socket套接字编程
socket套接字编程
掌握基本的客户端与服务端代码编写
通信循环
代码健壮性校验
链接循环
TCP黏包现象(流式协议)
socket套接字编程
简介,socket模块,用于连接网络的TCP传输协议,涉及远程数据交互和osi七层。
案例:可以数据交互的程序
#架构启动肯定是先启动服务端再启动客户端
import socketserver = socket.socket() # 默认就是基于网络的TCP传输协议 买手机 server.bind(('127.0.0.1', 8080)) # 绑定ip和port 插电话卡 server.listen(5) # 半连接池 开机(过渡) sock, address = server.accept() # 监听 三次握手的listen态 print(address) # 客户端地址 data = sock.recv(1024) # 接收客户端发送的消息 听别人说话 print(data) sock.send(b'hello my big baby~~~') # 给别人回话 sock.close() # 挂电话 server.close() # 关机 import socket client = socket.socket() # 买手机 client.connect(('127.0.0.1', 8080)) # 拨号 # 说话 client.send(b'hello big DSB DSB DSB!') # 听他说 data = client.recv(1024) print(data) client.close()
通信循环及代码优化
1.客户端校验信息不能为空
2.服务端添加兼容性代码(mac linux)
3.服务端重启频繁报端口占用错误
from socket import SOL_SOCKET, SO_REUSEADDR server.setsockopt(SOL_SOCKET, SO_REUSEADDR, 1) # 在bind前加
4.客户端异常关闭服务端报错的问题(异常捕获)
5.服务端链接循环
6.半连接池(设置可以等待的客户数量)
黏包现象
简介:TCP协议有一个特性,当数据比较小且同一时间发送的时候,会把同批数据合在一起打包发送,黏包现象就是多个数据包打包在一起,或数据太大没能完全发送成功
报头:识别即将到来的数据具体信息,并判断大小。报头的长度必须是固定的
struct模块
将数据按照模块内置大小进行压缩,便于局域内传播和接收
import struct import json d = { 'file_name': '很好看.mv', 'file_size': 1231283912839123123424234234234234234324324912, 'file_desc': '拍摄的很有心 真的很好看!!!', 'file_desc2': '拍摄的很有心 真的很好看!!!' } d = json.dumps(d) res = struct.pack('i',len(d)) print(len(res)) res1 = struct.unpack('i',res)[0] print(res1)
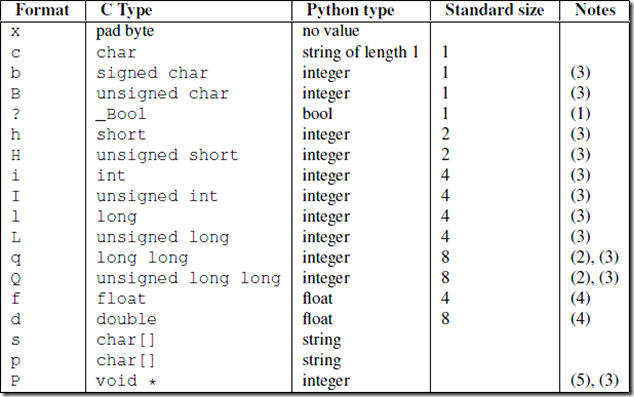
报头
简介:用于通知对方电脑将接收多大数据
import socket import subprocess import json import struct server = socket.socket() server.bind(('127.0.0.1', 8080)) server.listen(5) while True: sock, address = server.accept() while True: data = sock.recv(1024) # 接收cmd命令 command_cmd = data.decode('utf8') sub = subprocess.Popen(command_cmd, shell=True, stdout=subprocess.PIPE, stderr=subprocess.PIPE) res = sub.stdout.read() + sub.stderr.read() # 结果可能很大 # 1.制作报头 data_first = struct.pack('i', len(res)) # 2.发送报头 sock.send(data_first) # 3.发送真实数据 sock.send(res) import socket import struct client = socket.socket() # 买手机 client.connect(('127.0.0.1', 8080)) # 拨号 while True: msg = input('请输入cmd命令>>>:').strip() if len(msg) == 0: continue client.send(msg.encode('utf8')) # 1.先接收固定长度为4的报头数据 recv_first = client.recv(4) # 2.解析报头 real_length = struct.unpack('i',recv_first)[0] # 3.接收真实数据 real_data = client.recv(real_length) print(real_data.decode('gbk'))
上传数据案例:
import json import socket import struct import os client = socket.socket() # 买手机 client.connect(('127.0.0.1', 8080)) # 拨号 while True: data_path = r'D:\金牌班级相关资料\网络并发day01\视频' # print(os.listdir(data_path)) # [文件名称1 文件名称2 ] movie_name_list = os.listdir(data_path) for i, j in enumerate(movie_name_list, 1): print(i, j) choice = input('请选择您想要上传的电影编号>>>:').strip() if choice.isdigit(): choice = int(choice) if choice in range(1, len(movie_name_list) + 1): # 获取文件名称 movie_name = movie_name_list[choice - 1] # 拼接文件绝对路径 movie_path = os.path.join(data_path, movie_name) # 1.定义一个字典数据 data_dict = { 'file_name': 'XXX老师合集.mp4', 'desc': '这是非常重要的数据', 'size': os.path.getsize(movie_path), 'info': '下午挺困的,可以提神醒脑' } data_json = json.dumps(data_dict) # 2.制作字典报头 data_first = struct.pack('i', len(data_json)) # 3.发送字典报头 client.send(data_first) # 4.发送字典 client.send(data_json.encode('utf8')) # 5.发送真实数据 with open(movie_path,'rb') as f: for line in f: client.send(line) # 1.先接收固定长度为4的字典报头数据 recv_first = sock.recv(4) # 2.解析字典报头 dict_length = struct.unpack('i', recv_first)[0] # 3.接收字典数据 real_data = sock.recv(dict_length) # 4.解析字典(json格式的bytes数据 loads方法会自动先解码 后反序列化) real_dict = json.loads(real_data) # 5.获取字典中的各项数据 data_length = real_dict.get('size') file_name = real_dict.get("file_name") recv_size = 0 with open(file_name,'wb') as f: while recv_size < data_length: data = sock.recv(1024) recv_size += len(data) f.write(data)
在阅读源码的时候
1.变量名后面跟冒号 表示的意思是该变量名需要指代的数据类型
2.函数后更横杆加大于号表示的意思是该函数的返回值类型

 浙公网安备 33010602011771号
浙公网安备 33010602011771号