似文章每句长度值
word_size = len(ori_add_list[word])
# 文章总长度值
size += word_size
# 加入长度列表
word_lenth.append(word_size)
return size
total_size = Similiarity()
total_sum = 0
for i in range(len(word_lenth)):
total_sum += word_lenth[i] * sim_value[i]
# 加权求平均
ans = total_sum / total_size
# 保留后两位
ans = (str("%.2f") % ans)
5.输出文件
根据题目要求,从命令行参数给出输出的答案文件的绝对路径
# 写入文件
file = open(sys.argv[3], 'w', encoding='UTF-8')
file.write(ans)
file.close()
PART 3 计算模块接口部分的性能改进
1.性能分析
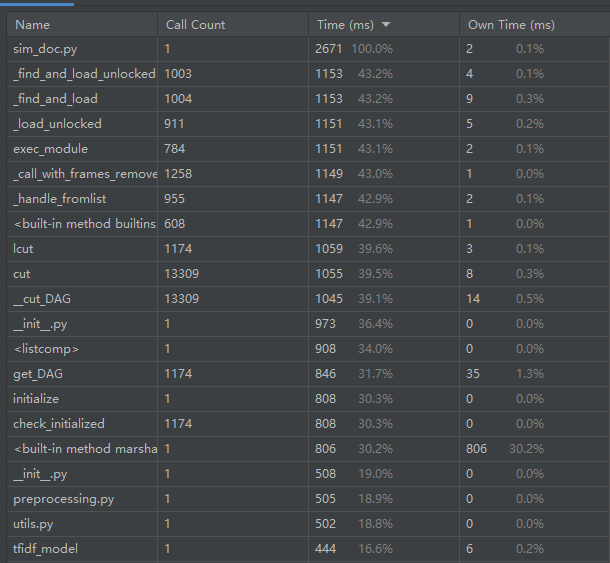
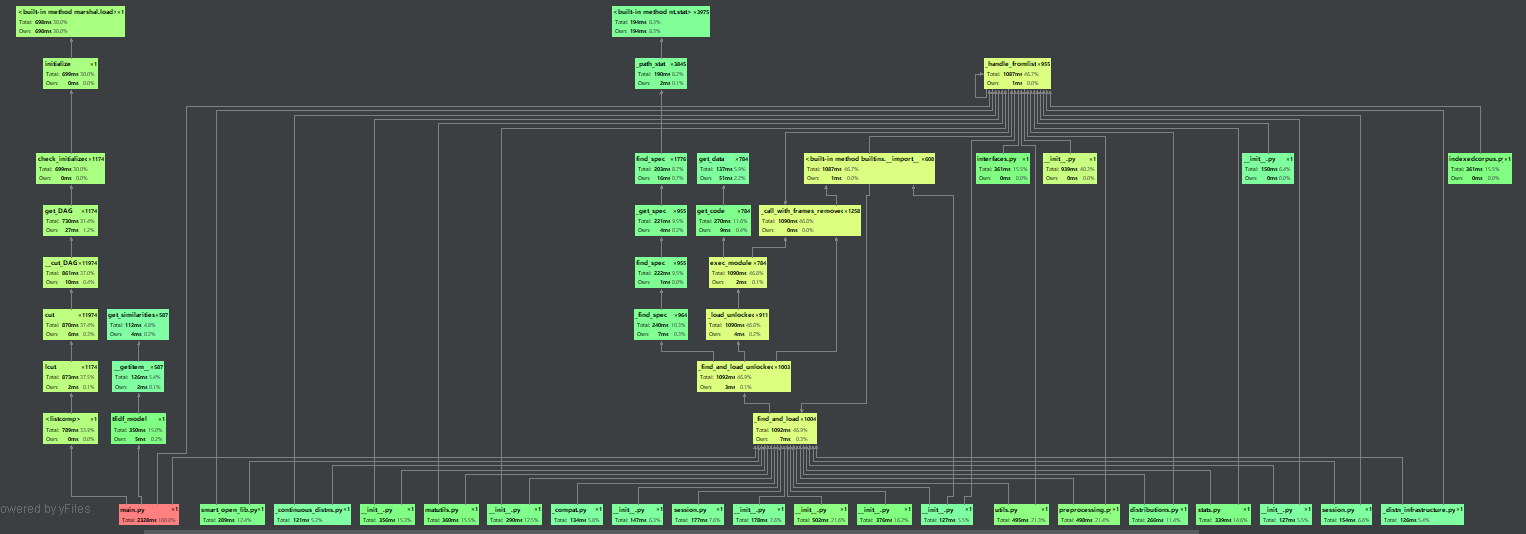
主程序运行时间感觉挺慢的TAT
2.单元测试:
调用python自带的uittest库函数,先调用calculation中的Split_sentence()函数将读取的文件分句,再通过分别调用Calculation_Similiarity()函数计算出每个测试文档的相似度
测试代码
import unittest
import calculation
class NewTest(unittest.TestCase):
def test_txt_add(self):
print("orig_0.8_add.txt的相似度 ")
file = open("D:\\sim_0.8\\orig.txt", "r", encoding='UTF-8')
orig_text = file.read()
file.close()
origin = calculation.Split_sentence(orig_text)
file = open("D:\\sim_0.8\\orig_0.8_add.txt", "r", encoding='UTF-8')
orig_add_text = file.read()
file.close()
origin_add = calculation.Split_sentence(orig_add_text)
sim = calculation.Calculation_Similiarity(origin, origin_add)
sim = str("%.2f") % sim
print(sim)
def test_txt_del(self):
print("orig_0.8_del.txt的相似度 ")
file = open("D:\\sim_0.8\\orig.txt", "r", encoding='UTF-8')
orig_text = file.read()
file.close()
origin = calculation.Split_sentence(orig_text)
file = open("D:\\sim_0.8\\orig_0.8_del.txt", "r", encoding='UTF-8')
orig_add_text = file.read()
file.close()
origin_add = calculation.Split_sentence(orig_add_text)
sim = calculation.Calculation_Similiarity(origin, origin_add)
sim = str("%.2f") % sim
print(sim)
def test_txt_dis_1(self):
print("orig_0.8_dis_1.txt的相似度 ")
file = open("D:\\sim_0.8\\orig.txt", "r", encoding='UTF-8')
orig_text = file.read()
file.close()
origin = calculation.Split_sentence(orig_text)
file = open("D:\\sim_0.8\\orig_0.8_dis_1.txt", "r", encoding='UTF-8')
orig_add_text = file.read()
file.close()
origin_add = calculation.Split_sentence(orig_add_text)
sim = calculation.Calculation_Similiarity(origin, origin_add)
sim = str("%.2f") % sim
print(sim)
def test_txt_dis_3(self):
print("orig_0.8_dis_3.txt的相似度 ")
file = open("D:\\sim_0.8\\orig.txt", "r", encoding='UTF-8')
orig_text = file.read()
file.close()
origin = calculation.Split_sentence(orig_text)
file = open("D:\\sim_0.8\\orig_0.8_dis_3.txt", "r", encoding='UTF-8')
orig_add_text = file.read()
file.close()
origin_add = calculation.Split_sentence(orig_add_text)
sim = calculation.Calculation_Similiarity(origin, origin_add)
sim = str("%.2f") % sim
print(sim)
def test_txt_dis_7(self):
print("orig_0.8_dis_7.txt的相似度 ")
file = open("D:\\sim_0.8\\orig.txt", "r", encoding='UTF-8')
orig_text = file.read()
file.close()
origin = calculation.Split_sentence(orig_text)
file = open("D:\\sim_0.8\\orig_0.8_dis_7.txt", "r", encoding='UTF-8')
orig_add_text = file.read()
file.close()
origin_add = calculation.Split_sentence(orig_add_text)
sim = calculation.Calculation_Similiarity(origin, origin_add)
sim = str("%.2f") % sim
print(sim)
def test_txt_dis_10(self):
print("orig_0.8_dis_10.txt的相似度 ")
file = open("D:\\sim_0.8\\orig.txt", "r", encoding='UTF-8')
orig_text = file.read()
file.close()
origin = calculation.Split_sentence(orig_text)
file = open("D:\\sim_0.8\\orig_0.8_dis_10.txt", "r", encoding='UTF-8')
orig_add_text = file.read()
file.close()
origin_add = calculation.Split_sentence(orig_add_text)
sim = calculation.Calculation_Similiarity(origin, origin_add)
sim = str("%.2f") % sim
print(sim)
def test_txt_dis_15(self):
print("orig_0.8_dis_15.txt的相似度 ")
file = open("D:\\sim_0.8\\orig.txt", "r", encoding='UTF-8')
orig_text = file.read()
file.close()
origin = calculation.Split_sentence(orig_text)
file = open("D:\\sim_0.8\\orig_0.8_dis_15.txt", "r", encoding='UTF-8')
orig_add_text = file.read()
file.close()
origin_add = calculation.Split_sentence(orig_add_text)
sim = calculation.Calculation_Similiarity(origin, origin_add)
sim = str("%.2f") % sim
print(sim)
def test_txt_mix(self):
print("orig_0.8_mix.txt的相似度 ")
file = open("D:\\sim_0.8\\orig.txt", "r", encoding='UTF-8')
orig_text = file.read()
file.close()
origin = calculation.Split_sentence(orig_text)
file = open("D:\\sim_0.8\\orig_0.8_mix.txt", "r", encoding='UTF-8')
orig_add_text = file.read()
file.close()
origin_add = calculation.Split_sentence(orig_add_text)
sim = calculation.Calculation_Similiarity(origin, origin_add)
sim = str("%.2f") % sim
print(sim)
def test_txt_rep(self):
print("orig_0.8_rep.txt的相似度 ")
file = open("D:\\sim_0.8\\orig.txt", "r", encoding='UTF-8')
orig_text = file.read()
file.close()
origin = calculation.Split_sentence(orig_text)
file = open("D:\\sim_0.8\\orig_0.8_rep.txt", "r", encoding='UTF-8')
orig_add_text = file.read()
file.close()
origin_add = calculation.Split_sentence(orig_add_text)
sim = calculation.Calculation_Similiarity(origin, origin_add)
sim = str("%.2f") % sim
print(sim)
def test_txt_ori(self):
print("orig.txt的相似度 ")
file = open("D:\\sim_0.8\\orig.txt", "r", encoding='UTF-8')
orig_text = file.read()
file.close()
origin = calculation.Split_sentence(orig_text)
file = open("D:\\sim_0.8\\orig.txt", "r", encoding='UTF-8')
orig_add_text = file.read()
file.close()
origin_add = calculation.Split_sentence(orig_add_text)
sim = calculation.Calculation_Similiarity(origin, origin_add)
sim = str("%.2f") % sim
print(sim)
if __name__ == '__main__':
unittest.main()
单元测试结果
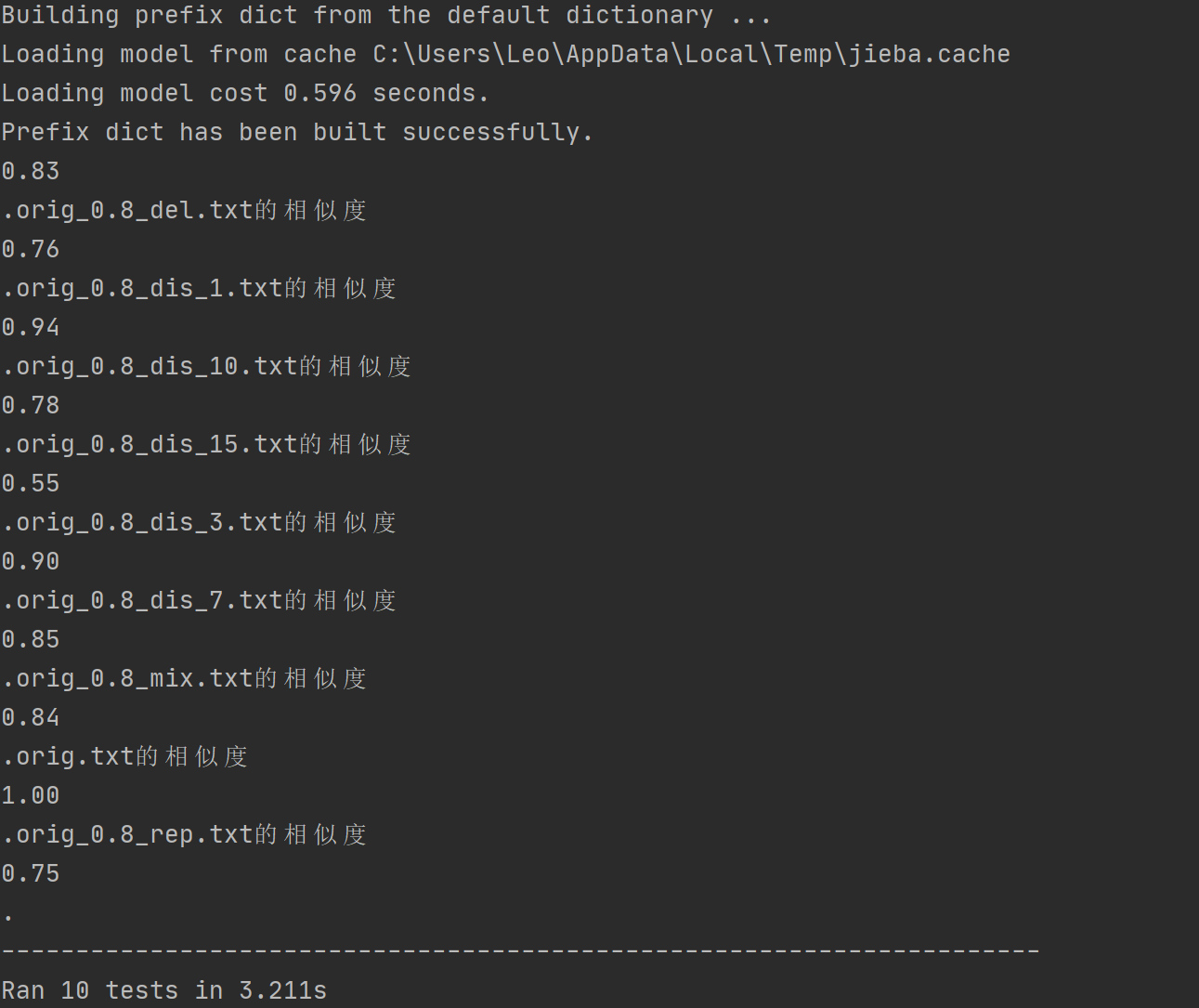
覆盖率测试
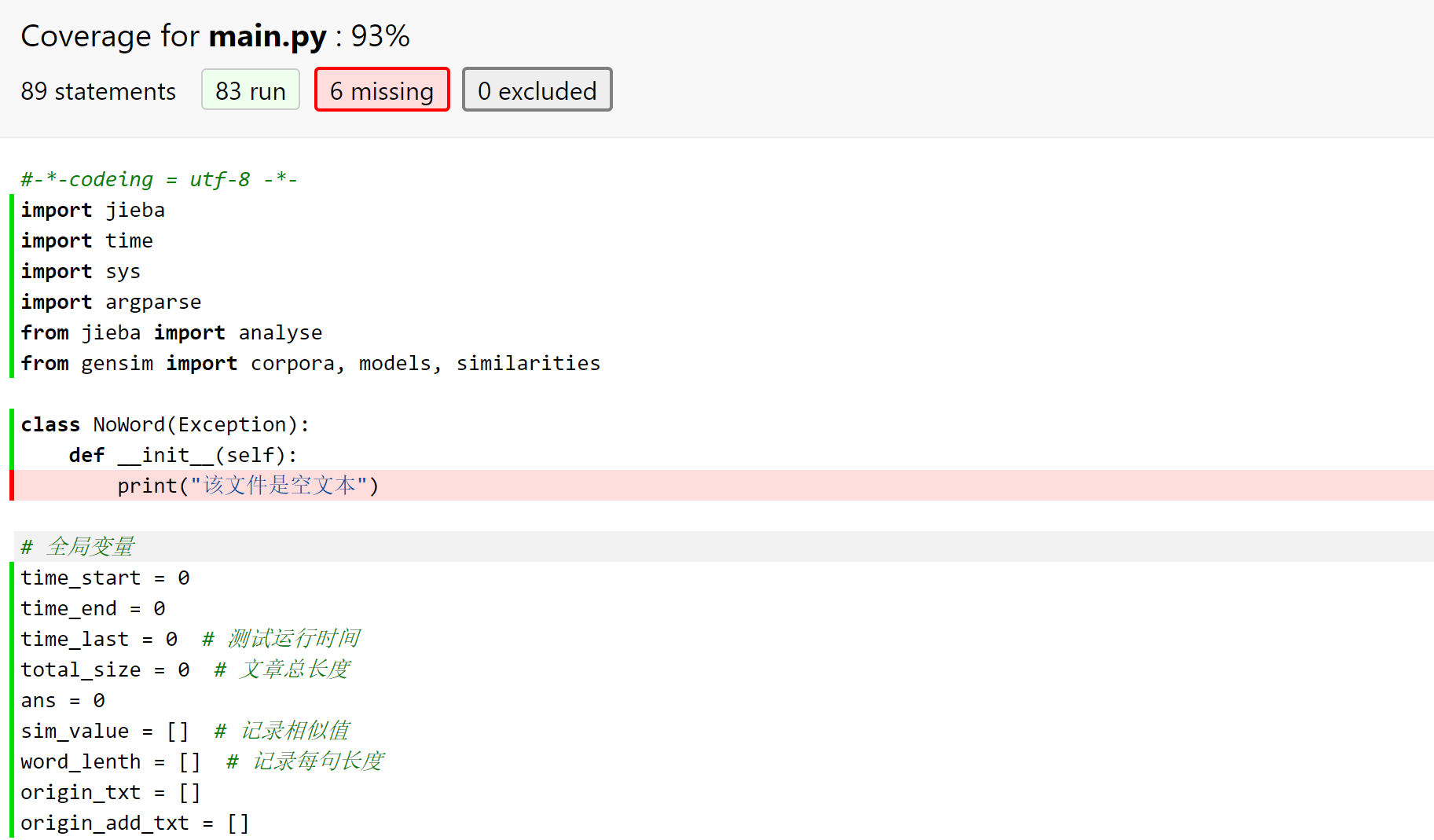
因为异常处理未使用到,因此只有93%的覆盖率
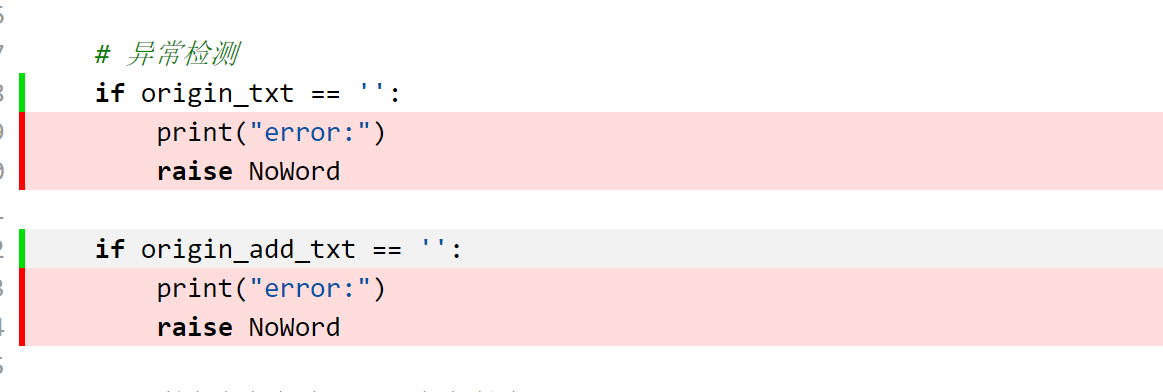
PART 4 计算模板部分异常处理说明
定义NoWord类,当文本没有汉字时跳转到这个类并输出
class NoWord(Exception):
def __init__(self):
print("该文件是空文本")
# 异常检测
if origin_txt == '':
print("error:")
raise NoWord
if origin_add_txt == '':
print("error:")
raise NoWord
PART 5 PSP表格
| *PSP2.1* | *Personal Software Process Stages* | *预估耗时(分钟)* | *实际耗时(分钟)* |
|---|---|---|---|
| Planning | ·计划 | 60 | 70 |
| · Estimate | · 估计这个任务需要多少时间 | 60 | 60 |
| Development | ·开发 | 800 | 1000 |
| · Analysis | · 需求分析 (包括学习新技术) | 360 | 400 |
| · Design Spec | · 生成设计文档 | 40 | 50 |
| · Design Review | · 设计复审 | 30 | 30 |
| · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 30 | 50 |
| · Design | · 具体设计 | 60 | 80 |
| · Coding | · 具体编码 | 100 | 120 |
| · Code Review | · 代码复审 | 40 | 50 |
| · Test | · 测试(自我测试,修改代码,提交修改) | 60 | 70 |
| Reporting | ·报告 | 30 | 40 |
| · Test Repor | · 测试报告 | 40 | 50 |
| · Size Measurement | · 计算工作量 | 30 | 30 |
| · Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 30 | 40 |
| · 合计 | 1770 | 2140 |
PART 6 作业总结
-
第一次编程作业就给我整懵了,完全涉及到我的知识盲区,于是花了两天的时间速学python以及相关库的知识,对我来说应该是一个全新的体验。
-
目前所积累的知识太少了,在真正实践的时候感到手足无措,很多时候都是依靠同学和百度,感到很愧疚也很无奈,在编程这方面还是需要进一步的提升。
吾命休矣~

 浙公网安备 33010602011771号
浙公网安备 33010602011771号